DOM(Document Object Model)
dom 提供了操作 html 和 xml 的机会,他是一个操作 html 和 xml 功能的一类对象的集合
DOM 的基本操作
document 代表整个文档

NodeList,一种节点集合
有 item(x)方法(与 NodeList[x]效果一样)
HTMLCollection,HTML 文档中的一种集合类型
该集合是对元素的引用,也就是说不是元素的闪照
有 item(x)方法;有 namedItem(name)方法,通过标签的 name 属性获取某一项的引用(可以直接用中括号使用如:HTMLCollection[name],实际调用的是 namedItem 方法)
查
1.getElementById('');,在 IE8 以下浏览器,如果没有 id 值则将会取相同的 name 元素;如果有多个则返回第一个
定义在 Document.prototype 上
2.getElementsByTagName('');,在 HTML 文档中返回的是 HTMLCollection 对象,是类数组
定义在了 Document.prototype 和 Element.prototype 上,可以使用 ' * ' 来选择所有标签
3.getElementsByClassName('');,IE8 以及 IE8 以下浏览器中没有
定义在了 Document.prototype 和 Element.prototype 上
4.getElementsByName('');,返回 HTMLCollection
定义在了 HTMLDocument.prototype 上
5.querySelector('');,里面直接写 css 选择器
IE6、IE7 没有此方法,选择出来的标签不是实时的(non-live),但是操作是实时的
定义在了 Document.prototype 和 Element.prototype 上
6.querySelectorAll('');,同上,但是会选择所有的匹配项
IE6、IE7 没有此方法,选择出来的标签不是实时的,但是操作是实时的
定义在了 Document.prototype 和 Element.prototype 上
7.node.parentNode
8.node.childNodes
9.node.firstChild
10.node.lastChild
11.node.nextSibling,后一个兄弟节点
12.node.previousSibling,前一个兄弟节点
元素节点树
13.dom.parentElement,IE9 及以下不兼容
14.dom.children
15.dom.childElementCount,等于dom.children.length,IE9 以及以下不兼容
16.dom.firstElementChild,IE9 以及以下不兼容
17.dom.lastElementChild,IE9 以及以下不兼容
18.dom.nextElementSibling,IE9 以及以下不兼容
19.dom.previousElementSibling,IE9 以及以下不兼容
20.dom.hasChildNodes();,返回 true 和 false,判断节点有没有子节点
节点的属性
nodeName,返回节点名,只读
nodeValue,text 节点或 comment 节点的文本内容,可读可写
nodeType,该节点的类型(返回值看上述的节点树中的节点类型对应的数值),只读
attributes,属性节点的集合(类数组)
ownerDocument,指向代表整个文档的文档节点的指针
节点的类型
元素节点——1、属性节点——2、文本节点——3、注释节点(Comment)——8、document——9、DocumentFragment(文档碎片节点)——11
增
1、document.createElement('');,接收一个参数,即要创建元素的标签名
2、document.createTextNode('');
3、document.createComment('');
4、document.createDocumentFragment('');
插
1、parentNode.appendChild(dom);,返回新添加的节点;
如果 dom 是文档中有的节点,那么类似于剪切,将 dom 从原来位置剪切到当前元素的子元素最后
2、parentNode.insertBefore(a, b);,返回 b;理解为 div 子元素中,insert a before b
b 上所有关系指针都会被复制到 a 上;如果 b 为 null,则与 appendChild()效果相同
3、parentNode.insertAfter(a, b);,需要自己封装
function insertAfter(newelement, targetelement) {
var parentelement = targetelement.parentNode;
if (parentelement.lastChild == targetelement) {
parentelement.appendChild(newelement);
} else {
parentelement.insertBefore(newelement, targetelement.nextSilbing);
}
}删
1、parent.removeChild();,会返回被 remove 的 dom
2、child.remove();
3、node.normalize()
处理节点子树中的文本节点,该方法会删除 node 中的空文本节点;如果俩个或多个文本节点是相邻的,则合并为一个文本节点
替换
1、parentNode.replaceChild(new, origin);
复制
1、node.cloneNode(),传入布尔值,表示是否深复制,返回复制的副本
如果传入 true,则会复制节点以及其整个子 DOM 树;如果传入 false,则只会复制调用该方法的节点
但是这个方法只复制 HTML,不会复制添加到 DOM 节点的 JavaScript 属性,比如事件处理程序
Document 类型
Document 类型是 js 中表示文档节点的类型
在浏览器中,document 是 HTMLDocument 的实例(HTMLDocument 继承 Document),表示整个页面;document 是 window 对象的属性,所以是一个全局变量;该类型的节点有以下特征:
nodeType:9
nodeName:#document
nodeValue:null
parentNode:null
ownerDocument:null
子节点可以是:DocumentType(最多一个)、Element(最多一个,通常指<html>)、ProcessingInstruction 或 Comment 类型
文档子节点
1、在 Document.prototype 上定义了 documentElement 属性,指代文档的根元素 <html>
可以直接通过 document.documentElement 获取<html>元素
let html = document.documentElement;
html === document.childNodes[0]; //truehtml === document.firstChild; //true2、在 HTMLDocument.prototype 上定义了 body、head 属性直接指代 HTML 文档中的 body、head 标签
可以直接通过 document.body 获取<body>元素
3、可以通过 document.doctype 来访问<!doctype>标签
4、浏览器不同,可能以不同的方式对待<html>之外的注释,属于 document 中的注释不一定被识别
一般来说 appendChild、removeChild、replaceChild 方法不会用在 document 对象上,因为文档类型是只读的,而且只能有一个 Element(即<html>,已经存在了)
文档信息
1、title,可以通过 document.title 读写文档标题,但是这个属性并不会改变<title>元素
2、URL,通过 document.URL 获得当前页面完整的 URL
3、referrer,通过 document.referrer 包含链接到当前页面的那个页面的 URL,如果页面没有来源,则返回空字符串
4、domain,通过 document.domain 取得或设置当前页面的域名
但是设置 domain 是有限制的,如果 URL 包含子域名如:“p2p.wrox.com”、“www.wrox.com”,则可以将domain设置成“wrox.com”,不能给这个属性设置URl不包含的值如:“aaffdadf.com”
当页面包含来自某个不同子域的窗格(<frame>)或内嵌窗格(<iframe>)时,设置 domain 是有效的。因为跨源通信存在安全隐患,所以不同子域的页面间无法通过 js 通信,但是用 document.domain 将它们设为相同的值,就可以访问对方的 js 了
当一个 domain”放松“后就不能”收紧“了,将“p2p.wrox.com”设置成“wrox.com”就不能再设置回去了
上面三个信息都能从 HTTP 头部信息获取,只是在 js 中通过这几个属性暴露
特殊集合
1、document.anchors,包含文档中所有带 name 属性的<a>元素
2、document.applets,包含文档中所有<applet>元素(因为该元素不建议使用,所以该集合已经废弃)
3、document.forms,包含文档中所有<form>元素
4、document.images,包含文档中所有<img>元素
5、document.links,包含文档中所有带 href 属性的<a>元素
DOM 兼容性检测(已废弃)
由于 DOM 有多个 Level 和多个部分,确定浏览器实现了哪些部分是很重要的
