Webpack(内容留存于 3.8.1 版本)
入门
安装
需要依赖 Node.js(version >= 5.0.0)环境
npm init 初始化新建的 web 项目目录
npm i -D webpack 安装 webpack 到项目;也可以使用 npm i -g webpack 安装到全局
建议在项目里安装,避免不同项目产生冲突
使用
webpack 会默认从项目根目录下的 webpack.config.js 文件中读取配置,所以我们得新建文件,通过 CommonJS 规范导出一个 Config Object 对象
module.exports = {
entry: './main.js',
output: {...},
}然后执行 webpack 命令
webpack 会从 entry 出发,识别源码中模块化导入于语句,递归的找出所有依赖,将入口和依赖模块打包到一个文件中
Loader
如果我们写了 css 文件,通过在 main.js 中引入,直接构建将会报错,因为 webpack 不支持原生解析 css 文件,如果要支持非 JavaScript 文件,需要使用 Loader
module.exports = {
...
module: {
rules: [
test: /\.css$/,
use: ['style-loader', 'css-loader?minimize'],
]
}
}module.rules 数组配置一组规则,告诉 webpack 在遇到那些文件时使用哪些 Loader 去加载和转换
上述配置告诉 webpack 在遇到 .css 文件结尾时,先使用 css-loader 读取 css 文件,再用 style-loader 将 css 文件内容注入到 JavaScript 里,注意:
- use 属性值是一个 Loader 名组成的数组,Loader 执行顺序是由后至前的
- 每个 Loader 都可以通过 URL querystring 的方式传入参数
每个不同 Loader 的属性需要我们查阅不同文档
在执行前我们需要保证 Loader 下载完成:npm i -D style-loader css-loader
style-loader 的原理大概是将 css 内容在 JavaScript 中通过 DOM 操作添加 style 标签,如果想让 css 文件单独存在,可以通过 Plugin 机制实现
Loader 传入属性的方式还可以是 Object:
use: [
"style-loader",
{
loader: "css-loader",
options: {
minimize: true,
},
},
];除了在 webpack 配置文件中指定 loader,还可以在源码中指定 loader 处理文件:require('style-loader!css-loader?minimize!./main.css'),这样就可以指定先用 css-loader 再使用 style-loader 进行转换
Plugin
Plugin 是用来扩展 webpack 功能的,通过在构建流程里注入钩子实现
例如将上面例子中的 css 从 js 提取到单独的文件中
const ExtractTextPlugin = require('extract-text-webpack-plugin');
module.exports = {
...
module: {
rules: [
{
test: /\.css$/,
loaders: ExtractTextPlugin.extract({
use: ['css-loader'],
})
}
]
},
plugins: [
new ExtractTextPlugin({
filename: `[name]_[contenthash:8].css`,
})
]
}同样的要安装相关的插件(新版本请用:mini-css-extract-plugin 代替)
DevServer
实际开发中我们需要:
- 提供 HTTP 服务而不是本地文件预览
- 监听文件的变化并自动刷新网页
- 支持 Source Map,方便调试
以上 2、3 点 webpack 原生支持,第一点可以通过官方的开发工具支持(webpack-dev-server),安装后执行 webpack serve 命令
DevServer 会将构建好的文件保存在内存中,可以通过 HTTP 访问,所以要注意 index.html 中的 script src
在 DevServer 模式下默认会开启监听模式,webpack 开启监听模式需要 webpack --watch
DevServer 会在 webpack 构建出的 JavaScript 代码中注入一个代理客户端用于控制网页,网页和 DevServer 之间通过 websocket 通信,DevServer 收到 webpack 文件变化通知时,通过注入的客户端控制网页刷新
但是如果修改 index.html 文件并保存,并不会出发上述机制,是因为 webpack 会根据 entry 为入口递归解析出 entry 以及其依赖文件,所以只有 entry 本身和其依赖的文件才会被 webpack 添加到监听列表里
热模块替换
热模块替换可以在不重新加载整个网页情况下通过将已更新的模块替换旧模块,并重新执行来实现重新预览
DevServer 默认关闭热替换,我们需要在启动时附带 --hot 参数
支持 Source Map
浏览器运行中的代码都是编译后的代码,可读性很差,如果要添加断点调试会很困难,通过 Source Map 映射代码后,我们可以在源代码上断点调试
webpack 支持生成 Source Map,只需要在启动时附带 --devtoll source-map 参数。重启 DevServer 后刷新页面,就可以在 Chrome 浏览器开发工具中查看到可调试的源码了
核心概念
- Entry:入口,webpack 执行构建的第一步
- Module:模块,webpack 里一切皆模块,一个模块对应一个文件,webpack 会从 Entry 开始递归找出所有依赖模块
- Chunk:代码块,一个 Chunk 由多个模块组合而成,用于代码的合并和分割
- Loader:模块转换器,将模块的原内容按照需求转换成新内容
- Plugin:扩展插件,在 webpack 构建流程中的特定时机注入扩展逻辑,改变构建结果或做我们想做的事情
- Output:输出结果,webpack 经过一系列处理后得出最终代码的输出结果
webpack 会从 entry 开始,递归解析 entry 依赖的所有 module,每找到一个 module 都会根据相应的配置使用 loader 转换,这些模块会以 entry 为单位进行分组,一个 entry 及其对应的所有依赖被分到一个组也就是一个 chunk,最后 webpack 会将所有 chunk 转换成文件输出。整个流程中 webpack 会在恰当的时机执行 plugin
配置
webpack 配置有两种:
- 通过一个 js 文件配置,例如 webpack.config.js
- 执行 webpack 命令时通过命令行参数传入,例如 webpack --devtool source-map
还可以通过执行 webpack --config webpack-dev.config.js 指定配置文件
按照配置影响的功能来划分,有如下内容:
- Entry
- Output
- Module:处理模块的规则
- Resolve:寻找模块的规则
- Plugins
- DevServer
- 其他配置
- 整体配置结构:整体地描述各配置项的结构
- 多种配置类型:配置文件还可以返回除 Object 以外的其它形式内容
- 配置总结:寻找配置 webpack 的规律,减少思维负担
Entry
必填
context
webpack 再执行时总是会以 context 为根目录,context 默认为执行启动 webpack 时所在的当前工作目录,可以在配置文件中手动设置
module.exports = {
context: path.resolve(__dirname, "app"),
};context 必须是一个绝对路径字符串,在启动时也可以通过命令行 --context 设置
Entry 类型
| 类型 | 例子 | 含义 |
|---|---|---|
| string | './app/entry' | 入口模块的文件路径,可以是相对的 |
| array | ['./app/entry1', './app/entry2'] | 入口模块的文件路径,可以是相对的 |
| object | {a: './app/entry-a', b: ['./app/entry-b1', './app/entry-b2']} | 配置多个入口,每个入口生成一个 chunk |
如果是 array 类型,则搭配 output.library 配置项使用,数组中的多个模块会合并为一个 chunk 导出
Chunk 名称
webpack 会为每一个 chunk 取一个名称,chunk 的名称和 entry 的配置有关
- 如果 entry 是一个 string 或 array,就只会生成一个 chunk,这时名称是 main(默认)
- 如果 entry 是一个 object,就可能出现多个 chunk,这时 chunk 的名称是 object 的键的名称
配置动态 Entry
可以将 entry 设置成一个函数
entry: () => ({
a: "./pages/a",
b: "./pages/b",
});
// 异步函数
entry: () =>
new Promise((res) =>
res({
a: "./pages/a",
b: "./pages/b",
})
);Output
配置如何输出最终代码
filename
string、支持字符串模板
可以指定具体名称 'bundle.js',但是在有多个 chunk 情况下,需要使用模板和变量 '[name].js'
内置变量有:
| 变量名 | 含义 |
|---|---|
| id | chunk 唯一标识,从 0 开始 |
| name | chunk 的名称 |
| hash | chunk 唯一标识的 hash 值 |
| chunkhash | chunk 内容的 hash 值 |
其中 hash 值的长度是可以指定的,例如 [hash:8] 代表取 8 位 hash 值,默认是 20 位
上述插件 mini-css-extract-plugin 中的配置使用的是 contenthash 而不是 chunkhash,是因为该插件只读取单个模块内容而不是由一组模块组合成的 chunk 内容
chunkFilename
支持字符串模板(同 filename 配置)
配置无入口的 chunk 在输出时的文件名称,只用于指定在运行过程中生成的 chunk 在输出时的文件名称
运行时生成 chunk 的场景包括:使用 CommonChunkPlugin、使用 import('path/to/module') 动态加载等
path
string
配置输出文件存放在本地的目录,必须是绝对路径
publicPath
string、支持字符串模板,内置变量只有 hash
默认值是 '' 即使用相对路径
复杂的项目可能会有异步资源需要加载,这些资源需要对应的 URL 地址
例如构建出来的资源需要上传到 cdn 服务器上,我们就需要配置 publicPath: 'https://cdn.example.com/assets/'
crossOriginLoading
配置 JSONP script 标签的 crossorigin 值
- anonymous(默认),此脚本加载不会带上用户的 cookies
- use-credentials,此脚本加载会带上用户的 cookies
libraryTarget、library
构建一个可以被其他模块导入的库时需要的配置
- libraryTarget,配置以何种方式导出库
- library,配置导出库的名称
libraryTarget 是字符串枚举类型:
1、var()默认
编写的库将通过 var 被赋值给 通过 library 指定名称的变量
例如,配置 library 为 libName,则 webpack 输出的代码为:
var libName = lib_code;如果 library 配置为空,则直接输出:lib_code
lib_code 为导出的代码内容,是一个有返回值的立即执行函数
2、commonjs
编写的库将通过 CommonJS 规范导出
exports["libName"] = lib_code;3、commonjs2
编写的库将通过 CommonJS2 规范导出
module.exports = lib_code;在 libraryTarget 配置为 commonjs2 时,配置 library 将没有意义
4、this
编写的库将通过 this 被赋值给 library 指定的名称
this["libName"] = lib_code;5、window
编写的库将通过 window 赋值给 library 指定的名称
window["libName"] = lib_code;6、global
编写的库将通过 global 赋值给 library 指定的名称
global["libName"] = lib_code;版本 5 已经支持更多的配置
libraryExport
配置要导出的模块中哪些子模块需要导出,只有在 libraryTarget 为 commonjs 或 commonjs2 时才有意义
假如要导出的模块代码为:
export const a = 1;
export default b = 2;如果想让构建输出的代码中只导出 a,则可以将 libraryExport 设置成 a,那么构建输出的代码如下:
module.exports = lib_code["a"];webpack ouput 还有很多配置项,可以在官方文档查阅
Module
配置 Loader
rules 配置模块的读取解析规则通常用来配置 loader。其类型是一个数组,数组中的每一项都描述了如何处理部分文件,大致可以通过一下方式配置一项 rules:
- 条件匹配:通过 test、include、exclude 来过滤文件
- 应用规则:对选中的文件通过 use 配置应用 loader,可以应用单个 loader,多个 loader 的应用顺序是按照数组从后到前
- 重置顺序:可以通过 enforce 选项将其中一个 loader 执行顺序放到最前或最后
例如:
module: {
rules: [
{
test: /\.js$/,
use: ["babel-loader?cacheDirectory"],
include: path.resolve(__dirname, "src"),
exclude: path.resolve(__dirname, "node_modules"),
},
];
}我们还可以用 object 描述 loader 配置:
use: [
{
loader: "babel-loader",
options: {
cacheDirectory: true,
},
enforce: "post", // 或者 pre
},
];test、include、exclude 可以传入一个数组类型,数组中的每项是 “或” 的关系
noParse
可选、RegExp,[RegExp],function
该配置项可以让 webpack 忽略部分没有采用模块化文件的递归解析和处理,提高构建性能。例如一些库:jQuery、ChartJS 等,既庞大有没有采用模块化,webpack 解析这些文件耗时也没有意义,例如:
noParse: /jquery|chartjs/;
// 或者
noParse: (content) => /jquery|chartjs/.test(content);被忽略的代码中不能包含 import、require、define 等模块化语句,不然会导致构建出的代码中包含无法在浏览器环境下执行的模块化语句
parser
webpack 内置了对模块化 JavaScript 的解析功能,支持 AMD、CommonJS、SystemJS、ES6。该配置项可以更细粒度地配置需要解析的模块
与 noParse 不同的是,parser 可以精确到语法层面,而 noParse 只能控制哪些文件不被解析
module: {
rules: [
{
test: /\.js$/,
use: ["babel-loader"],
parser: {
amd: false,
commonjs: false,
system: false,
harmony: false, // 禁用 ES6 import/export
requireInclude: false,
requireEnsure: false,
requireContext: false,
browserify: false,
requireJs: false,
},
},
];
}Resolve
该配置规定了 webpack 如何寻找模块所对应的文件。webpack 内置 JavaScript 模块化语法解析功能,默认会采用模块化标准里约定的规则去找,但我们可以修改默认规则
alias
通过别名将原导入路径映射成一个新的导入路径
resolve: {
alias: {
components: "./src/components/";
}
}
import Button from "components/button";
import Button from "./src/components/button";alias 还支持通过 $ 符号来缩小范围到只命中以关键字结尾的导入语句
mainFields
某些第三方模块会针对不同环境提供多份代码,例如提供 ES5 和 ES6 环境的两份代码,这两份代码的位置写在 package.json 里
{
"jsnext:main": "es/index.js", // ES6
"main": "lib/index.js" // ES5
}webpack 会根据 mainFields 配置去决定优先采用哪份代码,默认配置 mainFields: ['browser', 'main']
webpack 会按照数组的顺序在 package.json 里面找,使用第一个找到的文件
extensions
导入语句没有带文件后缀时,webpack 会自动附上后缀尝试访问文件是否存在,该配置规定了在尝试过程中用到的后缀列表
extensions: [".js", ".json"];modules
配置 webpack 优先在那些目录下寻找第三方模块,默认 node_modules,例如:
modules: ["./src/components", "node_modules"];这样配置后,想要导入 import './src/components/button'; 就可以直接导入 import 'button';
descriptionFiles
配置第三方模块的配置文件名称,也就是我们常用的 package.json 文件
enforceExtension
boolean
开启后所有导入语句都必须带文件后缀
enforceModuleExtension
和 enforceExtension 作用类似,但该配置只对 node_modules 下的模块生效
Plugin
array
用于扩展 webpack 功能,将 plugin 实例通过构造函数传入就行,例如:
plugins: [
new CommonChunkPlugin({
name: "common",
chunks: ["a", "b"],
}),
];plugin 的使用基本没有难度,而每个 plugin 的作用和传入参数才是难点所在,需要自行查阅文档