document.implementation 属性是一个对象,其中提供了与浏览器 DOM 实现相关的信息和能力
DOM Level 1 在这个属性上只定义了一个方法:hasFeature(),该方法接受两个参数:特性名称和 DOM 版本,如果浏览器支持则返回 true,如:
let hasXmlDom = document.implementation.hasFeature("XML", "1.0");
由于实现不一致,该返回值并不可靠;目前这个方法已经被废弃,不建议使用;主流浏览器中该方法始终会返回 true
文档写入
document.write()、document.writeln()(writeln 方法会在字符串末尾追加一个换行符 ‘\n’)
向网页输出流中写入内容
这俩个方法都接收字符串,会将字符串写入网页中,这些字符串会被解析,所以可以在字符串中写入 html 代码
需要注意的是如果在页面加载完后再调用则输出的内容会重写整个页面
document.open()、document.close()
这两个方法用于打开和关闭网页输出流,但是无法影响上面两种方法
Element 类型
Element 是 Web 开发最常用的类型了,表示 XML 或者 HTML 元素,该类型节点具有以下特征:
nodeType:1
nodeName:元素的标签名(tagName 也可以)
nodeValue:null
parentNode:Document 或 Element
子节点可以是:Element、Text、Comment、ProcessingInstruction、CDATASection、EntityReference 类型
在 HTML 中,元素标签名始终以全大写表示,在 XML(包括 XHTML 中)始终以源代码中的大小写一致
HTML 元素
所有 HTML 元素都通过 HTMLElement 类型表示,包括其直接实例和间接实例;它直接继承了 Element 并增加了一些属性,所有 HTML 元素上都有的标准属性:
id,元素在文档中的唯一标识符
title,包含元素的额外信息,通常以提示条形式展示、
lang,元素内容的语言代码(很少用)
dir,语言的书写方向(“ltr”表示从左到右,“rtl”表示从右到左,很少用)
className,相当于 class 属性
这些属性都支持读写操作
元素及其对应的类型,请查阅红宝书 p415
Element 节点属性
1、dom.innerHTML,可读可写
2、dom.innerText,可读可写,老版本 firefox 不兼容(但是有 textContent,但是老版本 IE 不兼容)
3、dom.className,可读可写
取得属性
e.getAttribute(attrName);
属性名不区分大小写
所有的属性也可以通过对应的 DOM 元素对象的属性来取得,包括 HTMLElement 定义的直接映射对应属性的 5 个属性,还有所有公认属性(不包括自定义属性)会被添加为 DOM 对象的属性
通过 DOM 对象取得的属性值中有了两个值和通过 getAttribute 取得的值不一样:
1、style 属性,通过 getAttribute 返回的是一个字符串;通过 DOM 取得的是一个 CSSStyleDeclaration 对象,而且其相关属性值不会直接映射为元素中的 style 属性的字符串值
2、事件处理程序,例如 onclick;通过 getAttribute 取得的是字符串形式的源码;通过 DOM 对象取得的访问事件的属性则是一个 js 函数(未指定该属性则返回 null)
在开发中一般使用 getAttribute 获取自定义的属性
设置属性
e.setAttribute(attrName, value);
设置的属性名会规范为小写形式
也可以通过给 DOM 对象属性赋值来设置属性;但是在 DOM 对象上添加自定义属性,不会让它变成元素属性,如:
div.myColor = "red";
div.getAttribute("myColor"); //null删除属性
e.removeAttribute(attrName);
会将整个属性从元素中去掉
attributes 属性
Element 是唯一使用 attributes 属性的 DOM 节点类型。该属性包含一个 NamedNodeMap 实例,是一个类似于 NodeList 的”实时“的集合,该元素每个属性都表示为一个 attr 节点保存在这个 NamedNodeMap 对象中,这个对象有下列方法:
getNamedItem(name),返回 nodeName 属性等于 name 的节点
removeNamedItem(name),删除 nodeName 属性等于 name 的节点
setNameItem(node),向列表中添加 node 节点,以其 nodeName 为索引
item(pos),返回索引位置 pos 处的节点
attributes 属性中每个节点的 nodeName 对应的是属性的名字,nodeValue 是属性的值
let id = element.attributes.getNamedItem("id").nodeValue;
let id = element.attributes["id"].nodeValue;
//还可以这样子设置属性的值
element.attributes["id"].nodeValue = "sss";
//removeNamedItem()与removeAttribute()类似,只不过前者返回删除属性的attr节点
let oldAttr = element.attributes.removeNamedItem("id");
//setNamedItem()很少用,他接受一个属性节点
element.attributes.setNamedItem(newAttr);attributes 属性一般用于迭代元素上所有属性的时候用,这时候往往要把 DOM 结构序列化为 XML 或 HTML 字符串
元素后代
可以通过查询元素的方法取得,也可以通过查询 node 方法然后判断 nodeType 取得
Text 类型
该类型节点有以下特征:
nodeType:3
nodeName:#text
nodeValue:节点中的文本
parentNode:Element 对象
不支持子节点
Text 节点中包含的文本可以通过 nodeValue 属性访问,也可以通过 data 属性访问,这两个属性值一样;修改其中一个属性值,另一个属性也会相应改变,文本节点有以下方法:
appendData(text),向节点末尾添加文本
deleteData(offset, count),从位置 offset 开始删除 count 个字符
insertData(offset, text),在位置 offset 插入 text
replaceData(offset, count, text),用 text 替换从位置 offset 到 offset + count 的文本
splitText(offset),在位置 offset 将当前文本节点拆分为两个文本节点
substringData(offset, count),提取从位置 offset 开始到 offset + count 的文本
还可以通过 length 获取文本节点中包含的字符数量
包含文本内容的元素最多只能有一个文本节点:
<div></div>
<!-- 没有内容,所以没有文本节点 -->
<div> </div>
<!-- 有一个空格,所以有一个包含空格的文本节点 -->
<div>hello</div>
<!-- 有内容,有一个文本节点 -->我们可以读写文本节点
let text = div.firstChild.nodeValue; //div.childNodes[0].nodeValue
div.firstChild.nodeValue = "change";其中的 HTML 或 XML 代码会被转义
div.firstChild.nodeValue = "<strong>other</strong>";
//输出为"<strong>other</strong>"创建文本节点
document.createTextNode(),该方法接收一个本文参数,和设置文本节点值一样,其中的 HTML 或 XML 代码会被转义
通过创建文本节点方式可以让一个元素包含多个文本节点
规范化文本节点
normalize()
拆分文本节点
splitText(offset),在 offset 位置拆分文本节点,将文本节点一分为二
Comment 类型
DOM 中的注释通过 Comment 类型表示,该类型有以下特征:
nodeType:8
nodeName:#comment
nodeValue:注释的内容
parentNode:Document 或 Element 对象
不支持子节点
Comment 类型和 Text 类型继承同一个基类(CharacterData),所以它拥有除 splitText()之外的所有 Text 类型的字符串操作方法,注释的内容可以通过 nodeValue 或 data 获得
通过 document.createComment()创建注释
浏览器不承认</html>标签后的注释;如果要访问注释节点,则要保证他们是<html>元素的后代
CDATASection 类型
CDATASection 类型标识 XML 中独有的 CDATA 区块,CDATASection 类型继承 Text 类型,所以具有 Text 类型所有字符串方法,该类型有以下特征:
nodeType:4
nodeName:#cdata-section
nodeValue:CDATA 区块中的内容
parentNode:Document 或 Element 对象
不支持子节点
CDATA 只在 XML 文档中有效,有些浏览器比较旧的版本会将 CDATA 区块解析为 Comment 或 Element,主流的浏览器中也不能洽当的支持嵌入 CDATA 区块
真正的 XML 文档中,document.createCDataSection()可以创建 CDATA 区块,传入内容
DocumentType 类型
该类型的节点保存了文档的文档类型信息,有以下特征:
nodeType:10
nodeName:文档类型名称
nodeValue:null
parentNode:Document 对象
不支持子节点
DocumentType 对象在 DOM Level 1 中不支持动态创建,只能在解析文档代码时创建;对于支持这个类型的浏览器,该对象保存在 document.doctype 属性中;DOM Level 1 规定了该对象三个属性:name、entities、notations;name 是文档类型名称,entities 是文档类型描述实体的 NameNodeMap,notations 是文档类型描述的表示法的 NameNodeMap;因为文档类型通常是 HTML 或 XHTML,所以后两者列表都为空;无论如何,只有 name 属性是有用的
<!DOCTYPE html>
<!-- document.doctype.name; //"html" -->DocumentFragment 类型
该类型是唯一一个在标记中没有对应表示的类型,它被定义为”轻量级“文档,可以包含和操作节点,但是没有完整文档那样额外的消耗,该类型节点具有以下特征:
nodeType:11
nodeName:#document-fragment、
nodeValue:null
parentNode:null
子节点可以是:Element、ProcessingInstruction、Comment、Text、CDATASection 或 EntityReference
不可以直接将文档片段添加到文档,它应该是充当其他要被添加到文档节点的仓库,使用 document.createDocumentFragment()方法创建文档片段
let fragment = document.createDocumentFragment();
文档片段从 Node 类继承了型所有文档类型所具备的可执行 DOM 操作的方法
如果要进行重复的添加节点,可以先添加到文档片段中,然后一次性添加到文档里,这样避免了多次重复渲染
Attr 类型
元素数据在 DOM 中通过 Attr 类型表示;Attr 类型构造函数和原型在所有浏览器中都可以直接访问;技术上讲,属性是存在于元素 attributes 中的节点;该类型有以下特征:
nodeType:2
nodeName:属性名
nodeValue:属性值
parentNode:null
在 HTML 中不支持子节点
在 XML 中子节点可以是 Text 或 EntityReference
属性节点虽然是节点,但不被认为是 DOM 文档树的一部分,Attr 节点很少直接被引用,通常更常用 getAttribute、setAttribute、removeAttribute
Attr 对象上有三个属性:name(属性名)、value(属性值)、specified(布尔值,表示属性使用的是默认值还是被指定的值)
可以使用 document.createAttribute()方法创建新的 Attr 节点,参数为属性名
let attr = document.createAttribute("align");
attr.value = "left";
element.setAttributeNode(attr);
element.attributes["align"].value;
element.getAttributeNode("align").value;
element.getAttribute("align");
//上面三个方法都能返回align属性值,但是前两者返回的是Attr节点,后者返回的是属性值DOM 编程
动态脚本(动态 JS)
通过向页面中动态添加<script>标签来添加脚本
红宝书 p426
通过 innerHTML 创建的 script 标签永远不会执行,浏览器虽然会创建标签元素以及其中的脚本文本,但解析器会给这个元素打上用不执行的标签
动态样式(动态 CSS)
通过向页面添加<link>或<style>标签来添加样式
红宝书 p428
对于 IE 要小心使用 styleSheet.cssText,如果重复用同一个<style>元素并设置该属性超过一次,可能导致浏览器崩溃;将 cssText 设置为空字符串也可能导致浏览器崩溃
操作表格
通过 DOM 构建表格很繁琐,所以为了方便构建表格,HTML DOM 给<table>、<tbody>、<tr>元素添加了一些属性和方法:、
<table>元素有以下属性和方法
caption,指向 caption 元素的指针(如果存在)
tBodies,包含 tbody 元素的 HTMLCollection
tFoot,指向 tfoot 元素(如果存在)
tHead,指向 thead 元素(如果存在)
rows,包含表示所有行的 HTMLCollection
createTHead(),创建 thead 元素,放到表格中,返回引用
createTFoot(),创建 tfoot 元素,放到表格中,返回引用
createCaption(),创建 caption 元素,放到表格中,返回引用
deleteTHead(),删除 thead 元素
deleteTFoot(),删除 tfoot 元素
deleteCaption(),删除 caption 元素
deleteRow(pos),删除指定位置的行
insertRow(pos),在行集合中给定位置插入一行
<tbody>元素有以下属性和方法
rows,包含 tbody 元素中所有行的 HTMLCollection
deleteRow(pos),删除指定位置的行
insertRow(pos),在指定位置插入行,返回该行的引用
<tr>元素有以下属性和方法
cells,包含 tr 元素所有表元的 HTMLCollection
deleteCell(pos),删除给定位置的表元
insertCell(pos),在指定位置插入表元,返回该表元的引用
使用 NodeList
理解 NodeList 对象和相关的 NamedNodeMap、HTMLCollection,是理解 DOM 编程的关键;这三个集合类型都是”实时的“,文档结构的变化会在它们身上实时的反映,所以它们的值始终代表最新状态
每次访问集合时浏览器都会更新集合,所以要限制操作 NodeList 的次数,因为每次查询都会搜索整个文档,所以最好把查询到的 NodeList 缓存起来
MutationObserver 接口
添加到 DOM 规范不久,可以在 DOM 被修改时异步执行回调;使用该接口可以观察整个文档、DOM 树的一部分或某个元素,还可以观察元素属性、子节点、文本、或前三者任意组合的变化(引进 MutationObserver 接口是为了取代废弃的 MutationEvent)
基本用法
observe()
新创建的实例不会关联 DOM 任何部分,需要通过实例的 observe()方法将这个实例与 DOM 关联起来
这个方法接收两个参数:要观察其变化的 DOM 节点,一个 MutationObserverInit 对象
MutationObserverInit 对象用于控制观察哪些方面的变化,一个是键/值对形式配置选项的字典
let observer = new MutationObserver(() => console.log("body attribute changed"));
observer.observe(document.body, { attributes: true });
document.body.className = "foo";
console.log("changed body class");
//changed body class
//body attribute changed
//回调函数是异步执行的回调与 MutationRecord
每个回调都会收到一个 MutationRecord 实例的数组,MutationRecord 实例包含的信息包括发生了什么变化,以及 DOM 的哪一部分收到了影响
每次执行回调函数都会传入一个包含按顺序入队的 MutationRecord 实例的数组
变动触发之后,将变动记录在数组中,统一进行回调的,也就是说,当你使用 observer 监听多个 DOM 或者 DOM 多个变化时,并且这个 DOM 发生了多次变化,那么 observer 会将变化记录到变化数组中,等待变动都结束了,然后一次性的从变化数组中执行其对应的回调函数
let observer = new MutationObserver((mutationRecords) => console.log(mutationRecords));
observer.observe(document.body, { attributes: true });
document.body.setAttribute("foo", "bar");
//[
// {
// addedNodes: NodeList [],
// attributeName: "foo",
// attributeNamespace: null,
// nextSibling: null,
// oldValue: null,
// previousSibling: null,
// removedNodes: NodeList [],
// target: body,
// type: "attributes"
// }
//]
//如果连续改变多次
document.body.className = "foo";
document.body.className = "bar";
document.body.className = "baz";
//[MutationRecord, MutationRecord, MutationRecord]MutationRecord 实例的属性:
| 属性 | 说明 |
|---|---|
| target | 被修改影响的目标节点 |