DevServer
只有通过 DevServer 启动 webpack 时,这项配置才会生效
hot
boolean
热模块替换功能,不刷新整个页面下通过替换新老模块做到实时预览
inline
DevServer 实时预览功能依赖一个注入页面里的代理客户端,去接受来自 DevServer 的命令负责刷新网页
该配置决定是否将这个代理客户端自动注入运行在页面的 chunk 里,默认开启
- 开启,网页会自动刷新
- 关闭,DevServer 将会通过 iframe 方式运行网页,更新时刷新 iframe,但是我们需要到
http://localhost:8080/webpack-dev-server/实时预览自己的网页
historyApiFallback
boolean,object
开启了 history 模式的 SPA 应用需要在命中任何路由时都返回一个对应的 HTML 文件
该选项就是提供此功能的
我们可以简单的设置为 true 开启,也可以用一个 object 启用更复杂的配置
historyApiFallback: {
rewrites: [
{ from: /^\/user/, to: "/user.html" },
{ from: /^\/game/, to: "/game.html" },
{ from: /./, to: "/index.html" }, // 其它都返回 index.html
];
}contentBase
boolean,string
配置 DevServer HTTP 服务器的文件根目录,默认当前执行目录
devServer: {
contentBase: path.join(__dirname, "public");
}DevServer 通过 HTTP 暴露文件的方式可以分为两种:
- 暴露本地文件
- 暴露 webpack 构建结果,webpack 会将构建结果提交给 DevServer,所以我们在使用 DevServer 时,本地找不到构建文件
该规则只能用来配置暴露本地文件
可以通过设置成 false 关闭暴露本地文件
headers
可以在 HTTP 响应中注入响应头
headers: {
'X-foo': 'bar'
}host
配置服务监听的地址
默认值是 127.0.0.1,即本地访问
如想要局域网上其他设备访问自己的本地服务,可以配置该项或者在启动时附带上 --host 0.0.0.0
port
配置服务监听的端口,默认 8080 端口,如果被占用则 +1 尝试,直到成功
allowedHosts
配置白名单列表,只有 HTTP 请求的 HOST 在列表中才能正常返回
allowedHosts: [
"host.com",
".host2.com", // 匹配 host2.com 以及所有的子域名 *.host2.com
];disableHostCheck
配置是否关闭用于 DNS 重定向绑定的 HTTP 请求的 HOST 检查
DevServer 默认只接收来自本地的请求,关闭后可以接收来自任意 HOST 的请求,通常搭配 host: 0.0.0.0 使用,因为一般直接通过 IP 访问,所以没有 HOST,则需要关闭该项
https
配置 https 服务
可以直接设置为 true 开启,DevServer 会为我们自动生成一份 HTTPS 证书
如果我们想用自己的证书,可以如下配置:
https: {
key: fs.readFileSync('path/server.key'),
cert: fs.readFileSync('path/server.crt'),
ca: fs.readFileSync('path/ca.pem')
}clientLogLevel
string
配置客户端日志等级,影响开发者工具控制台里的日志打印,枚举类型:none、error、warning、info
设置为 info 即输出所有日志类型,none 即不输出任何日志
compress
boolean
是否启用 Gzip 压缩,默认 false
open
配置是否在第一次构建完后,自动打开浏览器并导航到相应的网页
openPage
配置自动打开浏览器后要导航的网页
其它配置项
只涉及一些常用配置项
target
该配置可以让 webpack 构建出不同运行环境的代码
| target 值 | 描述 |
|---|---|
| web | 针对浏览器(默认),所有代码都集中在一个文件里 |
| node | 针对 Node.js,使用 require 语句加载 chunk 代码 |
| async-node | 针对 Node.js,异步加载 chunk 代码 |
| webworker | 针对 webworker |
| electron-main | 针对 Electron 主线程 |
| electron-renderer | 针对 Electron 渲染线程 |
例如,配置为 node 时,在源码中导入 Node.js 原生模块的语句 require('fs') 将会被保留,fs 模块内容将不会被打包到 chunk 里
devtool
boolean、string
该配置规范 webpack 如何生成 source map,默认值是 false,即不生成 source map,若想开启则设置为 'source-map'
更多的值查看官网:https://www.webpackjs.com/configuration/devtool/
watch、watchOptions
boolean & object
开启监听文件更新,watchOptions 只有在 watch 为 true 时才生效
watchOptions: {
ignored: /node_modules/, // 排除的文件夹,支持正则,默认为空
aggregateTimeout: 300, // 文件更改后重新编译的延迟,防止重新编译频率过高,默认 300ms
poll: 1000, // 判断文件是否发生变化是通过不停地询问系统指定文件有没有变化实现的,默认 1000次/s
}externals
告诉 webpack 构建的代码中不用被打包的模块,一些第三方模板是外部提供的,webpack 在打包的时候可以忽略,代码中直接使用就行
externals: {
jquery: "jQuery"; // 将导入语句中的 jquery 替换成运行环境里的全局变量 jQuery
}resolveLoader
该配置用来告诉 webpack 如何寻找 loader,因为在使用 loader 时是通过包名称去引用的,webpack 需要根据配置的 loader 包名去找到 loader 的实际代码,然后调用 loader 去处理源文件
resolveLoader: {
modules: ['node_modules'], // loader 所在的目录
extensions: ['.js', '.json'], // 入口文件的后缀
mainFields: ['loader', 'main'] // 指明入口文件位置的字段
}该配置用于加载本地的 loader
整体配置结构
书上 p54
多种配置类型
除了通过 object 导出 webpack 所需配置,还有其他更灵活的方式
Function 方式
通常我们需要同一份源码构建出多份代码,例如一份用于开发,一份用于发布
如果采用 object 配置 webpack 则需要两份文件,然后启动时指定文件
采用 function 方式能更灵活的配置 webpack
module.exports = function (env = {}, argv) {
const plugins = [];
const isProduction = env["production"];
if (isProduction) {
plugins.push(new UglifyJsPlugin());
}
return {
plugins: plugins,
devtool: isProduction ? undefined : "source-map",
};
};运行 webpack 时会传入两个参数:
- env,当前运行时的 webpack 专属环境变量,是一个 object,依赖于执行 webpack 命令时附带的参数例如:
webpack --env.production --env.bao=foo - argv,在启动 webpck 时,通过命令行传入的所有参数,例如:--config、--env、--devtool,可以通过
webpack -h列出所有 webpack 支持的命令行参数
Promise 方式
某些情况下不能同步返回描述配置的 object,可以返回一个 promise 函数
module.exports = function (env = {}, argv) {
return new Promise((res, rej) => {
setTimeout(() => {
res({
// ...
});
}, 5000);
});
};导出多份配置
webpack 支持导出一个数组,数组中每项配置都会执行一遍构建
module.exports = [
{
// ...
},
function () {
return {...}
},
function () {
return new Promise(...);
}
]特别适合用 webpack 构建一个要上传到 npm 仓库的库
总结
我们不需要全部记住,只需要知道针对问题判断问题属于何种或者哪几种配置相关:
- 想要源文件加入构建流程中,则配置 entry
- 想要自定义出书文件位置和名称,则配置 output
- 想要自定义寻找依赖模块时的策略,则配置 resolve
- 想要自定义解析和转换文件的策略,则配置 module,通常是配置 module.rules 中的 loader
- 其它大部分需求可以通过配置 plugin 实现
实战
使用 ES6
通常我们需要将采用 ES6 的代码转换成 ES5 代码,需要做两件事:
- 要将 ES6 语法用 ES5 实现,例如 ES6 class 用 ES5 的 prototype 实现
- 为新的 API 注入 polyfill,例如新的 fetch
认识 babel
babel 是一个 JavaScript 编译器,能将 ES6 代码转换为 ES5 代码
babel 执行编译的过程中,会从根目录下的 .babelrc 文件中读取配置,该文件是一个 JSON 格式文件,例如:
{
"plugins": [
[
"transform-runtime",
{
"polyfill": false
}
]
],
"presets": [
[
"es2015",
{
"modules": false
}
],
"stage-2",
"react"
]
}
// 以上配置已不适用于最新版 babelplugin
该配置告诉 babel 要使用哪些插件,这些插件控制如何转换代码
上述 transform-runtime 插件全名叫 babel-plugin-transform-runtime,我们先要安装后者名字的插件才能正常运行
presets
该属性告诉 babel 要转换的源码使用了哪些新的语法特性,一个 presets 对一组新语法的特性提供了支持,多个 presets 可以叠加
presets 其实是一组 plugins 的集合,每个 plugin 完成一个新语法的转换工作
presets 是按照 ECMAScript 草案来组织的,通常可以分为三大类:
(1)已经被写入 ECMAScript 标准里的特性:ES2015(包含在 2015 年天界的新特性)、ES2016(包含在 2016 年添加的新特性)、ES2017(包含在 2017 年加入的新特性)、ENV(包含当前所有 ECMAScript 新特性)
(2)被社区提出来但还未被写入 ECMAScript 标准的特性:stage0(一个美好激进的想法)、stage1(值得被纳入标准的特性)、stage2(该特性已被起草,将会被纳入标准)、stage3(该特性已经定稿,各浏览器厂商和 Node.js 社区已经开始着手实现)、stage4(在接下来一年里将会加入标准里)
(3)用于支持一些特定场景下的语法特性,与 ECMAScript 没有关系,例如 babel-present-react 用于支持 React 开发里的 JSX 语法
接入 babel
在 webpack 配置中接入 babel loader
module: {
rules: [
{
test: /\.js$/,
use: ["babel-loader"],
},
];
}在重新运行 webpack 之前我们需要安装 babel-core、babel-loader 以及相关 babel 运行时所需的 plugins 和 presets
使用 TypeScript 语言
认识 TypeScript
TypeScript 是 JavaScript 的超集,主要提供了类型检查系统核对 ES6 语法的支持
但是现在没有环境可以直接运行 TypeScript 代码,必须要将它转换成 JavaScript 代码后才能运行
我们可以尝试将之前的项目中的 show.js 和 index.js 换成 ts 代码
ts 和 babel 一样,会读取在根目录中的 tsconfig.json 配置文件:
{
"compilerOptions": {
"module": "commonjs", // 编译出的代码采用的模块规范
"target": "es5", // 编译出的代码采用 ES 的哪个版本
"sourceMap": true // 输出 source map,当然在 webpack 中也需要开启
},
"exclude": [
// 不编译的文件目录
"node_modules"
]
}当然,我们需要安装 typescript 编译器包,这里可以安装到全局,因为 typescript 编译器可以通过执行 tsc 命令调用
例如:tsc hello.ts
减少代码冗余
typescript 编译器会有与 babel 一样的问题:再将 ES6 语法转换成 ES5 语法时需要注入辅助函数,为了不让同样的辅助函数出现在多个文件中,可以开启 typescript 编译器的 importHelpers 选项
{
"compilerOptions": {
"importHelpers": true
}
}该原理和之前的 transform-runtime 很类似,会将辅助函数转换成导入语句,该能力依赖于 tslib 这个迷你库
集成 webpack
让 webpack 支持 typescript,需要解决两个问题:
- 通过 loader 将 typescript 转换成 JavaScript
- webpack 在寻找模块对应的文件时需要尝试 ts 后缀
社区中有 ts-loader 可用,源码引入 ts 文件时不能带 .ts 后缀,并且需要在 webpack 配置 extensions,这个问题是 typescript 更新后的 break change
使用 Flow 检查器
认识 Flow
是 facebook 开源的一个 JavaScript 静态类型检测器,和 typescript 一样它是 JavaScript 语言的超集
在需要的地方加上类型检查
// @flow
function squarel(n: number): number {
return n * n;
}
squarel("2"); // Error: squarel 需要传入 number 作为参数
function squarel2(n) {
return n * n; // Error: 传入的 string 类型不能做乘法运算
}
squarel2("2");代码中第一行 // @flow 告诉 flow 检查器这个文件需要被检查
使用 Flow
使用前需要安装 flow-bin,安装完成后在根目录下执行 flow,flow 会遍历出所有需要检查的文件并对其进行检查,输出错误到控制台
采用 flow 静态类型语法的 JavaScript,是无法直接在目前已有的 JavaScript 引擎中运行的,要让代码可以运行,需要去掉静态类型的语法
可以使用两种方法实现:
- flow-remove-types:可单独使用,速度快
- babel-preset-flow:与 babel 集成
集成 webpack
将 flow 集成到项目里最方便的方法是借助 babel,我们需要安装相关 preset 并在 babel 配置中添加相应步骤
许多编辑器已经整合了 flow,可以实时在代码中高亮显示 flow
使用 SCSS 语言
认识 SCSS
它是一种 css 预处理器,语法和 css 相似,但加入了变量、逻辑登编程元素
scss 又叫 sass,区别在于 sass 语法类似于 ruby,而 scss 语法类似于 css
scss 优点在于可以方便地管理代码,抽离公共部分,通过逻辑写出更灵活的代码。和 scss 类似的 css 预处理器还有 less
scss 官方提供了以多种语言实现的编译器,更贴合前端工程师的是 node-sass
node-sass 核心模块是用 c++ 编写的,再用 node.js 封装了一层
node-sass 还支持通过命令行调用,例如 node-sass main.scss main.css
接入 webpack
webpack 官方提供了 sass-loader
因为需要先将 scss 文件转换成 css 所以在配置时应该如下:
rules: [
{
test: /\.scss/,
use: ["style-loader", "css-loader", "sass-loader"],
},
];使用 PostCSS
认识 PostCSS
它是一个 css 处理工具,和 scss 不同的是它可以通过插件机制灵活地扩展其支持的特性,而不像 scss 那样语法是固定的
它能向 css 自动加前缀、使用下一代 css 语法等
postcss 就像 babel 一样,它们解除了语法的禁锢,通过插件机制扩展语言本身,插件配置和 babel 一样从 postcss.config.js 文件读取
例如为 css 自动加前缀,增加各浏览器特性:
/* 输入 */
h1 {
display: flex;
}
/* 输出 */
h1 {
display: -webkit-box;
display: -webkit-flex;
display: -ms-flexbox;
display: flex;
}例如使用 css 下一代语法:
/* 输入 */
:root {
--red: #d33;
}
h1 {
color: var(--red);
}
/* 输出 */
h1 {
color: #d33;
}postcss 采用 JavaScript 编写,运行在 node.js 上,还可以使用命令行执行程序,启动时会读取配置文件:
module.exports = {
plugins: [require("postcss-cssnext")],
};接入 webpack
与 scss 无异
使用 React 框架
React 的语法特性
在使用了 react 项目的代码中有 jsx 语法和 class 语法
jsx 语法是无法直接在浏览器环境中运行的,所以我们需要转换 jsx 语法
React 与 Babel
首先我们需要安装 react 基础依赖:react、react-dom
然后需要安装并在 babel 配置文件中加入相应的 presets:babel-preset-react
我们 webpack 配置文件 module 对应的 test 规则需要加上 jsx 后缀
React 与 TypeScript
jsx 文件需要修改成 tsx 文件
并且需要安装相应的 typescript 接口描述模块 @types/react 和 @types/react-dom