| type | 字符串,表示变化的类型:”attributes“、”characterData“或”childList“ |
| oldValue | 在 MutationObserverInit 对象中启用(attributeOldValue 或 characterDataOldValue 为 true);”attributes“或”characterData“类型的变化事件会设置这个属性值为被替代的值,”childList“类型的变化始终会将此值设置为 null、 |
| attributeName | 对于”attributes“类型的变化,这里保存被修改属性的名字;其他类型变化这个属性为 null |
| attributeNamespace | 对于使用了命名空间的”attirbutes“类型的变化,这里保存被修改属性的名字;其他类型变化这个属性值为 null |
| addedNodes | 对于”childList“类型的变化,返回包含变化中添加节点的 NodeList,默认为空 NodeList |
| removedNodes | 对于”childList“类型的变化,返回包含变化中删除节点的 NodeList,默认为空 NodeList |
| previousSibling | 对于”childList“类型的变化,返回变化节点前一个同胞 Node,默认为 null |
| nextSibling | 对于”childList“类型的变化,返回变化节点后一个同胞 Node,默认为 null |
传给回调函数第二个参数是观察变化的 MutationObserver 的实例
disconnect()
默认情况下,只要被观察的元素不被垃圾回收,MutationObserver 的回调就会响应 DOM 变化事件从而被执行
如果要提前终止回调,可以调用 disconnect 方法;使用 disconnect 之后,不仅会停止此后的回调事件,也会抛弃已经加入任务队列要异步执行的回调
document.body.className = "foo";
observer.disconnect();
document.body.className = "bar";
//没有日志输出
//如果想让已经加入任务队列的回调执行,可以使用setTimeout()让已经入列的回调执行完毕再调用disconnect()
document.bodyclassName = "foo";
setTimeout(() => {
observer.disconnect();
document.body.className = "bar";
}, 0);
//body attribute changed复用 MutationObserver
多次调用 observe()方法,可以复用一个 MutationObserver 对象观察多个不同的目标节点,MutationRecord 中的 target 属性可以标识目标节点
但是 disconnect()方法会停止观察所有目标,也就是清除 MutationObserver 上所有要观察的对象,并且清空相关任务队列
重用 MutationObserver
调用 disconnect()方法后不会结束 MutationObserver 对象的生命,还可以重新使用它关联到目标节点
MutationObserverInit 与观察范围
MutationObserverInit 控制对目标节点的观察范围
| 属性 | 说明 |
|---|---|
| subtree | 布尔值,表示除了目标节点,是否观察目标节点的子树;默认 false |
| attributes | 布尔值,表示是否观察目标节点的属性变化;默认 false |
| attributeFilter | 字符串数组,表示要观察哪些属性变化;把这个值设置为 true 也会将 attributes 的值转为 true,默认是观察所有属性 |
| attributeOldValue | 布尔值,表示 MutationRecord 是否记录变化之前的属性值;把这个值设为 true 也会将 attributes 的值转换为 true;默认为 false |
| characterData | 布尔值,表示修改字符数据是否触发变化事件;默认 false |
| characterDataOldValue | 布尔值,表示 MutationRecord 是否记录变化之前的字符数据;把这个值设置为 true 也会将 characterData 的值转换为 true;默认为 false |
| childList | 布尔值,表示修改目标节点的子节点是否触发变化事件;默认为 false |
在调用 observe()时,MutationObserverInit 对象中的 attributes、characterData、childList 属性必须有一项为 true(直接或间接导致它们转换为 true 都行)
观察属性、观察字符数据、观察子节点、观察子树
异步回调与记录队列
MutationObserver 接口是出于性能考虑设计的,其核心时异步回调与记录队列模型
为了在大量变化事件发生时不影响性能,每次变化的信息会保存在 MutationRecord 实例中,然后添加到记录队列,这个队列对每个 MutationObserver 实例都是唯一的,是所有 DOM 变化事件的有序列表
记录队列
每次 MutationRecoed 被添加到 MutationObserver 的记录队列时,仅当之前没有已排期的微任务回调时(队列中微任务长度为 0),才会将观察者注册的回调作为微任务调度到任务队列上,这样可以保证记录队列的内容不会被回调处理两次
当回调执行后,记录队列中的 MutationRecord 就用不着了,因此记录队列会被清空,其内容会被丢弃
takeRecords()方法
调用 MutationObserver 实例的 takeRecords 方法可以清空记录队列,取出并返回其中的所有 MutationRecord 实例
document.body.className = "foo";
document.body.className = "foo";
document.body.className = "foo";
console.log(observer.takeRecords());
console.log(observer.takeRecords());
//[MutationRecord, MutationRecord, MutationRecord]
//[]这个方法在观察者断开与目标的联系,但又希望处理记录队列中的 MutationRecord 实例时比较有用
性能内存与垃圾回收
MutationObserver 的引用
MutationObserver 拥有对目标节点的弱引用,所以不妨碍垃圾回收程序回收目标节点
但是目标节点对 MutationObserver 是强引用,如果目标节点从 DOM 中移除后,随后被垃圾回收,则关联的 MutationObserver 也会被垃圾回收
MutationRecord 的引用
记录队列中每个 MutationRecord 实例至少包含对已有 DOM 节点的一个引用;记录队列和回调函数处理的默认行为就是耗尽这个队列,处理每个 MutationRecord,然后让他们超出作用域并被垃圾回收
如果保存这些节点的引用就会妨碍这些节点的回收,如果需要尽快的释放内存,建议从每个 MutataionRacord 中抽取最有用的信息,然后保存到一个新对象中,最后抛弃 MutationRecord
脚本化 CSS
dom.style.prop,能读能写,也是唯一能写值的方法
只能获取行间样式里面的值,行间样式里没有的值将会返回空字符串,同样地,只能设置行间样式的值
如果遇到 float 这样的保留字属性,前面应该加 css,如float -> cssFloat
window.getComputedStyle(elem, null),不能修改
第二个参数:可选,伪类元素,当不查询伪类元素的时候可以忽略或者传入 null(例如:getComputedStyle(elem, ':after'))
获取当前元素的所有显式样式属性,没有相对值,只有绝对值(如没有 em,最后都会转为 px),IE8 以及一下不兼容
dom.currentStyle,IE 独有
同样的,不能修改
要注意效率,多次 style 操作效率会很慢,要减少 js 中 style 操作
封装 getStyle 方法
function getStyle(elem, prop) {
if (window.getComputedStyle) {
return window.getComputedStyle(elem, null)[prop];
} else {
return elem.currentStyle[prop];
}
}DOM 扩展
Selectors API
Selectors API 是 W3C 的推荐标准,规定了浏览器原生支持的 CSS 查询 API
Selectors API Level 1 的核心是两个方法:querySelector()和 querySelectorAll()
Selectors API Level 2 规范在 Element 上增加更多方法:matches()、find()、findAll()
querySelector()
接收 CSS 选择符参数,返回匹配到的第一个后代元素,如果没有匹配项则返回 null;返回的后代是实时的
在 document 上使用时,会从文档开始搜索;在 Element 上使用时,则只会从当前元素的后代中查询
querySelectorAll()
接收 CSS 选择符参数,返回所有匹配到的节点,返回值是一个 NodeListd 的静态实例,也就是说返回值是这些匹配元素的一个“闪照”,不是实时的
matches()
接收一个 CSS 选择符参数,如果元素匹配则返回 true,否则返回 false,这样可以方便的检测一个元素是否存在
主流浏览器都支持,IE9-11 以及一些移动浏览器支持带前缀的方法