我们还需要在 typescript 配置文件中开启 jsx 并支持 react:
{
"compilerOptions": {
"jsx": "react"
}
}还需要注意的一点是我们 webpack 配置文件 module 对应的 test 规则需要加上 tsx 后缀
使用 Vue 框架
vue 是一个渐进式框架,它可以直接编写成为直接在浏览器运行的代码,但是一般我们都使用 vue 官方提供的单文件组件的方法编写项目
认识 Vue
vue 和 react 都是由数据推动视图渲染的框架
过多的内容就不介绍了,可以自行了解
接入 webpack
首先我们需要安装 vue 运行需要的库:vue
然后安装构建所需要的依赖:vue-loader、vue-template-compiler
- vue-loader 负责解析和转换 .vue 文件,提取出其中的 script、style、template,再分别将他们交给对应的 loader 去处理
- vue-template-compiler 负责将 vue-loader 提取出的 html template 编译成对应的可执行的 JavaScript 代码,这和 react 中 jsx 语法编译成 JavaScript 代码类似
使用 TypeScript 编写 Vue 应用
配置 tsconfig.json:
{
"compilerOptions": {
"target": "es5", // 构建出 es5 版本的 JavaScript,与 vue 的浏览器支持保持一致
"strict": true,
"module": "es2015", // typescript 编译器输出的 JavaScript 采用 es2015 模块化,使 tree sharking 生效(后续将会说明)
"moduleResolution": "node"
}
}由于 typescript 不认识 .vue 文件的导入语句,所以我们需要创建 vue-shims.d.ts 文件来定义 .vue 文件类型
declare module "*.vue" {
import { ComponentOptions } from "vue";
const componentOptions: ComponentOptions;
export default componentOptions;
}我们还需要在 webpack 配置中加入 .ts 和 .vue 的 extensions,并且在 ts-loader 中加入对 .vue 文件的配置
{
test: /\.ts$/,
loader: 'ts-loader',
exclude: /node_modules/,
options: {
// 让 tsc 将 vue 文件当成一个 typescript 模块去处理,其本省不会处理 .vue 结尾的文件
appendTsSuffixTo: [/\.vue$/]
}使用 Angular2 框架
认识 Angular2
它继承了 angularjs 中部分思想,又加入了一些新的改进,与 react 和 vue 相比,angular2 要复杂的多,这三者出发点都是组件化和数据驱动视图,但是 angular2 多出了一下概念:
- 模块(NgModule):不是 JavaScript 或者其它编程语言里的模块化,而是指 angular2 里的独有方法
- 注解(Decorator):通过注解 @xxx 的方法为一个 class 附加元数据
- 服务(Service):按照功能划分,将项目中可重复的代码封装成一个个服务为其他模块使用。服务可以包含函数、常值等,常见的有日志服务、数据服务、应用程序配置等
- 依赖注入(Depandency Injection):也叫做控制反转(Inversion of Control),是面向对象编程中的一种设计原则,可以用来降低代码间的耦合度
这些 angular2 的概念对于大型项目提升显著,但是对于小型项目来说可能是累赘
angular2 支持 typescript 和 JavaScript,但通常选择 typescript,这也是开发 angular2 的语言
示例可以参考*《webpack 深入浅出》p86*,这里不做过多介绍
接入 webpack
由于 angular2 采用 typescript 开发,我们需要修改 typescript 配置
{
"compilerOptions": {
"target": "es5",
"module": "commonjs",
"sourceMap": true,
"experimentalDecorators": true, // 开启注解支持
"lib": [
// angular2 依赖新的 JavaScript API 和 DOM 操作
"es2015",
"dom"
]
},
"exclude": ["node_modules/*"]
}为单页应用生成 HTML
引入问题
在实际项目中需要引入的文件远不止我们生成的 bundle.js,例如:
- 项目采用 es6 语言以及 react 框架
- 为页面加入 google analytics,这部分代码需要内嵌到 head 标签里
- 为页面加入 disqus 用户评论,需要异步加载提升首屏加载速度
- 压缩和分离 JavaScript 和 css 代码,提升加载速度
我们需要自动化实现这些功能,不能每次都手动添加
解决方案
可以使用 html-webpack-plugin 或者 web-webpack-plugin
web-webpack-plugin 的用法与 html-webpack-plugin 有差异,可以在官网查看:
https://github.com/gwuhaolin/web-webpack-plugin#readme
https://github.com/jantimon/html-webpack-plugin#options
管理多个单页应用
一个大型项目不会将所有内容都集成到一个页面中,这会导致网页性能不佳
我们可以重复使用 html-webpack-plugin 来为我们生成多个 html:
// 多余配置省略
module.exports = {
entry: {
index: "./src/index/index.ts",
login: "./src/login/index.ts",
},
output: {
filename: "[name]_[chunkhash:8].js",
},
plugins: [
new htmlWebpackPlugin({
template: "./public/index.html",
chunks: ["index"],
filename: "index.html",
}),
new htmlWebpackPlugin({
template: "./public/index.html",
chunks: ["login"],
filename: "login.html",
}),
],
};这样会按照 entry 的键值去动态导入 chunk 到 html 中
当然对于每个 html 中可能有自己唯一的资源需要加载,也可能有公共资源需要加载,当我们每次要新增 html 时,手动去维护配置很麻烦
web-webpack-plugin 为我们提供了一种以目录维护 html 生成的能力,我们只需要按照规定目录格式来维护我们的代码就行,例如:
|-- pages
| |-- index
| | |-- index.css
| | |-- index.js
| |-- login
| | |-- index.css
| | |-- index.css
|-- common.css
|-- google_analytics.js
|-- template.html
|-- webpack.config.jswebpack 配置:
const { AutoWebPlugin } = require("web-webpack-plugin");
const autoWebPlugin = new AutoWebPlugin("pages", {
template: "./template.html",
postEntrys: ["./common.css"], // 通用 css 样式文件
commonsChunk: {
// 提取出所有页面的公共代码
name: "common", // 提取出公共代码的 chunk 名称
},
});
module.exports = {
entry: autoWebPlugin.entry({
// 可以加入我们额外需要的 chunk 入口
}),
plugins: [autoWebPlugin],
};配置中 template.html 模板文件参照上一章,按照 web-webpack-plugin 模板方式边学(同《webpack 深入浅出》p98)
构建同构应用
指写一份代码但可同时在浏览器和服务器中运行的应用
认识同构应用
因为大多数单页应用视图都是通过 JavaScript 代码在浏览器端渲染出来的,所以当项目复杂的时候,渲染过程的计算量大,对于设备较差的用户来说可能会有性能问题
所以同构应用思想是:采用服务端渲染出带内容的 html 后再返回,这样可以减少首屏渲染的时间
随着 node.js 的成熟和虚拟 dom 的实现,这个设想成为可能
现在流行的主流框架都支持同构,接下来以 react 为例介绍如何构建同构应用
同构应用运行原理的核心是虚拟 dom,虚拟 dom 的意思是不直接操作 dom,而是通过 JavaScript object 描述原来的 dom 结构,这样做有以下优势:
- 操作 dom 树是高耗时操作,所以尽量减少 dom 树操作能优化网页的性能,虚拟 dom 的 diff 算法能找出两个不同 object 的最小差异,得出最小的 dom 操作
- 虚拟 dom 在渲染时不仅可以通过操作 dom 树表示结果,也可以有其他表示方式,例如将虚拟 dom 渲染成字符串,或者渲染成手机 app 原生 ui 组件(React Native)
例如 react,其核心模块是 react(负责管理 react 生命周期),而 react-dom 负责渲染工作
同构应用的最终目的是从一份项目源码中构建出两份 JavaScript 代码,一份用于浏览器端运行,一份用于在 node.js 环境中运行并渲染出 html,在 node.js 环境下运行的 JavaScript 代码需要注意一下内容:
- 不能包含浏览器 api,例如 document
- 不能包含 css 代码,服务端渲染的目的是渲染出 html 内容,渲染出 css 代码会额外增加计算量,影响性能
- 不能将第三方模块和 node.js 原生模块打包进去,需要通过 commonjs 规范引入
- 需要通过 commonjs 规范导出一个渲染函数,用于在 http 服务器中执行这个渲染函数,渲染出 html 的内容后返回
解决方案
为了构建出两份不同的代码,我们需要有两份 webpack 配置文件,并且需要两份不同的入口文件,相关实现不做赘述,《webpack 深入浅出》p101
构建 Electron 应用
认识 Electron
我们熟悉的 atom 和 vscode 编辑器就是用 electron 开发的
electron 是 node.js 和 chromium 的结合体,通过 chromium 管理 gui,通过 node.js 与操作系统交互
由于 chromium 和 node.js 都是跨平台的,所以 electron 能做到在不同操作系统中运行同一份代码
electron 应用运行时,会从一个主进程开始,这个主进程的启动是通过 node.js 执行一个入口 JavaScript 入口文件实现的,这个入口文件是 main.js
const { app, BrowserWindow } = require("electron");
let win;
function createWindow() {
win = new BrowserWindow({ width: 800, height: 600 });
const indexPageURL = `file://${__dirname}/dist/index.html`;
win.loadURL(indexPageURL);
win.on("closed", () => {
win = null;
});
}
app.on("ready", createWindow);
app.on("window-all-closed", () => {
// MacOS 系统上退出窗口并不会真正的退出应用,只有使用 cmd + q 才会真正的退出应用
if (process.platform !== "darwin") {
app.quit();
}
});主进程启动后会一直驻留在后台运行,我们看到的和操作的窗口是由主进程新启动的窗口子进程
应用生命周期事件可以通过 electron.app.on() 去监听,具体参见 api 文档:https://www.electronjs.org/zh/docs/latest/api/app
应用启动时会加载 loadURL 中的传入的网页地址,每个窗口都是一个单独的网页进程,窗口之间需要借助主进程传递信息
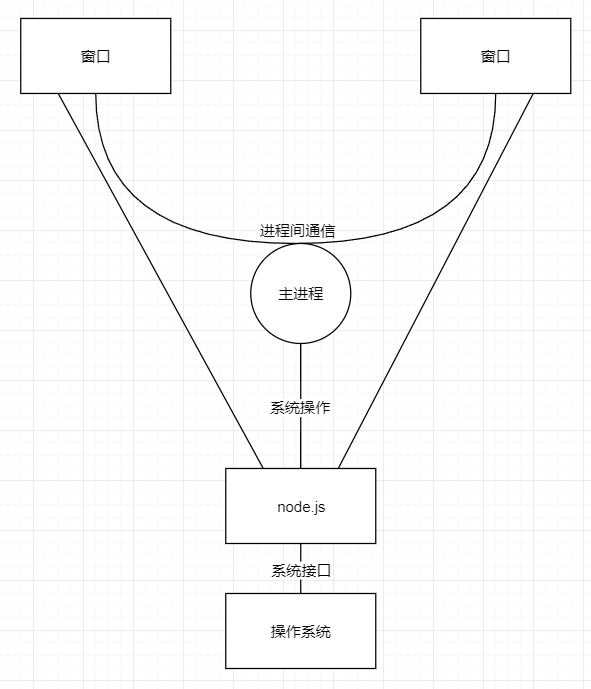
接入 webpack
因为 electron 每个窗口对应一个网页所以我们要打开新的窗口就需要一个新的网页
我们以之前的项目代码来改造
main.js 文件
const { app, BrowserWindow } = require("electron");
const remote = require("@electron/remote/main"); // remote 模块,是从 elctron 中分离出来的,因为该模块采用 ipc 进行通信,这导致了一系列问题,详情:https://zhuanlan.zhihu.com/p/406184033
remote.initialize(); // 初始化
function createWindow() {
let win = new BrowserWindow({
width: 1000,
height: 800,
webPreferences: {
nodeIntegration: true, // 是否启用Node integration. 默认值为 false
contextIsolation: false, // 是否在独立 JavaScript 环境中运行 Electron API 和指定的 preload脚本
},
});
const indexPageURL = `./dist/index.html`;
win.loadFile(indexPageURL);
remote.enable(win.webContents);
}
app.whenReady().then(() => {
createWindow();
app.on("activate", () => {
if (BrowserWindow.getAllWindows().length === 0) createWindow();
});
});
app.on("window-all-closed", () => {
if (process.platform !== "darwin") app.quit();
});index.vue
<template>
<h1>{{ msg }}</h1>
<button @click="login">login</button>
</template>
<script lang="ts">
import { defineComponent } from "vue";
import { BrowserWindow } from "@electron/remote"; // 这里需要使用 remote 提供的模块
export default defineComponent({
name: "App",
setup() {
return {
msg: "hello, webpack",
login: () => {
const URL = `./dist/login.html`; // 目录还是会相对于启动时的目录,所以不需要使用当前文件的相对路径
let win = new BrowserWindow({ width: 400, height: 320 });
win.loadFile(URL);
},
};
},
});
</script>
<style lang="css" scoped>
h1 {
color: red;
}
</style>构建 Npm 模块
认识 Npm
npm 是目前最大的 JavaScript 模块仓库,我们可能会需要发布模块到 npm 仓库
npm 仓库中的模块有以下特点:
- 根目录下必须有 package.json 文件描述模块的入口文件,以及该模块依赖的模块
- 模块中的文件以 JavaScript 为主,但不限于 JavaScript,例如 ui 组件就需要 css 等
- 代码大多采用模块化规范,目前比较广泛支持的是 commonjs 模块
抛出问题
例如构建一个 react 组件,需要注意以下几点:
- 源码采用 es6 编写,但是需要转换到 es5 再发布,遵守 commonjs 模块规范
- 该组件依赖的其它资源(例如 css)也需要包含在发布的模块里
- 减少冗余代码
- 不能含有其依赖的模块代码
最终发布到 npm 仓库的代码目录结构
node_modules/hello-webpack
|-- lib
| |-- index.css
| |-- index.css.map
| |-- index.js
| |-- index.js.map
|-- src
| |-- index.css
| |-- index.js
|-- package.json使用 webpack 构建 Npm 模块
- es6 代码的转换可以用 babel-loader;output.libraryTarget='commonjs2' 可以构建出符合 commonjs 的代码
- 通过 css-loader 和 mini-css-extract-plugin 可以实现对 css 的处理
- 冗余代码例如构建时生成的 es6 辅助函数(多次使用会重复出现)可以通过 require 的方式导入,通过 babel-transform-runtime 可以实现
- 使用 externals 配置可以防止打包后的代码含有不需要被打包的第三方依赖
发布到 Npm
在发布之前,我们需要确保我们的模块描述文件正确配置,所以我们需要将 package.json 文件中的 main 字段属性值换成打包后文件路径,这样可以确保使用者引入的时候 npm 或者 webpack 知道引用的是哪个具体文件
之后就能打包发布了(发布之前确保登录了 npm【npm login】)
如果想要发布到 npm 的代码同源代码目录结构保持一致,那么用 webpack 将不再合适,因为 webpack 打包会将依赖得模块组合在一起形成一个 chunk 文件,所以面对工具函数库,webpack 可能不再合适
构建离线应用
认识离线应用
离线应用是指利用离线缓存技术,让资源在第一次被加载后缓存在本地,在下次访问的时候就直接返回本地的文件,即使没有网络连接
离线应用有以下优势:
- 没有网络的情况下也能打开网页
- 由于部分被缓存的资源直接从本地加载,可以减少运营者服务器压力以及流量传输费用
离线应用的核心是离线缓存技术,历史上总共出现过两种离线缓存技术:
- AppCache,已经从 web 标准中删除,请不要使用
- Service Workers,通过拦截网络请求实现离线缓存,比前者更灵活,也是构建 PWA 应用的关键技术之一
认识 Service Workers
1、兼容性