元素遍历
Element Traversal API 为 DOM 新增的五个属性:
childElementCount,返回子元素数量
firstElementChild,指向第一个 Element 类型子元素
lastElementChild,指向最后一个 Element 类型子元素
previousElementSibling,指向前一个 Element 类型同胞元素
nextElementSibling,指向后一个 Element 类型同胞元素
IE9 及以上版本,所有主流浏览器都支持
HTML5
CSS 类扩展
1、getElementByClassName()
接收一个包含一个或多个类名的字符串,返回类名中包含相应类的元素的 NodeList 集合
IE9 及以上版本,所有主流浏览器都支持
2、classList 属性
要操作类名,可以通过 className 属性实现添加、删除和替换,但是 className 是一个字符串,所以每次操作后要重新设置这个值才能生效,即使只改动了一部分也一样、
classList 是一个新的集合类型 DOMTokenList 实例,它有 length 属性,能够使用 item()获取元素,还有以下新方法:
add(value),向类名列表中添加指定字符串值 value,如果该值已存在则什么都不做
contains(value),返回布尔值,表示 value 是否存在
remove(value),从类名列表删除指定的字符串值 value
toggle(value),如果类名列表中存在了指定的 value,则删除;如果不存在,则添加
IE10 及以上版本,所有主流浏览器都支持
焦点管理
document.activeElement,该属性始终包含当前拥有焦点的 DOM 元素;默认情况下,页面完全加载之前该属性值为 null,页面加载完后该属性会被设置为 document.body
document.hasFocus()方法,返回布尔值,表示文档是否拥有焦点;该方法可以确定用户是否在操作页面
HTMLDocument 扩展
1、readyState 属性
这是最早 IE4 添加到 document 对象上的属性,后来其他浏览器也相继实现,最后 HTML5 将这个属性写进了标准
该属性有两个可能的值:loading,表示文档正在加载、complete,表示文档加载完成
2、compatMode 属性
IE 为 document 添加了 compatMode 属性,表示当前浏览器处于什么渲染模式
标准模式下 document.compatMode 的值是 CSS1Compat,而混杂模式下的值是 BackCompat
HTML5 最终也将这个属性标准化了
3、head 属性
对 document.body 的补充,HTML5 增加了 document.head 属性指向 head 元素
字符集属性
HTML5 增加了几个与文档字符集有关的新属性,其中 characterSet 属性表示文档实际使用的字符集,也可以用来指定新的字符集
这个属性默认是“UTF-16”,可以通过<meta>元素或响应头,以及新增的 characterSet 属性来修改
document.characterSet;
document.characterSet = "UTF-8";自定义数据属性
HTML5 允许给元素指定非标准的属性,但要使用 data-前缀以便告诉浏览器,命名没有限制,data-后面跟什么都可以
自定义属性后可以根据元素的 dataset 属性来访问,dataset 属性是一个 DOMStringMap 的实例,包含一组键值对映射
自定义的属性都可以在 dataset 中通过 data-后面的字符串作为键值访问(例如:data-myname、data-myName 可以通过 myname 访问,data-my-name、data-My-Name 要通过 myName 来访问)
这样子的访问是可以读写值的
插入标记
当要向 DOM 中添加大量 HTML 时,用创建节点的方式很麻烦,但是 HTML5 可以直接插入 HTML 字符串
1、innerHTML 属性
设置 innerHTML 回导致浏览器将 HTML 字符串解析为相应的 DOM 树
2、旧 IE 中 innerHTML
浏览器中通过 innerHTML 插入的 script 标签是不会执行的
而在 IE8 及之前的版本中有玄学问题,不管他了,IE 已经被微软抛弃了
3、outerHTML
会返回自身和子树,修改也相当于修改自身
4、insertAdjacent()与 insertAdjacentText()
插入标签的新语法,最早来源于 IE,它们都接收两个参数:要插入标记的位置、要插入的 HTML 或文本
第一个值必须是以下几个:
beforebegin,插入当前元素前面
afterbegin,插入当前元素内部,作为一个新的子节点或放在第一个子节点前面
beforeend,插入当前元素内部,作为新的子节点或最后一个子节点前面
afterend,插入当前元素后面
第二个参数会作为 HTML 字符串或纯文本解析
假设当前元素是<p>hello</p>,则 beforebegin 和 afterbegin 中的 begin 指开始标签<p>;而另外两个指结束标签</p>
5、内存与性能问题
最好在使用 innerHTML 和 outerHTML 和 insertAdjacentHTML()之前,最好手动删除要被替换元素上的事件处理程序和 js 对象
而且面对多次迭代,尽量生成一个总字符串再使用 innerHTML 等属性插入
6、跨站点脚本
如果页面中要使用用户提供的信息,则不建议使用 innerHTML,因为恶意用户可以毫不费力的创建元素并执行 onclick 事件等,所以在涉及用户信息的时候应该毫不犹豫的使用相关库定义插入元素
scrollIntoView
这个方法存在于所有 HTML 元素上
这个方法参数如下:
alignToTop 是一个布尔值
true,窗口滚动后元素顶部与视口顶部对齐
false,窗口滚动后元素的底部与视口的底部对齐
scrollIntoViewOption 是一个选项对象
behavior,定义过度动画,可取的值为 smooth 和 auto(默认)
block,定义垂直方向的对齐,可取的值为:start(默认)、center、end、nearest
inline,定义水平方向的对齐,可取的值为:start、center、end、nearest(默认)
不传参数等同于 alignToTop 为 true
专有扩展
不确定在所有浏览器上都适用
children 属性
contains()方法
IE 首先引入
确定一个元素是不是另一个的后代,是返回 true,不是则返回 false
使用 DOM Level 3 的 compareDocumentPosition()方法也可以确定节点关系,这个方法会返回两个节点关系的位掩码
| 掩码 | 节点关系 |
|---|---|
| 0x1 | 断开(传入的节点不在文档中) |
| 0x2 | 领先(传入的节点在 DOM 树中位于参考节点之前) |
| 0x4 | 随后(传入的节点在 DOM 树中位于参考的节点之后) |
| 0x8 | 包含(传入的节点是参考节点的祖先) |
| 0x10 | 被包含(传入的节点是参考节点的后代) |
插入标记
HTML5 没有入选 innerText 和 outerText
innerText 属性
在查询时,会按照深度优先的顺序将子树中所有文本的值拼接起来;在写入值时,会移除元素所有后代并插入一个包含该值的文本节点
该属性已经取得所有浏览器支持
outerText 属性
这个属性读取值时和 innerText 一样;但在写入值时,outerText 会连元素自身一起覆盖,所以原来的元素会与文档脱离关系,无法访问
除 FireFox 之外的所有主流浏览器都支持
滚动
scrollIntoViewIfNeeded(alignCenter)
该方法作为 HTMLElement 类型的扩展可以在所有元素上调用
如果元素不可见,则将其滚动到窗口或包含窗口中,使其可见;如果元素可见,则这个方法什么也不做;如果将 alignCenter 设置为 true,则浏览器会尝试将其放在视口中央
Safari、Chrome、Opera 实现了
DOM2 和 DOM3
DOM1 主要定义了 HTML 和 XML 文档底层结构,DOM2 和 DOM3 在这些结构上加入了更多交互能力,提供了更高级的 XML 特性
DOM 的演进
DOM2 和 DOM3 新增了一些方法、属性、类型和 DOM 接口
XML 命名空间
XML 命名空间可以实现在一个格式的规范化文档中混用不同 XML 语言,而不用担心元素名冲突
严格来说 XML 命名空间在 XHTML 中才支持,HTML 并不支持
命名空间是使用 xmlns 来指定的,XHTML 的命名空间是“http://www.w3.org/1999/xhtml”应该包含在XHTML页面的html元素中
<html xmlns="http://www.w3.org/1999/xhtml">
<head></head>
<body></body> </html
><!-- 可以给使用xmlns给命名空间创建一个前缀,格式为:xmlns:前缀 -->
<xhtml:html xmlns:xhtml="http://www.w3.org/1999/xhtml">
<xhtml:head></xhtml:head>
<xhtml:body></xhtml:body> </xhtml:html
><!-- 这里为XHTML命名空间定义了前缀,同时所有XHTML元素都必须加上这个前缀,为了避免混淆,属性也可以加上 --><xhtml:html
xmlns:xhtml="http://www.w3.org/1999/xhtml"
>
<xhtml:head></xhtml:head>
<xhtml:body xhtml:class=""></xhtml:body> </xhtml:html