目前 chrome、firefox、opera 都已经全面支持,只有高版本的 android 支持移动端的浏览器,由于 service workers 无法通过注入 polyfill 实现兼容,所以使用前需要先明白自己网页运行的场景,判断浏览器是否支持 service workers 最简单的方法:
if (navigator.serviceWorker) {
}2、注册 Service Workers
if (navigator.serviceWorker) {
window.addEventListener("DOMContentLoaded", function () {
navigator.serviceWorker.register("/sw.js");
});
}第一次打开网页时,service workers 逻辑不会生效,因为脚本还没有被加载和注册,之后再打开网页时脚本里的逻辑才会生效
3、使用 Service Workers 实现离线缓存
注册成功后会在 service workers 中派发一些事件,通过监听对应事件在特定的时间节点上做一些事情
在 service workers 脚本中有一个新的关键字 self,代表当前的 service worker 实例
可以监听 install 和 fetch 事件
4、更新缓存
有时候缓存文件需要被更新,可以通过更新 service workers 脚本文件做到
浏览器针对 service workers 有如下机制:
- 每次打开网页时都会重新下载 service workers 脚本文件。如果发现和当前已经注册过的文件存在字节差异,就将其视为“新服务工作者线程”
- 新的 service workers 线程将会启动,触发 install 事件
- 网站关闭时,旧的 service workers 线程将会被终止,新的 service workers 线程将会取得控制权
- 新的 service workers 线程取得控制权后,会触发其 activate 事件
新的线程中的 activate 事件就是清理旧缓存的最佳时间点
上述四点实现代码翻阅书中 p122
接入 webpack
使用 webpack 构建离线应用时,要解决如何生成 sw.js 文件,并且 sw.js 文件中的 cacheFileList 变量需要根据每次打包动态生成
webpack 没有原生功能,不过有插件可以是实现:serviceworker-webpack-plugin
还有两点需要注意:
- 由于 service workers 必须在 https 环境下才能拦截网络请求来实现离线缓存
- 插件为了保持灵活性,允许使用者自定义 sw.js,构建输出的 sw.js 文件中会在头部注入一个变量, serviceWorkerOption.assets 到全局,里面存放着所有被缓存的文件的 url 列表
验证结果
可以通过浏览器开发者工具来查看
搭配 Npm Script
认识 Npm Script
npm script 是一个任务执行者,npm 是在安装 node.js 时附带的包管理器,npm script 则是 npm 内置的一个功能,定义在 package.json 文件中
npm script 底层是通过调用 shell 脚本去运行脚本命令
有一些第三方包安装后不能直接在命令行中执行(因为环境变量中没有,也不可能每一个都创建环境变量),而是需要执行 ./node_modules/.bin/some ,这样很麻烦,而 npm 可以解决这个问题,在 script 中直接设置 some ,然后运行 npm run some ,npm 会先去 node_modules 目录中查询有没有可执行文件,如果没有就使用全局的
webpack 为什么需要 Npm Script
webpack 只是一个打包模块化代码的工具,并没有提供任何任务管理相关功能,所以需要一个可以自定义任务的管理器
检查代码
代码检查具体是做什么的
规定代码风格,让项目成员遵循统一的代码风格
发现代码运行过程中可能出现的潜在 bug
怎么做代码检查
1、检查 JavaScript
目前最常用的的是 eslint
安装好 eslint 第三方包后,在目录下执行 eslint init 会新建一个配置文件 .eslintrc,该文件格式为 json
可以配置相关属性覆盖原有检查规则
最后可以使用 eslint some.js 检查文件
2、检查 TypeScript
tslint 插件
和 eslint 相差无异,不过配置文件是 tslint.json
3、检查 css
stylelint,基于 postcss
通过 .stylelintrc 文件配置
上述三项配置都可以通过官网查询
结合 webpack 检查代码
1、结合 ESLint
eslint-loader 可以方便地将 eslint 整合到 webpcak 中
module.exports = {
module: {
rules: [
{
test: /\.js$/,
include: /node_modules/, // 不用检查该目录下的代码
loader: "eslint-loader",
enforce: "pre",
},
],
},
};2、结合 TSLint
和 eslint 相差无几
3、结合 stylelint
使用 StyleLintPlugin
4、一些建议
将代码检查功能整合到 webpack 中会导致以下问题:
- 执行检查步骤计算量大,所以整合到 webpack 中会导致构建变慢
- 整合到 webpack 后,输出的错误信息是通过行号来定位错误的,没有编辑器集成显示错误直观
为了避免以上问题:
- 使用集成了代码检查功能的编辑器,让编辑器实时的显示错误
- 将代码检查步骤放到代码提交时,只有在提交前调用工具去检查,只有通过了才能提交代码到仓库
git 提供了 hook 功能能在代码提交前触发执行脚本
执行 npm i -D husky 安装时,husky 会通过 npm script hook 自动配置好 git hook,我们只需要在 package.json 中定义几个脚本
{
"scripts": {
"precommit": "npm run lint",
"prepush": "lint",
"lint": "eslint && stylelint"
}
}可以根据需要选择设置 precommit 和 prepush 中的一个,无需两个都设置
通过 Node.js API 启动 webpack
webpack 还支持通过 node.js api 调用,因为 webpack 由 JavaScript 开发
通过 api 调用并执行 webpack,比直接通过可执行文件启动更灵活,可以用在一些特殊的场景中
安装和使用 webpack
安装步骤 npm i webpack
导入 const webpack = require('webpack'); or import webpack from "webpack";
使用:
webpack(
{
// webpack 配置
},
(err, stats) => {
if (err || stats.hasErrors()) {
// 构建出错
}
// 构建成功
}
);如果我们将构建配置写在文件中的话
const config = require("./webpack.config.js");
webpack(config, cb);以监听模式运行
以 api 方法启动的 webpack 只能执行一次构建,无法以监听模式运行,如果需要则要获取 compiler 实例
// 如果不传 cb 函数作为第二个参数,就会返回一个 compiler 实例用于控制启动
const compiler = webpack(config);
const watching = compiler.watch(
{
// watchOptions
aggregateTimeout: 300,
},
(err, stats) => {
// 每次重新构建后
}
);
watching.close(() => {
// 关闭后回调函数
});使用 webpack Dev Middleware
devServer 其实是基于 webpack-dev-middleware 和 express 实现的,webpack-dev-middleware 其实是 express 的一个中间件
实现 devServer 的大致代码
const express = require("express");
const webpack = require("webpack");
const webpackMiddleware = require("webpack-dev-middleware");
const config = require("./webpack.config.js");
const app = express();
const compiler = webpack(config);
app.use(webpackMiddleware(compiler));
app.listen(3000); // 监听 3000 端口webpackMiddleware 函数返回一个 express 中间件,该中间件有以下功能
- 接受来自 webpack compiler 实例输出的文件,但不会将文件输出到硬盘,而是保存在内存中
- 在 express 上注册路由,拦截 http 请求,根据请求相应对应的文件内容
通过 webpack-dev-middleware 可以将 devServer 集成到现有的 http 服务器中
webpack dev middleware 支持的配置项
app.use(
webpackMiddleware(compiler, {
publicPath: "/assets/", // 必填
noInfo: false, // 不输出任何 info 类型的日志到控制台
quiet: false, // 不输出任何类型的日志到控制台
lazy: true, // 在有请求时编译对应的文件
watchOptions: {
// 非懒惰模式下有效
aggregateTimeout: 300,
poll: true,
},
index: "index.html", // 默认 url 路径,默认值为 index.html
headers: { a: "yes" }, // 自定义 http 头
mimeTypes: { "text/html": ["phtml"] }, // 为特定后缀的文件添加 http mimeType,作为文件类型映射表
stats: {
//统计信息输出样式
colors: true,
},
reporter: null, // 自定义输出日志展示方法
serverSideRender: false, // 开启或关闭服务端渲染
})
);热模块替换
devServer 提供的一个便捷功能,但是 webpack-dev-middleware 没有实现该功能,而是由 devServer 自己实现的
如果需要实现我们还需要接入 webpack-hot-middleware
const HotModuleReplacementPlugin = require("webpack/lib/HotModuleReplacementPlugin");
module.exports = {
entry: ["webpack-hot-middleware/client", "./src/main.js"],
output: {
filename: "bundle.js",
},
plugins: [new HotModuleReplacementPlugin()],
devtool: "source-map",
};const express = require("express");
const webpack = require("webpack");
const webpackMiddleware = require("webpack-dev-middleware");
const config = require("./webpack.config.js");
const app = express();
const compiler = webpack(config);
app.use(webpackMiddleware(compiler));
app.use(require("webpack-hot-middleware")(compiler));
app.use(express.static(".")); // 将根目录作为静态资源目录,用于服务 html 文件
app.listen(3000, () => console.log("成功部署")); // 监听 3000 端口最后在入口文件(main.js)最后加入以下代码:
if (module.hot) {
module.hot.accept();
}加载图片
使用 file-loader
该 loader 可以将 JavaScript 和 css 中导入图片的语句替换成正确的地址,同时将文件输出到对应位置
例如 css 中的 url(./images/a.png) 会被转换成 url(fjasldfjlaksfj2234234.png)
在输出的目录中会有相对应解析的图片文件,文件名可以是根据内容得出的 hash 值
同理,在 JavaScript 导入的图片也会被解析
使用 file-loader 只需要配置 module.rules 就行
使用 url-loader
该 loader 可以将文件的内容经过 base64 编码后注入 JavaScript 或者 css 中
但是如果图片过大就会导致相应的 css 文件或者 JavaScript 文件变大,导致网页加载缓慢
所以 url-loader 也提供了 limit 配置,用于在超出规定大小文件才使用 url-loader,否则使用 fallback 选项中的 loader
除此之外还可以压缩图片,制作雪碧图等
加载 SVG
svg 作为矢量图已经被各大浏览器所支持,用 svg 代替位图有以下好处:
- svg 比位图更清晰,在任意缩放的情况下都不会破坏图形的清晰度
- svg 文件的大小小于位图,大多数情况下是这样的
- 图形相同的 svg 比对应的高清图有更好的渲染性能
- svg 采用和 html 一致的 xml 语法描述,灵活性更高
svg 的使用和普通图片没有差异,loader 也只需要添加相应的 test 就行
使用 raw-loader
raw-loader 可以将文本文件的内容读取出来,注入 JavaScript 或 css 中
例如:import svgContent from "./svg/a.svg";,这样输出的 svgContent 就会是 svg 的内容(<svg ...>...</svg>)
但是这样导致 css 文件中不能直接使用 svg 文件了
使用 svg-inline-loader
和 raw-loader 很相似,不过该插件会分析 svg 内容,去除其中不必要的代码
加载 Source Map
控制 source map 输出的 webpack 配置项是 devtool,它有很多值
| devtool | 含义 |
|---|---|
| 空 | 不生成 source map |
| eval | 每个 module 会封装到 eval 里包裹起来执行,并且每个 eval 语句的末尾都会追加注释 |
| source-map | 会额外生成一个单独的 source map 文件,并且会在 JavaScript 文件的末尾追加注释 |
| hidden-source-map | 和 source-map 类似,但不会在 JavaScript 文件的末尾追加注释 |
| inline-source-map | 和 source-map 类似,但不会额外生成一个单独的 source map 文件,而是将 source map 转换成 base64 编码内嵌到 JavaScript 中 |
| eval-source-map | 和 eval 类似,但会将每个模块的 source map 转换成 base64 编码内嵌到 eval 语句的末尾 |
| cheap-source-map | 和 source-map 类似,但生成的 source map 文件中没有列信息,因此生成速度更快 |
| cheap-module-source-map | 和 cheap-source-map 类似,但会包含 loader 生成的 source map |
以上只是其中的一部分,它的取值可以由 source-map、eval、inline、hidden、cheap、module 六个关键字随意组合而成,六个关键字每一种都代表一个特性:
- eval:用 eval 语句包裹需要安装的模块
- source-map:生成独立的 source map 文件
- hidden: 不在 JavaScript 文件中指出 source map 文件所在,这样浏览器不会自动加载 source map
- inline:将生成的 source map 转换成 base64 格式内嵌在 JavaScript 文件中
- cheap: 在生成的 source map 中不会包含列信息,这样计算量更小,输出文件更小,同时 loader 输出的 source map 不会被采用
- module: 来自 loader 的 source map 被简单处理成每行一个模块
如何选择
推荐在开发环境下使用:cheap-module-eval-source-map
推荐在生产环境下使用:hidden-source-map
生产环境下通常不会将 source map 上传到服务器上,而是上传到 JavaScript 错误收集系统,在错误收集系统上根据 source map 和收集到的 JavaScript 运行错误堆栈,计算错误所在源码位置
不要再生产模式下使用 inline 模式,这样会使 JavaScript 文件变得很大,而且会泄露源码
加载现有的 source map
很多时候第三方包中会附带对应的 source map 文件
默认情况下,webpack 不会加载这些附加的 source map 文件,我们需要安装 source-map-loader
module.exports = {
module: {
rules: [
{
test: /\.js$/,
include: [path.resolve(root, "node_modules/a")],
use: ["source-map-loader"],
enforce: "pre", // 要将执行顺序放到最前面,如果在之前有 loader 转换了 JavaScript 文件,就会导致 source map 错误
},
],
},
};source-map-loader 在加载 source map 时计算量很大,因此要避免 loader 处理过多的文件,不然会导致构建速度缓慢
优化
缩小文件搜索范围
webpack 从 entry 出发递归解析文件,在遇到导入语句时,webpack 会做两件事情:
- 根据导入语句寻找对应的要导入的文件
- 根据找到的要导入的文件后缀,使用 loader 处理
上述两件事在较小项目会很快,但是在项目大了以后文件量会变得非常大,这时候构建慢的问题就会暴露出来
优化 Loader 配置
由于 loader 操作很耗时,所以需要让尽量少的文件被 loader 处理
可以通过 test、include、exclude 三个配置来命中文件
优化 resolve.modules 配置
该配置用于 webpack 去哪些目录下寻找第三方模块
默认值是 ['node_modules'],优先在当前目录寻找 node_modules 目录,没找到再去上级目录寻找,再没找到再上一级以此类推......
当安装的第三方模块都在项目的根目录 ./node_modules 目录下时,就没有必要按照默认方式一层层的去寻找,可以指明绝对路径,减少没有必要的寻找
resolve: {
modules: [path.resolve(__dirname, "node_modules")];
}优化 resolve.mainFields 配置
用于配置第三方文件使用哪个入口文件
在 package.json 中有多个入口文件,因为一个第三方包可能会需要适配多个环境
该配置的值和当前的 target 配置有关系
- 当 target 为 web 或者 webworker 时,值是
['browser', 'module', 'main'] - 当 target 为其他情况时,值是
['module', 'main']
webpack 会按照配置顺序搜索模块入口文件
我们可以手动设置模块入口文件,不过如果有一个模块不是使用该入口文件的话,就会造成构建出的代码无法正常运行
优化 resolve.alias 配置
例如我们使用 react 的时候会发现 node_modules 目录下的 react 文件夹中包含两套代码、
|-- dist
| |-- react.js
| |-- react.min.js
|-- lib
| |-- ...
|-- package.json
|-- react.js- 一套是采用 commonjs 规范的模块化代码,都放在 lib 目录下,以 package.json 中指定的 react.js 为入口文件
- 一套是将所有代码打包好完整代码的单独文件,有 react.js 以及 react.min.js 文件,前者用于开发环境,里面包含检查和警告的代码;后者用于线上环境,被最小化了
默认情况下,webpack 会从 react 根目录的 react.js 文件开始递归和解析处理依赖文件,通过配置可以直接定位打包好的 react.min.js 文件从而跳过递归和解析的操作,简化时间消耗
但是,使用该方法后,我们的 tree-shaking 除去无效代码的优化将会被影响,因为打包好的完整代码中有的部分我们可能用不上,一般我们对整体性较强的库使用本方法优化
优化 resolve.extensions 配置
对于没有后缀类型的文件,webpack 会根据这个配置尝试访问文件是否存在
但是我们尽量将出现次数多的后缀放到前面,尽快退出寻找过程;将不可能出现的文件从列表中移除;尽可能在源码中带上后缀
优化 module.noParse 配置
该配置可以忽略部分没有采用模块化文件的处理,提高构建性能
例如 jQuery,ChartJS 庞大又没有采用模块化标准
module: {
noParse: [/react\.min\.js$/];
}被忽略的文件不应该包含 import、require、define 等模块化语句
使用 DllPlugin
认识 DLL
用过 windows 系统的人经常会看到以 .dll 为后缀的文件,这些文件叫动态链接库,在一个动态链接库中可以包含为其他模块调用的函数和数据
要为 web 项目构建接入动态链接库的思想,需要完成以下事情:
- 将网页依赖的基础模块抽离出来,打包到一个个单独的动态链接库中,在一个动态链接库中可以包含多个模块
- 当需要导入的模块存在于某个动态链接库中时,这个模块不能被再次打包,而是去动态链接库中获取
- 页面依赖的所有动态链接库都需要被加载
因为包含大量复用模块的动态链接库只需要被编译一次,在之后的构件中被动态链接库包含的模块将不会重新编译,而是直接使用动态链接库中的代码,动态链接库中的模块通常是常用的第三方模块,例如 react,只要不升级这些模块的版本,动态链接库就不需要更新
接入 webpack
webpack 已经内置了对动链接态库的支持,只需要通过以下两个内置插件接入
- DllPlugin 插件:用于打包出一个个单独的动态链接库文件
- DllReferencePlugin 插件:用于在主要的配置文件中引入 DllPlugin 插件打包好的动态链接库文件
以 react 项目为例,接入 DllPlugin,构建出的项目最终结构:
|-- main.js
|-- polyfill.dll.js
|-- polyfill.manifest.json
|-- react.dll.js
|-- react.manifest.json其中包含两个动态链接库文件:
- polyfill.dll.js:包含项目所有依赖的 polyfill,例如 promise、fetch 等
- react.dll.js:包含 react 基础运行环境,即 react 和 react-dom 模块
例如:
var _dll_react = (function (modules) {
// ... webpackBootstrap 函数代码
})([
function (module, exports, __webpack_require__) {},
function (module, exports, __webpack_require__) {},
// ...
]);一个动态链接库包含大量模块代码,这些模块被存放在一个数组里,通过数组的索引号作为 ID,通过 _dll_react 变量将自己暴露在全局中,通过 window._dll_react 访问到其中包含的模块
manifest.json 文件也是由 DllPlugin 生成的,用于描述在动态链接库文件中包含哪些模块,例如:
{
"name": "_dll_react",
"content": {
"./node_modules/process/browser.js": {
"id": 0,
"meta": {}
}
// ...
}
}最后我们需要在 index.html 中引入相关 dll.js 依赖,因为最后我们的代码中需要调用模块的地方会直接使用 window._some_name[2]
1、构建动态链接库文件
dll.js 文件和 manifest.json 文件需要由一份独立的构建输出,用于主构建使用,所以我们需要新建一个 webpack_dll.config.js 专门用于构建它们:
const path = require("path");
const DllPlugin = require("webpack/lib/DllPlugin");
module.exports = {
entry: {
react: ["react", "react-dom"],
polyfill: ["core-js/fn/object/assign", "core-js/fn/promise", "whatwg-fetch"],
},
output: {
filename: "[name].dll.js",
path: path.resolve(__dirname, "dist"),
library: "_dll_[name]",
},
plugins: [
new DllPlugin({
name: "_dll_[name]", // 需要和 output.library 保持一致
path: path.join(__dirname, "dist", "[name].manifest.json"), // manifest.json 文件输出的文件名及路径
}),
],
};2、使用动态链接库文件
const path = require("path");
const DllReferencePlugin = require("webpack/lib/DllReferencePlugin");
module.exports = {
entry: {
main: "./main.js",
},
output: {
filename: "[name].js",
path: path.resolve(__dirname, "dist"),
},
module: {
rules: [
{
test: /\.js$/,
use: ["babel-loader"],
exclude: path.resolve(__dirname, "node_modules"),
},
],
},
plugins: [
new DllReferencePlugin({
manifest: require("./dist/react.manifest.json"),
}),
new DllReferencePlugin({
manifest: require("./dist/polyfill.manifest.json"),
}),
],
devtool: "source-map",
};3、执行构建
我们要先执行动态链接库的编译,再执行主文件的编译;如果动态链接库文件已经存在且不需要升级则可以直接编译主文件
使用 HappyPack
构建操作是文件读写和计算密集型操作,特别是当文件数量变多之后,webpack 构建慢的问题将会边得更为严重。运行在 node.js 之上的 webpack 是单线程模型,也就是说 webpack 需要一个个的处理任务
那有没有方法让 webpack 同时处理多个任务呢,HappyPack 就能让 webpack 做到这一点,他将任务分解给多个子进程去并发执行,子进程处理完后再将结果发送给主进程
由于 js 是单线程模型,所以要发挥多核 cpu 功能,就只能通过多进程实现
上述观点本人存疑,worker threads 不能实现吗?
使用 HappyPack
对于分解任务和管理进程的事情,HappyPack 会帮我们管理好,我们只需要接入 HappyPack,相关代码如下:
const path = require("path");
const ExtractTextPlugin = require("extract-text-webpack-plugin");
const HappyPack = require("happypack");
module.exports = {
module: {
rules: [
{
test: /\.js$/,
use: ["happypack/loader?id=babel"],
exclude: path.resolve(__dirname, "node_modules"),
},
{
test: /\.css$/,
use: ExtractTextPlugin.extract({
use: ["happypack/loader?id=css"],
}),
},
],
},
plugins: [
new HappyPack({
id: "babel",
loaders: ["babel-loader?cacheDirectory"],
// ... 其它配置项
}),
new HappyPack({
id: "css",
loaders: ["css-loader"],
// ... 其它配置项
}),
new ExtractTextPlugin({
filename: "[name].css",
}),
],
};在实例化 HappyPack 插件时,除了可以传入 id 和 loaders 两个参数,HappyPack 还支持传入如下参数:
- threads:代表开启几个子进程处理这一类型的文件,默认是 3 个
- verbose:是否允许 HappyPack 输出日志,默认是 true
- threadPool:代表共享进程池,多个 HappyPack 实例都使用同一个共享进程池中的子进程去处理任务,防止资源占用过多
const HappyPack = require("happypack");
const happyThreadPool = HappyPack.ThreadPool({ size: 5 });
module.exports = {
plugins: [
new HappyPack({
id: "babel",
loaders: ["babel-loader"],
threadPool: happyThreadPool,
}),
],
};HappyPack 原理
在整个 webpack 构建流程中,最耗时的流程可能就是 loader 对文件的转换操作了,因为要转换文件的数据量巨大,而且只能一个个去处理
而 HappyPack 每通过实例化一个 HappyPack,其实就是告诉 HappyPack 核心调度器如何通过一系列 loader 去转换一类文件,并且可以指定如何为这类转换操作分配子进程
核心调度器的逻辑代码在主进程中,也就是运行着 webpack 的进程中
使用 ParallelUglifyPlugin
我们发布到线上版本的代码一般都有代码压缩这一流程,最常见的 JavaScript 代码压缩工具是 UglifyJS,并且 webpack 也内置了它
当我们在构建线上代码时,uglifyJS 会占用较大一部分时间,因为压缩 js 代码需要分析语法树,再应用各种规则分析和处理 AST,所以这个计算量巨大
同样的,我们可以按照上节所说,使用多进程并行处理,parallelUglifyPlugin 就是用来做这个工作的
module.exports = {
plugins: [
new ParallelUglifyPlugin({
uglifyJS: {
output: {
beautify: false, // 最紧凑的输出
comments: false, // 删除所有注释
},
compress: {
warning: false, // 在 UglifyJS 删除没有用到的代码时不输出警告
drop_console: true, //删除所有 console 语句,可以兼容 IE 浏览器
collapse_vars: true, // 内嵌已经用到但是只使用一次的变量
reduce_vars: true, // 提取出出现多次但是没有定义成变量去引用的静态值
},
},
}),
],
};配置:
- test:使用正则去匹配哪些文件需要被 ParallelUglifyPlugin 压缩,默认
/.js$/ - include:使用正则命中需要被压缩的文件,默认
[] - exclude:使用正则排除不需要被压缩的文件,默认
[] - cacheDir:缓存压缩后的结果,遇到同样的输出直接从缓存中获取压缩后的结果并返回,该选项用于配置路径
- workerCount:开启几个子进程去并发执行压缩,默认为当前运行的计算机 CPU 核数减一
- sourceMap:boolean
- uglifyJS:用于压缩 ES5 代码时的配置,会原封不动的传递给 UglifyJS 作为参数
- uglifyES:用于压缩 ES6 代码时的配置,会原封不动的传递给 UglifyES 作为参数
UglifyES 是 uglifyJS 的变种,专门用于压缩 ES6 代码,他们都出自同一个项目并且不能同时使用
uglifyES 一般用于为比较新的 js 运行环境压缩代码,例如 reactnative 的代码运行在兼容性较好的 JavaScriptCore 引擎中
parallelUglifyPlugin 同时内置了 UglifyJS 和 UglifyES
使用自动刷新
对于开发时我们做的修改,需要及时刷新浏览器重新运行最新代码,虽然这个相对于开发原生 IOS 和 Android 应用来的方便,但是我们可以将这个体验优化的更好,借助自动化操作我们能让 webpack 监听源码的变动后自动重构并控制浏览器刷新
幸好,webpack 这些功能都内置了
文件监听
文件监听是在源码文件发生变化时自动构建出新的输出文件
webpack 提供了两大模块,一个是核心的 webpack,一个是 webpack-dev-server,而监听文件的功能是 webpack 提供的
1、文件监听工作原理
webpack 监听一个文件变化的原理,是定时获取这个文件最后编辑时间,每次都缓存这个最新编辑时间,如果发现当前获取的和最后一次保存的最后编辑时间不一致,就认为该文件发生了变化,watchOption.poll 选项用于控制指定检查的周期(详细信息前文有)
当某个文件发生变化时,并不会立刻告诉监听者,而是先缓存起来,收集一段时间的变化后,再一次性告诉监听者,watchOption.aggregateTimeout 用于配置这个时间,原因是我们编辑代码的过程中高频的输入文字,导致文件变化过快,每次都执行构建的话就会让构建卡死
当有多个文件时,会对列表中每个文件都进行检查,但首先我们需要确定这个监听列表,在默认情况 webpack 会从 配置的 entry 文件出发,递归解析 entry 文件所依赖的文件,将这些文件都加入监听列表中(而不是粗暴的直接监听整个目录)
由于保存文件路径以及最后编辑的时间需要占用内存,定时检查周期检查需要占用 cpu 和 文件 I/O,所以最好减少需要监听的文件数量和降低检查频率
2、优化文件监听的性能
因为默认情况下会监听配置的 entry 文件以及所有 entry 递归依赖的文件,在这些文件中会有很多存在于 node_modules 下,如今的 web 项目会依赖大量的第三方模块,但大多数情况下我们不回去编辑 node_modules 下的文件,而是编辑自己建立的源码文件,所以我们可以忽略 node_modules 下的文件
这样后,webpack 消耗的内存和 CPU 将会大大减少
自动刷新浏览器
监听文件更新后下一步就是刷新浏览器,webpack 模块负责监听文件,webpack-dev-server 模块去启动 webpack 模块时,webpack 模块的监听模式会被默认开启,webpack 模块会在文件发生变化时通知 webpack-dev-server 模块
1、自动刷新的原理
控制浏览器刷新有三种方法:
- 借助浏览器扩展去通过浏览器提供的接口刷新,webstorm ide 的 liveEdit 功能就是这样实现的
- 向要开发的网页中注入代理客户端代码,通过代理客户端去刷新整个页面
- 将要开发的网页装进一个 iframe 中,通过刷新 iframe 去看到最新效果
devServer 支持第 2、3 种方法,第 2 种是 devServer 默认采用的刷新方法
在浏览器开发工具中我们也可以看到由代理客户端向 devServer 发起的 websocket 连接
2、优化自动刷新的性能
devServer.inline 配置项用于控制是否向 chunk 中注入代理客户端,默认会注入
事实上,在开启 inline 时,devServer 会向每个输出的 chunk 中注入代理客户端的代码,当我们项目需要很多 chunk 时,就会导致构建缓慢
其实要完成自动刷新,一个页面只需要一个代理客户端,devServer 之所以暴力的给每个 chunk 都注入,是因为它不知道某个网页依赖哪几个 chunk,索性全部都注入
优化思路首先要关闭不够优雅的 inline 模式,只注入一个代理客户端
这样网页入口就变成了代理路由,chunk 中不再包含代理客户端代码
要开发的网页被放入了一个 iframe 中,如果不想以 iframe 方法去访问,我们需要手动向网页中注入代理客户端脚本,向 index.html 中插入以下标签:
<script src="http://localhost:8080/webpack-dev-server.js"></script>这样后独立打开的网页就可以自动刷新了,但发布到线上时注意删除这段代码
开启模块热替换
为了做到实时预览,除了可以使用刷新整个网页,还可以使用热模块替换,原理是在一个源码发生变化时,只需要重新编译发生变化的模块,再用新输出的模块替换掉浏览器中对应的老模块
另外,热模块替换反应更快,等待时间更短;而且不刷新浏览器就能保留当前运行状态,例如 vuex 和 redux 在发生热模块替换时数据可以不受影响
热模块替换原理
和自动刷新原理相同,也要向页面注入一个代理客户端
devServer 默认不会开启热模块替换,要开启,只需要在启动时带上参数 --hot(从 webpack-dev-server v4.0.0 开始,热模块替换是默认开启的)
除了通过启动时参数,还可以通过接入 plugin 实现:
const HotModuleReplacementPlugin = require("webpack/lib/HotModuleReplacementPlugin");
module.exports = {
entry: {
// 为每个入口都注入一个代理客户端(书本配置,webpack3)
// main: ['webpack-dev-server/client?http://localhost:8080', 'webpack/hot/dev-server.js', './src/index.js'],
// 或者(官网配置,webpack5)
app: "./src/index.js",
hot: "webpack/hot/dev-server.js", // Runtime code for hot module replacement
client: "webpack-dev-server/client/index.js?hot=true&live-reload=true", // Dev server client for web socket transport, hot and live reload logic
},
plugin: [
new HotModuleReplacementPlugin(), // 该插件的作用就是实现热模块替换,若启动时带上参数,就会注入该插件,生成 .hot-update.json
],
devServer: {
// (webpack3)
// hot: true
// 或者 (webpack5)
hot: false,
client: false,
},
};webpack5 已经不再需要这么复杂的处理了,上述 webpack5 配置是适用于自定义 HMR 入口,通常我们没有必要这样做,可以一步到位:
module.exports = {
devServer: {
hot: true,
},
};与自动刷新的代理客户端相比,最后构建日志多出了三个用于模块热替换的文件,代理客户端更大了
然后我们需要在 index.js 文件里加入热模块替换逻辑:
// ...