><!-- 如果文档只使用了一种XML语言,那么命名空间前缀其实是多余的,只有一个文档混合使用多种XML语言才有必要 -->1、Node 的变化
在 DOM2 中,Node 类型包含以下特定于命名空间的属性:
localName,不包含命名空间前缀的节点名
namespaceURI,节点命名空间 URL,如果未指定则为 null
prefix,命名空间前缀,如果未指定则为 null
在节点使用空间命名空间的情况下,nodeName 等于 prefix+“:”+localName
DOM3 进一步增加了如下命名空间相关的方法:
isDefaultNamespace(namespaceURI),返回布尔值,表示 namespaceURI 是否为节点的默认命名空间
lookupNamespaceURI(prefix),返回给定 prefix 的命名空间 URI
lookupPrefix(namespaceURI),返回给定的 namespaceURI 的前缀
2、Document 变化
DOM2 在 Document 类型上新增了如下命名空间特定的方法:
createElementNS(namespaceURI, tagName),以给定的标签名 tagName 创建指定的命名空间 namespaceURI 的一个新元素
createAttributeNS(namespaceURI, tagName),以给定的属性名 tagName 创建指定的命名空间 namespaceURI 的一个新属性
getElementsByTagNameNS(namespaceURI, tagName),返回指定的命名空间 namespaceURI 中所有标签名为 tagName 的元素的 NodeList
3、Element 变化
DOM2 Core 对 Element 类型的更新主要集中在对属性的操作上
getAttributeNS(namespaceURI, localName),取得指定命名空间 namespaceURI 中名为 localName 的属性
getAttributeNodeNS(namespaceURI, localName),取得指定命名空间 namespaceURI 中名为 localName 的属性节点
getElementsByTagNameNS(namespaceURI, tagName),取得指定命名空间 namespaceURI 中标签名为 tagName 的元素的 NodeList
hasAttributeNS(namespaceURI, localName),返回布尔值,表示元素中是否有命名空间 namespaceURI 下名为 localName 的属性(注意,DOM2 Core 也添加不带命名空间的 hasAttribute()方法)
removeAttributeNS(namespaceURI, localName),删除指定命名空间 namespaceURI 中名为 localName 的属性
setAttributeNS(namespaceURI, qualifiedName, value),设定指定命名空间 namespaceURI 中名为 qualifiedName 属性为 value
setAttributeNodeNS(attNode),为元素设置包含命名空间信息的属性节点 attNode
4、NamedNodeMap 的变化
这些方法大都使用属性:
getNamedItemNS(namespaceURI, localName),取得指定命名空间 namespaceURI 中命名为 localName 的项
removeNamedItemNS(namespaceURI, localName),删除指定命名空间 namespaceURI 中名为 localName 的项
setNamedItemNS(node),为元素设置包含命名空间信息的节点
其他变化
除命名空间的变化,DOM2 Core 还对 DOM 的其他部分做了一些更新,这些变化与命名空间无关
1、DocumentType 的变化
DocumentType 新增了三个属性:publicId、systemId、internalSubset
2、Document 的变化
importNode(),这个方法的目的是从其他文档获取一个节点并导入到新文档,以便将其插入新文档
如果调用 appendChild 方法时传入节点的 ownerDocument 不是指向当前文档则会发生错误,而调用 importNode 导入其他文档的节点会返回一个新节点,这个新节点 ownerDocument 属性是正确的
该方法接收两个参数:要复制的节点、同时是否复制子树的布尔值,返回适当文档中的新节点
DOM2 View 给 Document 类型增加了新属性 defaultView,是一个指向拥有当前文档的窗口(或窗格 frame)的指针
DOM2 Core 还针对 document.implementation 对象增加了两个新方法:createDocumentType()和 createDocument()
前者用于创建 DocumentType 类型的新节点,接收三个参数:文档类型名称、publicId 和 systemId
已有文档的文档类型不可更改,createDocumentType 只有在创建新文档时才用到,而创建新文档要使用 createDocument()方法,createDocument()只接收三个参数:文档元素的 namespaceURI、文档元素的标签名和文档类型
DOM2 HTML 模块为 document.implementation 对象添加了 createHTMLDocument()方法,使用这个方法可以创建一个完整的 HTML 文档,包含 html、head、title、body 元素,这个方法只接收一个参数,即新创建文档的标题,返回一个 HTML 文档
3、Node 的变化
DOM3 新增了用于比较两个节点的方法:isSameNode()和 isEqualNode(),这两个方法都接收一个节点参数如果传入节点和参考节点相同或相等,则返回 true
节点相同,意味着引用同一个对象;节点类型相同,拥有相等的属性,而且 attributes 和 childNodes 也相等(即同样的位置包含相等的值)
DOM3 增加了给 DOM 节点附加额外数据的方法,setUserData()方法接收 3 个参数:键、值、处理函数,也用于给节点追加数据
document.body.setUserData("name", "lsn", function () {}); //这样可以给节点追加数据
let value = document.body.getUserData("name"); //这样可以获取这个信息setUserData()处理函数会在包含数据的节点被复制、删除、重命名或导入其他文档的时候执行,可以在这个时候决定如何处理用户数据。该函数接收 5 个参数:表示操作类型的数值(1-代表复制,2-代表导入,3-代表删除,4-代表重命名)、数据的键、数据的值、源节点、目标节点;删除节点时,目标节点为 null;除复制外,目标节点都为 null
4、内嵌窗格的变化
DOM2 HTML 给 HTMLIFrameElement 类型增加了一个属性叫 contentDocument,这个属性包含代表子窗格中内容的 document 对象指针
还有一个 contentWindow,返回窗格的 window 对象,这个对象上有一个 document 属性
跨域访问子内嵌窗格 document 对象会受到安全限制
样式
存取元素样式
任何支持 style 属性的 HTML 元素在 js 中都有一个对应的 style 属性,他是 CSSStyleDeclaration 类型的实例,其中包括通过 HTML style 属性为元素设置的所有样式信息,但是不包括通过层叠机制从文档样式和外部样式中继承来的值
style 上的属性包括了所有 HTML style 属性中 CSS 属性,但是连字符‘ - ’要转换为驼峰法,而且 float 属性在 js 中属于保留字,所以 DOM2 style 规定要用 cssFloat
在标准模式下所有尺寸必须包含单位,不然会被忽略;混杂模式下,可以不带单位,会默认为默认单位
通过 HTML 标签上的 style 属性设置的样式可以通过 js 对应元素的 style 属性获得;如果没有设置,则全为空值
1、DOM 样式属性和方法
DOM2 styl 规范在 style 对象上定义了一些属性和方法:
cssText,包含 style 属性中的 CSS 代码
length,应用元素的 CSS 属性数量
parentRule,表示 CSS 信息的 CSSRule 对象
getPropertyCSSValue(propertyName),包含 CSS 属性 propertyName 值的 CSSValue 对象(已废弃)
getPropertyPriority(propertyName),如果 CSS 属性 propertyName 值使用了!important 则返回“!important”,否则返回空字符串
getPropertyValue(propertyName),返回属性 propertyName 的字符串值
item(index),返回索引的 CSS 属性名,连字符式
removeProperty(propertyName),从样式中删除 CSS 属性
setProperty(propertyName, value, priority),设置 CSS 属性 propertyName 的值为 value,priority 是“important”或空字符串
cssText 赋值会覆盖元素标签上整个 style 属性值
2、计算样式
DOM2 style 在 document.defaultView 上增加了 getComputedStyle()方法,这个方法接收两个参数:要取得的计算样的元素、伪元素字符串(如:“:after”);如果不需要查询伪元素则第二个参数可以传 null;该方法返回一个 CSSStyleDeclaration 对象,该对象是不能修改的