if (module.hot) {
module.hot.accept(["./AppComponent"], () => {
render(<AppComponent />, window.document.getElementById("app"));
});
}module.hot 是开启热模块替换后注入全局的 API
但是我们修改 index.js 时,网页还是刷新了,这是因为在子模块更新时,更新事件会一层层向上传递,直到有某层文件接收了当前变化的模块,这个时候就会执行传入的 cb 函数,如果一直往上抛出直到最外层都没有文件接收它,则会直接刷新网页
至于修改 css 文件能够使用模块热替换,是因为 style-loader 会注入用于接收 css 的代码
优化模块热替换
模块替换时我们能在控制台上看到相关日志,但是日志指出的模块 id 并不友好,我们可以使用 webpack 内置的 NamedModulesPlugin 插件解决该问题
const NamedModulesPlugin = require("webpack/lib/NamedModulesPlugin");
module.exports = {
plugins: [new NamedModulesPlugin()],
};除此之外,模块热替换也需要监听文件变化和注入客户端,优化方式也差不多类似,监听更少的文件(忽略 node_modules 目录下的文件),但是关闭 inline 模式手动注入代理客户端的方法,不能用于模块热替换的情况,因为模块热替换的运行依赖在每个 chunk 中都包含代理客户端
区分环境
为什么要区分环境
开发网页时,一般都有多套运行环境
既要压缩线上环境代码,也要去除线上环境控制台日志输出,更要分离线上和开发环境链接地址
如何区分环境
具体区分方法很简单,在源码中通过 process.env.NODE_ENV === 'production' 即可
当代码中出现了使用 process 模块的语句时,webpack 会自动打包进 process 模块的代码以支持非 node 运行环境
构建线上环境代码时,需要为当前的运行环境设置环境变量 NODE_ENV,但是网页中并不存在环境变量,注入 process 模块又会增大代码体积,所以需要使用相关 plugin:
const DefinePlugin = require("webpack/lib/DefinePlugin");
module.exports = {
plugins: [
new DefinePlugin({
// 'process.env': {
// NODE_ENV: JSON.stringify('production')
// }
// 但是官方更建议下面这种方式,因为前者会覆盖 process.env 对象,这可能会破坏与某些模块的兼容性
"process.env.NODE_ENV": JSON.stringify("production"),
}),
],
};请注意,由于本插件会直接替换文本,因此提供的值必须在字符串本身中再包含一个 实际的引号 。通常,可以使用类似
'"production"'这样的替换引号,或者直接用JSON.stringify('production')
构建后的代码中判断语句将会直接变成 true 或者 false,这样也不需要去注入 process 模块
definePlugin 定义的环境变量只对 webpack 需要处理的代码有效,而不会影响 node.js 运行时环境变量的值
我们也可以通过 shell 脚本定义环境变量,但是这样定义的环境变量对 webpack 处理代码中环境区分语句没有任何作用
如果想要 webpack 通过 shell 脚本的方式定义环境变量,可以使用 environmentPlugin:new webpack.EnvironmentPlugin(['NODE_ENV'])
结合 UglifyJS
处理了判断语句后其实在代码中还是会留有两种判断的分支存在,应该直接按照判断语句保留运行的一部分,其他部分可以除去,这部分的工作可以交由 uglifyJS 实现
关于这点后一节说明
第三方库中的环境区分
除了自己的源码有环境区分,很多第三方库也做了环境区分的优化,例如 react 和 vue,在其源码中有大量环境变量判断语句
如果不定义环境变量,这些判断语句中所有的分支都将会打包进输出的代码中,这将会是一个灾难
压缩代码
浏览器访问网页时获取的 JavaScript、css 等资源都是文本形式的,文件大小直接影响网页加载的时间
我们可以选择压缩资源,减少文本大小,然后再使用 gzip 算法压缩文件
压缩文本除了可以减少大小,还可以混淆源码,提升我们代码的安全性
压缩 JavaScript
uglifyjs 是目前(webpack3 时代,webpack5 更倾向于 terser-webpack-plugin)较为成熟的压缩工具,他会分析代码语法树,去除无效代码和日志输出代码,缩短变量名等
有两个插件支持了我们使用:
- UglifyJsPlugin
- ParallelUglifyPlugin
前文已经解释过两者插件,这里我们介绍配置 uglifyJS 达到最优压缩效果
我们了解常用的几个选项:
- sourceMap:默认不生成
- beautify:是否输出可读性较强的代码,即会保留空格和制表符,默认开启
- comments:是否保留代码中的注释,默认为保留
- compress.warnings:是否在插件删除没有用到的代码时输出警告信息,默认为输出
- drop_console:是否删除代码中 console 语句,默认不删除
- collapse_vars:是否内嵌只使用到一次的变量,默认不开启
- reduce_vars:是否提取出现多次的静态值,默认不转换
webpack 内置了 uglifyJsPlugin(webpack5 内置了 terser-webpack-plugin)
同时 webpack 还提供了一个更加简便的方法来接入,即在启动时添加参数 --optimize-minimize
压缩 ES6
我们在运行环境允许下,可以尽量使用 ES6 代码运行,这样我们的代码量和运行速率上会有较大提升(许多引擎已经针对 ES6 语法做了相关优化)
我们压缩 ES6 代码时,会发现上述 uglifyJS 不支持 ES6 语法,这时我们就要使用 uglifyES 去进行压缩
接入时我们需要单独安装 uglifyjs-webpack-plugin
同时我们需要去掉 babel 对源码的处理(例如输出 ES5)
压缩 CSS
比较可靠的压缩工具是 cssnano,基于 postCSS
cssnano 能解析代码的语法,而不是简简单单去掉空格
因为 css-loader 内置了,所以我们要开启只需要配置 loader 的 minimize 选项
CDN 加速
什么是 CDN
虽然我们减少了加载的代码内容大小,但最影响用户的还是首次加载时的等待,其根本原因是网络传输过程耗时太大
cdn 的作用是将内容部署到世界各地,用户按照就近原则获取服务器资源
接入 CDN
要为网站接入 cdn 就需要将静态资源上传到 cdn 服务上,访问这些静态资源时需要通过 cdn 服务提供的地址去访问
因为一般 cdn 服务都会开启资源缓存,这个时间一般不短,所以我们最好不要将 html 文件放入 cdn 缓存中,对于静态的 JavaScript、css、图片等文件我们需要开启缓存,同时为每个文件带上由文件内容算出的 hash 值(这样只要文件变化了其对应的 url 一定会变,就一定会被重新下载)
然后我们需要将 html 中的资源地址换成 cdn 地址,但是浏览器对于同一个域名的资源的并行请求有数量限制,我们不能只将所有的资源放在同一个 cdn 下,我们尽可能需要将不同的资源分散到不同的 cdn 上,这样可以在一定程度上加快资源请求速度(但是过多的域名又会增加域名解析时间,所以这个度我们要自己衡量,还可以通过添加 <link rel="dns-prefetch" href="//js.cdn.com">)
用 webpack 实现 CDN 接入
我们需要做到几点:
- 静态资源的 url 要指向 cdn 服务,而不是相对路径
- 静态资源需要借助 hash 值来防止被无效缓存
- 将不同类型的资源放到不同域名的 cdn 上
最终配置:
module.exports = {
// ...
output: {
filename: "[name]_[chunkhash:8].js",
path: path.resolve(__dirname, "./dist"),
publicPath: "//js.cdn.com/id/",
},
module: {
rules: [
{
test: /\.css$/,
use: ExtractTextPlugin.extract({
use: ["css-loader?minimize"],
publicPath: "//img.cdn.com/id/", // 指定 css 中导入资源的 cdn
}),
},
{
test: /\.png$/,
use: ["file-loader?name=[name]_[hash:8].[ext]"],
},
// ...
],
},
plugins: [
new WebPlugin({
template: "./template.html",
filename: "index.html",
stylePublicPath: "//css.cdn.com/id/", // 指定 css 的 cdn
}),
new ExtractTextPlugin({
filename: "[name]_[contenthash:8].css",
}),
],
// ...
};使用 Tree Shaking
认识 Tree Shaking
tree shaking 可以用来剔除 js 中用不上的代码,它依赖 es6 模块化语法
例如 utils.js 文件中有两个函数,但是 main.js 文件中只使用了一种,tree shaking 后 utils.js 文件中没有用到的代码就会被去除
要让 tree shaking 正常工作,js 代码必须采用 es6 模块化语法
接入 tree shaking
我们首先要将代码输出改为 es6 模块化,为此我们需要配置 babel 让其保留 es6 模块化语句
{
"presets": [
[
"env",
{
"modules": false // 关闭 babel 转换功能
}
]
]
}之后,我们可以在启动 webpack 时附带上 --display-used-exports 参数,以方便追踪 tree shaking 的工作,这时我们可以看到控制台相关输出,webpack 确实分析出了代码逻辑,但是无用代码并没有被剔除
想要移除代码,我们可以通过 uglifyJS 来实现,也可以附带启动参数来实现
但是当项目中大量第三方库中都采用 commonJS 语法时,tree shaking 则会无法正常工作,所以一般的第三方库会带有两份代码,一份 cjs,一份 es6,在 package.json 文件中会配置两种入口
我们可以通过配置 mainFields 来优先使用 es6 模块入口文件
提取公共代码
为什么要提取公共代码
大型网站通常由多个页面组成,每一个页面都是一个独立的单页应用,但由于所有页面都采用同样的技术栈以及同一套代码,所以这些页面之间会有很多相同的代码
我们可以将其公共代码抽离成单独的文件,这样浏览器缓存后在下一次访问时可以直接读取缓存数据
如何提取公共代码
多页应用提取代码原则:
- 将所有公共的基础库(例如 react 技术栈中的 react、react-dom)提取到单独的 base.js
- 去除 base.js 的代码后所有页面所依赖的公共部分代码提取到 common.js
- 最后为每个网页生成单独文件,只包含该网页需要的代码
为什么将页面都依赖的方法提取到 common.js 中,但是基础库却另外放到 base.js 中呢?
是因为基础库一般不会频繁更新,这样基础库输出的文件 hash 就不会变化,可以被浏览器长期缓存,并且基础库大小一般会比较大,这样有利于优化网页性能;而 common.js 更新频率更高,所以两者需要分开
如何通过 webpack 提取公共代码
webpack 内置了用于提取多个 chunk 中的公共部分插件 commonsChunkPlugin
module.exports = {
// ...