浏览器内部样式表中的默认信息也可以通过这个方法得到
let computedStyle = document.defaultView.getComputedStyle(document.getElementById("div"), null);
computedStyle.width;
computedStyle.backgroundColor;操作样式表
CSSStyleSheet 类型表示样式表,包括使用 link 和 style 元素定义的样式表,这两个元素本身就是 HTMLLinkElement 和 HTMLStyleElement
CSSStyleSheet 类型是一个通用样式表类型,可以表示以任何方式在 HTML 中定义的样式表,这个类型的实例式一个只读对象(只有一个属性例外)
CSSStyleSheet 继承了 StyleSheet,后者可用作非 CSS 样式表的基类,CSSStyleSheet 从 StyleSheet 继承了以下属性:
disabled,布尔值,表示是否禁用样式表(这个值是可读写的,设置为 true 会禁用样式表)
href,如果是使用 link 包含的样式表,则返回样式表的 URL,否则返回 null
media,样式表支持的媒体类型集合,这个集合有 length 属性和 item 方法,和所有 DOM 集合一样;如果样式表可用于所有属性,则返回的空列表
ownerNode,指向拥有当前样式表的节点,在 HTML 中要么是 link 要么是 style;在 XML 中可以是指令;如果是通过@import 被包含在另一个样式表中,则这个属性值为 null
parentStyleSheet,如果当前样式表是通过@import 被包含在另一个样式表中,则这个属性指向导入他的表
title,ownerNode 的 title 属性
type,字符串,表示样式表类型,如:“text/css”
CSSStyle 自有属性:
cssRules,当前样式表包含的样式规则的集合
ownerRule,如果样式表是使用@import 导入的,则指向导入规则,否则为 null
deleteRule(index),在指定位置删除 cssRule 中插入规则
insertRule(rule, index),在指定位置项 cssRule 中插入新规则
document.styleSheets 表示文档中样式表集合
通过 link 和 style 元素同样可以直接获取 CSSStyleSheet 对象
1、CSS 规则
CSSRule 表示样式表中的一条规则,他是一个通用基类,很多类型都继承它,但其中最常用的是表示央视信息的 CSSStyleRule,该对象上的属性有:
cssText,返回整条规则文本,这里的文本根据浏览器可能产生差异
parentRule,如果这条规则被其他规则包含,则指向包含规则,否则为 null
parentStyleSheet,包含当前规则的样式表
selectorText,返回规则的选择符文本,这里的文本根据浏览器有差异,这个属性在其他浏览器上只读,在 Opera 上可修改
style,返回 CSSStyleDeclaration 对象,可以读写当前规则中的样式
type,数值常量,表示规则类型,对于样式规则,始终为 1、
cssText 属性和 style.cssText 类似,不过前者包含选择符文本和环绕样式声明的大括号,而后者只包含样式声明;前者只读,后者可以读写
2、创建规则
DOM 规定,可以用 insertRule 向样式表中添加新规则,这个方法接收两个参数:规则文本、表示插入位置的索引
3、删除规则
deleteRule(),它接收一个参数,要删除规则的索引
元素尺寸
1、偏移尺寸
offsetHeight,元素在垂直方向上占用的像素尺寸,包括它的高度,水平滚动条高度(如果可见)、上下边框的高度
offsetLeft,元素左边框距离外侧包含边框的距离
offsetTop,元素上边框距离包含边框的距离
offsetWidth,元素在水平方向上占用的像素尺寸,包括宽度、垂直滚动条的宽度、左右边框的宽度
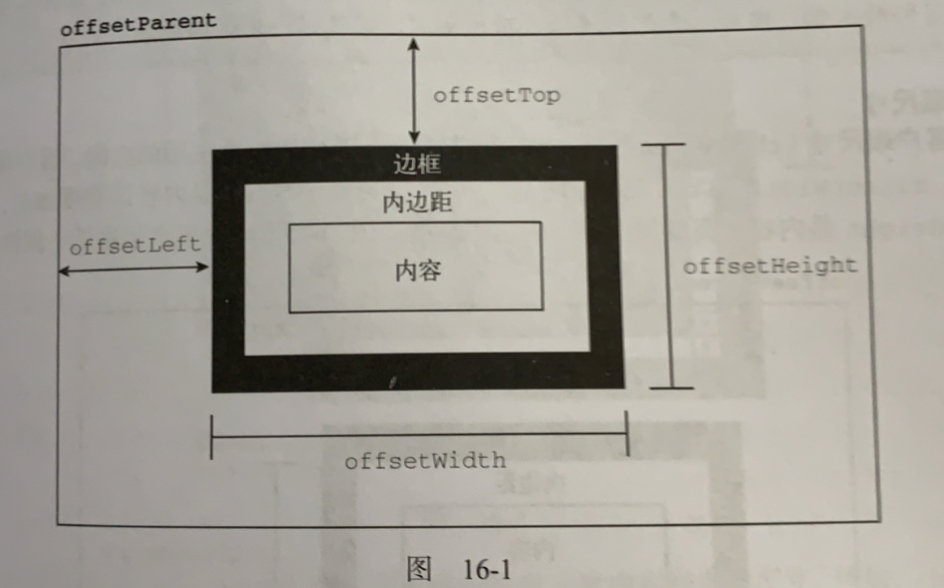
所有这些属性都是只读的,每次访问会重新计算,所以尽量减少访问次数,将他们保存在局部变量中
2、客户端尺寸
clientWidth、clientHeight,这两个属性只代表元素内部空间尺寸,不包括滑动条和边框尺寸
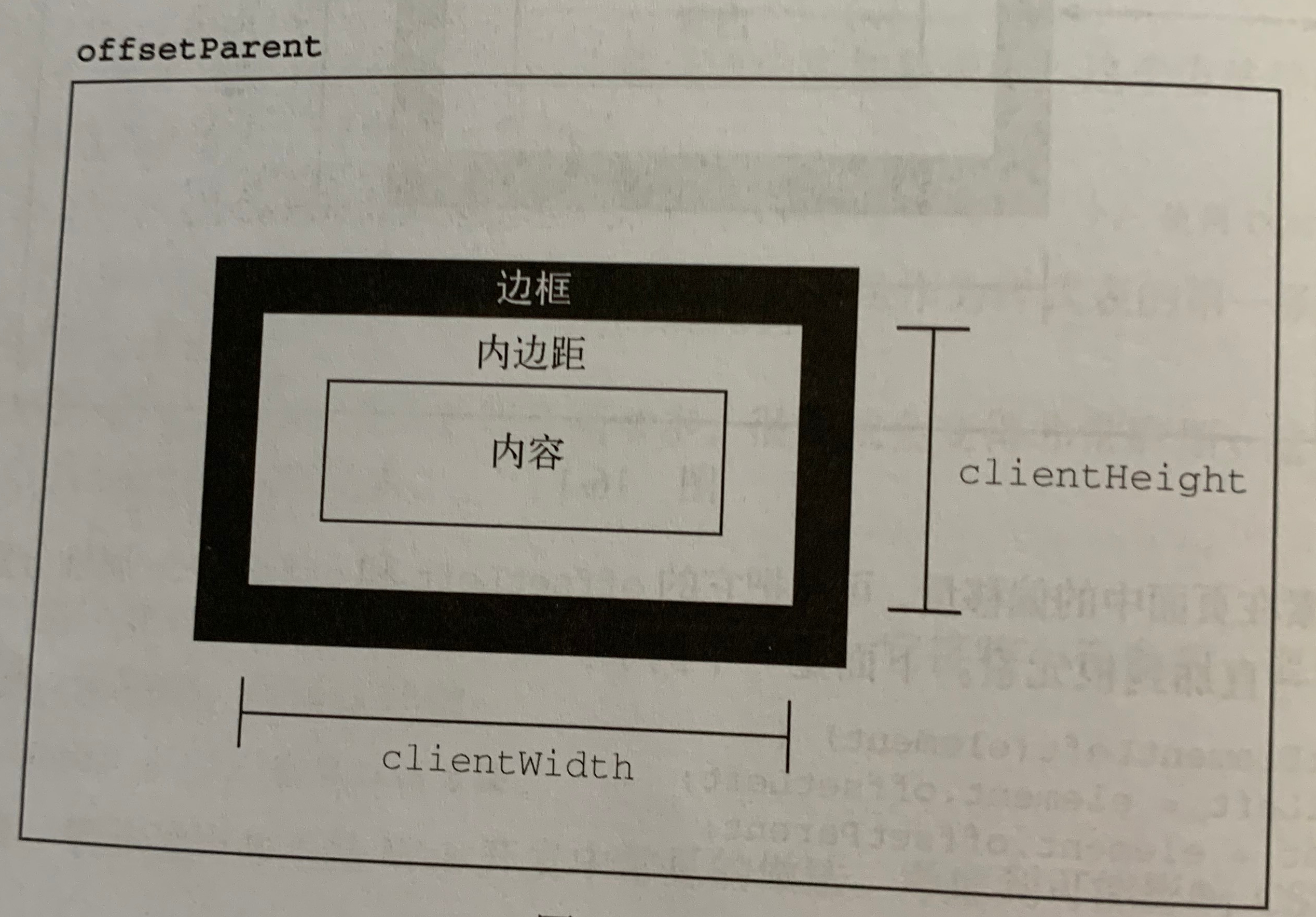
同时这两个属性也和偏移量一样只读,并且访问时会重新计算
3、滚动尺寸
scrollHeight,没有滚动条出现时,元素内容总高度
scrollLeft,内容区左侧隐藏的像素数,设置这个元素可以改变元素的滚动位置
scrollTop,内容区顶部隐藏的像素数,设置这个属性可以改变元素的滚动位置、
scrollWidth,没有滚动条出现时,元素内容的总宽度
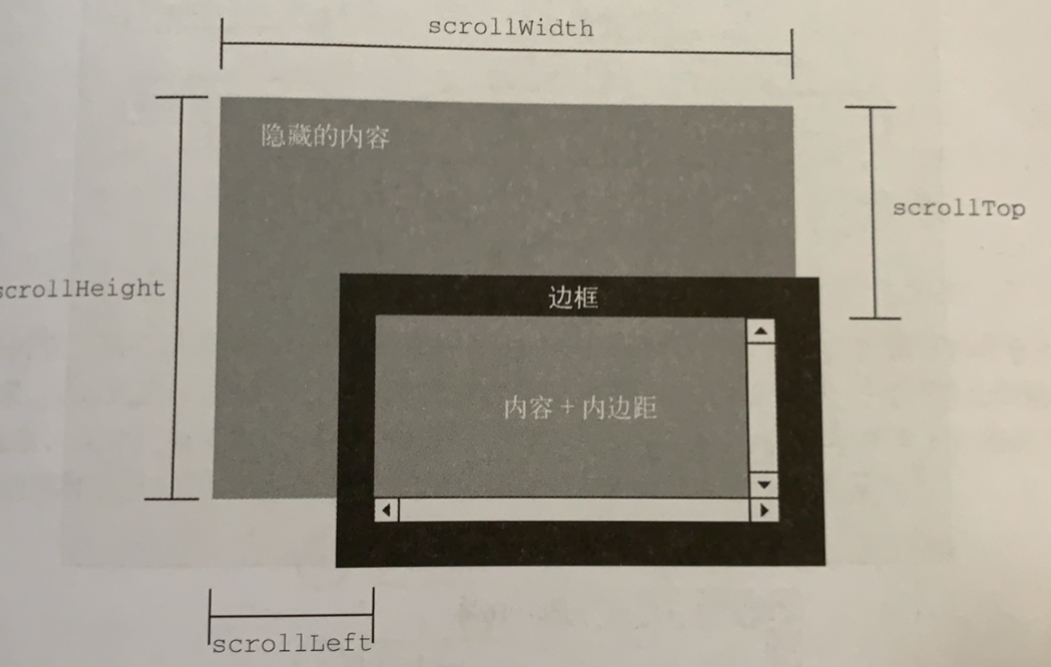
4、确定元素尺寸
getBoundingClientRect()方法,返回一个 DOMRect 对象,包含六个属性:left、top、right、bottom、height、width
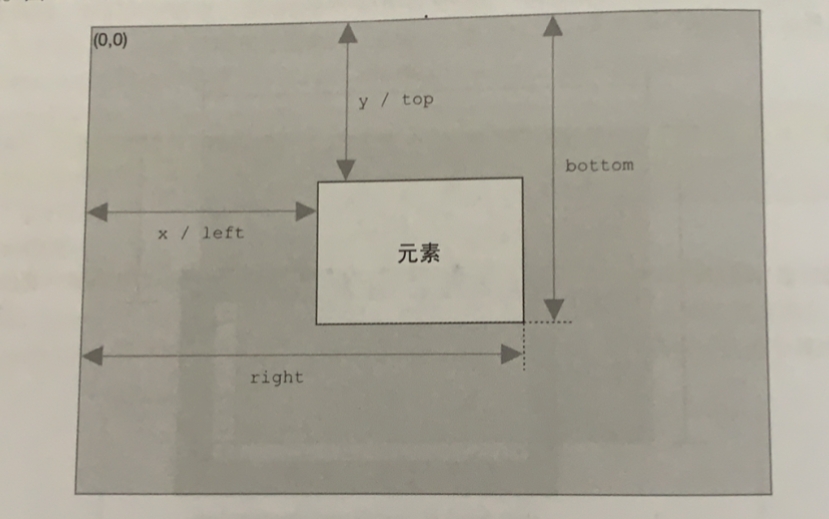
查看元素的几何尺寸与位置
大小
1、domEle.getBoundingClientRect()
兼容性很好,但是不是实时的
bottom: 200
元素右下角y坐标 height: 100 left: 100
元素左上角x坐标 right: 200
元素右下角x坐标 top: 100
元素左上角y坐标 width: 100 x: 100 y: 1002、dom.offsetWidth/offsetHeight
位置
1、dom.offsetLeft/offsetTop
对于有定位的父级的元素返回对父级的距离,对于无定位的父级的元素则返回对文档的距离
2、dom.offsetParent
返回最近有定位的父级,如无则返回 body,body.offsetParent 会返回 null
求元素相对文档的坐标 getElementPosition
function getElementPosition(elem) {
var position = {
top: elem.offsetTop,
left: elem.offsetLeft,
};
while (elem.offsetParent) {
elem = elem.offsetParent;
position["left"] += elem.offsetLeft;
position["top"] += elem.offsetTop;
}
return position;
}遍历
DOM2 Traversal and Range 模块定义了两个用于辅助顺序遍历的 DOM 结构:NodeIterator、TreeWalker——从某个起点开始执行对 DOM 结构的优先遍历

NodeIterator
通过 document.createNodeiterator()方法创建其实例,接收四个参数:
root,作为遍历的根节点
whatToShow,数值代码,表示因该访问哪些节点
filter,NodeFilter 对象或函数,表示是否接收或跳过特定节点
entityReferenceExpansion,布尔值,表示是否扩展实体引用,在 XHTML 中没有效果,因为实体引用永远不扩展
whatShow 参数是一个位掩码,通过一个或多个过滤器来指定访问哪些节点,这个参数对应的常量是在 NodeFilter 类型中定义的:
NodeFilter.SHOW_ALL,所有节点
NodeFilter.SHOW_ELEMENT,元素节点
NodeFilter.SHOW_ATTRIBUTE,属性节点(实际用不上)
NodeFilter.SHOW_TEXT,文本节点
NodeFilter.SHOW_CDATA_SECTION,CData 区块节点,HTML 中不使用
NodeFilter.SHOW_ENTITY_REFERENCE,实体引用节点,HTML 中不使用
NodeFilter.SHOW_ENTITY,实体节点,HTML 中不使用
NodeFilter.SHOW_PROCESSING_INSTRUCTION,处理指令节点,HTML 中不使用
NodeFilter.SHOW_COMMENT,注释节点
NodeFilter.SHOW_DOCUMENT,文档节点
NodeFilter.SHOW_DOCUMENT_TYPE,文档类型节点
NodeFilter.SHOW_DOCUMENT_FRAGMENT,文档片段节点,HTML 中不使用
NodeFilter.SHOW_NOTATION,记号节点,HTML 中不使用
这些值处了第一个以外,都可以组合使用,可以使用按位或操作组合多个选项
let whatToShow = NodeFilter.SHOW_ELEMENT | NodeFilter.SHOW_TEXT;
filter 参数可以用来指定自定义 NodeFilter 对象,或者一个节点过滤器函数;NodeFilter 对象只有一个方法 acceptNode(),如果给定节点应该访问就返回 NodeFilter.FILTER_ACCEPT,否则返回 NodeFilter.FILTER_SKIP;NodeFilter 是个抽象类型,所以不能创造它的实例,只需要包含 acceptNode()的对象就行了;filter 还能是函数,和 acceptNode 形式一样
如果不需要指定过滤器则直接传入 null
let iterator = document.createNodeIterator(div, NodeFilter.SHOW_ELEMENT, null, false);
let node = iterator.nextNode();
while (node != null) {
//遍历到结尾时返回null
//...
}nextNode()和 previousNode()方法共同维护 NodeIterator 对 DOM 的内部指针,修改 DOM 结构也会体现在遍历中
TreeWalker
TreeWalker 是 NodeIterator 的高级版,除了同样的 nextNode()、previousNode()方法,还添加了如下方法:
parentNode()、firstChild()、lastChild()、nextSibling()、previousSibling()
通过 document.createTreeWalker()方法创建,方法接收参数和 document.createNodeIterator()相同
节点过滤器(filter)除了返回 NodeFilter.FILTER_ACCEPT 和 NodeFilter.FILTER_SKIP,还可以返回 NodeFilter.FILTER_REJECT
在 NodeIterator 中,skip 和 reject 是一样的,但是在 TreeWalker 中,skip 表示跳过当前节点,reject 表示跳过该节点以及该节点整个子树
TreeWalker 类型有一个名为 currentNode 属性,表示遍历过程中上一次返回的节点(任何方法),通过修改这个属性可以影响接下来遍历的节点
范围
DOM2 Traversal and Range 模块定义了范围接口,范围接口可用于在文档中选择内容,而不用考虑节点之间的界限
DOM 范围
DOM2 在 Document 类型上定义了一个 createRange()方法,暴露在 document 对象上
let range = document.createRange();
与节点类似,这个范围节点是与创建它的文档关联的,不能在其他文档中使用;;创建并指定它的位置后,可以对范围内容执行一些操作
下面的属性提供了与范围在文档中位置相关信息:
startContainer,范围起点所在的节点(选区中第一个子节点的父节点)
startOffset,范围起点在 startContainer 中的偏移量。如果 startContainer 是文本节点,注释节点或 CData 区块节点,则 startOffset 指范围七点之前跳过的字符数,否则表示范围中第一个节点的索引
endContainer,范围终点所在的节点(选区中最后一个子节点的父节点)
endOffset,范围起点在 startContainer 中的偏移量
commonAncestorContainer,文档中以 startContainer 和 endContainer 为后代的最深的节点
这些属性会在就范围放到文档中特定位置时获得相应的值
简单选择
通过范围选择文档中某个部分最简单的方式就是:selectNode()、selectNodeContents()
这两个方法都接收一个节点作为参数,并将该节点的范围调用到它的范围
selectNode()方法选择整个节点,包括其后代节点;selectNodeContents()方法只选择节点的后代
<!DOCTYPE html>
<html>
<body>
<p id="p1">
<b>hello</b>
world
</p>
</body>
</html>let range1 = document.createRange();
let range2 = document.createRange();
p1 = document.getElementById("p1");
range1.selectNode(p1);
range2.selectNodeContents(p1);
调用 selectNode()时,startContainer、endContainer、commonAncestorContainer 都是传入节点的父节点,startOffset 属性等于传入节点在其父节点 childNodes 集合中的索引,endOffset 等于 startOffset 加选中节点个数
调用 selectNodeContents()时,startContainer、endContainer、commonAncestorConteiner 属性就是传入的节点,startOffset 始终为 0,endOffset 为传入节点子节点数量
选定完节点后,可以在范围上调用相应方法,实现对范围选中区的更精细控制
setStartBefore(refNode),把范围的起点设置到 refNode 之前,从而让 refNode 策划归纳为选区的第一个子节点;startContainer 被设置为 refNode.parentNode,startOffset 被设置为 refNode 在其父节点 childNodes 集合中的索引
setStartAfter(refNode),把范围的起点设置到 refNode 节点之后,从而将 refNode 排出在选区之外,让其下一个同胞节点称为第一个子节点;startContainer 被设为 refNode.parentNode,startOffset 被设为 refNode 在其父节点 childNodes 集合中的索引+1
setEndBefore(refNode),把范围的终点设置到 refNode 之前;endContainer 被设置为 refNode.parentNode,endOffset 被设置为 refNode 在其父节点 childNodes 集合中的索引
setEndAfter(refNode),把范围的终点设置到 refNode 之后;endContainer 被设置为 refNode.parentNode,endOffset 被设置为 refNode 在其父节点 childNodes 集合中的索引+1
复杂的选区
使用 setStart()和 setEnd()方法
两个方法都接收两个参数:参照节点、偏移量
参照节点会赋值给 xxxContainer,偏移量会赋值给 xxxOffset
具体操作请见红宝书 p484
操作范围
创建范围后,浏览器会在内部创建一个文档片段节点,用于包含范围选区中的节点。操作范围中的内容必须格式完好,如果不完好,范围能够确定缺失的结构,从而可以重构出有效的 DOM 结构,但是这样会影响 document 结构
操作范围的方法:
deleteContents(),删除 document 中范围内包含的对象
extractContents(),删除 document 中范围内包含的对象,返回文档片段,内容是删除的对象
cloneContents(),创建范围内对象副本,返回一个文档片段
范围插入
insertNode()方法可以在范围选区的开始位置插入一个节点
surroundContents()方法插入包含范围的内容,传入包含范围内容的节点,调用这个方法,后台执行如下操作:
1、提取范围的内容
2、在原始文档中范围之前所在的位置插入给定的节点
3、将范围对应的文档片段的内容添加到给定节点
这种功能适合在网页中高亮显式某些关键字;但是范围中必须包含完整的 DOM 结构,如果范围中包含部分选择的非文节点,这个操作会失败并报错,如果给定的节点是 Document、DocumentType、DocumentFragment 类型也会出错
范围折叠
如果范围并没有选择文档的任何部分,则成为折叠

折叠范围可以使用 collapse()方法,这个方法接收一个布尔值,表示折叠到范围的哪一端,true 表示折叠到起点,false 表示折叠到终点,要确定范围是否被折叠,可以检测范围的 collapsed 属性
范围比较
如果有多个范围,compareBoundaryPoints()方法确定范围之间是否存在公共的边界(起点或终点),这个方法接收两个参数:要比较的范围、常量值
常量参数包括:
Range.START_TO_START(0),比较两个范围的起点
Range.STRAT_TO_END(1),比较第一个范围的起点和第二个范围的终点
Range.END_TO_END(2),比较两个范围的终点
Range.END_TO_START(3),比较第一个范围的终点和第二个范围的起点
边界不包含返回-1,相切返回 0,包含返回 1
复制范围
cloneRange()方法可以复制范围,新范围包含原始范围一样的属性,对新范围的修改不会影响原始范围
清理
使用完范围后,最好调用 detach()方法把范围从创建它的文档中剥离,调用 detach()后可以放心解除对范围的引用
range.detach(); range = null;
异步加载 JS
1、defer="defer",在 script 标签上添加,只有 IE 能用,用于外部脚本
推迟执行脚本
2、aysnc="aysnc"(asychronous),只针对外部脚本
异步执行脚本
3、创建 script 插入到 dom 中,加载完毕后 callback
动态加载脚本,这种资源获取方式对浏览器预加载器是不可见的,会严重影响他们在资源获取队列中的优先级,如果想要预加载器知道这些文件存在,可以在文档头部显示声明<link rel="preload" href="tools.js">
<script type="text/javascript">
var script = document.createElement("script");
script.type = "text/javascript";
script.src = "tools.js"; //此刻将会执行下载
if (script.readyState) {
script.onreadystatechange = function () {
if (script.readyState == "complete" || script.readyState == "loaded") {
}
};
} else {
script.onload = function () {};
}
document.head.appendChild(script);
</script>封装函数 loadScript
function loadScript(url, callback) {
var script = document.createElement('script');
script.type = 'text/javascript';
if (script.readyState) {
script.onreadystatechange = function() {
if (script.readyState == "complete" || script.readyState == "loaded") {
callback();
}
}
} else {
script.onload = function() {
callback();
}
}
script.src = url; //此刻将会执行下载
document.head.appendChild(script);
}
loadScript('tools.js', function() {
test();
});
tools.js -> function test() {console.log('a')}
//方法二
loadScript('tools.js', "test");
tools.js -> var tools = {
test: function() {},
demo: function() {}
}
function loadScript(url, callback) {
var script = document.createElement('script');
script.type = 'text/javascript';
if (script.readyState) {
script.onreadystatechange = function() {
if (script.readyState == "complete" || script.readyState == "loaded") {
tools[callback]();
}
}
} else {
script.onload = function() {
tools[callback]();
}
}
script.src = url; //此刻将会执行下载
document.head.appendChild(script);
}JS 加载时间线
1、创建 Document 对象,开始解析 Web 页面 —— document.readyState = "loading"
2、遇到 link 外部 css,创建线程并加载,并且继续解析文档
3、遇到 script 外部 js,并且没有设置 async、defer,浏览器加载并阻塞页面,等待 script 加载完并执行该脚本,然后继续解析文档
4、加载设置了 async、defer 的脚本,浏览器创建线程加载,继续解析文档。设置了 async 的脚本加载完立即执行(异步禁止使用 document.write 方法)
document.write 方法在文档全部加载完后会消除文档流,甚至连自己的 script 标签都消除
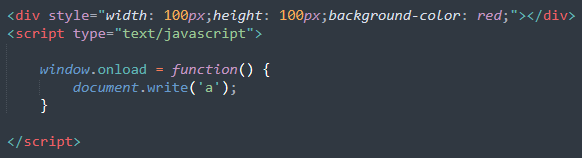
5、遇到 img 等,先正常解析 dom 结构,然后浏览器异步加载 src,并继续解析文档
6、文档解析完成,document.readyState = 'interactive'
7、文档解析完成后(DOM 树构建完),所有设置有 defer 的脚本会按照顺序执行(同样禁止使用 document.write 方法)
8、document 触发 DOMContentLoaded 事件
9、当所有 async 脚本加载完并执行后,img 加载完后。document.readyState = 'compelete',window 对象触发 load
10、从此以异步响应方式处理用户输入、网络事件等
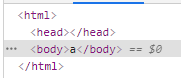
console.log(document.readyState);
document.onreadystatechange = function () {
console.log(document.readyState);
};
document.addEventListener(
"DOMContentLoaded",
function () {
console.log("a");
},
false
);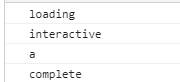
一般我们不会等到 async 脚本和 img 等加载完再执行,所以需要用 DOMContentLoaded 方法
domTree + cssTree = randerTree
reflow 重排触发条件:
dom 节点的删除、添加,宽高变化、位置变化、display none --> block,offsetWidth、offsetLeft 等
尽量避免重排,因为重排会将 renderTree 进行整个重排
repaint 重绘
将改变的部分进行重绘,属于部分改变