plugins: [
new CommonsChunkPlugin({
chunks: ["a", "b"], // 从 chunk 中提取
name: "common", // 提取出的公共部分 chunk 名
}),
],
};每个该插件实例都会生成一个新的 chunk,如果不配置 chunks 属性则默认会从所有 chunk 中提取
在此之后,我们需要再从 common.js 中提取基础库到 base.js
首先我们需要配置一个单独的 chunk,这个 chunk 中只依赖基础库以及公共样式
import "react";
import "react-dom";
import "./base.css";然后为 base 添加 entry 配置
module.exports = {
entry: {
base: "./base.js",
},
};然后为了提取公共部分,我们新增一个 commonsChunkPlugin,用来提取 common chunk 和 base chunk 中的公共部分放到 base 中
由于 common 和 base 的公共部分就是 base 本身,所以提取后 common.js 会变小
但是我们在 html 中的导入顺序就要严格按照 base、common、a/b.js
针对 css 资源,以上理论和方法同样有效
但是采用以上方法后很容易出现 common.js 没有内容的情况,原因是去掉基础运行库后很难找到各个页面公用的模块,我们可以这样做:
- commonsChunkPlugin 提供了一个选项 minChunks,表示文件要被提取出来时需要在指定的 chunks 中出现的最小次数,例如设置为 2,chunks = ['a', 'b', 'c', 'd'] 时,只要文件在其中两个或以上的 chunk 中出现,就会被提取出来
- 根据页面的依赖性来提取部分页面的公共部分,而不是全部页面;这样的操作可以进行多次,但是没有通用性
分割代码以按需加载
为什么需要按需加载
当网页较大时,所有资源都在初始化时加载会导致页面加载缓慢,分割代码后可以按照需要加载相应代码,也就是叫按需加载
如何使用
在为单页应用做按需加载优化时,一般采用以下原则:
- 将整个网站划分成一个个小功能,再按照每个功能的相关程度将他们分为几类
- 将每一类合并为一个 chunk,按需加载对应的 chunk
- 不要按需加载用户首次打开网站时需要的相关功能,将其放入执行入口所在的 chunk 中
- 对于不依赖大量代码的功能点,例如依赖 Chart.js 画图表的功能,可以对其进行按需加载
被分割出去的代码一定要有时机去触发,尽可能让用户感知不到加载存在
用 webpack 实现按需加载
webpack 内置了强大的功能,例如:
div.addEventListener("click", () => {
import(/* webpackChunkName: "show" */ "./show").then((show) => show("a"));
});webpack 会去解析 import(*),这告诉了 webpack 以 ./show.js 文件重新生成一个 chunk,当代码执行到 import 语句时才去加载由 chunk 生成的文件,import() 返回一个 promise,可以在 then 中获取导出的内容
因为依赖了 import(*),所以浏览器需要支持 promise,不然就要注入 promise polyfill
为了正确应用在注释语句中配置的 chunk 名,我们还要在 output 中配置
module.exports = {
output: {
filename: "[name].js", // 为从 entry 中配置生成的 chunk 配置输出文件名称
chunkFilename: "[name].js", // 为动态加载的 chunk 配置输出文件名称
},
};如果没有为动态生成的 chunk 配置 filename,则生成的文件名将会是 [id].js
按需加载与 ReactRouter
代码部分查看书上 p212
由于我们的代码需要通过 babel 转换后才能在浏览器中正常运行,所以源码会先由 babel-loader 处理后再交由 webpack 处理,但是 babel 并不认识 import(*) 语法(但是现在应该认识了),所以我们需要安装一个插件 babel-plugin-syntax-dynamic-import 并修改 babel 配置
使用 Prepack
认识 Prepack
前面的代码压缩和分块都是在网络层面的优化,除此之外我们还可以优化运行时的效率
实际上,prepack 就是一个部分求值器,编译代码时提前将计算结果放到编译后的代码中
例如:
function hello(name) {
return "hello" + name;
}
class Button extends Component {
render() {
return hello(this.props.name);
}
}
console.log(renderToString(<Button name="webpack" />));最后会直接被输出 console.log("hello webpack")
prepack 大致工作流程如下:
- 通过 babel 将 js 源码解析成抽象语法树
- prepack 实现了一个 js 解释器,用于执行源码,借助这个解析器,prepack 才能理解源码是如何执行的,并将执行过程中的结果返回到输出中
当前 prepack 还处于开发阶段,并且 facebook 已经不维护了(如今)
接入 webpack
我们需要使用 prepack-webpack-plugin,然后在 webpack 中配置
开启 Scope Hoisting
scope hoisting 可以让 webpack 打包出来的代码文件更小,运行更快,它又被译作“作用域提升”
认识 Scope Hoisting
开启之后,scope hoisting 会分析模块之间的依赖关系(例如输出文件中声明两个函数可以合并成一个),尽可能将被打散的模块合并到一个函数中,但是不能造成代码冗余,因为只有那些被引用了一次的模块才能被合并
由于 scope hoisting 需要分析模块之间的依赖关系,所以必须采用 ES6 模块化语句,不然无法生效
使用 Scope Hoisting
因为 webpack 内置了该功能,所以只需要使用相关插件就行了
但是 scope hoisting 依赖 ES6 模块化语法,还需要配置 mainFields
如果文件采用了非 ES6 模块化语法,webpack 则会降级处理,在启动时携带参数 --display-optimization-bailout 就可以查看相关输出日志
输出分析
前者介绍的很多方法无法应对所有场景,为此我们需要对输出结果进行分析,决定下一步优化方向
最直接的方法是阅读 webpack 输出的代码,但 webpack 输出的代码可读性非常差,而且文件非常大。为了更加简单直观地分析出结果,社区中出现了许多可视化分析工具
webpack 支持如下两个参数:
- --profile:记录构建过程中的耗时信息
- --json:以 JSON 的格式输出构建结果,最后只输出一个 .json 文件,包含所有构建相关信息
例如:webpack --profile --json > stats.json
webpack --profile --json 会输出字符串形式的 JSON,> stats.json 是 UNIX/Linux 系统中的管道命令,表示将输出的内容通过管道输出到 stats.json
官方可视化分析工具
webpack 官方提供了可视化分析工具 webpack analyse,他是一个在线的 web 应用
打开 webpack analyse 链接的网页后,会提示我们上传一个 JSON 文件,也就是上文输出的 stats.json 文件
webpack analyse 会在本地分析该文件
该主页被分为 6 大模块:
- modules:展示所有模块,每个模块对应一个文件,并包含所有模块之间的依赖关系图、模块路径、模块 ID、模块所属的 chunk、模块的大小
- chunks:展示所有代码块,在代码中包含多个模块,并且包含代码块的 ID、名称、大小、每个代码包含的模块数量,以及代码块之间的依赖关系图
- assets:展示所有输出的文件资源,包括 .js、.css、图片等,并且包括文件的名称、大小以及该文件来自哪个代码块
- warnings:展示构建过程中出现的警告信息
- errors:展示构建过程中出现的所有错误信息
- hints:展示处理每个模块所耗费的时间
webpack-bundle-analyzer
是另一个可视化分析工具,虽然没有 webpack analyse 那么多功能,但是比 webpack analyse 更直观
它很方便的让我们知道:
- 打包出的文件中都包含什么
- 每个文件的尺寸在总体中的占比
- 模块之间的关系
- 每个文件的 Gzip 后的大小
使用方法:
- 安装 webpack-bundle-analyzer 到全局
- 按照上面提到的方法生成 stats.json
- 在目录中执行 webpack-bundle-analyzer 后,浏览器会打开对应网页并展现以上效果
优化总结
代码查看书本 p226
原理
工作原理概括
基本概念
我们需要掌握几个核心概念:
- entry:入口,webpack 执行构建的第一步将从 entry 开始,可抽象成输入
- module:模块,在 webpack 里一切皆模块,一个模块对应一个文件,webpack 会从 entry 开始递归找出所有模块
- chunk:代码块,一个 chunk 由多个模块组合而成,用于代码合并与分割
- loader:模块转换器,用于将模块的原内容按照需求转换成新内容
- plugin:扩展插件,在 webpack 构建流程中的特定时机会广播对应的事件,插件可以监听这些事件的发生,在特定时机做对应的事情
流程概括
webpack 运行流程是一个穿行的过程,从启动到结束会依次执行以下流程:
- 初始化参数:从配置文件和 shell 语句中读取与合并参数,得出最终的参数
- 开始编译:用上一步得到的参数初始化 compiler 对象,加载所有配置的插件,通过执行对象的 run 方法开始执行编译
- 确定入口:根据配置文件中的 entry 找出所有入口文件
- 编译模块:从入口文件出发,调用所有配置的 loader 对模块进行翻译,再找出该模块依赖的模块,再递归本步骤直到所有入口依赖的文件都经过了本步骤的处理
- 完成模块编译:经过上一步 loader 翻译完所有模块后,得到每个模块被翻译后的最终内容及他们之间的依赖关系
- 输出资源:根据入口和模块之间的依赖关系,组装成一个个包含多个模块的 chunk,再将每个 chunk 转换成一个单独的文件加入到输出列表中,这是可以修改输出内容的最后机会
- 输出完成:再确定好输出内容后,根据配置确定输出的路径和文件名,将文件的内容写入文件系统中
以上过程,webpack 会在特定的时间点广播特定的事件,插件在监听到感兴趣的事件后会执行特定的逻辑,并且插件可以调用 webpack 提供的 api 改变 webpack 的运行结果
流程细节
webpack 构建流程可以分为三大阶段:
- 初始化:启动构建,读取与合并配置参数,加载 plugin,实例化 compiler
- 编译:从 entry 发出,针对每个 module 串行调用对应的 loader 去翻译文件的内容,再找到该 module 依赖的 module,递归的编译处理
- 输出:将编译后的 module 组合成 chunk,将 chunk 转换成文件,输出到文件系统中
在开启监听模式下,以上流程将会反复执行:
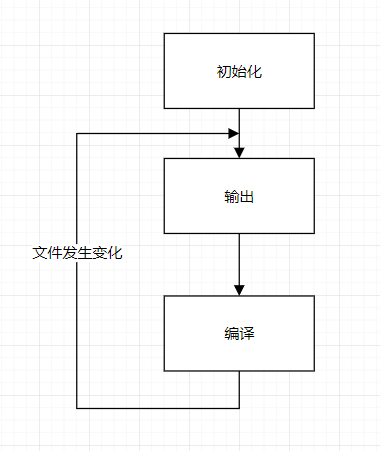
在每个大阶段中会发生很多事件,webpack 会将这些事件广播出来供 plugin 使用
1、初始化阶段
| 事件名 | 解释 |
|---|---|
| 初始化参数 | 从配置文件和 shell 语句中读取与合并参数,的得出最终参数,这个过程中执行插件的实例化语句 |
| 实例化 compiler | 用上一步得到的参数初始化 compiler 实例,compiler 负责文件监听和启动编译,compiler 实例中包含了完整的 webpack 配置,全局只有一个 compiler 实例 |
| 加载插件 | 依次调用插件的 apply 方法,让插件可以监听后续的所有事件节点。同时向插件传入 compiler 实例的引用,以方便插件通过 compiler 调用 webpack 提供的 api |
| environment | 开始应用 node.js 风格的文件系统到 compiler 对象,以方便后续文件寻找和读取 |
| entry-option | 读取配置的 entrys,为每个 entry 实例化一个对应的 entryPlugin,为后面该 entry 的递归解析工作做准备 |
| after-plugins | 调用完所有内置的和配置的插件的 apply 方法 |
| after-resolvers | 根据配置初始化 resolver,resolver 负责在文件系统中寻找指定路径的文件 |
2、编译阶段
| 事件名 | 解释 |
|---|---|
| run | 启动一次新的编译 |
| watch-run | 和 run 类似,区别在于它是在监听模式下启动编译,在这个事件中可以获取是哪些文件发生了变化从而导致重新启动一次新的编译 |
| compile | 该事件是为了告诉插件一次新的编译要启动,同时会给插件带上 compiler 对象 |
| compilation | 当 webpack 以开发模式运行时,每当检测到文件变化,便有一次新的 compilation 被创建。一个 compilation 对象包含了当前的模块资源、编译生成资源、变化的文件等。compilation 对象也提供了很多事件回调给插件进行扩展 |
| make | 一个新的 compilation 创建完毕,即将从 entry 开始读取文件,根据文件的类型和配置的 loader 对文件进行编译,编译完成后再找出该文件依赖的文件,递归的进行编译和解析 |
| after-compile | 一次 compilation 执行完成 |
| invalid | 当遇到文件不存在、文件编译错误等异常时会触发该事件,该事件不会导致 webpack 退出 |
在编译阶段中,最重要的事件是 compilation,因为在 compilation 阶段调用了 loader,完成了每个模块的转换操作。在每个 compilation 阶段又会发生很多小事件:
| 事件名 | 解释 |
|---|---|
| build-module | 使用对应的 loader 去转换一个模块 |
| normal-module-loader | 在用 loader 转换完一个模块后,使用 acorn 解析转换后的内容,输出对应的抽象语法树,以方便 webpack 在后面对代码进行分析 |
| program | 从配置的入口模块开始,分析其 AST,当遇到 require 等导入其它模块的语句时,便将其加入依赖的模块列表中,同时对新找出的依赖模块递归分析,最终弄清楚所有模块的依赖关系 |
| seal | 所有模块及其依赖模块都通过 loader 转换完成,根据依赖关系开始生成 chunk |
3、输出阶段
| 事件名 | 解释 |
|---|---|
| should-emit | 所有要输出的文件已经生成,询问插件有哪些文件需要输出,有哪些不要输出 |
| emit | 确定好输出哪些文件后,执行文件输出,可以在这里获取和修改输出内容 |
| after-emit | 文件输出完毕 |
| done | 成功完成一次完整的编译和输出过程 |
| failed | 如果在编译和输出的流程中遇到异常,导致 webpack 退出,就会直接跳到本步骤,插件可以在本事件中获取具体错误原因 |
在输出阶段已经得到各个模块经过转换后的结果和其依赖关系,并且将相关模块组合在一起形成一个个 chunk。在输出阶段会根据 chunk 类型,使用对应的模块生成最终要输出的文件内容
输出文件分析
前面我们学习了如何使用 webpack,但是其输出的 bundle.js 是什么样子呢?为什么原来一个个的模块文件被合并成了一个单独的文件?为什么 bundle.js 能直接运行在浏览器中?
代码查看 p238
bundle.js 文件能直接在浏览器中运行的原因是:在输出的文件中通过 __webpack__require__ 函数定义了一个可以在浏览器中执行的加载函数,来模拟 node.js 中的 require 语句
将所有的模块文件合并到一个单独的 bundle.js 中的原因是,浏览器不能像 node.js 一样快速的加载本地的一个个模块文件,而必须通过网络请求去加载还未得到的文件,模块数量越多,加载的时间就越长
webpack 还做了缓存优化,已经加载过的模块不会再执行第二次加载,而是会直接去内存中读取被缓存的返回值
在使用了前面介绍的 DLL 优化方法时,输出的文件将会被分为两个;
代码查看 p242
编写 Loader
loader 就像一个翻译员,能将源文件经过转化后输出新的结果,并且一个文件还可以链式的经过多个 loader 转换
以 scss 文件为例:
- 先将 scss 源代码提交给 css-loader 处理,将 scss 转换成 css
- 将 sass-loader 输出的 css 提交给 css-loader 处理,找出 css 中依赖的资源、压缩 css 等
- 将 css-loader 输出的 css 提交给 style-loader 处理,转换成通过脚本加载的 JavaScript 代码
Loader 的职责
一个 loader 的职责是单一的,只需要完成一种转换,如果一个源文件需要经历多步转换才能正常使用,就通过多个 loader 去转换。在调用多个 loader 去转换一个文件时,每个 loader 都会链式地顺序执行。第一个 loader 将会拿到需要处理的原内容,上一个 loader 处理后的结果会被传给下一个 loader 接着处理,最后的 loader 将处理后的最终结果返回给 webpack
所以,在开发一个 loader 时,请保持其职责的单一性
Loader 基础
webpack 是运行在 node.js 上的,一个 loader 其实就是 node.js 模块,这个模块需要导出一个函数。这个导出函数的工作就是获得处理前的原内容,对原内容执行处理后,返回处理后的内容
例如:
module.exports = function (source) {
// source 为 compiler 传递给 loader 的一个文件的原内容
// do something
return source;
};由于 loader 运行在 node.js 中,所以我们可以调用任意的 node.js 自带的 API,或者安装第三方模块进行调用
const sass = require("node-sass");
module.exports = function (source) {
// source 为 compiler 传递给 loader 的一个文件的原内容
return sass(source);
};Loader 进阶
webpack 还提供了一些 api 供 loader 调用
1、获得 loader 的 options
在最上面处理 scss 文件的 webpack 配置中,将 options 参数传给了 css-loader,以控制 css-loader
const loaderUtils = require("loader-utils");
module.exports = function (source) {
const options = loaderUtils.getOptions(this);
return source;
};2、返回其他结果
上面的 loader 都只是返回了原内容转换后的内容,但在某些场景下需要返回除了内容之外的东西
以用 babel-loader 转换 es6 代码为例,他还需要输出转换后的 es5 代码对应的 source map,以方便调试源码。为了将 source map 也一起随着 es5 代码返回给 webpack,可以这样写:
module.exports = function (source) {
this.callback(null, source, sourceMaps);
return; // 我们使用 this.callback 之后,该 loader 必须要返回 undefined
};其中 this.callback 是 webpack 向 loader 注入的 api,以方便 loader 和 webpack 之间通信,使用的方法如下:
this.callback(
err: Error | null,
content: string | Buffer,
sourceMap?: SourceMap,
abstractSyntaxTree?: AST // 如果本次 loader 处理后生成了 ast,就可以将该 ast 返回,让后续 loader 复用
)source map 的生成很耗时,通常在开发环境下才会生成 source map,在其他环境下不用生成,以加速构建
所以,webpack 提供了 this.sourceMap api 去告诉 loader 在当前构建环境下用户是否需要 source map
3、同步与异步
loader 有同步和异步之分,上面介绍的都是同步的 loader
但在某些场景下转换的步骤只能是异步完成的,例如我们需要通过网络请求才能得出结果 ,如果采用同步的方式,则网络请求会阻塞整个构建,导致构建缓慢
module.exports = function (source) {
var callback = this.async(); // 告诉 webpack 本次转换是异步的,loader 会在 callback 中回调结果
someAsyncOperation(source, function (err, result, sourceMaps, ast) {
callback(err, result, sourceMaps, ast);
});
};4、处理二进制数据
默认情况下 webpack 传给 loader 的都是 utf-8 格式编码的字符串
在某些场景下 loader 不会处理文本文件,而会处理二进制文件如 file-loader,这时候就需要 webpack 为 loader 传入二进制格式数据
module.exports = function (source) {
source instanceof Buffer === true; // 在 exports.raw === true 时,webpack 传给 loader 的 source 是 Buffer 类型
return source; // loader 也可以返回 Buffer 类型的结果,exports.raw 为 false 时,也可以返回 Buffer
};
module.exports.raw = true; // 通过该属性告诉 webpack 该 loader 是否需要二进制数据如果没有最后一行的声明,该 loader 只能拿到字符串
5、缓存加速
某些转换操作需要大量计算,非常耗时,如果每次构建都得重新执行重复的转换操作,则构建将会变得非常缓慢
所以 webpack 会默认缓存所有 loader 的处理结果,在需要被处理的文件没有变化时,不会重新调用对应的 loader 去执行转换操作
我们可以手动关闭 webpack 缓存 loader 结果:
module.exports = function (source) {
this.cacheable(false);
return source;
};其它 Loader API
- this.context:当前处理的文件所在的目录,假如当前 loader 处理的文件是
/src/main.js则该属性等于/src - this.resource:当前处理的文件的完整请求路径,包括 querystring,例如
/src/mgin.js?name=1 - this.resourcePath:当前处理文件的路径,例如
/src/main.js - this.resourceQuery:当前处理的文件的 querystring
- this.target:等于 webpack 配置中的 target
- this.loadModule:在 loader 在处理一个文件时,如果依赖其他文件的处理结果才能得出当前文件的结果,就可以通过
this.loadModule(request: string, callback: function(err, source, sourceMap, module))去获取 request 对应的文件处理结果 - this.resolve:像 require 语句一样获得指定文件的完整路径,
this.resolve(context: string, request: string, callback: function(err, result: string)) - this.addDependency:为当前处理的文件添加其依赖的文件,以便其依赖的文件发生变化时,重新调用 loader 处理该文件,
this.addDependency(file: string) - this.addContextDependency: 和 addDependency 类似,但 addContextDependency 是将整个目录加入当前正在处理的文件的依赖中,
this.addContextDependency(directory: string) - this.clearDependencies:清除当前正在处理文件的所有依赖
- this.emitFile:输出一个文件,
this.emitFile(name: string, content: Buffer|string, sourceMap: {...})
其它 API 可以在官网查看
加载本地 Loader
在开发本地 loader 的过程中,为了编写的 Loader 能否正常工作,需要将它配置到 webpack 中,才可能会调用该 loader
按照原先的配置方法,我们需要将编写的 loader 源码放到 node_modules 目录下,这会很麻烦,需要先上传到 npm 仓库再安装到本地项目中使用
1、Npm link
npm link 专门用于开发和调试本地的 Npm 模块,能做到在不发布模块的情况下,将本地的一个正在开发的模块的源码链接到项目的 node_modules 目录下,项目可以直接使用
因为是软链接的方式实现的,编辑了本地的 Npm 模块的代码,所以在项目中也能直接使用到编辑后的代码
我们有几个步骤需要注意:
- 确保正在开发的本地 Npm 模块的 package.json 已经正确配置好
- 在本地 Npm 模块根目录下执行 npm link,将本地模块注册到全局
- 在项目根目录下执行 npm link loader-name,将第二步注册到全局的本地 npm 模块链接到项目的 node_modules 下,loader-name 就是在第一步配置的 package.json 文件中配置的模块名
2、ResolveLoader
该配置用于配置 webpack 如何寻找 loader,我们可以修改 resolveLoader.modules 配置,添加我们本地 loader 所在目录
实战
function replace(source) {
// 将 // @require '../style/index.css' 转换成 require('../style/index.css');
return source.replace(/(\/\/ *@require) +(('|").+('|")).*/, "require($2);");
}
module.exports = function (content) {
return replace(content);
};编写 Plugin
webpack 通过 plugin 机制让其更灵活,以适应各种应用场景
在 webpack 运行的生命周期中会广播许多事件,plugin 可以监听这些事件,在适合的时机通过 webpack 提供的 api 改变输出结果
class BasicPlugin {
// 在构造函数中获取用户为该插件传入的配置
constructor(options) {}
// webpack 会调用 BasicPlugin 实例的 apply 方法为插件实例传入 compiler 对象
apply(compiler) {
compiler.plugin("compilation", function (compilation) {});
}
}
module.exports = BasicPlugin;webpack 启动后,在读取配置过程中会先执行 new BasicPlugin(options),初始化一个 basicPlugin 并获得其实例
在初始化 compiler 对象后,再调用 basicPlugin.apply(compiler) 为插件实例传入 compiler 对象
插件在获取到 compiler 对象后,就可以通过 compiler.plugin('eventName', callBack) 监听到 webpack 广播的事件,并且可以通过 compiler 对象去操作 webpack
Compiler 和 Compilation
在开发 plugin 时,最常用的两个对象就是 compiler 和 compilation,他们是 plugin 和 webpack 的桥梁:
- compiler 对象包含了 webpack 环境的所有配置信息,包含 options、loaders、plugins 等,这个对象在 webpack 启动时被实例化,它是全局唯一的,可以简单的将其理解为 webpack 实例
- compilation 对象包含了当前的模块资源、编译生成资源、变化的文件等;当 webpack 以开发模式运行时,每当检测到一个文件发生变化,便有一次新的 compilation 被创建,compilation 对象也提供了很多事件回调提供插件进行扩展,通过 compilation 可以获取到 compiler 对象
compiler 和 compilation 的区别在于:compiler 代表了整个 webpack 从启动到关闭的生命周期,而 compilation 只代表一次新的编译
事件流
webpack 就像一条生产线,要经过一系列处理流程后才能将源文件转换成输出结果
这条生产线上的每个处理流程的职责都是单一的,多个流程之间存在依赖关系,只有在完成当前处理后才能交给下一个流程去处理
插件就像插入生产线中的某一个功能,在特定的时机对生产线上的资源进行处理
webpack 通过 tapable 来组织这条复杂的生产线;webpack 在运行过程中会广播事件,插件只需要监听它所关心的事件,就能加入这条生产线中,去改变生产线的运作;webpack 事件流机制保证了插件的有序性,使得整个系统的扩展性良好
webpack 事件流机制应用了观察者模式,和 node.js 中的 eventEmitter 非常相似;compiler 和 compilation 都继承自 tapable,可以直接在 compiler 和 compilation 对象上广播和监听事件
// 广播事件:event-name 为事件名称,不要和现有事件重名,params 为附带的参数
compiler.apply("event-name", params);
//监听名称为 event-name 的事件,当 event-name 事件发生时,函数就会被执行,同时函数中的 params 参数为广播事件时附带的参数
compiler.plugin("event-name", function (params) {});compilation 上的这两个方法也一样
在开发插件时,还需要注意以下两点:只要能拿到 compiler 或 compilation 对象,就能广播新的事件,所以在新开发的插件中也能广播事件,为其他插件监听使用
传给每个插件的 compiler 和 compilation 对象都是同一个引用,所以我们对这两个对象的修改都会影响后面的插件
有些事件是异步的,这些异步的事件会附带两个参数,第二个参数为回调函数,在插件处理完任务时需要调用回调函数通知 webpack,才会进入下一个流程
compiler.plugin("emit", function (compilation, callback) {
callback(); // 不执行会阻塞后续流程
});常用的 API
插件可以用来修改输出文件和增加输出文件,甚至可以提升 webpack 的性能等;插件可以通过调用 webpack 提供的 api 完成很多事情,由于 webpack 提供的 api 非常多,有一些常用 api 在这里介绍一下
1、读取输出资源、代码块、模块及其依赖
某些插件可能需要读取 webpack 的处理结果,例如输出资源、代码块、模块及其依赖
emit 事件发生时,代表源文件的转换和组装已经完成,在这里可以读取到最终将输出的资源、代码块、模块及其依赖,并且可以修改输出资源的内容,例如:
class Plugin {
apply(compiler) {
compiler.plugin("emit", function (compilation, callback) {
// compilation.chunks 存放代码块,是一个数组
compilation.chunks.forEach(function (chunk) {
// 代码块由多个模块组成,通过 chunk.forEachModule 能读取代码块每个模块
chunk.forEachModule(function (module) {
// module 代表一个模块
// module.fileDependencies 存放当前模块的所有依赖的文件路径,是一个数组
module.fileDependencies.forEach(function (filePath) {});
});
// webpack 会根据 chunk 生成输出的文件资源,每个 chunk 都对应一个及以上的输出文件
// 例如在 chunk 中包含 css 模块并且使用了 ExtractTextPlugin 时,该 chunk 就会生成 .js 和 .css 两个文件
chunk.files.forEach(function (filename) {
// compilation.assets 存放当前即将输出的所有资源,调用一个输出资源的 source() 方法能获取输出资源的内容
let source = compilation.assets[filename].source();
});
});
// 这是一个异步事件,要记得调用 callback 来通知 webpack 本次事件监听处理结束
// 如果忘记调用 callback,webpack 会一直卡在这里
callback();
});
}
}2、监听文件的变化
webpack 会从配置的入口模块出发,依次找出所有依赖模块,当入口模块或者其它依赖模块发生变化时,就会触发一次新的 compilation,我们需要知道是哪个文件导致了新的 compilation,我们可以这样做:
// 当依赖文件发生变化时会触发 watch-run 事件
compiler.plugin("watch-run", (watching, callback) => {
// 获取发生变化的文件列表
const changedFiles = watching.compiler.watchFileSystem.watcher.mtimes;
// changedFiles 格式为键值对,键为发生变化的文件路径
if (changedFiles[filePath] !== undefined) {
} // filePath 对应文件发生了变化
callback();
});在默认情况下, webpack 只会监听入口和其依赖的模块是否发生变化,在某些情况下项目可能需要引入新的文件,例如 html 文件
由于 JavaScript 文件不会导入 html 文件,所以 webpack 不会监听 html 文件的变化,编辑 html 文件时就不会重新触发新的 compilation;为了能够监听 html 文件的变化,我们需要将 html 文件加入依赖列表中,可以这样做:
compiler.plugin("after-compile", (compilation, callback) => {
compilation.fileDependencies.push(filePath);
callback();
});3、修改输出资源
在某些场景下插件需要修改、增加、删除输出的资源,要做到这一点,则需要监听 emit 事件,因为发生 emit 事件时所有模块的转换和代码块对应的文件已经生成好,需要输出的资源即将输出,因此 emit 事件是修改 webpack 输出资源的最后时机
所有需要输出的资源都会被存放在 compilation.assets 中,compilation.assets 是一个键值对,键为需要输出的文件名称,值为文件对应的内容
compiler.plugin("emit", (compilation, callback) => {
// 设置名为 filename 的输出资源
compilation.assets[filename] = {
source: () => {
// 返回文件内容
return fileContent;
},
size: () => {
return Buffer.byteLength(fileContent, "utf8");
},
};
callback();
});
// 读取 compilation.assets 的代码
compiler.plugin("emit", (compilation, callback) => {
const asset = compilation.assets[filename];
asset.source();
asset.size();
callback();
});4、判断 webpack 使用了哪些插件
在开发一个插件,我们可能需要依据当前配置是否使用了其他插件来做下一步决定,因此需要读取 webpack 当前的插件配置情况
比如若想判断当前是否使用了 extractTextPlugin,例如:
function hasExtractTextPlugin(compiler) {
const plugins = compiler.options.plugins; // 当前配置使用的所有插件列表
return plugins.find((plugin) => plugin.__proto__.constructor === ExtractTextPlugin) != null; // 去 plugins 中寻找有没有 ExtractTextPlugin 的实例
}实战
我们尝试做一个 endWebpackPlugin,在 webpack 成功编译和输出了文件后执行发布操作,将输出的文件上传到服务器,同时插件还能区分 webpack 构建是否执行成功
class EndWebpackPlugin {
constructor(doneCallback, failCallback) {
this.doneCallback = doneCallback;
this.failCallback = failCallback;
}
apply(compiler) {
compiler.plugin("done", (status) => {
this.doneCallback(status);
});
compiler.plugin("failed", (err) => {
this.failCallback(err);
});
}
}
module.exports = EndWebpackPlugin;调试 Webpack
在编写 plugin 和 loader 时,执行结果可能和我们预期的不一样,就像我们平时写代码遇到了奇奇怪怪的 bug 一样,我们就需要调试程序源码
console.log 的方式不是很方便,我们可以使用第三方软件中的 node.js 调试工具,下面以 webstorm 为例
1、设置断点
在编辑区左侧设置断点
2、配置执行入口
新建 node.js debug 执行入口
- name,设置 debug 名称
- working directory,设置需要调试项目所在根目录
- JavaScript file,要执行的 js 文件(指向 webpack 执行文件:webpack/bin/webpack.js)
3、启动调试
4、执行到断点
执行到断点还可以查看当前变量的状态,找出问题